Python, Docker, Scrapyを使ってURLからWebページをHTML形式でダウンロードする
本記事でやりたいこと
Python, Docker, Scrapyを使ってURLからWebページをHTML形式でダウンロードする
今回は私が以前作成した記事である下記のURLをHTML形式でダウンロードしたいと思います。
本記事のリポジトリ
うまく行かない処理などありましたら、こちらをご覧ください!
Python, Dockerの設定
Docker Desktopをインストールする
下記リンクからDocker Desktopをダウンロードして、インストールして起動してください
Python環境を作成
- Dockerfileを作成します
$ touch Dockerfile
FROM python:3.8.12-bullseye
WORKDIR /usr/src/app
RUN apt-get update && apt-get install -y unzip
ENV PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/chrome
COPY requirements.txt ./
RUN pip install --upgrade pip && pip install --no-cache-dir -r ./requirements.txt
- requirements.txtを作成し、必要なライブラリを記述します
$ touch requirements.txt
scrapy==2.9.0
- docker-compose.ymlを作成します
$ touch docker-compose.yml
version: '3.9'
services:
scrapy:
build:
context: .
dockerfile: Dockerfile
image: scrapy:2.6.1
container_name: my_scrapy
volumes:
- $PWD/app:/usr/src/app
tty: true
- コンテナを起動する
$ docker-compose up -d --build
Creating network "docker-scrapy-spider_default" with the default driver
Building scrapy
[+] Building 32.9s (8/9)
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 369B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for docker.io/library/python:3.8.12-bullseye 3.6s
=> [1/5] FROM docker.io/library/python:3.8.12-bullseye@sha256:53cb5152064a7e7b485ad42704ea63c5155b264c82e7f17de99d3aa28e4f8956 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 93B 0.0s
=> CACHED [2/5] WORKDIR /usr/src/app 0.0s
=> CACHED [3/5] RUN apt-get update && apt-get install -y unzip 0.0s
=> [4/5] COPY requirements.txt ./ 0.0s
=> [5/5] RUN pip install --upgrade pip && pip install --no-cache-dir -r ./requirements.txt [+] Building 119.1s (10/10) FINISHED
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 369B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for docker.io/library/python: 3.6s
=> [1/5] FROM docker.io/library/python:3.8.12-bullseye@sh 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 93B 0.0s
=> CACHED [2/5] WORKDIR /usr/src/app 0.0s
=> CACHED [3/5] RUN apt-get update && apt-get install -y 0.0s
=> [4/5] COPY requirements.txt ./ 0.0s
=> [5/5] RUN pip install --upgrade pip && pip install - 115.0s
=> exporting to image 0.4s
=> => exporting layers 0.4s
=> => writing image sha256:081870f12dabf66be0d5d6f1cf72df 0.0s
=> => naming to docker.io/library/scrapy:2.6.1 0.0s
Use 'docker scan' to run Snyk tests against images to find vulnerabilities and learn how to fix them
Creating my_scrapy ... done
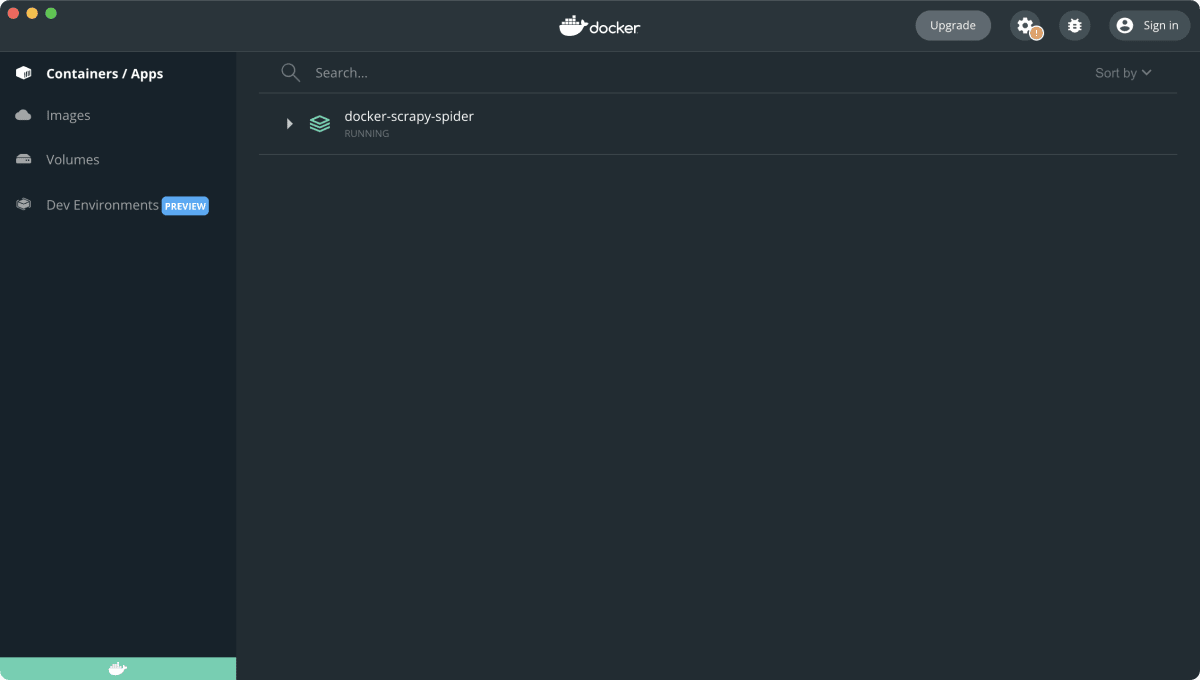
- Docker Desktopを開いて以下の画像のようにコンテナが立ち上がっていればOK
Scrapyを使ってHTMLを実際にダウンロードする
- Dockerコンテナに入ります
下記コマンドを打ったらroot@~:/usr/src/app#とターミナルが表示されればOKです
$ docker-compose exec scrapy bash
下記のコードで /usr/src/app# で始まっている部分はコンテナ内で実行するということです!
- Scrapyのプロジェクトを作成
今回はscrapingというプロジェクト名で作成します
/usr/src/app# scrapy startproject scraping .
New Scrapy project 'scraping', using template directory '/usr/local/lib/python3.8/site-packages/scrapy/templates/project', created in:
/usr/src/app
You can start your first spider with:
cd .
scrapy genspider example example.com
- spiderをgetHtmlという名前で作成する
/usr/src/app# scrapy genspider getHtml zenn.dev
- 生成されたgetHtml.pyを開いて以下のように修正する
import scrapy
import os
class GethtmlSpider(scrapy.Spider):
name = "getHtml"
allowed_domains = ["zenn.dev"]
start_urls = ["https://zenn.dev/elletech/articles/nextjs_microcms"]
def parse(self, response):
output_path = '/usr/src/app/downloads/'
os.makedirs(os.path.dirname(output_path), exist_ok=True)
with open(output_path + 'index.html', 'w', encoding='utf-8') as f:
f.write(response.text)
コードの解説
-
allowed_domains
このSpiderがクロールすることが許可されているドメインを指定します。これにより、Spiderはzenn.devからのリクエストに制限されます。 -
start_urls
Spiderがクロールを開始するURLを指定します。配列で複数指定することで連続で複数のURLに対してクロールを実行することができるようになります。 -
output_path
ダウンロードしたHTMLを保存するディレクトリのパスを設定します。 -
os.makedirs(os.path.dirname(output_path), exist_ok=True)
出力パスのディレクトリを作成します。exist_ok=Trueはディレクトリが既に存在する場合でもエラーを発生させないようにするオプションです。 -
with open(output_path + 'index.html', 'w', encoding='utf-8') as f:
新しいファイル(ここではindex.html)を作成し、そのファイルを書き込む準備をします。 -
f.write(response.text)
ダウンロードしたウェブページのHTMLをファイルに書き込みます。
- crawlを実行する
$ scrapy crawl getHtml
~省略
2023-07-08 06:06:21 [scrapy.core.engine] INFO: Spider closed (finished)
-
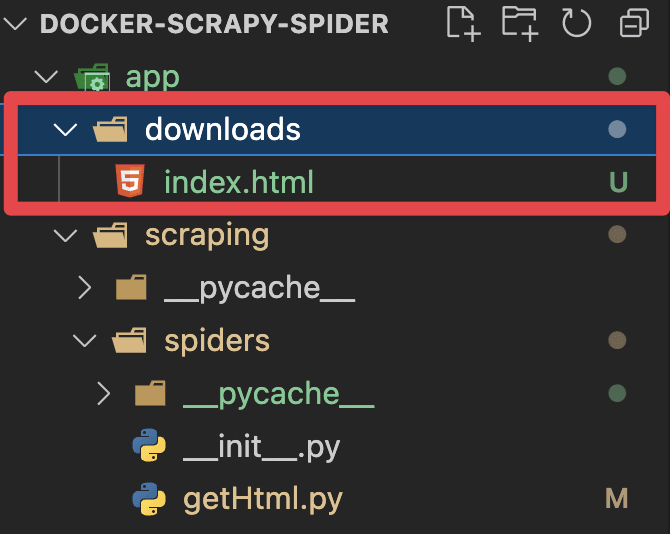
実行がうまくいくと下記の画像のようにapp/downloadsディレクトリの中にindex.htmlが作成されているはずです
-
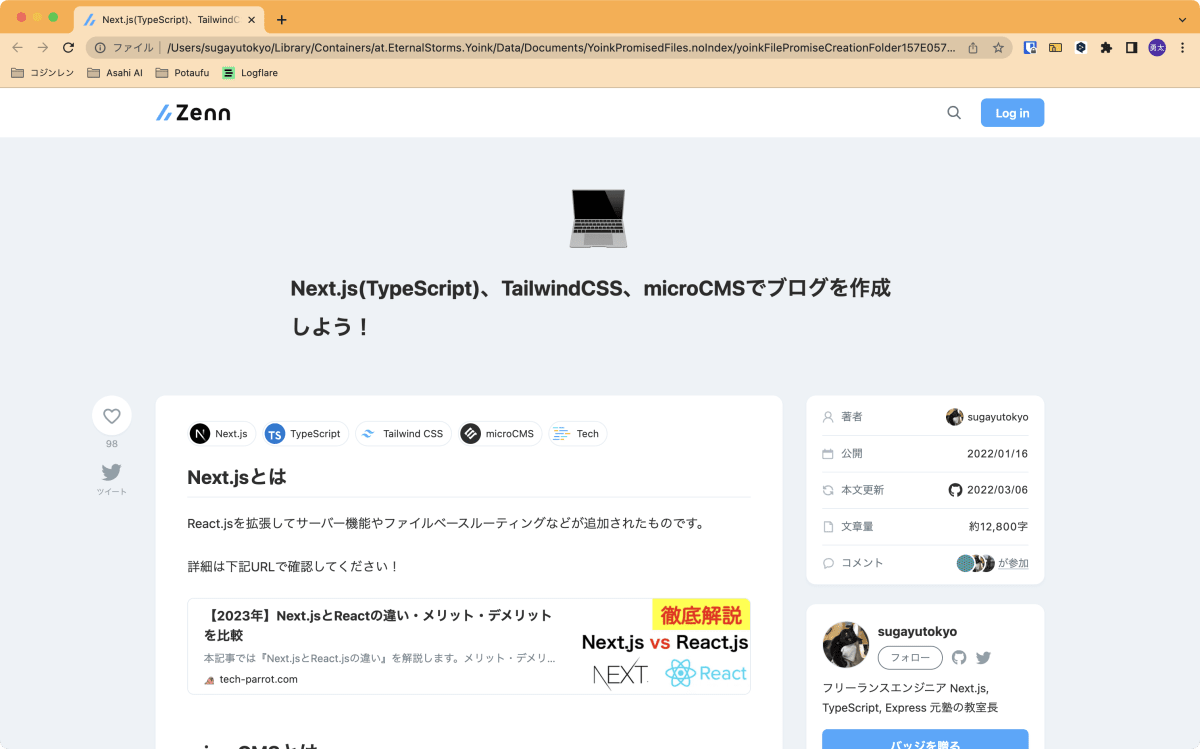
生成されたhtmlをchromeなどのブラウザで開いてみましょう!
以下のように表示されていれば成功です!お疲れ様でした!
参考
Discussion