こんにちは、株式会社エムニでCOOを務めているgyutaです。
エムニは松尾研発スタートアップ&京大発AIスタートアップとして、大手製造業を中心にオーダメードのAI開発事業を行なっています。
2023年10月設立のエムニは生成AIネイティブな企業として、顧客の業務フローのAIによる改善だけではなく、自社のあらゆる経営活動をAIを用いて効率化する『AI駆動経営』を推し進めています。今回はその中で作ったMCPサーバーを紹介します。
作ったもの
オーダーメードAI開発として、複数の新規AIプロダクト開発に関わっていく中で、非エンジニアに向けてプロダクトの仕様をドキュメントにまとめる場面が多々発生します。そこで業務の効率化を目指して1つのGoogle Documentの編集に特化したMCPサーバーを作りました。指定されたドキュメントをLLM(人間)が理解しやすいような形式でMCPクライアントに提示し、MCPクライアントからの変更要求を適切にマージしてGoogle Documentに反映させます。
根本的な課題感としては、NotionやGoogle DocumentがLLMフレンドリーでないというところにあります。これらのツールは内部的に複雑なネストされたデータ構造でドキュメントを表現しますが、人間にとって直感的に操作できるのは、視覚的に重要な情報だけがUIに表出するようにプログラム側で調整されているからです。もちろん、LLMは人間が一度に理解できるより遥かに膨大なコンテキストウィンドウを持ちますが、ブロックIDのようなノイズとなる情報は減らした方がタスクの遂行能力が上がることが推察されます。そこで、LLMにとっての適切なUX(LLMX?)を実現するため、Google Documentを編集するインターフェースとなるMCPサーバーを作成してみました。
ややこしく書きましたが、Google Documentの構造を簡略化して操作できるMCPサーバーを作った感じです。これによって、大規模なドキュメント編集に適した構造を実現し、また、LLMと人間とのクラウド上での同時編集を可能することを目指しました。
解説
MCP/ドメインモデル/外部API層の3層のレイヤーに大まかに分かれています。図にすると次のイメージです。
MCP
エムニでは、正社員エンジニア向けにCursorのビジネスプランを提供しているため、MCPクライアントとしては、Cursorを前提に実装しています。
MCPサーバーが提供できるリソースはいくつかありますが、Cursorが対応しているのがtoolsのみであるため、基本的にtoolsで全てを表現しています。
次の4つのtoolsを提供しています。
-
get_markdown
ドキュメントをマークダウン形式で取得するtool -
get_all_content
ドキュメントをContentのlistとして取得するtool -
modify_content
指定したContentの本文を置き換えるtool -
insert_content
Contentを指定した位置に挿入するtool
基本的に、1は最初の確認用で、2->(3or4)->2を繰り返してドキュメントを仕上げていく使い方を想定しています。
ソースコード
from mcp.server.fastmcp import FastMCP
from gdoc_mcp.model import ContentWithId, ContentId, Backend, GoogleDocBackend
from typing import Annotated
import argparse
from pydantic.dataclasses import dataclass
from gdoc_mcp.gdoc.client import get_document
from loguru import logger
@dataclass
class Args:
doc_id: str
parser = argparse.ArgumentParser()
parser.add_argument(
"doc_id",
type=str,
help="対象とするGoogleドキュメントのID",
)
args = parser.parse_args(namespace=Args)
# バリデーション
try:
get_document(args.doc_id)
logger.info(
f"対象とするGoogleドキュメントのID: {args.doc_id} の取得に成功しました。"
)
except Exception as e:
logger.error(
f"対象とするGoogleドキュメントのID: {args.doc_id} の取得に失敗しました。"
)
logger.error(e)
exit(1)
mcp = FastMCP("GDoc-mcp")
def get_backend() -> Backend:
return GoogleDocBackend.from_gid(args.doc_id)
@mcp.tool(name="get_markdown", description="ドキュメントをMarkdown形式で取得します。")
async def get_md() -> str:
backend = get_backend()
return backend.llmdoc.to_md()
@mcp.tool(
name="get_all_content", description="ドキュメントのすべてのコンテンツを取得します。"
)
async def get_all_content() -> list[ContentWithId]:
backend = get_backend()
return backend.llmdoc.get_all_content()
@mcp.tool(name="modify_content", description="ドキュメントを編集します。")
async def modify_content(
content_id: Annotated[ContentId, "コンテンツのID"],
content_body: Annotated[str, "コンテンツの内容"],
) -> list[ContentWithId]:
backend = get_backend()
llmdoc = backend.replace_content(content_id, content_body)
return llmdoc.get_all_content()
@mcp.tool(
name="insert_content", description="指定したcontent_idの後ろに段落を挿入します。"
)
async def insert_content(
before_content_id: Annotated[ContentId, "段落を挿入する前のコンテンツのID"],
paragraph_body: Annotated[str, "段落の内容"],
) -> list[ContentWithId]:
backend = get_backend()
llmdoc = backend.insert_paragraph(before_content_id, paragraph_body)
return llmdoc.get_all_content()
if __name__ == "__main__":
mcp.run(transport="streamable-http")
ドメインモデル
設計書のようなドキュメントは、基本的に章立てに分かれており、各章の関係性は比較的薄く、章ごとに独立して記述するとの考えのもと、Headerで区切ったモデルで表現しています。
これによって、章ごとに深掘りしながらLLMにドキュメントを作成させること目指します。
class Content(Protocol):
body: str
def replace(self, content: str) -> None: ...
def to_md(self) -> str: ...
class Heading(BaseModel):
level: Literal[1, 2, 3, 4, 5, 6] = Field(description="見出しのレベル")
body: str = Field(description="見出しの内容")
def replace(self, content: str) -> None:
self.body = content
def to_md(self) -> str:
return f"{'#' * self.level} {self.body}"
class Paragraph(BaseModel):
body: str = Field(description="段落の内容")
def replace(self, content: str) -> None:
self.body = content
def to_md(self) -> str:
return self.body
class LLMDoc(BaseModel):
model_config = ConfigDict(arbitrary_types_allowed=True)
contents: list[Content] = Field(description="コンテンツのリスト")
...
ソースコード
from pydantic import BaseModel, ConfigDict, Field
from typing import Protocol, Literal, Self, runtime_checkable
from gdoc_mcp.gdoc.gen.api_model import (
BatchUpdateDocumentRequest,
Request,
InsertTextRequest,
Location,
ReplaceAllTextRequest,
SubstringMatchCriteria,
)
from gdoc_mcp.gdoc.client import (
paragraph_to_str,
table_to_str,
get_document,
update_document,
)
@runtime_checkable
class Content(Protocol):
body: str
def replace(self, content: str) -> None: ...
def to_md(self) -> str: ...
class ContentId(BaseModel):
id: str = Field(
description="コンテンツのID"
)
class ContentWithId(BaseModel):
model_config = ConfigDict(arbitrary_types_allowed=True)
id: ContentId = Field(description="コンテンツのID")
content: Content
class Heading(BaseModel):
level: Literal[1, 2, 3, 4, 5, 6] = Field(description="見出しのレベル")
body: str = Field(description="見出しの内容")
def replace(self, content: str) -> None:
self.body = content
def to_md(self) -> str:
return f"{'#' * self.level} {self.body}"
class Paragraph(BaseModel):
body: str = Field(description="段落の内容")
def replace(self, content: str) -> None:
self.body = content
def to_md(self) -> str:
return self.body
class LLMDoc(BaseModel):
model_config = ConfigDict(arbitrary_types_allowed=True)
contents: list[Content] = Field(description="コンテンツのリスト")
def get_all_content(self) -> list[ContentWithId]:
return [
ContentWithId(id=ContentId(id=f"{i}"), content=content)
for i, content in enumerate(self.contents, start=1)
]
def get_content(self, content_id: ContentId) -> Content:
content_with_ids = self.get_all_content()
for content_with_id in content_with_ids:
if content_with_id.id.id == content_id.id:
return content_with_id.content
raise ValueError(f"Content with id {content_id.id} not found")
def replace_content(self, content_id: ContentId, content: str):
self.get_content(content_id).replace(content)
def insert_paragraph(self, before_content_id: ContentId, content: str):
insert_index = self.get_content_index(before_content_id)
self.contents.insert(insert_index, Paragraph(body=content))
def get_content_index(self, content_id: ContentId) -> int:
content_with_ids = self.get_all_content()
for i, content_with_id in enumerate(content_with_ids):
if content_with_id.id.id == content_id.id:
return i
raise ValueError(f"Content with id {content_id.id} not found")
def to_md(self) -> str:
return "\n".join([content.to_md() for content in self.contents])
@classmethod
def from_md(cls, md: str) -> Self:
contents: list[Content] = []
for line in md.split("\n"):
contents.append(line_to_content(line))
return cls(contents=contents)
def line_to_content(line: str) -> Content:
if line.startswith("#"):
if line.startswith("#######"):
raise ValueError(f"Invalid heading level: {line}")
elif line.startswith("######"):
level = 6
elif line.startswith("#####"):
level = 5
elif line.startswith("####"):
level = 4
elif line.startswith("###"):
level = 3
elif line.startswith("##"):
level = 2
else:
level = 1
body = line.lstrip("#").strip()
return Heading(level=level, body=body)
else:
return Paragraph(body=line)
class Backend(Protocol):
llmdoc: LLMDoc
def insert_paragraph(
self, before_content_id: ContentId, content: str
) -> LLMDoc: ...
def replace_content(self, content_id: ContentId, content: str) -> LLMDoc: ...
class GoogleDocContentIndex(BaseModel):
start_index: int
end_index: int
class GoogleDocBackend(BaseModel):
doc_id: str = Field(description="GoogleドキュメントのID")
llmdoc: LLMDoc = Field(description="LLMDoc")
index_list: list[GoogleDocContentIndex] = Field(
description="Googleドキュメントのコンテンツのインデックスリスト。内部で更新操作に利用する。"
)
def insert_paragraph(self, before_content_id: ContentId, content: str) -> LLMDoc:
content_index = self.llmdoc.get_content_index(before_content_id)
google_doc_content_index = self.index_list[content_index]
update_document(
self.doc_id,
BatchUpdateDocumentRequest(
requests=[
Request(
insertText=InsertTextRequest(
text=content,
location=Location(index=google_doc_content_index.end_index),
)
)
]
),
)
return self.from_gid(self.doc_id).llmdoc
def replace_content(self, content_id: ContentId, content: str) -> LLMDoc:
base_text = self.llmdoc.get_content(content_id).body
update_document(
self.doc_id,
BatchUpdateDocumentRequest(
requests=[
Request(
replaceAllText=ReplaceAllTextRequest(
containsText=SubstringMatchCriteria(
text=base_text,
matchCase=True,
),
replaceText=content,
)
)
]
),
)
return self.from_gid(self.doc_id).llmdoc
@classmethod
def from_gid(cls, doc_id: str) -> Self:
document = get_document(doc_id)
index_list: list[GoogleDocContentIndex] = []
contents: list[Content] = []
if document.body is None:
return cls(doc_id=doc_id, llmdoc=LLMDoc(contents=[]), index_list=[])
if document.body.content is None:
return cls(doc_id=doc_id, llmdoc=LLMDoc(contents=[]), index_list=[])
for content in document.body.content:
if content.paragraph:
contents.append(line_to_content(paragraph_to_str(content.paragraph)))
elif content.table:
contents.append(Paragraph(body=table_to_str(content.table)))
else:
continue
start_index = content.startIndex if content.startIndex else 0
end_index = content.endIndex if content.endIndex else 0
index_list.append(
GoogleDocContentIndex(start_index=start_index, end_index=end_index)
)
# 空文字のcontentsが入るのを防ぐ。
# これは、replace_contentで空文字を指定した場合に、GoogleDocのAPIがエラーを返すため。
filled_contents: list[Content] = []
filled_index_list: list[GoogleDocContentIndex] = []
for i, content in enumerate(contents):
if content.body != "":
filled_contents.append(content)
filled_index_list.append(index_list[i])
return cls(
doc_id=doc_id,
llmdoc=LLMDoc(contents=filled_contents),
index_list=filled_index_list,
)
外部API層
Google Documentとドメインモデルを同期させる層になります。Google Documentのデータ構造はかなり複雑で、LLMにとって理解しやすいよう、なるべくプレーンなデータ構造へと変換を行います。
内部的には、LLMが行った変換をGoogle Docsの形式に合うようにコツコツ擦り合わせている感じです。現在対応しているのが、ヘッダーと通常の文章だけになりますが、今後テーブルやリストなどの対応を入れると破綻する未来が見えるので、個別に変換を実装する今回のアプローチではなく、そもそもmarkdownからgoogle docsにインポートする戦略の方が良かったかもしれません。
かなり複雑なJSON構造を扱う必要があるにもかかわらず、SDKは型情報がなくて辛いなと思っていましたが、Google独自のAPI定義用のDSLからOpenAPIに変換するプロジェクト(https://github.com/APIs-guru/google-discovery-to-swagger)と、OpenAPIからPydanticのスキーマを生成するプロジェクト(https://github.com/koxudaxi/datamodel-code-generator)を見つけてとても助かりました。
ソースコード
from google.oauth2.credentials import Credentials
from googleapiclient.discovery import build
from gdoc_mcp.gdoc.gen.api_model import (
Document,
BatchUpdateDocumentRequest,
Table,
Paragraph,
NamedStyleType,
)
import os
from google.auth.transport.requests import Request
from google_auth_oauthlib.flow import InstalledAppFlow
SCOPES = [
"https://www.googleapis.com/auth/documents",
"https://www.googleapis.com/auth/drive",
]
def get_credentials():
if os.path.exists("token.json"):
creds = Credentials.from_authorized_user_file("token.json", SCOPES)
# If there are no (valid) credentials available, let the user log in.
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file("credentials.json", SCOPES)
creds = flow.run_local_server(port=0)
# Save the credentials for the next run
with open("token.json", "w") as token:
token.write(creds.to_json())
return creds
def get_service():
credentials = get_credentials()
service = build("docs", "v1", credentials=credentials).documents()
return service
def create_document(title: str) -> Document:
service = get_service()
res = service.create(body={"title": title}).execute()
return Document.model_validate(res)
def get_document(doc_id: str) -> Document:
service = get_service()
res = service.get(documentId=doc_id).execute()
return Document.model_validate(res)
def update_document(doc_id: str, request: BatchUpdateDocumentRequest):
service = get_service()
res = service.batchUpdate(documentId=doc_id, body=request.model_dump()).execute()
return Document.model_validate(res)
def show_document(doc: Document):
if doc.body is None:
return
if doc.body.content is None:
return
for content in doc.body.content:
if content.paragraph:
print(paragraph_to_str(content.paragraph))
if content.table:
print(table_to_str(content.table))
def paragraph_to_str(paragraph: Paragraph):
result = ""
if paragraph.elements is None:
return ""
for element in paragraph.elements:
if element.textRun is None:
continue
if element.textRun.content is None:
continue
result += element.textRun.content
# リストの場合
if paragraph.bullet:
result = f" - {result}"
# heddingの場合
if paragraph.paragraphStyle and paragraph.paragraphStyle.namedStyleType:
match paragraph.paragraphStyle.namedStyleType:
case NamedStyleType.HEADING_1:
result = f"# {result}"
case NamedStyleType.HEADING_2:
result = f"## {result}"
case NamedStyleType.HEADING_3:
result = f"### {result}"
case NamedStyleType.HEADING_4:
result = f"#### {result}"
case NamedStyleType.HEADING_5:
result = f"##### {result}"
case NamedStyleType.HEADING_6:
result = f"###### {result}"
case _:
pass
# インデントの反映
if (
paragraph.paragraphStyle
and paragraph.paragraphStyle.indentStart
and paragraph.paragraphStyle.indentStart.magnitude
):
BASE_INDENT_SIZE = 18
indent_start = int(paragraph.paragraphStyle.indentStart.magnitude)
indent_depth = indent_start // BASE_INDENT_SIZE
result = f"{' ' * (indent_depth)}{result}"
return result.replace("\n", "")
def table_to_str(table: Table):
if table.tableRows is None:
return ""
table_data: list[list[str]] = []
for row in table.tableRows:
if row.tableCells is None:
continue
row_data: list[str] = []
for cell in row.tableCells:
cell_str = ""
if cell.content is None:
continue
for content in cell.content:
if content.paragraph:
cell_str += paragraph_to_str(content.paragraph)
row_data.append(cell_str.replace("\n", ""))
table_data.append(row_data)
return "\n".join([" | ".join(row) for row in table_data])
使ってみる
このプログラムの基本設計書を書いてもらいました。
このプログラムの基本設計書をGoogle Documentに記述してください。まずは、全体の構造を取得して、章立てを作るところから始めてください。
上記のようなプロントで開始し、全体を作らせながら各章を次のように詳細化していきます。
実際のプログラムの構造も探索しながらより詳細化していってください
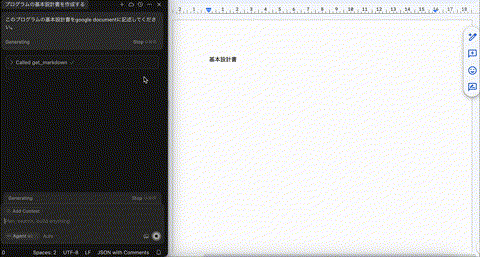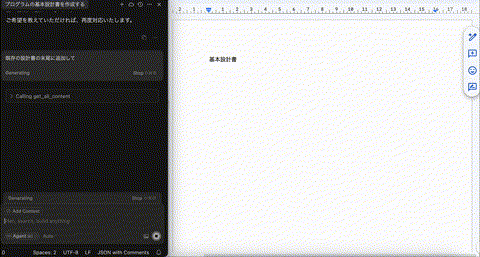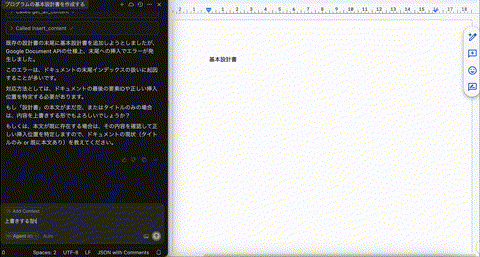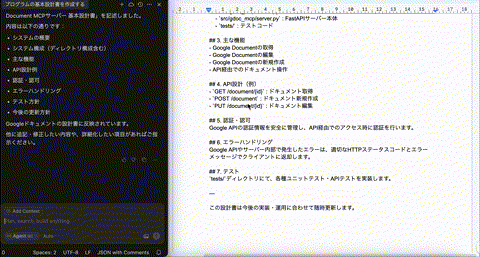
これを繰り返すことで、ある程度人間が方向性を指示しながらドキュメントを作り上げることができました。
ただ、品質的には、うーーん、という感じでした。ちょろっとプロンプトを書けば梃子のように文量・情報量が増えて記載されるのは体験としてとても良いのですが、プロジェクトの実行方法などのソースから判断できない情報から生じるハルシネーションがまだ多いです。これはrulesの整備で解決すべき問題ですね。
また、それ以上に根本的な問題として、テーブルやリストなどを単純に文字列として描画してしまうため、人間にとっての視認性がとても悪いです。純粋にエンジニアリングで解決できる問題ではあるのですが、Google Documentを無理やり使うのはデータの構造が違いすぎるので限界がありそうです。結局、現時点ではエージェントにコミット/プッシュ権限を与えて、GitHubでドキュメント管理する(非エンジニアは頑張ってGitHubを使ってもらう、、)という所が現実的なのかもしれません。
終わりに
ドキュメントを構造的に分割し、局所的に処理していくことで、大規模なドキュメントライティングをLLMで実行しやすくなりました。一方で、単純な文字列のままであると視認性が悪く、実用にはまだまだ課題がありそうです。マークダウンを基準とした、複数の人間とAIエージェントが協調してドキュメントをかける仕組みの必要性を感じました。LLMネイティブなドキュメントツールがあっても良さそうだと思いました。
株式会社エムニではAI駆動経営をともに進めていくメンバーを募集しています。
組織が100人を超え、全体の最適化を意識し始めたフェーズなので、AIを使った業務効率化のアイデアはたくさんありますが、実現するエンジニアが足りていないという状況です。生成AIを使ったアプリケーション開発に興味ある方はぜひカジュアル面談からお声がけください!
エントリーはこちらから

Discussion