はじめに
LLMのファインチューニングとして、指示文とコンテクストから出力を生成させるインストラクションチューニングという手法が存在します。インストラクションチューニングに用いるデータをインストラクションデータと呼びます。
本記事では、インストラクションデータを構築する方法とそのデータの収集源について解説します。
インストラクションデータ構築方法
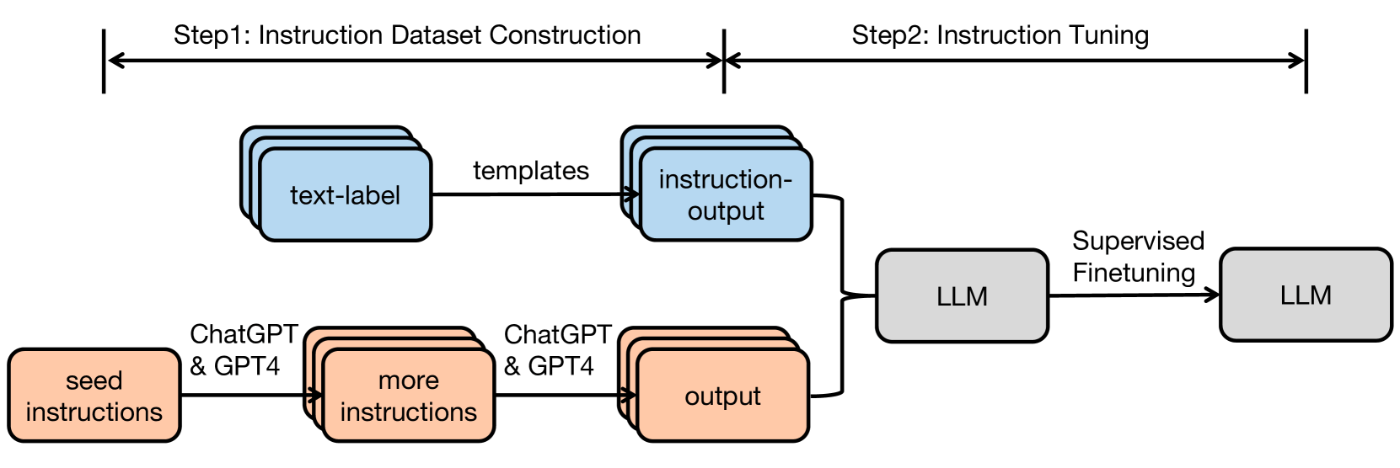
(Instruction Tuning for Large Language Models: A Survey. Figure 1より引用)
インストラクションデータの構築方法は2つです。一つ目は人手による収集、二つ目はLLMによるインストラクションデータの拡張です。
上図はインストラクションチューニングの流れを示しており、図の左側「Step1: Instruction Dataset Construction」が、インストラクションデータ構築です。
人手による収集

上図は人手による収集における流れを示します。
まず、インストラクションのテンプレートを用意します。集まったテキストラベルを用いて、対応するテンプレートの穴埋めによってデータを構築します。
簡単な例として、計算を行うデータセットの構築を挙げます。テンプレートは以下とします。
Instruction:
{計算式}を計算してください。
Output:
{結果}
「1 + 1 = 2」のテキストラベルが得られるとします。ここで、「 = 」でテキストを分割することで、計算式「1 + 1」と結果「2」が得られます。したがって、以下のように穴埋めをし、インストラクションデータを構築することができます。
Instruction:
1 + 1を計算してください
Output:
2
このように、穴埋めのロジックを定め、テンプレートからインストラクションデータを構築することで、データ構築を半自動化できます。
LLMによるインストラクションデータの拡張

上図はLLMによるインストラクションデータの拡張の流れを示します。
この方法によって、人手での作業を少なくして、データ量をスケールさせることができます。ChatGPTやGPT-4のようなLLMを用いてインストラクションデータを拡張します。ただし、ChatGPTやGPT4によって得られるデータは、ライセンスの観点から商用利用することはできません。公開されるLLMにはライセンスが付与されているため、よく確認するようにしましょう。
このデータ収集の特徴は、インストラクションに対応する出力をLLMから得るところにあります。この流れの詳細を説明します。
まず、人手でインストラクションを少量作成します。上図のseed instructionに当たります。
次に、人手で作成したインストラクションをLLMに入力し、インストラクションを拡張します。LLMによって、インストラクションを多様化させます。上図のmore instructionsに当たります。
最後に、拡張されたインストラクションをLLMに入力し、インストラクションに対応する出力を得ます。これによって、インストラクションデータが生成されます。上図のoutputに当たります。
具体的な手法として、InstructWildやSelf-Instructでインストラクションデータを構築することができます。
インストラクションデータの収集源
インストラクションデータ構築のためのデータの収集源として、よく用いられる二つを紹介します。一つ目は既存データセット、二つ目は構造化データです。
そのほか、Web上での対話などが挙げられますが、本記事での紹介は割愛します。
既存データセット
既存データセットからインストラクションデータセットを作成します。
質問応答のQAタスクは、質問をインストラクション、答えをインストラクションの応答とできます。データの構造からQAタスクからインストラクションデータは作りやすそうな印象を持ちますが、huggingface datasetsからChatGPTを用いて大規模なインストラクションデータを構築するDynosaurという手法も存在します。
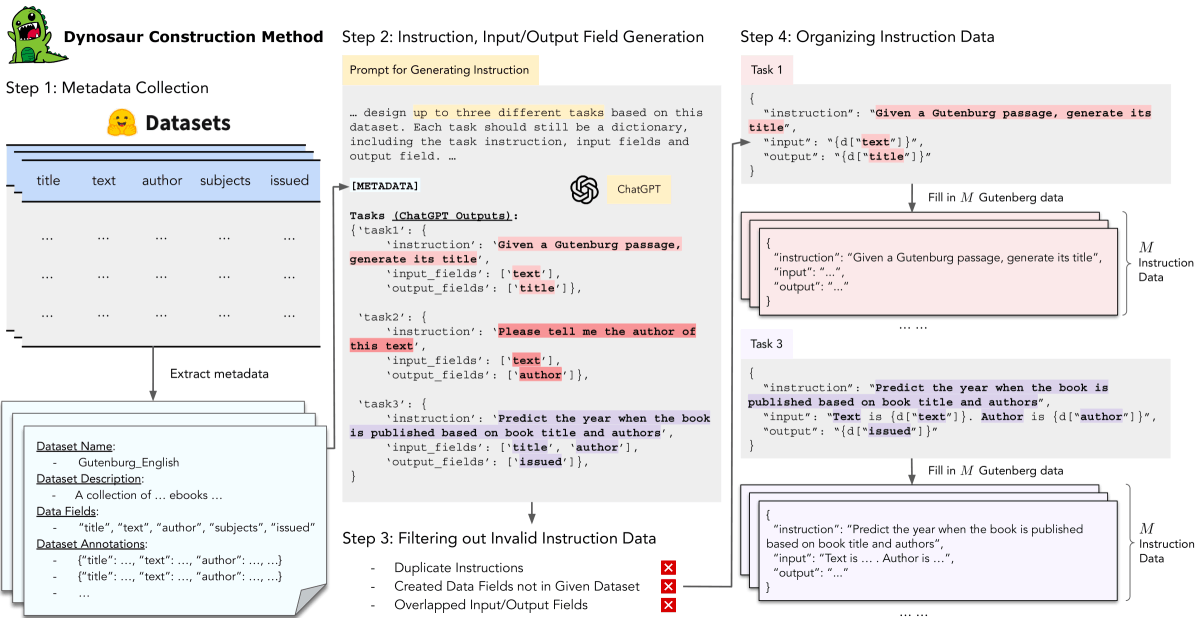
(Dynosaur: A Dynamic Growth Paradigm for Instruction-Tuning Data Curation. Figure 1より引用)
BioInstructデータセットでは、PubMedQAやMedNLIなどのさまざまなbiomedicalデータセットからインストラクションデータを構築しています。
構造化データ
構造化データからテンプレートをもとにインストラクションデータを構築します。構造化データとして、テーブルが挙げられます。
BioTABQAデータセットでは、Differential Diagnosis in Primary Careという教科書を表形式化することで、教科書を構造化データに変換しています。人手によるテンプレートを用いてインストラクションデータを構築しています。
教科書や本は目次やセクションが明確であるため、構造化データとして変換しやすいことが考えられます。
(余談)CoachLM: インストラクションデータの最適化
インストラクションデータには、LLMを用いて自動的に構築されたものも多く、品質が担保できない場合があります。
そこで、インストラクションデータを最適化するLLM (CoachLM)を構築し、CoachLMによって修正されたインストラクションデータでLLMをチューニングすることで、より高性能なモデルを構築する試みがあります。

(Automatic Instruction Optimization for Open-source LLM Instruction Tuning. Figure 2 (a)より引用)
エキスパートによって、人手で低品質なインストラクションデータを修正、調整、多様化、リライトし、修正前後のペアを作ります。そのペアを用いて、インストラクションを修正するCoachLMを構築します。
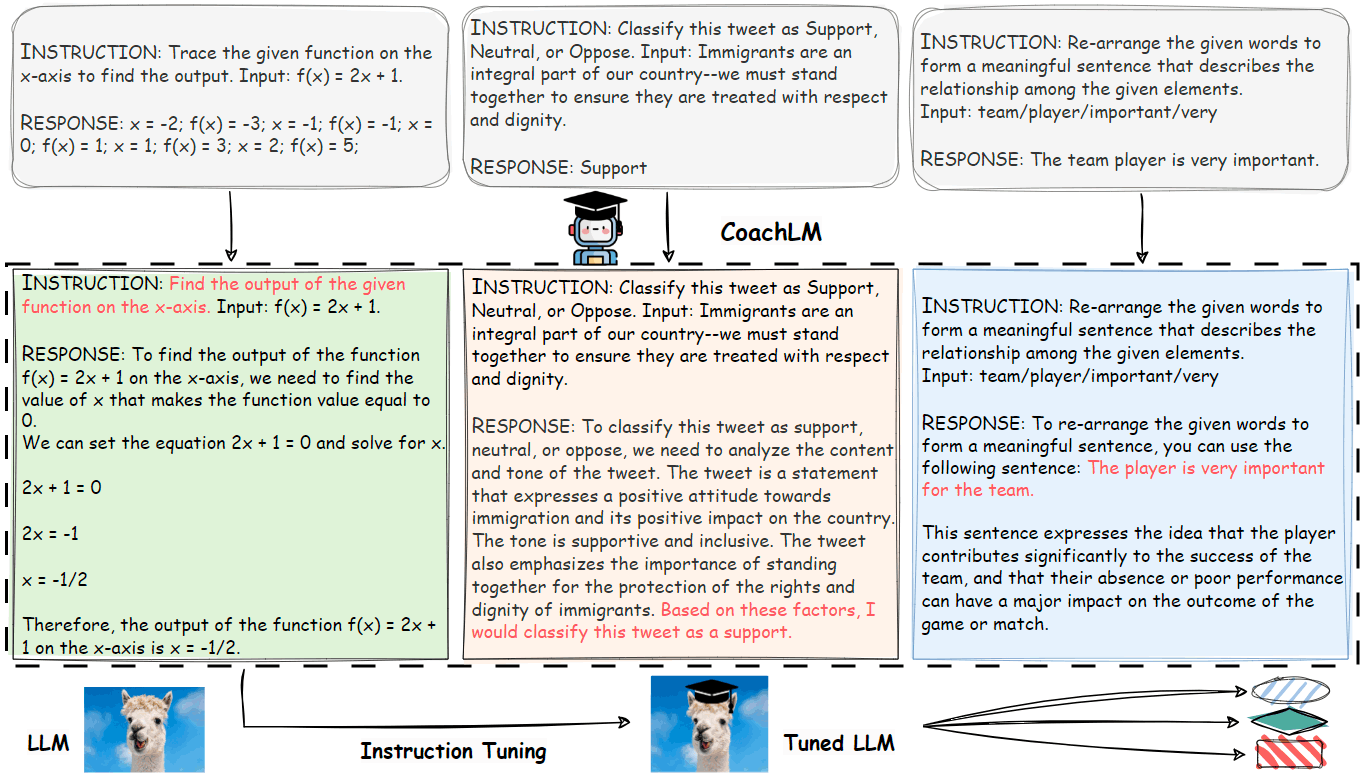
(Automatic Instruction Optimization for Open-source LLM Instruction Tuning. Figure 2 (b)より引用)
インストラクションチューニングのフェーズでは、CoachLMによって修正されたインストラクションデータが用いられます。
この手法により、インストラクションデータの品質が向上し、インストラクションチューニングされたモデルの性能が改善すると報告されています。
まとめ
本記事では、インストラクションデータを構築する方法とそのデータの収集源について解説しました。
LLMを用いてデータ量をスケールさせる手法や、インストラクションデータを高品質にする手法が研究されていることがわかりました。
教科書や本は品質が担保されるデータ収集源ですが、それらのデータをうまく用いる方法は難しく、有効活用している事例は多くない印象を受けました。BioTABQAのように、教科書を構造化データとしてインストラクションデータを構築する方向性はとても面白いです。世の中にありふれるデータをうまくインストラクションデータに落とし込む手法について、より深いサーベイを行いたいと思いました。
また、今回紹介したもの以外にも、対話データからインストラクションデータを構築する方法もあり、さまざまなデータ構築方法が検討できそうです。

Discussion