はじめに
株式会社Elithでインターン生として働いている中村彰成です。今回は、あるプロジェクトで扱ったGBDT(勾配ブースティング決定木)を紹介します。GBDT系の機械学習アルゴリズムは、2024年現在でもkaggleなどのテーブルコンペで人気なアルゴリズムです。
この記事では、GBDTの概要、GBDTの代表格であるXgboost, LGBM, CatBoost, それぞれのアルゴリズムの違いについて紹介します。
実装については、以下の記事で紹介しています。 ※画像に関しては、該当する論文から引用しています
GBDTについて
GBDTは、勾配降下法(Gradient)、ブースティング(Boosting)、そして決定木(Decision Tree)という3つの手法を組み合わせた機械学習アルゴリズムです。以下、それぞれの要素について簡単に説明します。
勾配降下法
勾配降下法は、ある関数𝑓(𝑥)の最小値を見つけるために使用される最適化手法です。
まず、勾配 ∇𝑓(𝑥)、すなわち𝑓の各パラメータに関する偏微分を計算します。次に、この勾配を用いてパラメータを更新します。 ここで、勾配はfが増加する方向なので逆方向に更新します。パラメータ 𝑥 の更新は以下の式に従います。
η は学習率(またはステップサイズ)と呼ばれ、どれだけ大きくパラメータを更新するかを決定します。
勾配降下法には、以下のような手技が存在しますが、この記事の本題とは外れますので、省略します。
- 最急降下法
- 確率的勾配降下法(SGD)
- ミニバッチ勾配降下法
ブースティング
ブースティングは、複数の弱学習器(単純なモデル)を組み合わせて、強力な予測モデルを構築する手法です。各学習ステージで、前のモデルが誤って分類または予測したデータポイントに注目し、それらのデータポイントにより大きな重みを与えることによって、次のモデルはそれらの難しいケースをより重点を置くように訓練されます。このプロセスを、一定数の弱学習器が構築されるか、あるいは改善が見られなくなるまで続けます。
決定木
決定木は、データを分類または回帰するためのシンプルな質問と答え("Yes/No")の連鎖によって構成されるモデルです。木の各ノードはデータの属性に関する質問を表し、ブランチはそれに対する答えを表し、リーフ(葉)ノードは最終的な出力(クラスラベルや数値)を表します。データセットの特徴をもとに、データを効果的に分割できる質問を決定し、その質問を基に木を成長させていきます。
以上3つの手法から、GBDTは予測モデルを構築するために多数の決定木を組み合わせたアンサンブル学習手法です。前の木の誤差を次の木が修正する形で逐次的に木を構築していき、誤差を減少させる方向に勾配降下法を適用することで、モデルの精度を向上させます。
アルゴリズム編
GBDT系アルゴリズムの代表格として、XGBoost,LightGBM(LGBM),CatBoost があります。これらの3つの特徴について紹介します。
早見表
| フレームワーク | 設計 | 学習の傾向 |
|---|---|---|
| XGBoost | - スケーラビリティと計算速度を重視 - 正則化と欠損値の扱いを工夫して過学習を抑制 |
- 大規模データセットとスパースな特徴空間に対して高速に動作 - 正則化により過学習に強く、精度の高いモデルが構築可能 |
| LightGBM | - GOSSとEFBを用いてデータ処理とメモリ効率を最適化 - 計算資源を効率的に使用 |
- 高次元データに対する高速な処理能力 - データのサブサンプリングにより効率的な学習を実現 - 大規模なデータセットにも迅速に適用可能 |
| CatBoost | - カテゴリカルデータを直接扱うためのアルゴリズム - 過学習を防ぐための Orderd Boosting 技術 - モデルの解釈可能性を強化 |
- カテゴリカルデータやテキストデータの処理に優れ、自動的に特徴量を変換して学習 - 解釈可能なモデル提供で、広範な応用が可能 |
XGBoost
XGBoostは、スケーラビリティと計算速度を重視して設計されています。正則化を用いて過学習を抑制し、欠損値の扱いを工夫しています。そのため、大規模なデータセットとスパースな特徴空間での処理に優れ、高い精度と速度を両立しています。
正則化([1]2.1節)
過学習を防止するために、正則化が重要な役割を果たします。正則化には二つの形式があります。
-
L1 正則化
- モデルの係数(重み)の絶対値に比例するペナルティを加えます。そのため、係数の一部がゼロに近づくことで、モデルがシンプルになり、不必要な特徴量の影響を減らすことができます。
-
L2 正則化
- 重みの二乗の和に比例するペナルティを加えることで、大きな重みが結果に与える影響を抑制します。これは、モデルがデータのノイズに対して過敏に反応するのを防ぐ効果があります。
欠損値の扱い([1]3.4節)
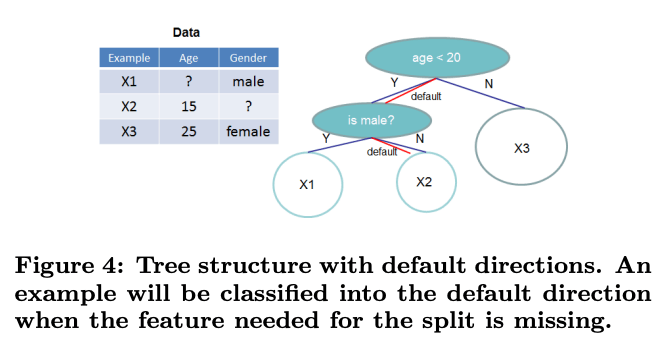
欠損値が含まれているデータに対しても効率的に学習を行います。欠損値を持つ特徴量で分岐する際、どのサンプルをどの子ノード(左か右)に進めるかを学習します。学習中に、欠損値を持つデータポイントが分岐する際のデフォルトの方向(左または右)が決定され、新しいデータにおいても欠損値がある場合に適切に分岐させることが可能になります。
LGBM
LightGBMは、データ処理とメモリ効率の最適化を目的として、Histogram-based Splitting,Leaf-wise Tree Growth ,Gradient-based One-Side Sampling(GOSS), Exclusive Feature Bundling(EFB) という技術を採用しています。特に高次元データに対する高速な処理能力を持ち、大規模なデータセットに迅速に適用可能で、効率的な学習を実現しました。
Histogram-based Splitting(Algorithm)([2]2.1節)
従来のレベルワイズの分割方法ではなく、ヒストグラムベースの分割を採用しています。連続値の特徴を固定数のビンに事前に分類し、これらのビンに基づいてヒストグラムを構築します。ヒストグラムに基づいて最適な分割点を探すことにより、特徴の分割時に必要な計算量を大幅に削減できます。
Leaf-wise(Best-first) Tree Growth([2]5.1節)
従来の深さ優先の成長戦略(depth-wise growth)ではなく、葉優先の成長戦略(leaf-wise growth)を採用しています。この手法では、分割による最大のInfomation Gain(データセットを分割するための最良のポイントを選択する際に用いられる指標)をもたらす葉から順にツリーを成長させます。よって、より低い損失を早期に達成できるため、同じ数の葉を持つツリーでより高い精度が期待できます。
GOSS([2]3章)
GOSS は、Information Gain(データセットを分割するための最良のポイントを選択する際に用いられる指標)の計算において、「勾配が大きい(つまり訓練不足の)データインスタンスがより重要な役割を果たす」という考えに基づいています。GOSS では、小さな勾配を持つデータの一部をランダムに除外し、大きな勾配を持つすべてのインスタンスを保持します。小さい勾配のデータからサンプリングする際、Information Gain の計算において、サンプリングされた小さい勾配データに一定の重みを乗算することで、データ分布の影響を補正します。よって、より正確な Information Gatin の推定が可能になり、全体のデータセットサイズを小さくしながらも、学習の精度を維持することができます。
EFB([2]4章)
EFBは、スパースな特徴空間の場合に、多くの特徴がほとんど同時にゼロ値を取らないという特性(one-hot的なイメージ)を活用します。この特性に基づき、特徴量をグループ化(bundle)することで、特徴数を削減します。
CatBoost
CatBoostは、カテゴリカルデータを直接扱うためのアルゴリズム Ordered TS と、過学習を防ぐための Orderd Boosting の二つを採用しています。そのため、カテゴリカルデータやテキストデータの処理に優れ、自動的に特徴量を変換してくるという特徴があります。
Ordered Target Statistics([3]3.2節)
Ordered Target Statistics (Ordered TS) は、カテゴリカル変数の各カテゴリに対して目的変数の統計値を、トレーニングデータのランダムな順列を用いて計算します。各データポイントが計算では、それより前にあるデータポイントのみを利用し、データリークを防ぎます。
Ordered Boosting([3]4.2節)
学習データのランダムな順列を使ってモデルを順次学習させる方法です。各トレーニングサンプルに対して、そのサンプルを除外したモデルを使用して残差を計算します。そのため、各サンプルが学習時に過度にフィッティングされるの防ぎます。

まとめ
この記事では、GBDTとその代表的な派生アルゴリズムである XGBoost、LightGBM、CatBoost の主な手法について紹介しました。アルゴリズムの背後にある理論は非常に深く、この記事では紹介しきれなかった点も多くあります。さらに詳しい情報やより深い理解を求める方は、ぜひ各アルゴリズムの原論文に目を通してみてください。私自身もさらに理解を深めていこうと思います。

Discussion