「[試して理解]Linuxのしくみ」をRustでやってみる(5章〜8章)
「[試して理解]Linuxのしくみ ―実験と図解で学ぶOS、仮想マシン、コンテナの基礎知識【増補改訂版】」をやっていきます。
Rustでコード写経したり、メモっておきたいことをメモっておく予定です。
プロセス管理(応用編)
プロセス作成処理の高速化
fork()関数は親プロセスのメモリを子プロセスにコピーするというが、実際はページテーブルだけを書き込み不可の状態でコピーする。物理アドレスは共有。
読むだけなら親も子も問題なく出来る。書き込みが発生するタイミング(ページフォールト発生)でページの共有を解除して専用ページを持つことになる。これがコピーオンライト。
コピーオンライトの確認
use nix::libc::{_exit, size_t};
use nix::sys::{
mman::{mmap, MapFlags, ProtFlags},
wait::waitpid,
};
use nix::unistd::{fork, getpid, ForkResult};
use std::ffi::c_void;
use std::io::Write;
use std::os::raw::c_int;
use std::ptr;
const ALLOC_SIZE: size_t = 100 * 1024 * 1024;
const PAGE_SIZE: size_t = 4096;
fn access(mut data: *mut c_void) {
for _ in (0..ALLOC_SIZE).step_by(PAGE_SIZE) {
unsafe {
let target_address = data as *mut c_int;
*(target_address) = 0;
data = data.add(PAGE_SIZE);
}
}
}
fn show_meminfo(msg: &str, process: &str) {
println!("{}", msg);
println!("freeコマンドの実行結果:");
let commmand = std::process::Command::new("free")
.output()
.expect("free failed");
std::io::stdout()
.write_all(&commmand.stdout)
.expect("write failed");
println!("{}のメモリ関連情報:", process);
let command = std::process::Command::new("ps")
.arg("-orss,maj_flt,min_flt")
.arg(getpid().to_string())
.output()
.expect("ps failed");
std::io::stdout()
.write_all(&command.stdout)
.expect("write failed");
}
fn main() {
let data = unsafe {
mmap(
ptr::null_mut(),
ALLOC_SIZE,
ProtFlags::PROT_READ | ProtFlags::PROT_WRITE,
MapFlags::MAP_ANON | MapFlags::MAP_PRIVATE,
-1,
0,
)
.expect("mmap failed")
};
access(data);
show_meminfo("*** 子プロセス生成前 ***", "親プロセス");
match unsafe { fork() } {
Ok(ForkResult::Child) => {
show_meminfo("*** 子プロセス生成直後 ***", "子プロセス");
access(data);
show_meminfo("*** 子プロセスによるメモリアクセス後 ***", "子プロセス");
unsafe { _exit(0) };
}
Ok(ForkResult::Parent { child, .. }) => {
waitpid(child, None).expect("waitpid failed");
}
Err(_) => unsafe { _exit(1) },
}
}
結果
neko@raspberrypi:~/linux/05/cow $ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
Running `target/debug/cow`
*** 子プロセス生成前 ***
freeコマンドの実行結果:
total used free shared buff/cache available
Mem: 3885428 240420 2637520 1164 1007488 3569536
Swap: 102396 0 102396
親プロセスのメモリ関連情報:
RSS MAJFL MINFL
104084 0 29588
*** 子プロセス生成直後 ***
freeコマンドの実行結果:
total used free shared buff/cache available
Mem: 3885428 240672 2637268 1164 1007488 3569284
Swap: 102396 0 102396
子プロセスのメモリ関連情報:
RSS MAJFL MINFL
103460 0 39
*** 子プロセスによるメモリアクセス後 ***
freeコマンドの実行結果:
total used free shared buff/cache available
Mem: 3885428 343236 2534704 1164 1007488 3466720
Swap: 102396 0 102396
子プロセスのメモリ関連情報:
RSS MAJFL MINFL
103464 0 25640
neko@raspberrypi:~/linux/05/cow $
RSSはプロセスが物理メモリを他のプロセスと共有しているかは気にしていない。単純にプロセスのページテーブルの中で物理メモリが割り当てられているメモリ領域を合計する。
プロセス間通信
共有メモリ
下記コードだと最終行の親プロセスの値が変わっていない。そりゃそうだが、共有メモリを使えば... ?
use nix::{
libc::_exit,
sys::wait::wait,
unistd::{fork, ForkResult},
};
fn main() {
let mut data = 1000;
println!("子プロセス生成前のデータの値:{}", data);
match unsafe { fork() } {
Ok(ForkResult::Parent { .. }) => {
wait().expect("wait failed");
}
Ok(ForkResult::Child) => {
data *= 2;
unsafe {
_exit(0);
};
}
Err(e) => println!("{}", e),
}
println!("子プロセス終了後のデータの値:{}", data);
}
書き換わる!
共有メモリでデータ共有
use nix::{
libc::{_exit, size_t},
sys::{
mman::{mmap, MapFlags, ProtFlags},
wait::wait,
},
unistd::{fork, ForkResult},
};
use std::ffi::c_void;
use std::i64;
use std::ptr;
fn main() {
const PAGE_SIZE: size_t = 4096;
let mut data: i64 = 1000;
let shared_memory: *mut c_void = unsafe {
mmap(
ptr::null_mut(),
PAGE_SIZE,
ProtFlags::PROT_READ | ProtFlags::PROT_WRITE,
MapFlags::MAP_SHARED | MapFlags::MAP_ANON,
-1,
0,
)
.expect("mmap failed")
};
println!("子プロセス生成前のデータの値:{}", data);
for (i, byte) in data.to_le_bytes().into_iter().enumerate() {
unsafe {
let addr = shared_memory.add(i) as *mut u8;
addr.write(byte);
}
}
match unsafe { fork() } {
Ok(ForkResult::Parent { .. }) => {
wait().expect("wait failed");
let addr = shared_memory as *mut [u8; 8];
data = unsafe { i64::from_le_bytes(*addr) };
}
Ok(ForkResult::Child) => {
let addr = shared_memory as *mut [u8; 8];
data = unsafe { i64::from_le_bytes(*addr) };
data *= 2;
for (i, byte) in data.to_le_bytes().into_iter().enumerate() {
unsafe {
let addr: *mut u8 = shared_memory.add(i) as *mut u8;
addr.write(byte);
}
}
unsafe { _exit(0) };
}
Err(_) => {
unsafe { _exit(1) };
}
}
println!("子プロセス終了後のデータの値:{}", data);
}
他にはシグナルやパイプ、ソケットもプロセス間通信を実現します、と。
ソケットについては本当にサラッと言及されるだけ。いつかちゃんと勉強する。
排他制御
下記のようなコードがあるとする。
排他制御してないコード
use std::{
fs::{File, OpenOptions},
io::{Read, Write},
path::Path,
};
fn main() {
let path = Path::new("count");
let mut file = match File::open(path) {
Ok(file) => file,
Err(e) => {
println!("open failed: {}", e);
return;
}
};
let mut content = String::new();
let mut count: i64 = match file.read_to_string(&mut content) {
Ok(_) => content.parse().expect("parse failed"),
Err(e) => {
println!("parse failed: {}", e);
return;
}
};
count += 1;
match OpenOptions::new().write(true).open(path) {
Ok(mut file) => {
file.write(count.to_string().as_bytes())
.expect("write failed");
}
Err(e) => {
println!("{}", e);
return;
}
}
}
countの初期状態では中身は0とだけ書かれたファイル。
上記のプログラムを1000回動かす。
結果
inc $ for ((i=0;i<1000;i++)) ; do ./inc & done; for ((i=0;i<1000;i++)); do wait; done
[1] 217614
[2] 217615
[3] 217616
...
[995] 終了 ./target/debug/inc
[996] 終了 ./target/debug/inc
[997] 終了 ./target/debug/inc
inc $ cat count
852
inc $
1000回実行後のcountの中身は1000であってほしい!そのためにはflock()とかを使おうぜ、という話。
余談として、高級言語で排他制御を実現するために「ピーターソンのアルゴリズム」というものがあるらしい。
まあそれは頭の片隅に入れておくとして、flock()を使ってみる。
flock()使ったコード
use std::path::Path;
use nix::fcntl::{flock, open, FlockArg, OFlag};
use nix::sys::stat::Mode;
use nix::unistd::{read, write};
fn main() -> Result<(), nix::Error> {
let path = Path::new("count");
let fd = open(path, OFlag::O_RDWR, Mode::empty())?;
flock(fd, FlockArg::LockExclusive)?;
let mut buf = [0u8; 8];
read(fd, &mut buf)?;
let content = buf
.iter()
.filter(|b| **b != 0)
.map(|b| *b as char)
.collect::<String>();
let mut count: i64 = content
.parse()
.expect(format!("parse error: {}", content).as_str());
count += 1;
let content = count.to_string().into_bytes();
let fd = open(path, OFlag::O_WRONLY | OFlag::O_TRUNC, Mode::empty())?;
write(fd, &content)?;
flock(fd, FlockArg::Unlock)?;
Ok(())
}
結果
inc $ for ((i=0;i<1000;i++)) ; do ./target/debug/inc & done; for ((i=0;i<1000;i++)); do wait; done
[1] 247181
[2] 247182
[3] 247183
...
[998] 終了 ./target/debug/inc
[999]- 終了 ./target/debug/inc
[1000]+ 終了 ./target/debug/inc
inc $ cat count
1000
inc $
排他制御が成功しているように見える。
Linuxではプロセスを作成するときもスレッドを作成するときもclone()を呼び出す。
clone()ではどのようなリソースを共有するかを決められる。
デバイスアクセス
デバイスファイル
キャラクタデバイス
読み出しと書き込みはできるが、シークはできない。
端末やキーボード、マウスが該当する。
ブロックデバイス
読み出し・書き込み・シークが可能。HDDやSSDなどのストレージデバイスがそう。
デバイスドライバ
現代的なデバイスはMMIO(メモリマップI/O)という仕組みによってデバイスのレジスタにアクセスする。
カーネルの仮想アドレス空間上にデバイスのレジスタもマップし、デバイスを操作する。
ポーリング
デバイスドライバが処理の完了を検出するための方法その1。
デバイスが、デバイスドライバから依頼された処理が完了することを知らせるために自身の処理完了通知用レジスタの値を変更させる。
デバイスドライバはその値を見て、処理が完了したかを検知する。
ずっと監視し続けるのはCPU資源のムダで、所定の間隔で値を確認しに行ったりする方法はデバイスドライバを複雑にする。
割り込み
デバイスドライバが処理の完了を検出するための方法その2。
デバイスに処理を依頼してその後は放っておく。デバイスが処理を完了させると割り込みでCPUに通知が行き、デバイスドライバが割り込みコントローラに予め登録していた割り込みハンドラが呼び出され、処理結果を受け取る。
ファイルシステム
ファイルシステムのおかげでデバイスファイルをいじらなくて済む、便利。
ファイルシステムへのアクセス関数はPOSIXで定められているので、ファイルシステムの種類の違いを意識しなくて済む、ありがたい。
操作の流れ
1.ファイルシステム操作の関数が、ファイルシステム操作をするシステムコール
2. カーネル内のVFSという処理が動作し、個々のファイルシステムの処理を呼ぶ
3. ファイルシステムの処理がデバイスドライバを呼ぶ(本当はブロック層が挟まるとのこと)
4. デバイスドライバがデバイスを操作
メモリマップトファイル
Linuxにはファイルの領域を仮想アドレス空間上にマップする「メモリマップトファイル」という機能があるとのこと。
それがなんか嬉しいのか〜?とちょいとググると、適切に使えば普通にファイルを操作するより速度やメモリの使用の点でメリットが出る感じだろうか。
メモリマップトファイルを使ってファイルを更新するコード
use std::{
error::Error,
io::{self, Write},
os::raw::c_void,
process::Command,
ptr,
};
use nix::{
self,
fcntl::{open, OFlag},
sys::{
mman::{mmap, MapFlags, ProtFlags},
stat::Mode,
},
unistd,
};
fn main() -> Result<(), Box<dyn Error>> {
let pid = unistd::getpid();
println!("*** testfileのメモリマップ前のプロセスの仮想アドレス空間");
let output = Command::new("cat")
.arg(format!("/proc/{}/maps", pid))
.output()?;
io::stdout().write_all(&output.stdout)?;
// File::open()を使うとmmap呼び出しがEACCESでエラー
//let file = File::open("./testfile")?;
// let fd = file.as_raw_fd();
let fd = open("testfile", OFlag::O_RDWR, Mode::empty())?;
let data: *mut c_void = unsafe {
mmap(
ptr::null_mut(),
5,
ProtFlags::PROT_READ | ProtFlags::PROT_WRITE,
MapFlags::MAP_SHARED,
fd,
0,
)?
};
println!("\ntestfileをマップしたアドレス:{:p}\n", data);
println!("*** testfileのメモリマップ前のプロセスの仮想アドレス空間");
let output = Command::new("cat")
.arg(format!("/proc/{}/maps", pid))
.output()?;
io::stdout().write_all(&output.stdout)?;
for (i, b) in b"HELLO".into_iter().enumerate() {
unsafe {
(data.add(i) as *mut u8).write(*b);
}
}
Ok(())
}
ウワッ~~...これはなんか楽しいぞ...。
一般的なファイルシステム
ext4,、XFS,、Btrfsを見ても「ふーんこのファイルシステムはこれなのね」くらいにしか思ってなかったが、ちゃんとそれぞれに特徴があり、ファイルシステムやファイルの最大サイズ、最大ファイル数とかとかに違いがあるらしい。
ちゃんと違いがあるのね、そりゃそうか…。
記憶階層
キャッシュメモリへのアクセス速度の計測
use nix::sys::mman::{mmap, MapFlags, ProtFlags};
use std::{error::Error, fs::OpenOptions, io::Write, os::raw::c_void, ptr, time};
const CACHE_LINE_SIZE: usize = 64;
const NACCESS: usize = 128 * 1024 * 1024;
fn main() -> Result<(), Box<dyn Error>> {
let mut file = OpenOptions::new()
.create(true)
.read(true)
.write(true)
.open("out.txt")?;
let mut i = 2.0;
while i <= 16.0 {
let bufsize: usize = 2_f64.powf(i) as usize * 1024;
let data: *mut c_void = unsafe {
mmap(
ptr::null_mut(),
bufsize,
ProtFlags::PROT_READ | ProtFlags::PROT_WRITE,
MapFlags::MAP_SHARED | MapFlags::MAP_ANON,
-1,
0,
)?
};
println!(
"バッファサイズ 2^{:.2}({}) KBについてのデータを収集中...",
i,
bufsize / 1024
);
let start = time::Instant::now();
let data = data as *mut u8;
for _ in (0..(NACCESS / (bufsize / CACHE_LINE_SIZE))).into_iter() {
for j in (0..bufsize).step_by(CACHE_LINE_SIZE).into_iter() {
unsafe { data.add(j).write(0) };
}
}
let end = time::Instant::now().duration_since(start).as_nanos();
writeln!(&mut file, "{}\t{}", i, (NACCESS as f64 / end as f64))?;
i += 0.25;
}
Ok(())
}
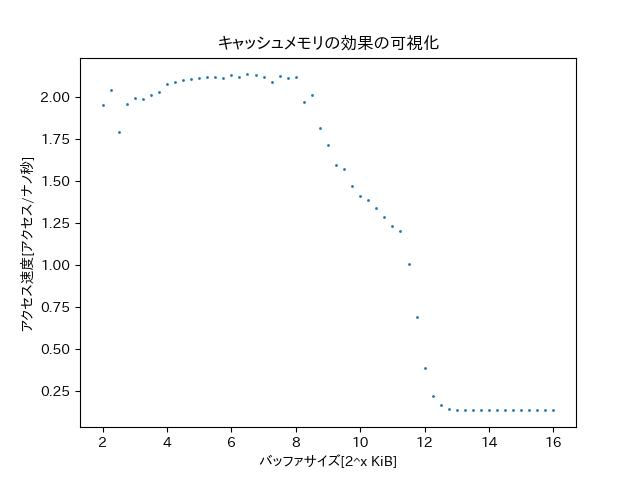
早い。ラズパイでなくthinkpadで動かした。本の図ほどわかりやすくはないが3パートに分かれている気がする。
バッファのサイズがL1、L2、L3キャッシュメモリの容量に達する前後でアクセス速度が変わるとのこと。
Simultaneous Multi Threadings(SMT)
CPUの計算リソースが空いてしまったとき、そいつを有効活用する仕組み。
CPUコアの中のレジスタなどの一部の資源を複数作って、それぞれスレッド(一般的なスレッドとは関係ない)とし、Linuxカーネルはそれらを論理CPUとして認識する。
あるプロセスで整数演算ばかり、他のプロセスでは浮動小数点数演算ばかり、みたいなときは空きリソースを束ねて処理させる、みたいなイメージだろうか。
ページキャッシュ
キャッシュメモリ:メモリのデータをキャッシュメモリにキャッシュする
ページキャッシュ:ファイルのデータをメモリにキャッシュする
ダーティーページ、ライトバックの概念はページキャッシュにもある。
バッファキャッシュ
ディスクのデータのうち、ファイルデータ以外のものをキャッシュする仕組み。
- ファイルシステムを使わずに、デバイスファイルを用いてストレージデバイスに直接アクセスするとき
- ファイルのサイズやパーミッションなどのメタデータにアクセスするとき
direct I/O
ページキャッシュやバッファキャッシュは無いほうがいいこともある。
- 一度しか読み書きしないようなデータの場合
- プロセスが自前でページキャッシュ相当の仕組みを実装する場合
open()時にO_DIRECTフラグを指定してページキャッシュを使わないようにできる。
統計情報
必要なタイミングまで覚えてられる気はしないが、知ってると良さそうなことが書かれているということだけは覚えておく。
9章以降にはRustで写経したいようなところはなかったのでスクラップはここで終わり。
あとはちょこちょこ読み返したりして脳みそに刻みこむ。
面白く読みやすかったので気になってる人は買って損しないと思います。
バイナウ。