つよつよ設定のfail2banでbanしたipたちを見ていく
前置き
こんにちは。
大体1年前の9月初めごろ、自宅鯖にfail2banを導入しました。
鯖に来た不正アクセスをipbanしてくれる優れものです。
今回は、こいつでbanされたipを見ていこうと思います。
設定
1年前にした設定はこちら
[DEFAULT]
# 1週間以内に2回不審なアクセスがあったら1年ban
bantime = 31536000
findtime = 604800
maxretry = 3
backend = auto
# SSHのアクセスに対する設定
[sshd]
enabled = true
banaction = firewallcmd-ipset
sshのみの設定です。
面白いですね(小並感)
私自身ipでログインすることはほとんどなく、tailscaleかcockpit経由でアクセスすることがほとんどなので、純粋な(?)不正アクセスをしてきたipを1年分収集できました。
(実際のアクセスログについては、当時、ログの保持設定をしていなかったため存在しません。惜しいことをしました。)
収集期間
実際の収集期間は2023/09/02~2024/12/15です。
設定期間が1年なのに対して、実際は15ヶ月放置していました。
なので最初の3ヶ月分のipのデータが消失しています。
が、直近1週間のアクセスログを見る限り、unbanが約500件なのに対して新規banが約500件なので、これは誤差とします()
収集結果
設定して最初の数日かの画像が残っていました。
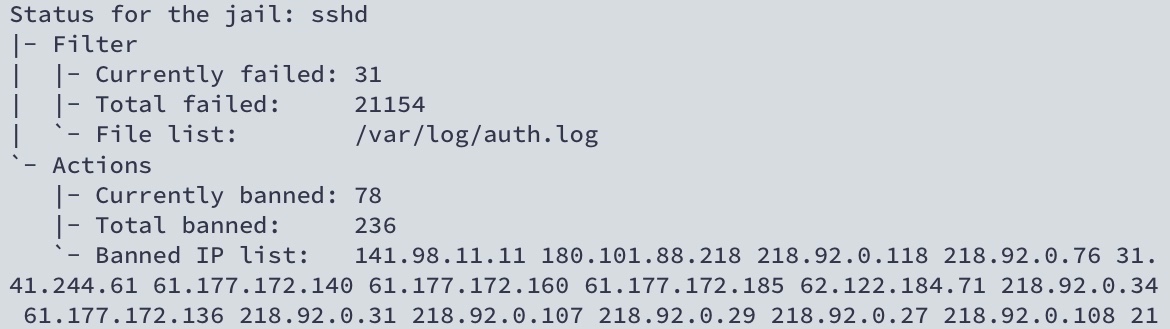
この時点で相当なアクセスが来ていますね。
これが1年後にはこうです。

流石に何回か再起動しているのでtotal failed(fail2banを起動してからの不正アクセス数)の数はそんなにですが、banip数は結構ありますね。
ipをまとめていく
整理しやすいようにまとめたいのですが、約2万個のipを1個ずつ調べていくのは流石に骨が折れます。
また、どこかしらのapiを使うにしてもこの量は流石にDosレベルです。
なので、ipinfoさんの出してるip,asn,countryリストセット[1]を使って整理していきましょう。
ipとasnと国名がセットになったcsvファイルです。
私はプログラミング言語をまだ何も書けないので、まとめるのはchatGPTに全部任せます。
最近のAIは本当にすごいですね。
データをあれこれまとめて一つのファイルにしてみました。
ipレンジごとにipをまとめています。
まとめるのに使ったコードたちは下の方に置いてます。
gist > ipdata.txt
調査結果
お待たせしました。発表のお時間です。
まずは、属性ごとに1~5位を発表していきましょう。
国別アクセスip数
country_name,Count
China,4906
United States,2653
Singapore,1882
Germany,1157
India,1088
...
堂々の1位に輝いたのは中国です。2位のアメリカと大体2倍差はすごいですね。
国名は大体そうだろうなっていう面子で並んでますね。
ドイツが4位に来ているのは少し意外です。
asnごとのアクセスip数
asn,Count
AS14061,2418
AS132203,2269
AS45090,1265
AS4134,772
AS45102,552
...
as_name,Count
"DigitalOcean, LLC",2418
"Tencent Building, Kejizhongyi Avenue",2269
Shenzhen Tencent Computer Systems Company Limited,1265
CHINANET-BACKBONE,772
"Alibaba (US) Technology Co., Ltd.",552
...
1位に輝いたのはAS14061、DigitalOcean社のVPSからですね。
2位はAS132203、tencent社のクラウドサービスですかね。
3位もtencent社、4位はchina telecom社のバックボーン、5位はalibaba cloudのクラウドサービスからでした。
vpsやクラウドサービスからのアクセスが多いです。
当然っちゃ当然ですかね。
asnに紐付いたドメイン[2]ごとのアクセスip数
as_domain,Count
tencent.com,3534
digitalocean.com,2418
chinatelecom.com.cn,1126
chinatelecom.cn,798
alibabagroup.com,786
1位はtencent社でした。
こうして見ると上位の面子はほとんど変わりません。
ここからは、日本を重点的に見ていきましょう。
いろいろ書いてある行の下の数字がipの数です。
日本のipのみを抽出
43.163.192.0,43.163.255.255,JP,Japan,AS,Asia,AS132203,"Tencent Building, Kejizhongyi Avenue",tencent.com
203
43.153.128.0,43.153.191.255,JP,Japan,AS,Asia,AS132203,"Tencent Building, Kejizhongyi Avenue",tencent.com
77
150.109.192.0,150.109.207.255,JP,Japan,AS,Asia,AS132203,"Tencent Building, Kejizhongyi Avenue",tencent.com
28
43.133.160.0,43.133.223.255,JP,Japan,AS,Asia,AS132203,"Tencent Building, Kejizhongyi Avenue",tencent.com
26
124.156.208.0,124.156.239.255,JP,Japan,AS,Asia,AS132203,"Tencent Building, Kejizhongyi Avenue",tencent.com
25
...
見事に上位はtencent社のasnで締められています。()
ちなみに1~6、10、16位は全てtencent社です。
日本かつ日本企業の所有するipのみを抽出
160.251.128.0,160.251.255.255,JP,Japan,AS,Asia,AS58791,"GMO Internet Group, Inc.",gmo.jp
14
163.44.96.0,163.44.127.255,JP,Japan,AS,Asia,AS58791,"GMO Internet Group, Inc.",gmo.jp
5
133.18.0.0,133.18.255.255,JP,Japan,AS,Asia,AS24282,KAGOYA JAPAN Inc.,kagoya.com
4
157.7.36.0,157.7.255.255,JP,Japan,AS,Asia,AS7506,"GMO Internet Group, Inc.",gmo.jp
4
162.43.0.0,162.43.127.255,JP,Japan,AS,Asia,AS131965,Xserver Inc.,xserver.co.jp
4
124.44.0.0,124.45.255.255,JP,Japan,AS,Asia,AS9595,NTT-ME Corporation,ntt-me.co.jp
3
...
こうしてみると国内vps、クラウドサービスからもそこそこアクセスがありますね。
これ以外には、さくらインターネット、Sony、Softbank、KDDI、IIJ、jpnicなどからもちらほら来ています。
まじで眺めてるだけで面白い。
まとめ
やっぱりこうやって普段意識していないデータを数値化してみると、いかに見えないところでいろいろやられてるかがはっきりわかりますね。
ファイアーウォールのありがたみを身に染みて感じられました。
これを機に、皆さんも自宅サーバーのセキュリティを見直してみてはいかがでしょうか。
私はban期間を1年から2年に増やしました。()
さすがにまずいのでグローバルからのアクセスを遮断しました。
コマンドと生成してもらったコードたち
使用したファイル等はgithubにまとめました。
今回は全てpythonで作ってもらいました。
ipをオクテットごとに並び替え
import re
import csv
# 入力ファイルと出力ファイルのパスを指定します
input_file = "log.txt" # IPアドレスが含まれるテキストファイル
output_file = "output1.csv" # 抽出されたIPアドレスを書き込むCSVファイル
# IPアドレスの正規表現
ip_pattern = r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b"
def extract_ips_from_file(input_file):
"""
指定したファイルからIPアドレスを抽出します。
"""
with open(input_file, 'r', encoding='utf-8') as file:
content = file.read()
return re.findall(ip_pattern, content)
def write_ips_to_csv(ips, output_file):
"""
抽出したIPアドレスをCSVファイルに書き込みます。
"""
with open(output_file, 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(["IP Address"])
for ip in ips:
csv_writer.writerow([ip])
def main():
# テキストファイルからIPアドレスを抽出
ips = extract_ips_from_file(input_file)
# 重複を除外してオクテッドごとにソート
unique_ips = sorted(set(ips), key=lambda ip: list(map(int, ip.split('.'))))
# 抽出したIPアドレスをCSVに出力
write_ips_to_csv(unique_ips, output_file)
print(f"{len(unique_ips)}個のIPアドレスを'{output_file}'に書き込みました。")
if __name__ == "__main__":
main()
ipinfoから得たデータを整理
import csv
import ipaddress
# 入力ファイルと出力ファイルのパス
input_file = "country_asn.csv" # 元のCSVファイル
output_file = "output2.csv" # IPv4のみを含むCSVファイル
def filter_ipv4_rows(input_file, output_file):
"""
IPv6アドレスを含む行を削除し、IPv4アドレスのみを保持する。
"""
with open(input_file, 'r', encoding='utf-8') as infile, open(output_file, 'w', newline='', encoding='utf-8') as outfile:
csv_reader = csv.reader(infile)
csv_writer = csv.writer(outfile)
# ヘッダー行を処理
header = next(csv_reader)
csv_writer.writerow(header)
# 各行を処理
for row in csv_reader:
try:
# start_ipの列をチェック
ip = ipaddress.ip_address(row[0])
if isinstance(ip, ipaddress.IPv4Address):
csv_writer.writerow(row)
except ValueError:
# IPアドレスとして認識できない場合は無視
continue
def main():
filter_ipv4_rows(input_file, output_file)
print(f"IPv4のみのデータを'{output_file}'に出力しました。")
if __name__ == "__main__":
main()
ipinfoから得たデータとipデータを結合し、並び替え
import csv
import ipaddress
from bisect import bisect_left, bisect_right
# 入力ファイルと出力ファイルのパス
ipinfo_file = "output1.csv" # IP範囲情報が含まれるCSVファイル
iplist_file = "output2.csv" # 単一のIPアドレスが含まれるCSVファイル
output_file = "end.csv" # 結合された結果を書き込むCSVファイル
def ip_to_int(ip):
"""
IPアドレスを整数に変換する(高速な比較のため)。
"""
return int(ipaddress.ip_address(ip))
def merge_ipinfo_and_iplist(ipinfo_file, iplist_file, output_file):
"""
IP範囲情報と単一IPアドレスを結合し、新しいファイルに出力する。
範囲内にIPが一つもない行は削除する。
"""
with open(ipinfo_file, 'r', encoding='utf-8') as ipinfo, open(iplist_file, 'r', encoding='utf-8') as iplist, open(output_file, 'w', newline='', encoding='utf-8') as outfile:
ipinfo_reader = csv.reader(ipinfo)
iplist_reader = csv.reader(iplist)
output_writer = csv.writer(outfile)
# IPリストを整数リストとしてソート
ip_set = sorted(ip_to_int(row[0]) for row in iplist_reader if row)
# IP範囲ごとに対応するIPを挿入
for ipinfo_row in ipinfo_reader:
if len(ipinfo_row) == 0 or ipinfo_row[0] == "start_ip": # 空行やヘッダーをスキップ
continue
start_ip, end_ip = ip_to_int(ipinfo_row[0]), ip_to_int(ipinfo_row[1])
# 二分探索で範囲内のIPを取得
start_idx = bisect_left(ip_set, start_ip)
end_idx = bisect_right(ip_set, end_ip)
matching_ips = ip_set[start_idx:end_idx]
# ログ出力: 範囲情報と一致するIP
print(f"Checking range {ipinfo_row[0]} - {ipinfo_row[1]}, found {len(matching_ips)} matching IPs.")
# 対応するIPがない場合はスキップ
if not matching_ips:
print(f"No matching IPs for range {ipinfo_row[0]} - {ipinfo_row[1]}, skipping.")
continue
# IP範囲を出力
output_writer.writerow(ipinfo_row)
print(f"Writing range: {ipinfo_row}")
# 対応するIPを出力
for ip in matching_ips:
output_writer.writerow([ipaddress.ip_address(ip)])
print(f"Writing IP: {ipaddress.ip_address(ip)}")
# 空行を挿入
output_writer.writerow([])
print("Adding empty line after range.")
def main():
merge_ipinfo_and_iplist(ipinfo_file, iplist_file, output_file)
print(f"'{ipinfo_file}'と'{iplist_file}'を結合して'{output_file}'に出力しました。")
if __name__ == "__main__":
main()
属性ごとに行数抜き出し
python extract.py 属性 end.csv 生成ファイル
import csv
import sys
from collections import defaultdict
def extract_information(input_file, category, output_file=None):
"""
指定したカテゴリごとにIPの行数を集計する。
Args:
input_file (str): 入力CSVファイル名。
category (str): 抜き出すカテゴリ名 (例: country_name, continent_name, asn, as_name, as_domain)。
output_file (str, optional): 出力CSVファイル名。指定しない場合はコンソールに出力。
"""
category_index = {
"country_name": 3,
"continent_name": 5,
"asn": 6,
"as_name": 7,
"as_domain": 8,
}
if category not in category_index:
print(f"エラー: 無効なカテゴリ '{category}' が指定されました。")
return
index = category_index[category]
counts = defaultdict(int)
with open(input_file, 'r', encoding='utf-8') as infile:
reader = csv.reader(infile)
current_category = None
for row in reader:
if len(row) == 0: # 空行は範囲の区切り
current_category = None
continue
if current_category is None: # 範囲のヘッダー行
current_category = row[index]
else: # IPアドレス行
counts[current_category] += 1
# 結果の出力
if output_file:
with open(output_file, 'w', encoding='utf-8', newline='') as outfile:
writer = csv.writer(outfile)
writer.writerow([category, "Count"])
for key, count in sorted(counts.items(), key=lambda x: x[1], reverse=True):
writer.writerow([key, count])
print(f"結果が'{output_file}'に出力されました。")
else:
print(f"{category.capitalize()}\tCount")
for key, count in sorted(counts.items(), key=lambda x: x[1], reverse=True):
print(f"{key}\t{count}")
if __name__ == "__main__":
if len(sys.argv) < 3:
print("使用方法: python extract.py <category> <input_file> [output_file]")
print("カテゴリは以下から選択してください: country_name, continent_name, asn, as_name, as_domain")
else:
category = sys.argv[1]
input_file = sys.argv[2]
output_file = sys.argv[3] if len(sys.argv) > 3 else None
extract_information(input_file, category, output_file)
属性別に抽出
python extract2.py 属性 データ end.csv 生成ファイル
import csv
import sys
from collections import defaultdict
def extract_and_list_information(input_file, category, value, output_file=None):
"""
指定したカテゴリと値に基づいてIP範囲と行数を抽出し、結果を出力する。
Args:
input_file (str): 入力CSVファイル名。
category (str): 抽出対象カテゴリ (例: country_name, continent_name, asn, as_name, as_domain)。
value (str): カテゴリ内の特定の値 (例: "Japan")。
output_file (str, optional): 出力CSVファイル名。指定しない場合はコンソールに出力。
"""
category_index = {
"country_name": 3,
"continent_name": 5,
"asn": 6,
"as_name": 7,
"as_domain": 8,
}
if category not in category_index:
print(f"エラー: 無効なカテゴリ '{category}' が指定されました。")
return
index = category_index[category]
results = []
total_count = 0
with open(input_file, 'r', encoding='utf-8') as infile:
reader = csv.reader(infile)
current_range = None
ip_list = []
count = 0
for row in reader:
if len(row) == 0: # 空行で範囲を終了
if current_range and current_range[index] == value:
results.append((current_range, count, ip_list))
total_count += count
current_range = None
ip_list = []
count = 0
continue
if current_range is None: # 範囲のヘッダー行
current_range = row
else: # IPアドレス行
if current_range[index] == value:
ip_list.append(row[0])
count += 1
if current_range and current_range[index] == value: # 最後の範囲を確認
results.append((current_range, count, ip_list))
total_count += count
# 結果の出力
if output_file:
with open(output_file, 'w', encoding='utf-8', newline='') as outfile:
writer = csv.writer(outfile)
writer.writerow([value])
writer.writerow(["Total Count", total_count])
writer.writerow([])
for current_range, count, ip_list in results:
writer.writerow(current_range)
writer.writerow([count])
for ip in ip_list:
writer.writerow([ip])
writer.writerow([])
print(f"結果が'{output_file}'に出力されました。")
else:
print(value)
print(f"Total Count: {total_count}\n")
for current_range, count, ip_list in results:
print(",".join(current_range))
print(count)
for ip in ip_list:
print(ip)
print()
if __name__ == "__main__":
if len(sys.argv) < 4:
print("使用方法: python extract2.py <category> <value> <input_file> [output_file]")
print("カテゴリは以下から選択してください: country_name, continent_name, asn, as_name, as_domain")
else:
category = sys.argv[1]
value = sys.argv[2]
input_file = sys.argv[3]
output_file = sys.argv[4] if len(sys.argv) > 4 else None
extract_and_list_information(input_file, category, value, output_file)
参考、出典
-
アカウント作成必須:https://ipinfo.io/account/data-downloads ↩︎
-
あんまりよくわかってないので誰か教えてください。 ↩︎
Discussion