はじめに
株式会社Elithでインターンとして活動している吉丸です。今回は画像から文字認識技術、特に手書きで書かれた文字の認識に関する研究サーベイを行いました。
文字認識は古くからOptical Character Recognition (OCR)と呼ばれ盛んに研究されています。主に実際の紙に書かれた文字を認識するための技術であり、文書のデジタル化に関わる幅広い応用先で活用できます。その中でも手描きで書かれた文字は、書く人の癖や乱雑な部分があるためデジタルな文体より認識が非常に難しいことが課題として挙げられています。
そこで本記事では手描き文字認識に焦点を当て、最新の研究動向をまとめます。本記事内で使用している図は参考文献の論文から引用しています。[1]
技術概要
OCR技術は、主に手書きの文字や、非デジタルの紙媒体に書かれた文書をデジタル化するために行われてきました。その中でも特に、手書き文字は人によって書き方や癖があり、困難な課題です。英語圏では Handwritten Text Recognition (HTR)と呼ばれ研究が行われています。以降では近年のOCR/HTRに関する論文を紹介します。特に論文とコードが公開されているものを重点的にまとめています。(詳細は各論文をご参照ください。)
Easter2.0: Improving convolutional models for handwritten text recognition[1]
概要
CNNベースの認識モデルである Easter2.0 とデータ拡張を行う Tiling and Corruption Augmentation(TACo) というアルゴリズムを提案
提案モデルのアーキテクチャ

Easter2.0のアーキテクチャ
Easter2.0は、3種類のブロック(タイプA、B、C) を含む合計14層から構成されています。
- ブロックタイプA:このブロックでは,1D-CNN層、バッチ正規化、ReLU(活性化関数)、ドロップアウトの順で処理されます。ただし各層のパラメータは処理される場所によって異なることに注意してください。(詳しくは以下表を参照)
- ブロックタイプB:タイプAのブロックを複数回繰り返し、それの間に残差接続(リジッド接続)を加えています。このブロックでは、最後の畳み込みブロックにSqueeze-and-Excitation(SE)層を含んでおり、特定の畳み込み後のバッチ正規化層の出力にこのSE層の出力を加算しています。
- ブロックタイプC:モデルの最終層で使用され、1x1 の畳み込み層とソフトマックス層を通じて出力サイズを調整し、与えられた語彙の文字に対する確率分布を計算します。
これら各層の数や順番などは以下の表にまとめられています。
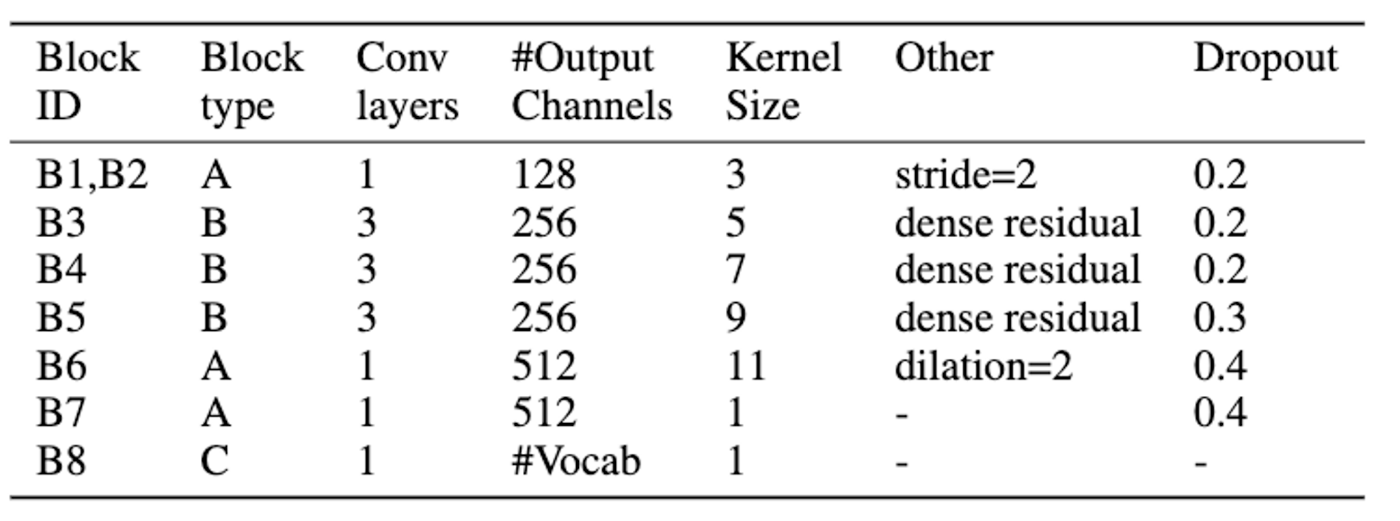
各層の概要表
また、縦方向と横方向のマスキングデータを作成しデータ数を増やすことで、モデル学習の精度向上の手助けをしています。そのアルゴリズムも疑似コードで定義されており、以下のようにグレーのマスキングを行っています。

マスキングによるデータ拡張例
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Modelsp[2]
概要
Transformerの仕組みをHTRに合わせて改変した研究
提案モデルのアーキテクチャ
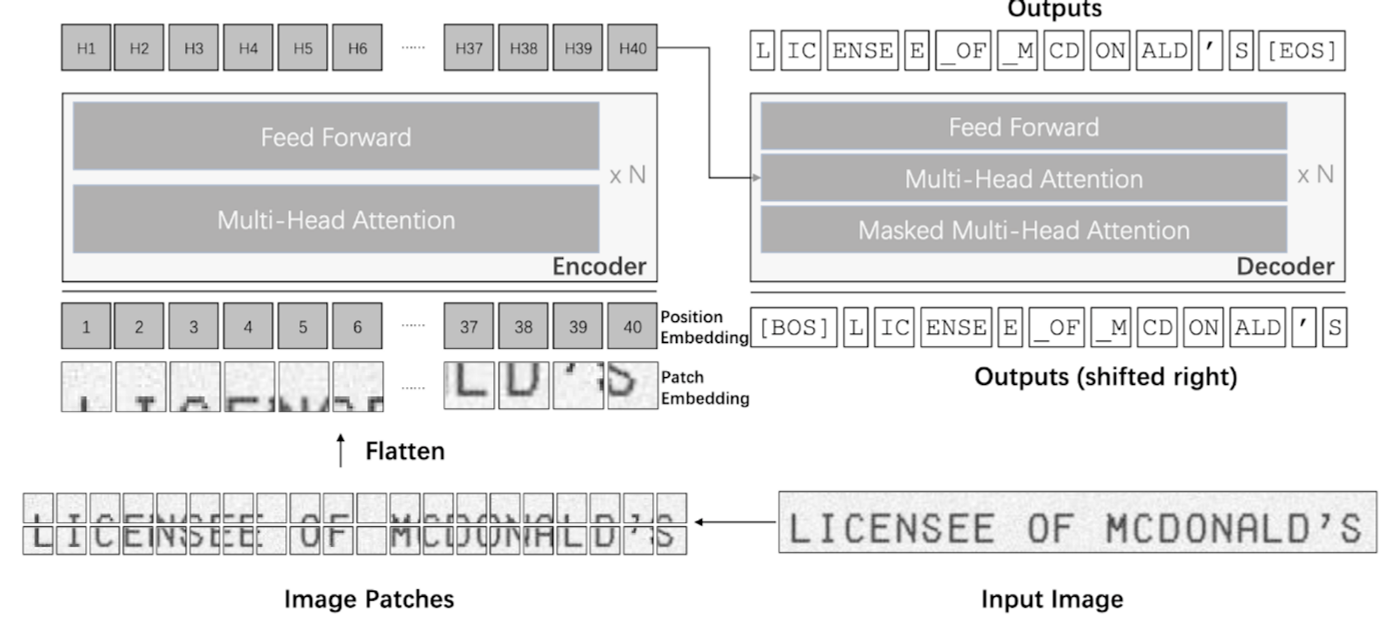
TrOCRのアーキテクチャ
上図は、TrOCRのアーキテクチャです。エンコーダーではDeiTやBEiTなどの事前学習済みの画像モデルを使用しており、デコーダーではRoBERTaやMiniLMなどの言語モデルを使用して初期化されます。エンコーダーは入力された画像をパッチに分割し、それぞれをベクトルに変換しています。そしてデコーダー側では事前学習済み言語モデルを用いているため、画像に現れない言語由来の知識を用いて適切にトークンを予測しています。
ScrabbleGAN: Semi-Supervised Varying Length Handwritten Text Generation[3]
概要
データ不足をカバーするためにGANを用いた研究
提案モデルのアーキテクチャ
手描き文字認識でラベル付きデータが少ない問題があり、その対処するために半教師ありアプローチである ScrabbleGAN を提案しています。
アーキテクチャの概要は以下の図です。
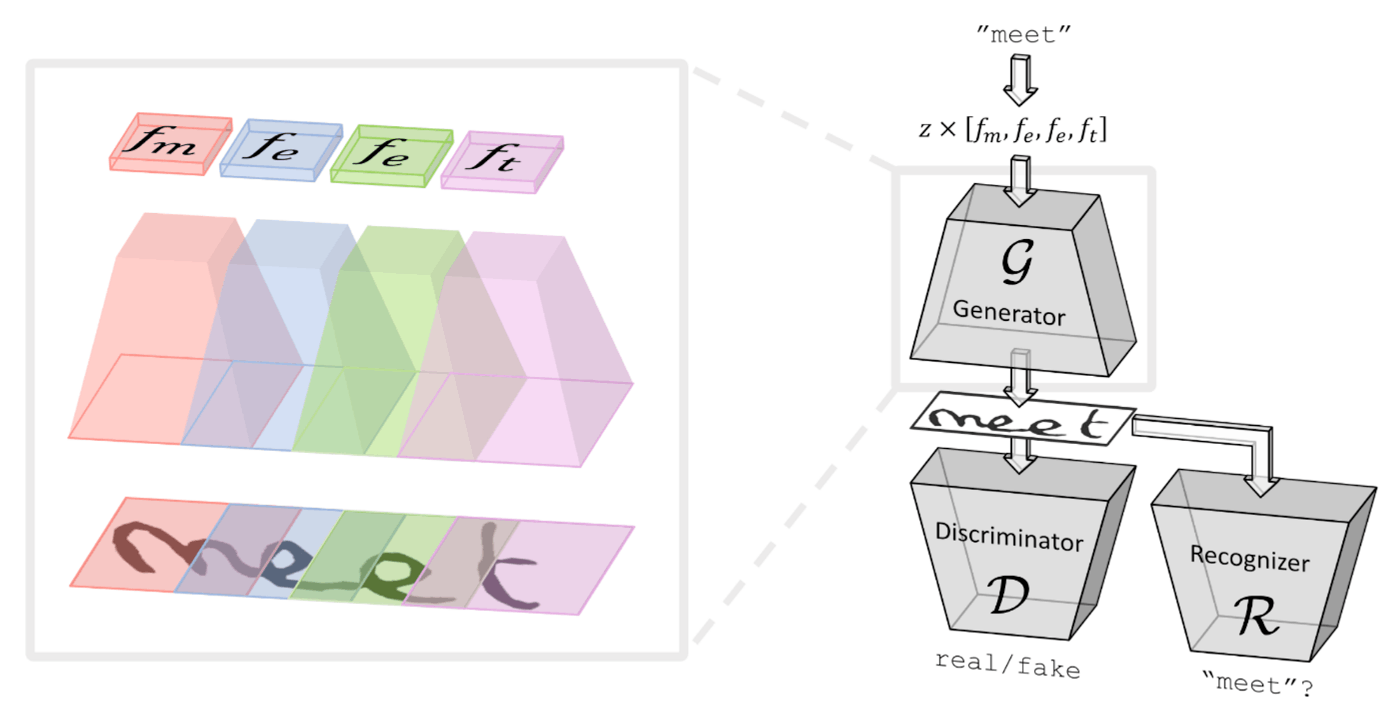
ScrabbleGANのアーキテクチャ
提案モデルは、通常のGANにあるGeneratorとDiscriminatorの他に、生成した画像が正しい文字列であるかどうかを判定するRecognizer機構が備わっています。また、Style interpolationと呼ばれる筆記体やペンの細さ太さを調整できる仕組みも提案しており、ノイズベクトル z を調整することで以下の図のように変えることができます。
!https://storage.googleapis.com/zenn-user-upload/4db2a66f3968-20240417.png
Diffusion models for Handwriting Generation[4]
概要
拡散モデル(Diffusion models)で手書き文字の生成を行なった取り組み
提案モデルのアーキテクチャ
画像生成分野で着目されている話題になった拡散モデルを手書き文字に適用した事例です。
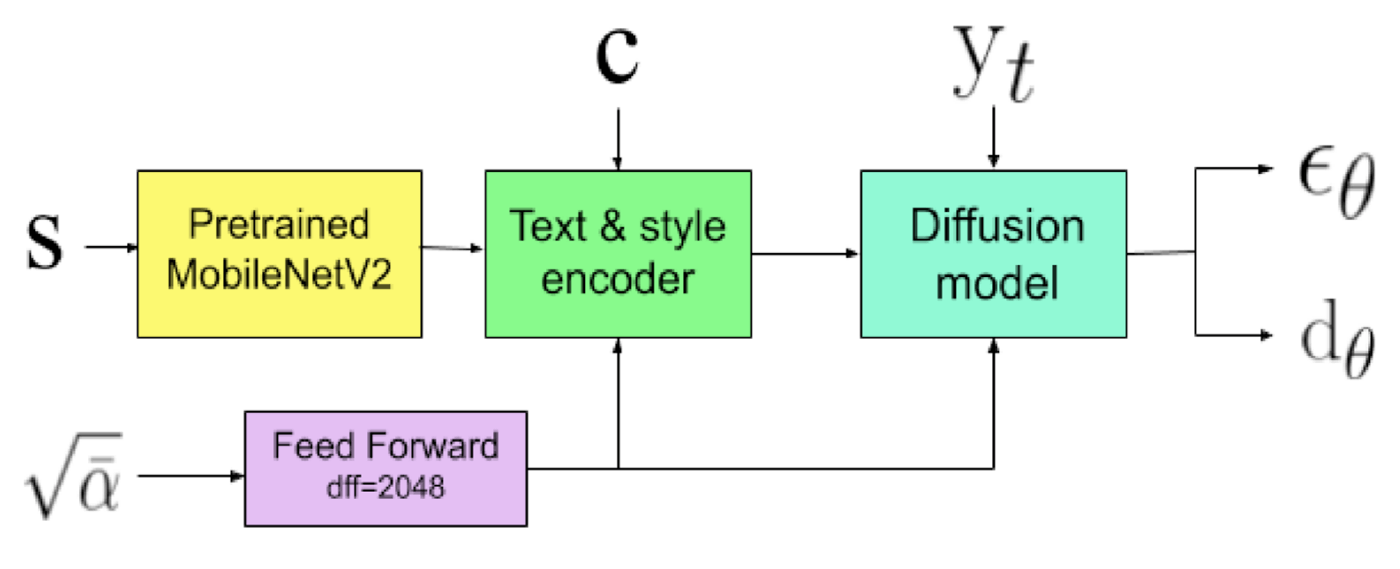
モデルアーキテクチャ
ImageNetで事前学習されたMobileNetV2を使用しており、ダウンサンプリングブロックとアップサンプリングブロックを含む構造で、長距離の畳み込みスキップ接続を使用しています。また、畳み込みブロックとアテンションブロックの2種類があり、畳み込みブロックは3つの畳み込み層とスキップ接続、アテンションブロックは2つのマルチヘッドアテンション層とフィードフォワードネットワークから構成されています。
OCR-free Document Understanding Transformer [5]
概要
Transformerで認識し各後段タスクを直接推論する、OCRをしないという大胆な手法
提案モデルのアーキテクチャ
タイトルでOCRフリーとあるように、文字認識を行わずエンドツーエンドで処理を行うモデルDountを提案しています。この研究ではOCRした先の後段タスク、例えば文書分類や文書情報抽出(Document Information Extraction.)、画像質問応答(VQA)なども同時に扱えるところが特徴です。

Dountの処理の流れ
EncoderにはSqin TransformerというViTの改良版を使用しており、デコーダには言語モデルであるBARTを用いています。
また実験では、以下のような複数の中国語・日本語・英語・韓国語のデータを用いて広範的に評価しています。(手書き文字を含む)また、提案モデルの動作デモをHugging FaceやGoogle Colabの環境で公開しているため、試しやすいです。

おわりに
本記事では、手書き文字認識の技術についてまとめました。サーベイを通じて、現在の研究ではモデルや言語モデルとの融合が主流であることがわかりました。これまでの領域認識や文字認識などのルールベースから End2End のマルチモーダルモデルへ移っており、今後もこの方向性で様々な研究が出てくると考えられます。画像モデル、言語モデルはそれぞれ現在盛んに研究されている分野なので、その融合により飛躍的に精度が向上する時も近いかもしれません。しかし、画像入力ができる言語モデル(GPT - 4Vなど)に単に入れるだけでは上手くいかないと言えるので、対象とするドメインや日本語、英語などの文字が書かれた背景知識を考慮してモデルを作る必要があると考えます。
最後に宣伝となりますが、株式会社 Elith は最先端のAI技術をビジネスに実装し、価値を生み出すテックカンパニーです。最近ではLLMの活用に関して様々な取り組みをしており、多数のイベントにも登壇しています。少しでも興味がある方は、X(旧Twitter)経由やElithのWebページ経由で、是非気軽にお話を聞きにきてください。
参考文献
[1] Chaudhary, K., & Bali, R. (2022). Easter2.0: Improving convolutional models for handwritten text recognition. arXiv preprint arXiv:2205.14879.
[2] Li, M., Lv, T., Chen, J., Cui, L., Lu, Y., Florencio, D., ... & Wei, F. (2023, June). Trocr: Transformer-based optical character recognition with pre-trained models. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 37, No. 11, pp. 13094-13102).
[3] Fogel, S., Averbuch-Elor, H., Cohen, S., Mazor, S., & Litman, R. (2020). Scrabblegan: Semi-supervised varying length handwritten text generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4324-4333).
[4] Luhman, T., & Luhman, E. (2020). Diffusion models for handwriting generation. arXiv preprint arXiv:2011.06704.
[5] Kim, G., Hong, T., Yim, M., Nam, J., Park, J., Yim, J., ... & Park,
S. (2022, October). Ocr-free document understanding transformer. In European Conference on Computer Vision (pp. 498-517). Cham: Springer Nature Switzerland.
-
この記事では文字認識のサービスではなく、精度を高めるための研究事例を扱っていることをご承知ください。 ↩︎

Discussion