TeamsからChatGPTを使えるアプリを作ってみた
概要
社内(事業会社)でChatGPTを使用してみたいという声があったので、社内で使用しているTeamsからChatGPTを使えるようにアプリを試作してみた。
使用技術の検討
- 極力お金をかけない(実験的に限定された範囲で使用するため)
- 極力AWSを使用する。(社内でAWSを既に使用しているため。オンプレネットワークもAWSをDirectConnectで接続済み。)
- とは言っても、どうしてもという場合は他社クラウドも使用可
という条件の下、今回は以下のような構成で作成した。

LambdaはPython 3.10を使用して作成。DynamoDBは会話の履歴を保持するために利用。
当初、AzureのBot Serviceは使用する予定がなく、TeamsのOutgoing Webhookを使用して作成し、AWSで完結させる予定だった。しかし、Outgoing Webhookは以下のような欠点があるため採用しなかった。
- 5秒以内にレスポンスを返す必要がある。(ChatGPTにリクエストを投げてレスポンスが返ってくるまで大体5秒以上かかるので致命的。)
- Teamに対しての作成となるうえに、スコープがTeamとなるため、Team毎にOutgoing Webhookを作成する必要がある。(配布に向かない。Bot Serviceを使用するとTeamsアプリとして配布できるためマニュアルさえあればエンドユーザーが自身で導入できる。)
- Outgoing Webhookを呼び出すにはメンション(@を付けて会話をする)が必要。
(エンドユーザーはITリテラシーが高い人ばかりではない。メンションを忘れて投稿し、うまく動かないという人にも使ってもらうこと想定。)
Bot Serviceの使用はTeamsとAPI Gateway間の橋渡しのみとした。ChatGPTからのレスポンスをTeamsに投稿するのは、TeamsのAPIをLambdaから呼ぶようにした。
構築手順
AWS
AWS SAMアプリケーションとしてデプロイする。
(Lambdaのコードは別途掲載。SAMのインストール方法は割愛。)
gitからソースをCloneした後、以下のコマンドでAWSにデプロイする。
cd callgptapi # template.yamlがあるディレクトリに移動する。
sam build
sam deploy --region ap-northeast-1 # 東京リージョンにデプロイ。
ちなみに、template.yamlの中身は以下の通り。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
callgptapi
Sample SAM Template for callgptapi
Globals:
Function:
Timeout: 30
MemorySize: 128
Resources:
Table:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: ConversationId
Type: String
TableName: ConversationTable
CallGPTAPIFunctionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- lambda.amazonaws.com
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: CallGPTAPIFunctionPolicies
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- dynamodb:List*
- dynamodb:DescribeReservedCapacity*
- dynamodb:DescribeLimits
- dynamodb:DescribeTimeToLive
- kms:Decrypt
- ssm:GetParameter
Resource: "*"
- Effect: Allow
Action:
- dynamodb:BatchGet*
- dynamodb:Get*
- dynamodb:Query
- dynamodb:Scan
- dynamodb:BatchWrite*
- dynamodb:Delete*
- dynamodb:Update*
- dynamodb:PutItem
Resource: !GetAtt Table.Arn
CallGPTAPIFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: callgptapi/
Handler: app.lambda_handler
Runtime: python3.10
Timeout: 60
Architectures:
- x86_64
Role: !GetAtt CallGPTAPIFunctionRole.Arn
Layers:
- arn:aws:lambda:ap-northeast-1:133490724326:layer:AWS-Parameters-and-Secrets-Lambda-Extension:4
Events:
CallGPTAPI:
Type: Api
Properties:
Path: /callgptapi
Method: post
CallGPTAPIFunctionLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/${CallGPTAPIFunction}
RetentionInDays: 14
Outputs:
CallGPTAPIApi:
Description: "API Gateway endpoint URL for Prod stage for CallGPTAPIFunction"
Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/callgptapi"
CallGPTAPIFunction:
Description: "CallGPTAPI Lambda Function ARN"
Value: !GetAtt CallGPTAPIFunction.Arn
CallGPTAPIFunctionIamRole:
Description: "Implicit IAM Role created for CallGPTAPI function"
Value: !GetAtt CallGPTAPIFunctionRole.Arn
API GatewayのURLは後程Azure Bot Serviceに登録するので控えておく。
Azure Bot Service
Bot Serviceの作成
Azure PortalからBot Serviceを検索して作成を押す。
Azure Botを選択。(下の方まで読み込まないと出てこないので注意。)
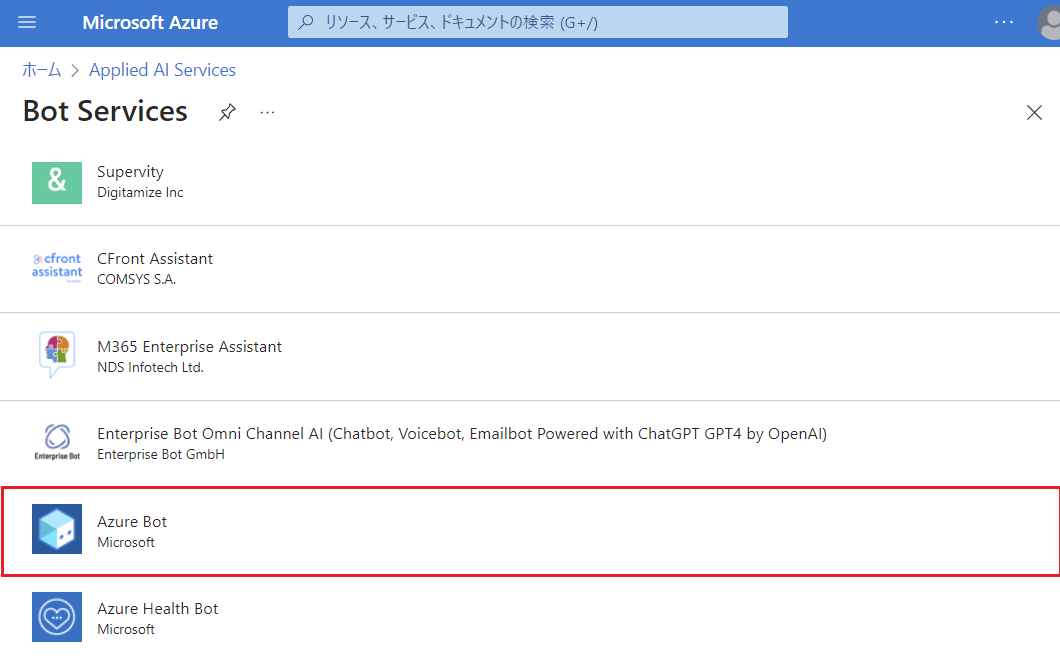
作成ボタンを押す。
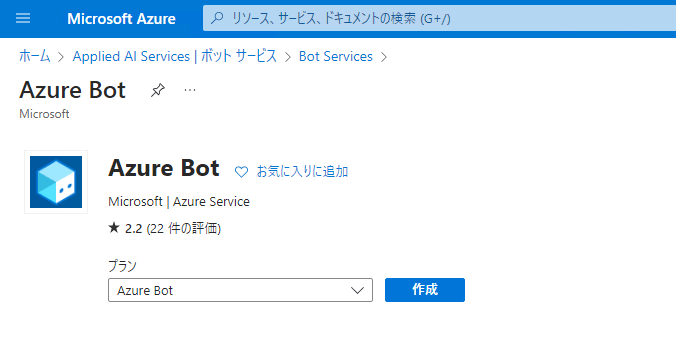
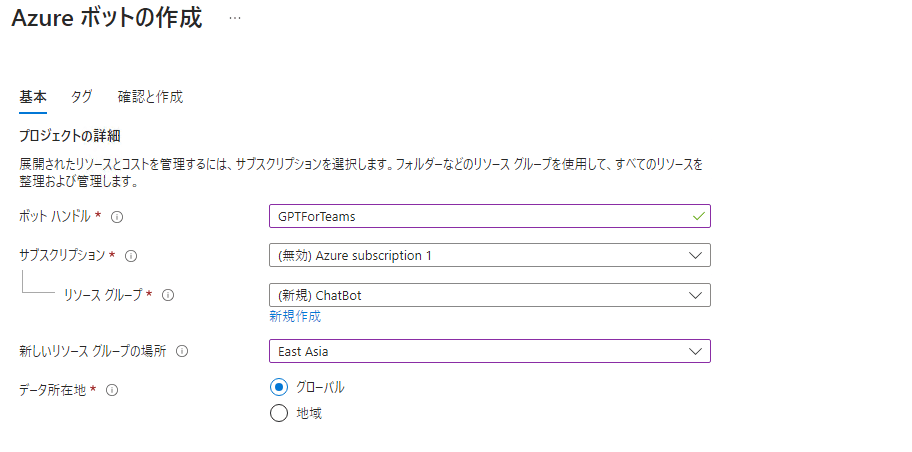
以下のように設定。(設定は適宜変更する。)
価格はFreeを選択。
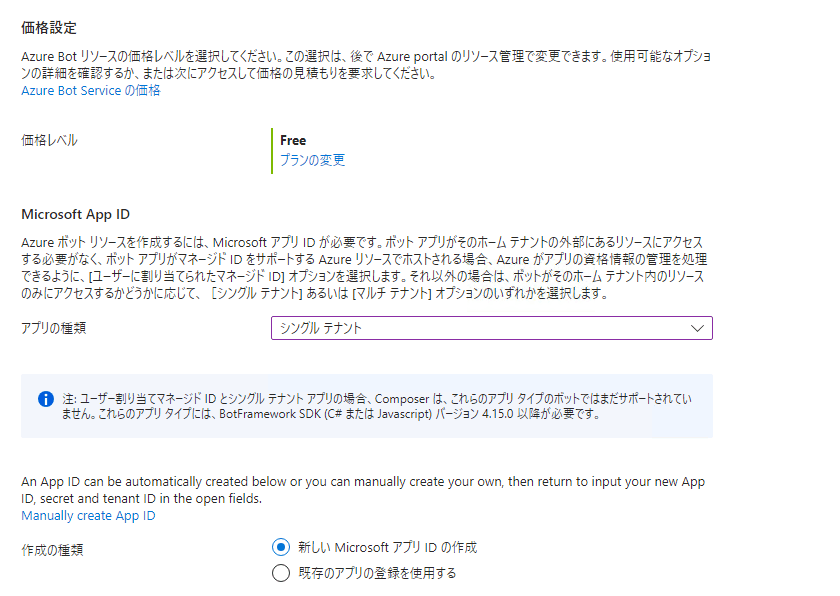
作成を押す。

Channelの設定
- メッセージングエンドポイントの作成。
画面左側の構成をクリック。
メッセージングエンドポイントにAWS側のAPI GatewayのURLを入力する。
これでTeamsにメッセージを入力した場合、Bot Serviceが指定したURLのAPIを呼び出すようになる。

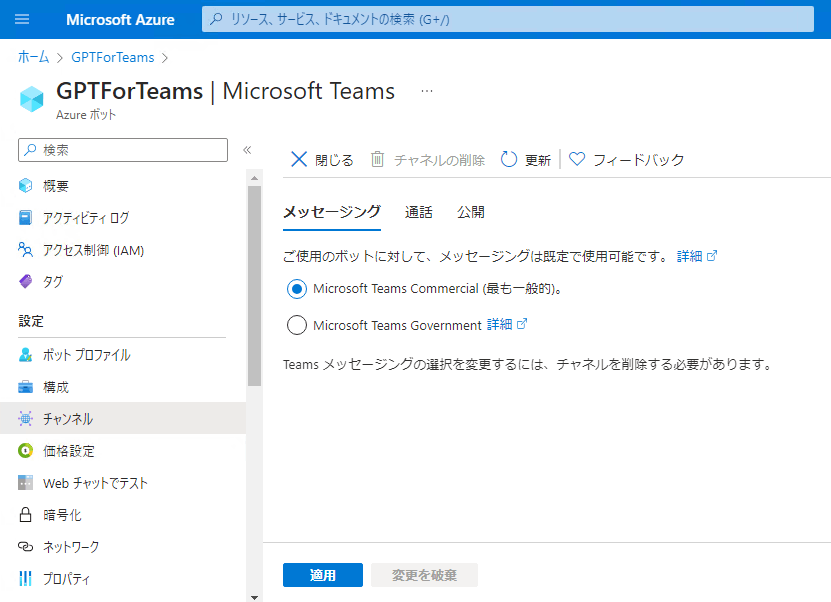
- チャンネルにTeamsを追加する。
画面左側のチャンネルをクリック。

使用可能なチャンネルの中からMicrosoft Teamsを選択。

Microsoft Teams Commercialを選択して適用。
Teamsアプリ
TeamsとAzureのBot Serviceを紐づけるためのアプリを作成する。
ユーザーはこのアプリをインストールして会話することで、ChatGPTと会話する仕組み。
(Teamsアプリ→Azure Bot Service→AWS APIGateway(Lambda)→ChatGPTと会話データが転送される。)
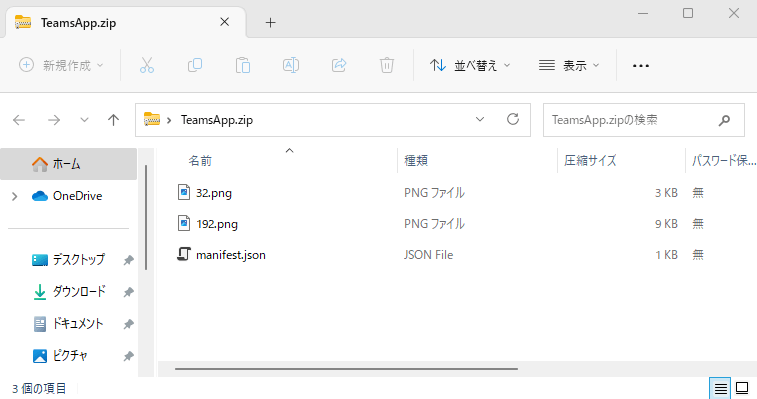
Teamsアプリを作成する際に用意するのは次の3つのファイル。
- manifest.json
- アイコンファイル小(pngファイル。32pixel * 32pixelのもの)
- アイコンファイル大(pngファイル。192pixel * 192pixelのもの)
この3つのファイルをzipで圧縮して一つのファイルにする。
manifest.jsonについては以下の通り。
{
"$schema": "https://developer.microsoft.com/json-schemas/teams/v1.15/MicrosoftTeams.schema.json",
"manifestVersion": "1.15",
"version": "1.0.0",
"id": "【Azure Bot ServiceのMicrosoft App IDを設定】",
"developer": {
"name": "em8215",
"websiteUrl": "https://zenn.dev/em8215",
"privacyUrl": "https://example.com/privacy",
"termsOfUseUrl": "https://example.com/app-tos"
},
"name": {
"short": "GPTForTeams"
},
"description": {
"short": "GPTForTeams",
"full": "Bot Talking with ChatGPT for teams."
},
"icons": {
"outline": "32.png",
"color": "192.png"
},
"accentColor": "#FF4749",
"bots": [
{
"botId": "【Azure Bot ServiceのMicrosoft App IDを設定】",
"scopes": [
"team",
"personal",
"groupchat"
],
"needsChannelSelector": false,
"isNotificationOnly": false,
"supportsFiles": false,
"supportsCalling": false,
"supportsVideo": false
}
],
"permissions": [
"identity",
"messageTeamMembers"
],
"devicePermissions": [
"notifications"
],
"validDomains": [
"crediai.com"
],
"defaultInstallScope": "team",
"defaultGroupCapability": {
"team": "bot",
"groupchat": "bot"
}
}
iconsのoutlineとcolorにはそれぞれ、アイコンファイル小、アイコンファイル大のファイル名を設定する。(ディレクトリパスは不要。)
idとbot idはBot ServiceのMicrosoft App IDを設定する。以下の画面で確認できる。

このmanifest.jsonの仕様は以下を参照。
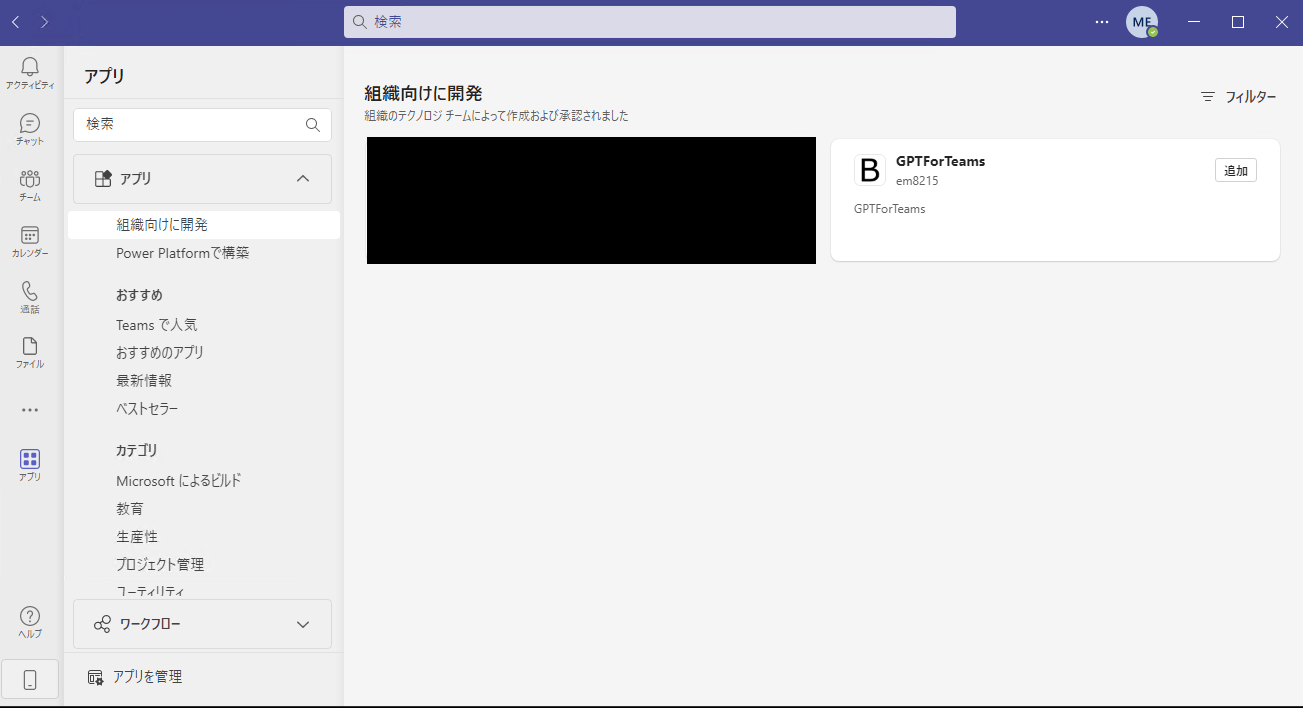
TeamsアプリとしてTeamsに登録する。
Teamsに管理者のユーザーでログインして、アプリ→アプリをアップロード→組織のアプリカタログにアプリをアップロードしますを選択し、TeamsApp.zipを選択する。

無事追加されると、以下のようにアプリが追加される。
また、追加された後は1時間くらい待つことをお勧めする。
追加された直後はアプリを使用しようとしても見つかりません等のメッセージが出ることがあった。
AWS Parameter Storeにパラメータを登録
以下の情報をAWSのParameter Storeに登録する。
| Key | 種類 | 値 | 備考 |
|---|---|---|---|
| /callgptapi/AZURE_CLIENT_ID | String | xxx | Bot ServiceのMicrosoft AppIDを設定 |
| /callgptapi/AZURE_CLIENT_SECRET | SecureString | xxx | Bot Serviceのクライアントシークレットの値を設定 |
| /callgptapi/AZURE_TENANT_ID | String | xxx | Bot Serviceのアプリ テナントIDを設定 |
| /callgptapi/CHATGPT_API_KEY | SecureString | xxx | OpenAIのAPIキーを設定 |
| /callgptapi/CHATGPT_MODEL | String | gpt-3.5-turbo-0613 | ChatGPTの使用Model |
| /callgptapi/CHATGPT_NUMBER_OF_MAX_PROMPT_HISTORY | String | 10 | ChatGPTにリクエストを投げる際のプロンプト作成時の履歴遡り数 |
/callgptapi/AZURE_CLIENT_ID、/callgptapi/AZURE_TENANT_IDは以下から情報を取得
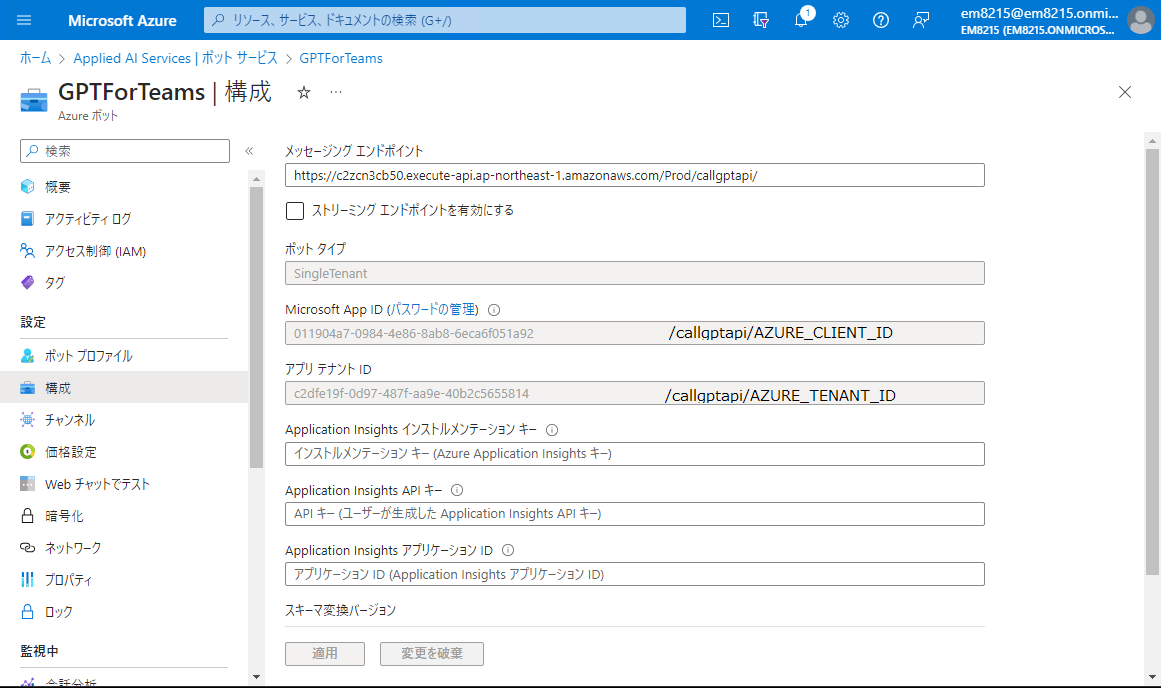
/callgptapi/AZURE_CLIENT_SECRETは上記の画面からパスワードの管理を押して、新しいクラインとシークレットを作成してから、「値」に表示されているキーを設定する。


Lambdaのコード
LambdaはPython3.10を使用。
基本的な処理流れ
- Bot ServiceからのActivity(Teamsの投稿内容)のIDをキーにDynamoDBに保存してある会話の履歴を取得する。
- 会話の履歴をもとにプロンプトを作成して、ChatGPTのAPIにリクエストを投げる。
この時、ChatGPTのAPIは状態を持っていないため、過去の会話の情報も遡ってプロンプトとして作成してリクエストを投げる。(遡る会話数はParameter Storeに保持) - ChatGPTからのレスポンスをTeamsに返信
- Teamsの投稿内容とChatGPTからのレスポンスをDynamoDBに保存
DynamoDBの定義
- ConversationTable
| 項目名(論理) | 項目名(物理) | 型 | 備考 |
|---|---|---|---|
| 会話ID | conversation_id | string | Partition Key |
| 会話アイテム | conversation_items | List[ConversationItem] | この項目の定義は別途参照 |
- ConversationItem
| 項目名(論理) | 項目名(物理) | 型 | 備考 |
|---|---|---|---|
| 会話内容 | content | string | |
| 会話シーケンス | seq | int | 1~の連番 |
| 役割 | role | string | system, user, assistant のどれか。 |
| 応答トークン | completion_token | int | ChatGPTの応答トークン数 |
| プロンプトトークン | prompt_token | int | プロンプトのトークン数 |
| 会話日時 | content_at | string | 会話発生日時(yyyy/mm/dd hh:mm:ss) |
| プロンプト | prompt | List[PromptItem] | この項目の定義は別途参照 |
- PromptItem
| 項目名(論理) | 項目名(物理) | 型 | 備考 |
|---|---|---|---|
| 会話内容 | content | string | |
| 会話シーケンス | seq | int | 1~の連番 |
| 役割 | role | string | system, user, assistant のどれか。 |
Bot Serviceからのデータ
Azure Bot ServiceからAWS API Gateway経由でLambdaに渡されるデータは以下のようなデータ。
(Teamsから「How are you?」をチャットで入力した場合。)
{
"resource":"/callgptapi",
"path":"/callgptapi/",
"httpMethod":"POST",
"headers":{
"Authorization":"Bearer xxxx",
"CloudFront-Forwarded-Proto":"https",
"CloudFront-Is-Desktop-Viewer":"true",
"CloudFront-Is-Mobile-Viewer":"false",
"CloudFront-Is-SmartTV-Viewer":"false",
"CloudFront-Is-Tablet-Viewer":"false",
"CloudFront-Viewer-ASN":"8075",
"CloudFront-Viewer-Country":"JP",
"Content-Type":"application/json; charset=utf-8",
"Host":"xxxxxx.execute-api.ap-northeast-1.amazonaws.com",
"MS-CV":"y5u+G2QMHU2+PYOAUvdc5A.1.1.1.1413547582.1.2",
"User-Agent":"Microsoft-SkypeBotApi (Microsoft-BotFramework/3.0)",
"Via":"1.1 3a7ba6126d80753b7016dac95efbb35c.cloudfront.net (CloudFront)",
"X-Amz-Cf-Id":"nJ7dfTf6bLx51NpOl2g_qyTYOSQtsZP6wIoZhUsnucgWWPLxJlx1Gg==",
"X-Amzn-Trace-Id":"Root=1-64b62a6e-513e921a4f2b2e5c24fd7c75",
"X-Forwarded-For":"xx.xx.xx.xx, xx.xx.xx.xx",
"X-Forwarded-Port":"443",
"X-Forwarded-Proto":"https",
"x-ms-conversation-id":"a:1EsRmK8bIsO2Ifl6UYrW0T7c8CBj6T8zF5xpGiGhE8cnMwgAMGzks4Aj9goHo73-2Dq3luvEKx5ocbTCE6hAs0h3Vv_mmM9Sm0ZncbBms1cjtoky9rVIYgaAF6kL8Z8cJ",
"x-ms-tenant-id":"cxxxx"
},
"multiValueHeaders":{
"Authorization":[
"Bearer xxxx"
],
"CloudFront-Forwarded-Proto":[
"https"
],
"CloudFront-Is-Desktop-Viewer":[
"true"
],
"CloudFront-Is-Mobile-Viewer":[
"false"
],
"CloudFront-Is-SmartTV-Viewer":[
"false"
],
"CloudFront-Is-Tablet-Viewer":[
"false"
],
"CloudFront-Viewer-ASN":[
"8075"
],
"CloudFront-Viewer-Country":[
"JP"
],
"Content-Type":[
"application/json; charset=utf-8"
],
"Host":[
"xxxxxx.execute-api.ap-northeast-1.amazonaws.com"
],
"MS-CV":[
"y5u+G2QMHU2+PYOAUvdc5A.1.1.1.1413547582.1.2"
],
"User-Agent":[
"Microsoft-SkypeBotApi (Microsoft-BotFramework/3.0)"
],
"Via":[
"1.1 3a7ba6126d80753b7016dac95efbb35c.cloudfront.net (CloudFront)"
],
"X-Amz-Cf-Id":[
"nJ7dfTf6bLx51NpOl2g_qyTYOSQtsZP6wIoZhUsnucgWWPLxJlx1Gg=="
],
"X-Amzn-Trace-Id":[
"Root=1-64b62a6e-513e921a4f2b2e5c24fd7c75"
],
"X-Forwarded-For":[
"xx.xxx.xx.xx, xx.xx.xx.xxx"
],
"X-Forwarded-Port":[
"443"
],
"X-Forwarded-Proto":[
"https"
],
"x-ms-conversation-id":[
"a:xxxx"
],
"x-ms-tenant-id":[
"xxxx"
]
},
"queryStringParameters":"None",
"multiValueQueryStringParameters":"None",
"pathParameters":"None",
"stageVariables":"None",
"requestContext":{
"resourceId":"2yeg2o",
"resourcePath":"/callgptapi",
"httpMethod":"POST",
"extendedRequestId":"IPuRUFfRNjMFQNg=",
"requestTime":"18/Jul/2023:06:00:14 +0000",
"path":"/Prod/callgptapi/",
"accountId":"553132409901",
"protocol":"HTTP/1.1",
"stage":"Prod",
"domainPrefix":"c2zcn3cb50",
"requestTimeEpoch":1689660014562,
"requestId":"9485220d-4e57-4ceb-ad7e-5a576bd8f81a",
"identity":{
"cognitoIdentityPoolId":"None",
"accountId":"None",
"cognitoIdentityId":"None",
"caller":"None",
"sourceIp":"xxx.xxx.xxx.xxx",
"principalOrgId":"None",
"accessKey":"None",
"cognitoAuthenticationType":"None",
"cognitoAuthenticationProvider":"None",
"userArn":"None",
"userAgent":"Microsoft-SkypeBotApi (Microsoft-BotFramework/3.0)",
"user":"None"
},
"domainName":"xxxxxxx.execute-api.ap-northeast-1.amazonaws.com",
"apiId":"xxxxx"
},
"body":"{\"text\":\"Who are you?\",\"textFormat\":\"plain\",\"attachments\":[{\"contentType\":\"text/html\",\"content\":\"<p>Who are you?</p>\"}],\"type\":\"message\",\"timestamp\":\"2023-07-18T06:00:14.35124Z\",\"localTimestamp\":\"2023-07-18T15:00:14.35124+09:00\",\"id\":\"1689660014279\",\"channelId\":\"msteams\",\"serviceUrl\":\"https://smba.trafficmanager.net/jp/\",\"from\":{\"id\":\"29:xxxx\",\"name\":\"em8215\",\"aadObjectId\":\"4cab4dd1-a0b4-49b9-a169-2d4167d8632a\"},\"conversation\":{\"conversationType\":\"personal\",\"tenantId\":\"xxxxx\",\"id\":\"a:xxxx\"},\"recipient\":{\"id\":\"28:xxxxx\",\"name\":\"GPTForTeams\"},\"entities\":[{\"locale\":\"ja-JP\",\"country\":\"JP\",\"platform\":\"Windows\",\"timezone\":\"Asia/Tokyo\",\"type\":\"clientInfo\"}],\"channelData\":{\"tenant\":{\"id\":\"xxxx\"}},\"locale\":\"ja-JP\",\"localTimezone\":\"Asia/Tokyo\"}",
"isBase64Encoded":false
}
body部分は以下の通り。
{
"text":"Who are you?",
"textFormat":"plain",
"attachments":[
{
"contentType":"text/html",
"content":"Who are you?"
}
],
"type":"message",
"timestamp":"2023-07-18T06:00:14.35124Z",
"localTimestamp":"2023-07-18T15:00:14.35124+09:00",
"id":"xxxx",
"channelId":"msteams",
"serviceUrl":"https://smba.trafficmanager.net/jp/",
"from":{
"id":"29:xxxx",
"name":"em8215",
"aadObjectId":"xxxx"
},
"conversation":{
"conversationType":"personal",
"tenantId":"xxxx",
"id":"a:xxxx"
},
"recipient":{
"id":"28:xxxx",
"name":"GPTForTeams"
},
"entities":[
{
"locale":"ja-JP",
"country":"JP",
"platform":"Windows",
"timezone":"Asia/Tokyo",
"type":"clientInfo"
}
],
"channelData":{
"tenant":{
"id":"xxxx"
}
},
"locale":"ja-JP",
"localTimezone":"Asia/Tokyo"
}
コード
import logging
import json
import traceback
import os
import json
import azure_bot
import boto3
from conversation_data import Conversation, ConversationItem, conversation_dict_factory
import call_gpt
from dataclasses import asdict
from datetime import datetime
logger = logging.getLogger(__name__)
logger.setLevel(logging.ERROR)
def lambda_handler(event, context):
try:
# Get previous conversation from DynamoDB
event_body = json.loads(event['body'])
conversation = load_previous_conversation(event_body['conversation']['id'])
# Set the current(recieved) conversation to conversation data.
conversation.add_converstion_item(ConversationItem(content=event_body['text'],role='user'))
# Call GPT
gpt_response_conversation_item = call_gpt.send_data_to_gpt(conversation)
# Send the ChatGPT response to Teams via Azure Bot service.
azure_bot.send_message_to_teams(event_body, gpt_response_conversation_item.content)
# Set the ChatGPT response to conversation data.
conversation.add_converstion_item(gpt_response_conversation_item)
# Save conversation data to DynamoDB
save_conversation(conversation)
return {
'statusCode': 200,
'body': json.dumps({
'message': 'success',
})
}
except Exception as e:
traceback.print_exc()
azure_bot.send_message_to_teams(event_body, "Sorry, your message couldn't be processed. Please try again.")
return {
'statusCode': 500,
'body': json.dumps({
'message': 'Error ' + traceback.format_exc(),
})
}
def load_previous_conversation(conversation_id:str) -> Conversation:
''' The fuction of Load conversation from AWS DynamoDB'''
db_resource = boto3.resource('dynamodb')
table = db_resource.Table('ConversationTable')
response = table.get_item( Key={'conversation_id':conversation_id} )
if 'Item' in response:
return convert_to_conversation(response['Item'])
else:
return Conversation(id=conversation_id)
def save_conversation(conversation:Conversation):
''' The fuction of Save conversation to AWS DynamoDB'''
db_resource = boto3.resource('dynamodb')
table = db_resource.Table('ConversationTable')
# Convert from object to dict
registration_item = asdict(conversation, dict_factory=conversation_dict_factory)
res = table.put_item(Item=registration_item)
def delete_conversation(conversation:Conversation):
''' The fuction of Delete conversation from AWS DynamoDB'''
db_resource = boto3.resource('dynamodb')
table = db_resource.Table('ConversationTable')
res = table.delete_item(Key={'conversation_id':conversation.conversation_id})
def convert_to_conversation(target:dict) -> Conversation:
''' The function of to convert from Json to Conversation_data '''
converted_item = Conversation(target['conversation_id'])
for item in target['conversation_items']:
converted_item.add_converstion_item(
ConversationItem(
content = item['content'],
role = item['role'],
completion_token = item['completion_token'],
prompt_token = item['prompt_token'],
prompt = item['prompt'],
content_at = datetime.strptime(item['content_at'], '%Y/%m/%d %H:%M:%S')
)
)
return converted_item
import logging
import requests
import traceback
import json
import os
from datetime import datetime
from conversation_data import Conversation,ConversationItem,PromptItem
import parameters
logger = logging.getLogger(__name__)
logger.setLevel(logging.ERROR)
def send_data_to_gpt(conversation:Conversation)->ConversationItem:
'''Send a conversation item to ChatGPT.'''
apikey = os.environ.get('CHATGPT_API_KEY', parameters.get_encrypted_parameter('/callgptapi/CHATGPT_API_KEY'))
openai_endpoint = 'https://api.openai.com/v1/chat/completions'
system_content = ''
payload = {
'model': parameters.get_parameter('/callgptapi/CHATGPT_MODEL'),
'messages': [
{'role': 'system', 'content': system_content},
]
}
return_conversation_item = ConversationItem()
# Set system(default) prompt.
prompt_counter = 1
return_conversation_item.prompt.append(PromptItem(content=system_content,seq=prompt_counter,role='system'))
prompt_counter += 1
# Create & set prompt from convesation histories.
number_of_max_prompt = int(parameters.get_parameter('/callgptapi/CHATGPT_NUMBER_OF_MAX_PROMPT_HISTORY')) * -1
for item in conversation.conversation_items[number_of_max_prompt:]:
payload['messages'].append({'role': item.role, 'content': item.content})
return_conversation_item.prompt.append(PromptItem(content=item.content,seq=prompt_counter,role=item.role))
prompt_counter += 1
headers = {
'Content-type': 'application/json',
'Authorization': 'Bearer '+ apikey
}
try:
response = requests.post(
openai_endpoint,
data=json.dumps(payload),
headers=headers
)
response_data = response.json()
# Set the response from ChatGPT
return_conversation_item.content = response_data['choices'][0]['message']['content']
return_conversation_item.role = response_data['choices'][0]['message']['role']
return_conversation_item.completion_token = response_data['usage']['completion_tokens']
return_conversation_item.prompt_token = response_data['usage']['prompt_tokens']
return return_conversation_item
except:
logger.error(traceback.format_exc())
return traceback.format_exc()
import os
import requests
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.ERROR)
def get_parameter(parameter_name:str) -> str:
'''Get a parameter from AWS Parameter Store with Lambda extention'''
endpoint = 'http://localhost:2773/systemsmanager/parameters/get/?name={}'.format(parameter_name)
headers = {
'X-Aws-Parameters-Secrets-Token': os.environ['AWS_SESSION_TOKEN']
}
res = requests.get(endpoint, headers=headers)
return res.json()['Parameter']['Value']
def get_encrypted_parameter(parameter_name:str) -> str:
''' Get a encrypted parameter from AWS Parameter Store with Lambda extention'''
endpoint = 'http://localhost:2773/systemsmanager/parameters/get/?withDecryption=true&name={}'.format(parameter_name)
headers = {
'X-Aws-Parameters-Secrets-Token': os.environ['AWS_SESSION_TOKEN']
}
res = requests.get(endpoint, headers=headers)
return res.json()['Parameter']['Value']
from dataclasses import dataclass, field
from dataclasses_json import dataclass_json
from decimal import Decimal
from datetime import datetime
from typing import Any
from datetime import datetime
from zoneinfo import ZoneInfo
@dataclass_json
@dataclass
class PromptItem:
"""Prompt for ChatGPT"""
def __init__(self,content:str='', role:str='', seq:int=0):
self.content = content
self.role = role
self.seq = seq
content: str
"""contents"""
seq: int
"""content sequence"""
role: str
"""speaker"""
@dataclass_json
@dataclass
class ConversationItem():
"""Item of conversation"""
def __init__(self,content:str='', role:str='', completion_token:int=0, prompt_token:int=0, prompt:list[PromptItem] =[], content_at:datetime=datetime.now(ZoneInfo("Asia/Tokyo"))):
self.content = content
self.role = role
self.seq = -1 # It will be set by parent class
self.completion_token = completion_token
self.prompt_token = prompt_token
self.prompt = prompt
self.content_at = content_at
content: str
"""contents"""
seq: int
"""content sequence"""
role: str
"""speaker"""
completion_token: int
'''response token from ChatGPT'''
prompt_token: int
'''prompt token from ChatGPT'''
content_at: datetime
'''datetime of speaking'''
prompt : list[PromptItem] = field(default_factory=list)
'''prompt sending to ChatGPT'''
@dataclass_json
@dataclass
class Conversation:
"""Conversation Management Class"""
conversation_id: str
"""Conversation ID for Teams"""
conversation_items: list[ConversationItem] = field(default_factory=list)
"""History of conversation"""
def __init__(self,id:str):
self.conversation_id = id
self.conversation_items = []
def has_conversation(self):
if self.conversation_items == None:
return False
else:
return False if self.conversation_items.count() <= 0 else True
def add_converstion_item(self, item:ConversationItem):
if ConversationItem == None:
self.conversation_items = []
item.seq = self.get_next_conversation_seq()
self.conversation_items.append(item)
def get_next_conversation_seq(self):
return len(self.conversation_items) + 1
def decimal_to_int(obj):
if isinstance(obj, Decimal):
return int(obj)
def conversation_dict_factory(items: list[tuple[str, Any]]) -> dict[str, Any]:
#convert conversation object to dict
adict = {}
for key, value in items:
if isinstance(value, datetime):
value = value.strftime('%Y/%m/%d %H:%M:%S')
adict[key] = value
return adict
Teamsでの使用方法
アプリを以下のように追加する。
アプリの追加ボタンを押す。
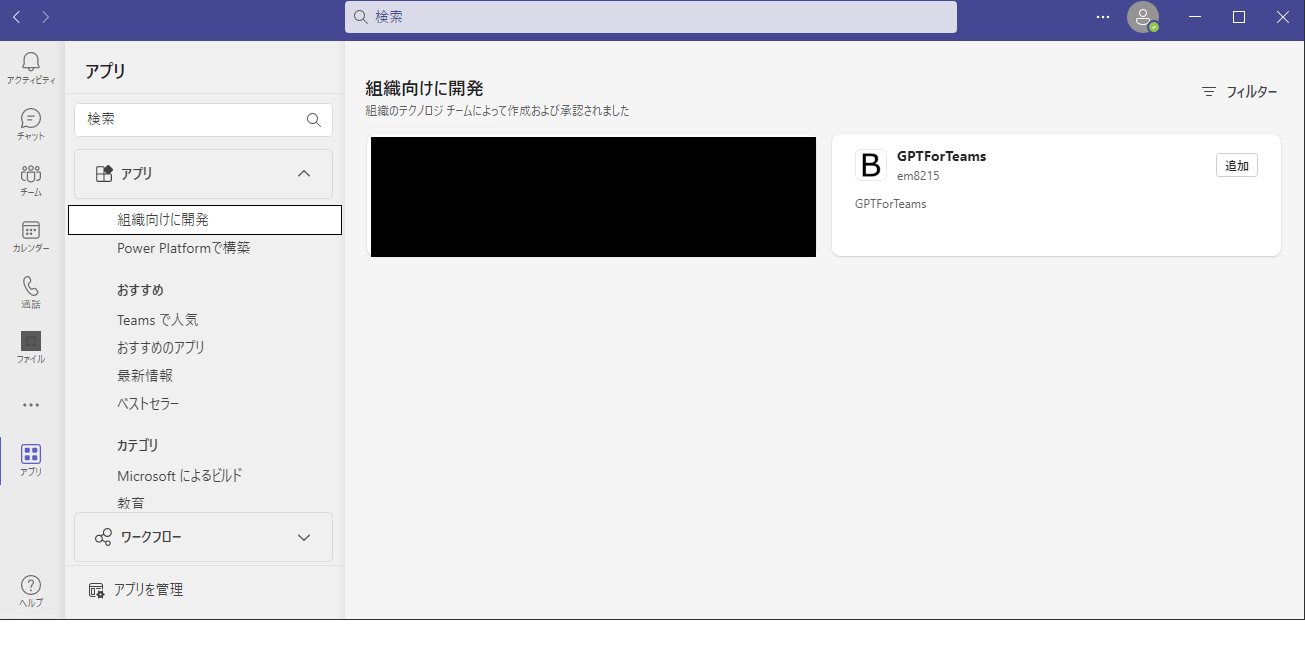
自分用に追加を選択して追加。(画像はチームに追加となっているが変更して追加)

Teamsの左のツールバーからGPTForTeamsを選択するか、画面上の検索バーからGPTForTeamsを検索して出てきたチャット画面に何か文字を入力する。入力すると、ChatGPTからの返信が書き込まれる。
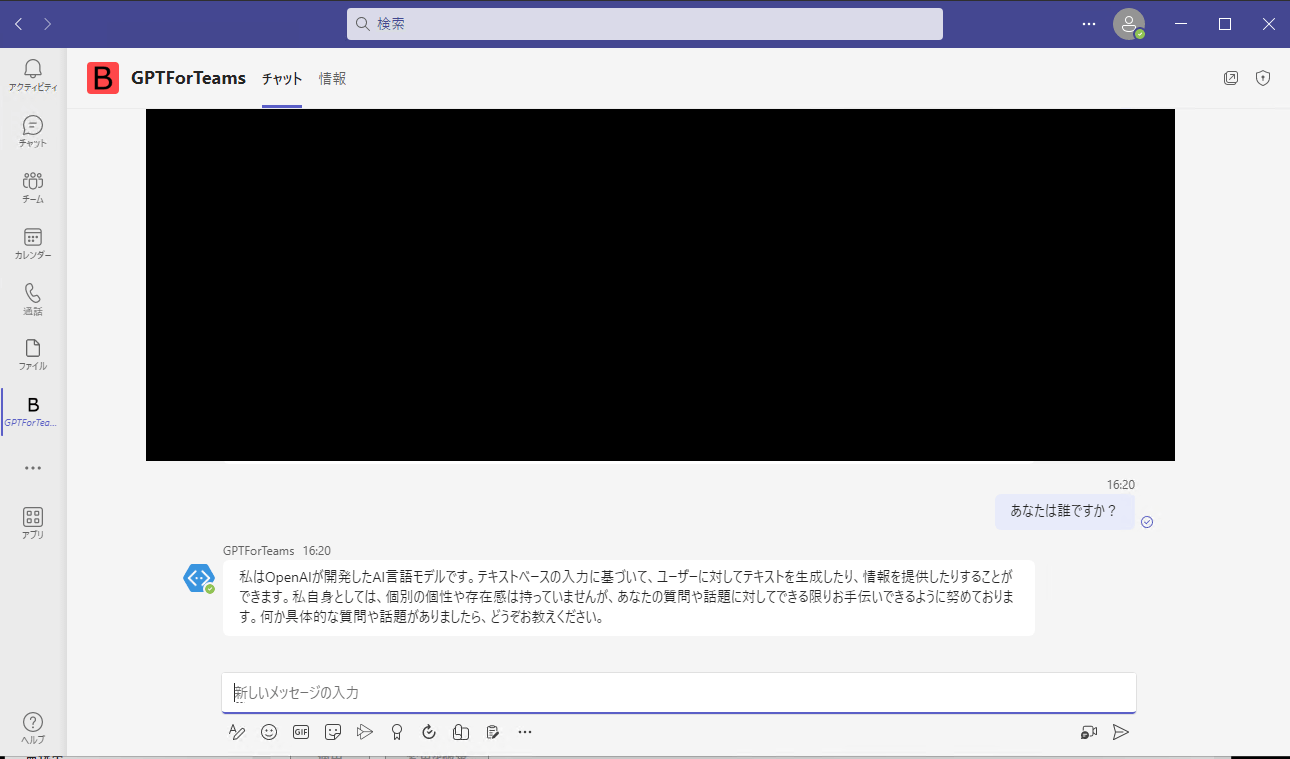
感想とか今後の展望とか
最近勉強している AWS SAM + Pythonで何か作ってみようかと思っていたときに、ちょうど良いタイミングで社内から声が上がったのでよいきっかけになった。
SAMについては、ローカル環境での実行・デバッグに結構苦戦したため、そちらの環境構築の方法も別の機会に記事にしたいと思う。
今後は以下のような改良を加えたい。
- 現在の実装だと、会話を消去できない仕様になっているので、その機能を追加する。(会話の消去もTeamsのメッセージのやり取りの中で行いたい。ChatGPTのFunction callingを使えばできそう。)
- AWS側は非同期処理としたい。具体的にはAPI GatewayとLambdaの間にSQSを配置し、SQS経由でlambdaを呼び出すようにする。(API Gatewayの30秒タイムアウト制限を無くす。)
- LangChainやLlamdaIndexを導入。今回は自前で履歴管理を行っているが、LangChainのMemoryを使えばもっと楽に実装できそう。他にも独自データの使用とかも色々とできそう。
Discussion