Webスクレイピング(selenium)
はじめに
データ収集のためにWebサイトをWebスクレイピングすることがありますが、今回は動的サイトにも対応しているseleniumの使い方をまとめました。
やりたいこと
試しにYahooのファイナンス FX・為替の情報を取得します。
以下の画像の赤枠部分の数値を取得してみましょう。
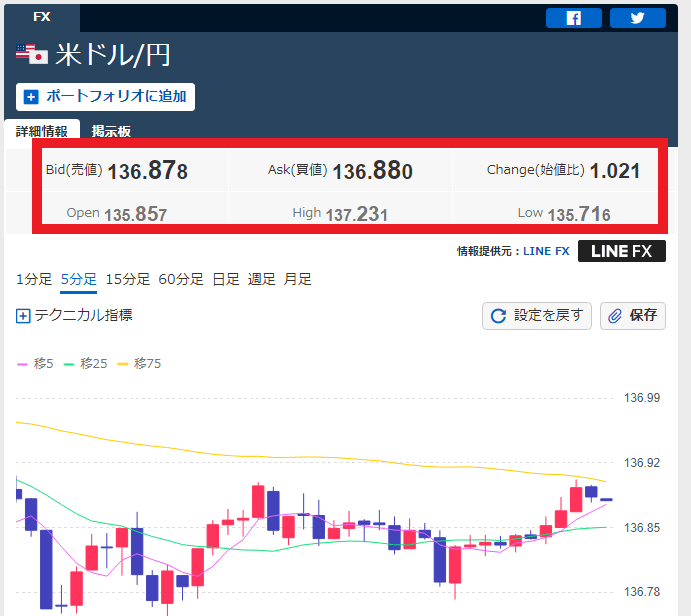
実行結果
先に実行結果ですが、以下のように欲しい情報だけを抽出します。
$ python3 ./scraiping_fx.py
=====================================================
米ドル/円 - FXレート・チャート - Yahoo!ファイナンス
=====================================================
Bid(売値): 136.878
Bid(買値): 136.880
Change(始値比): 1.021
Open: 135.857
High: 137.231
Low: 135.716
うまく取得できたようですね。
ソース
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
list_selector = [
["Bid(売値): ", "#root > main > div > div > div.XuqDlHPN > div._1IdtoV3i._2_d3RQf- > section._15smr45n._3D9KIUuT > div._2QdA_Jef > div > div._1vVJ9oXd._3ucBcVhW._2WmlQPbU > dl > dd"],
["Bid(買値): ", "#root > main > div > div > div.XuqDlHPN > div._1IdtoV3i._2_d3RQf- > section._15smr45n._3D9KIUuT > div._2QdA_Jef > div > div._1vVJ9oXd._3ucBcVhW._2t_FjeGH > dl > dd"],
["Change(始値比): ", "#root > main > div > div > div.XuqDlHPN > div._1IdtoV3i._2_d3RQf- > section._15smr45n._3D9KIUuT > div._2QdA_Jef > div > div._1vVJ9oXd._3ucBcVhW._4hyc0hX3 > dl > dd > span"],
["Open: ", "#root > main > div > div > div.XuqDlHPN > div._1IdtoV3i._2_d3RQf- > section._15smr45n._3D9KIUuT > div._2QdA_Jef > div > div._1vVJ9oXd._3ucBcVhW._1TcUUbuF > dl > dd"],
["High: ", "#root > main > div > div > div.XuqDlHPN > div._1IdtoV3i._2_d3RQf- > section._15smr45n._3D9KIUuT > div._2QdA_Jef > div > div._1vVJ9oXd._3ucBcVhW.l3zz7oWf > dl > dd"],
["Low: ", "#root > main > div > div > div.XuqDlHPN > div._1IdtoV3i._2_d3RQf- > section._15smr45n._3D9KIUuT > div._2QdA_Jef > div > div._1vVJ9oXd._3ucBcVhW._2zemqNZx > dl > dd"],
]
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(5)
url = "https://finance.yahoo.co.jp/quote/USDJPY=FX"
driver.get(url)
for list in list_selector:
mess = driver.find_element_by_css_selector(list[1])
print(list[0] + str(mess.text).replace('\n',''))
driver.quit()
list_selector[0]: 取得するデータの名前
list_selector[1]: 取得するデータのselector値※
※selector値は、後述の方法で取得します
options~の部分は実行オプションを設定しています。今回はブラウザを表示しないためヘッドレスモード('--headless')で立ち上げています。
driver.get(url): 「url」で指定したURLにアクセスします。
driver.find_element_by_css_selector: 取得したい要素をselector値を指定して取得できます。
selector値の取得方法
Webサイトに表示されている「Bid(売値)」、「Bid(買値)」のように特定の箇所のデータだけ取得するにはどうすればいいのでしょうか?
ほとんどのブラウザでDeveloper Toolが使えますので、Developer Toolを起動して取得したい情報のselectorを取得します。
chromeの場合はF12キーを押すと以下画面のように右側にDeveloper Toolの画面が開きます。
その後、左側のWebサイトの画面を見ながら、取得したい情報のところまで「▼」のマークを展開して辿っていきます。
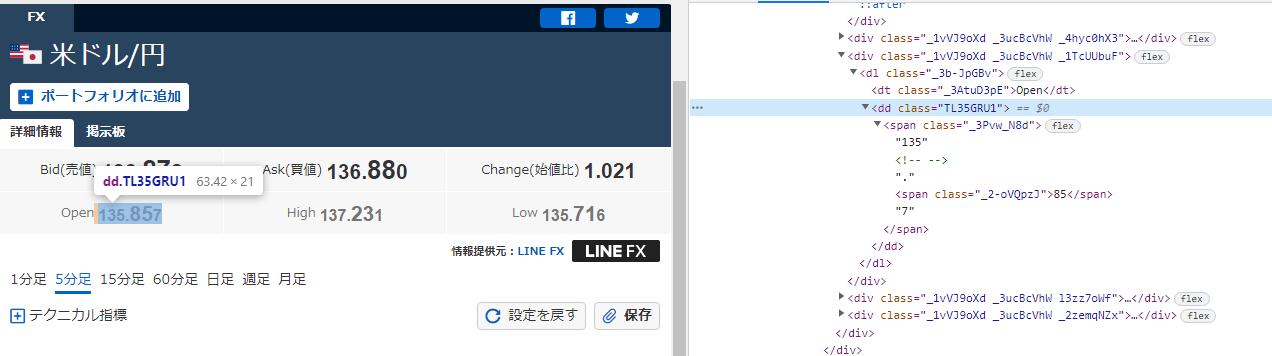
要素の場所が特定できたあと、右クリックで「COPY」―「COPY selector」をクリックし、selector値をコピーします。
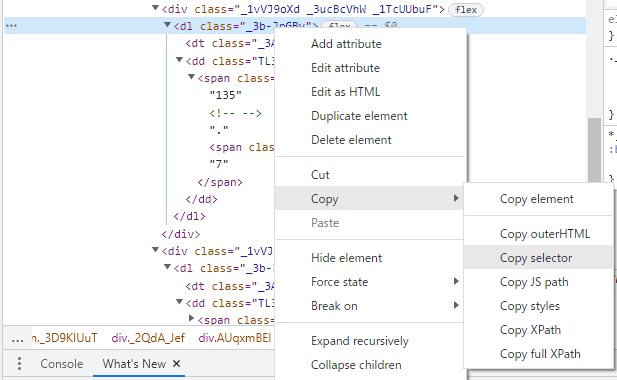
コピーすると以下のような文字列がクリップボードにコピーされます。
#root > main > div > div > div.XuqDlHPN > div._1IdtoV3i._2_d3RQf- > section._15smr45n._3D9KIUuT > div._2QdA_Jef > div > div._1vVJ9oXd._3ucBcVhW._2WmlQPbU > dl > dd
コピーした文字列をfind_element_by_css_selector()で指定して、欲しいデータだけ抽出します
他の情報も、同様の手順を繰り返せばWebサイトで取得したい情報だけ抽出できるようになります。
【参考】実行環境
以下のDockerfileを利用して環境を立ち上げました
Dockerfile
FROM centos:7
RUN yum -y update
RUN yum -y install epel-release
RUN yum -y install wget
RUN yum -y install unzip
RUN yum -y install python3
RUN wget https://bootstrap.pypa.io/pip/3.6/get-pip.py
RUN python3 get-pip.py
RUN pip install selenium
COPY ./google-chrome.repo /etc/yum.repos.d/
RUN yum -y install --enablerepo=google-chrome google-chrome-stable
RUN google-chrome --version
RUN wget https://chromedriver.storage.googleapis.com/104.0.5112.79/chromedriver_linux64.zip
RUN unzip chromedriver_linux64.zip
RUN mv chromedriver /usr/local/bin/
RUN export PATH=/usr/local/bin:${PATH}
RUN chmod 755 /usr/local/bin/chromedriver
RUN rm chromedriver_linux64.zip
コンテナイメージビルド
# docker build -t selenium:1 .
起動、コンテナログイン
# docker run -it <コンテナイメージID> /bin/bash
Discussion