TL; DR
- OpenAI が非常に高品質な動画生成モデル Sora を公開
- 画像生成モデル Diffusion-Transformer を利用
- 動画を3次元画像として扱うことで画像モデルを拡張
- キャプションは DALL•E3 同様、キャプション生成モデルで作成
OpenAI Sora
Sora は OpenAI が今年の2月に発表した、動画生成モデルです。まずはこのモデルの出力例を見てみましょう。

図1. Sora の生成例: https://cdn.openai.com/sora/videos/big-sur.mp4
各フレームの画像が非常に美しく生成されています。また、従来の動画生成では時間が経った際に写っているオブジェクトを保つことが難しく、消えたり現れたり、急に歪んだりするものが多かったのに対し、Sora では一度隠れてから再度現れる場合であっても、矛盾なく生成できています。
このような動画生成モデルはどのようにして作られているのでしょうか。本稿では OpenAI が公開している Sora のテクニカルレポートをもとに、その技術について深掘りします。
Sora で出来るようになること
Sora による動画生成は非常に拡張性が高く、単にテキストから動画を生成する以外の多くのタスクが可能になります。テックブログで例として挙げられているもの以下5つです。
- 最初のフレームの画像から動画を生成する
- 動画を (時間的に) 前後に拡張する
- 2つの動画をシームレスに繋ぐような中間の動画を生成する
- 動画のシチュエーションを変更する
- 画像を生成する
テクニカルレポートにはこれらのサンプル動画も載っているので、ぜひ確認してみてください。
また、上記以外にも画像生成モデルで可能な条件付けは全て可能と考えられます。
アーキテクチャの全体像
まずは Sora の全体像について簡単に説明します。
動画圧縮ネットワーク
Sora とは別に、動画を低次元の潜在空間に圧縮するエンコーダと潜在空間からピクセル空間に戻すデコーダを学習しています。Sora はこの圧縮モデルの出力を用いて、潜在空間上での生成を学習しています。これは Stable Diffusion に代表される潜在拡散モデルと同じアイディアです。
時空間パッチ
言語モデルで用いられる Transformer の枠組みに乗せるために、潜在空間に圧縮された動画を3次元の画像と捉えて、時空間パッチに区切ります (図2ではわかりやすさのため元の動画をパッチに分けています)。
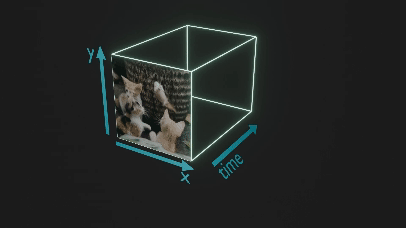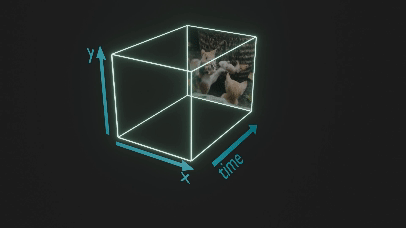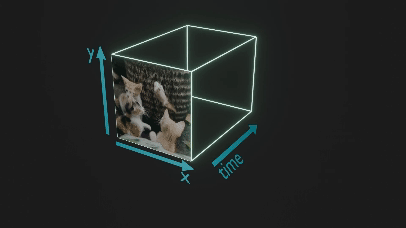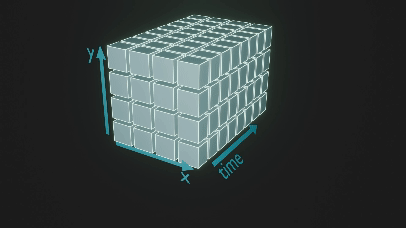
図2. パッチに区切る様子
各パッチ (図2のブロック) を1つのトークンとして捉え、拡散モデルと Transformer を組み合わせた Diffusion-Transformer を学習します。
以降では、拡散モデル、Vision-Transformer について簡単に説明した後、Diffusion-Transformer について説明します。
Diffusion-Transformer
拡散モデル
拡散モデルは綺麗に造形された粘土のフィギュアを徐々に潰していくステップ (拡散過程) を見ることで、反対に丸い粘土から綺麗なフィギュアの作る方法 (生成過程) を学ぶような手法です。例えば粘土の花の一部を潰したとして、潰れた後の粘土と潰し方がが分かればもとの花の形に戻せます。このような例を大量に見ることで、拡散モデルは潰れた後の形からどのように潰したのかを予測し、元の形を再現します。
このモデルは生成モデルの一種で、生成できる対象は画像に限らず、音楽やモーション、テキストなどを生成する研究もあります。本稿では簡単のためデータは画像に限定して説明します。
拡散モデルは、画像に小さなノイズを繰り返し加えることで元の情報を完全に失った状態に崩す拡散過程と、その反対に情報のない状態から意味のある画像を生成する生成過程 (逆拡散過程) の2つのプロセスで構成されます (図3)。以降での説明のため、元の画像を

図3. 拡散過程と生成過程
拡散過程はモデルに依存せず決まったノイズを加えており、この過程から生成過程を学習します。
この時加えるノイズとして最もよく用いられるのはガウスノイズで、次式のように足し合わせます。
ここで
上式を確率密度関数を用いて表すと、次式のようになります。
このような遷移に対して逆向きの遷移を次のようにモデリングします。
これらの拡散過程・生成過程の確率密度関数から、モデルによるデータの生成確率
Denoising Diffusion Probabilistic Models (DDPM) では、モデルの共分散行列が等方的である、つまり
そして、いくつかの項を無視すると拡散モデルの損失関数は以下のように非常にシンプルな形になります。
ここで
この損失関数では、ノイズを加えた画像から、どのようなノイズを加えたのか予測するよう学習していると解釈できます。DDPM ではこのように加わったノイズが予測し、そのノイズを引き算することで徐々に意味のある画像を生成します (図4)。図中の DNN で示したノイズの予測を行うモデルは、DDPM では UNet (図5)を用います。

図4. DDPMの概念図
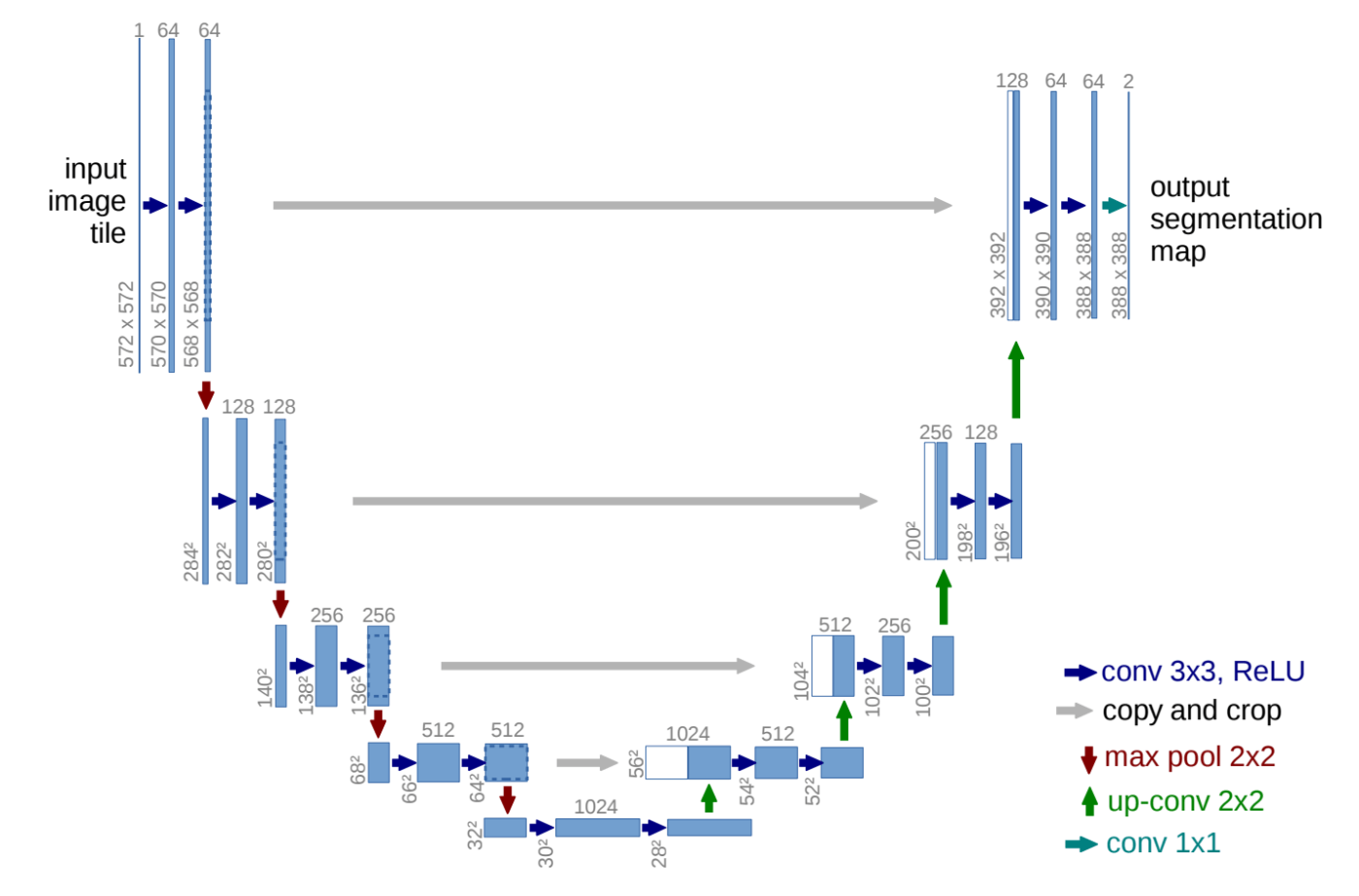
図5. UNetのアーキテクチャ
DDPM では上述のシンプルな損失関数で学習することで、Fréchet Inception Distance (FID) や Inception Score (IS) といった生成品質を評価する指標で高い性能を発揮することを示しました。
一方、共分散が等方的であるというのは強い制約で、対数尤度が低くなってしまうという問題があります。対数尤度を高くすることは、分布における全てのモード (峰)を捉えるのに非常に重要であることが知られており、さらに最近の研究では対数尤度の微小な向上でも生成品質に大きく影響することも知られています。そこで IDDPM では DDPM のように簡略化しない損失関数を用いて
Vision-Transformer
Transformer については知っている人も多いでしょう。これは 自然言語処理 (NLP) の文脈で提案されたモデルで、Attention 機構という、入力系列の中で注目する箇所の情報を抽出するようなパーツをフルに活用したモデルです。このモデルの登場により、NLPにおけるさまざまなタスクの性能が飛躍的に向上しました。また、ChatGPT に代表される、大規模言語モデル (LLM) を構成する主要なモジュールも Transformer です。
Vision-Transformer (ViT) はこのような NLP における成功を画像にも適用したいというモチベーションで提案された手法です。しかし、テキストのような情報と画像では形式が全く異なります。そこで、以下の3ステップで Transformer への入力を構成します。
- パッチと呼ばれる小領域に分解する
- 各パッチの画像を引き延ばしてベクトルとして扱う
- 引き延ばしたベクトルを線形変換する
例えば

図6. ViT の入力
以降は Transformer と同様で、位置符号を加えて入力します (図7)。
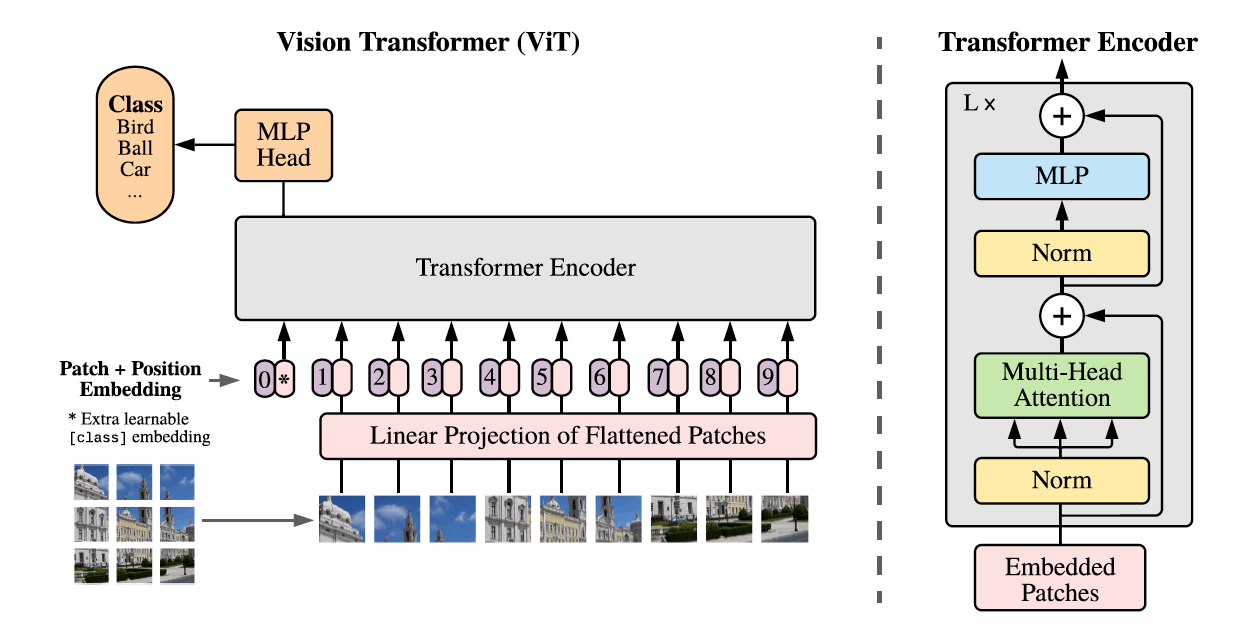
図7. ViT の全体像
Diffusion-Transformer
Diffusion-Transformer (DiT) では、IDDPM と同様に
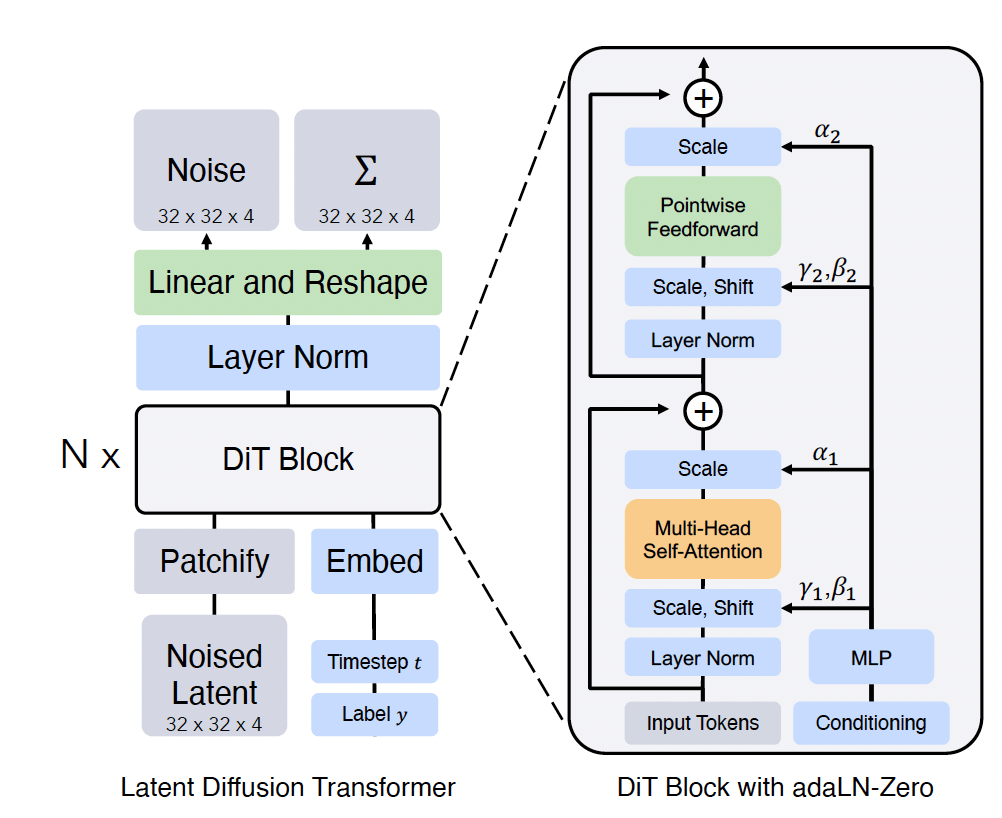
図8. DiT のアーキテクチャ
DDPM や IDDPM では、画素の空間で拡散モデルを学習していましたが、DiT では Stable Diffusion 等で用いられる Latent Diffusion と呼ばれる方法を用いています。 Latent Diffusion では、画像を低次元ベクトル (潜在ベクトル) に変換する Encoder と、低次元ベクトルから元の画像を復元する Decoder を用います。Encoder と Decoder 自体は拡散モデルとは別に学習された VAE 等で、拡散モデルは低次元ベクトルの空間 (潜在空間) 中での生成を学習します。これによって高解像度かつ高品質な生成が可能になりました。
DiT は潜在ベクトルの他に、時刻 (ステップ)
実験としては ImageNet データセットに対してクラスラベルで条件付けた生成を行なっています。画像サイズは
結果は下の表の通りで、FID や IS の意味で直近の SOTA モデルよりも性能が高いです。
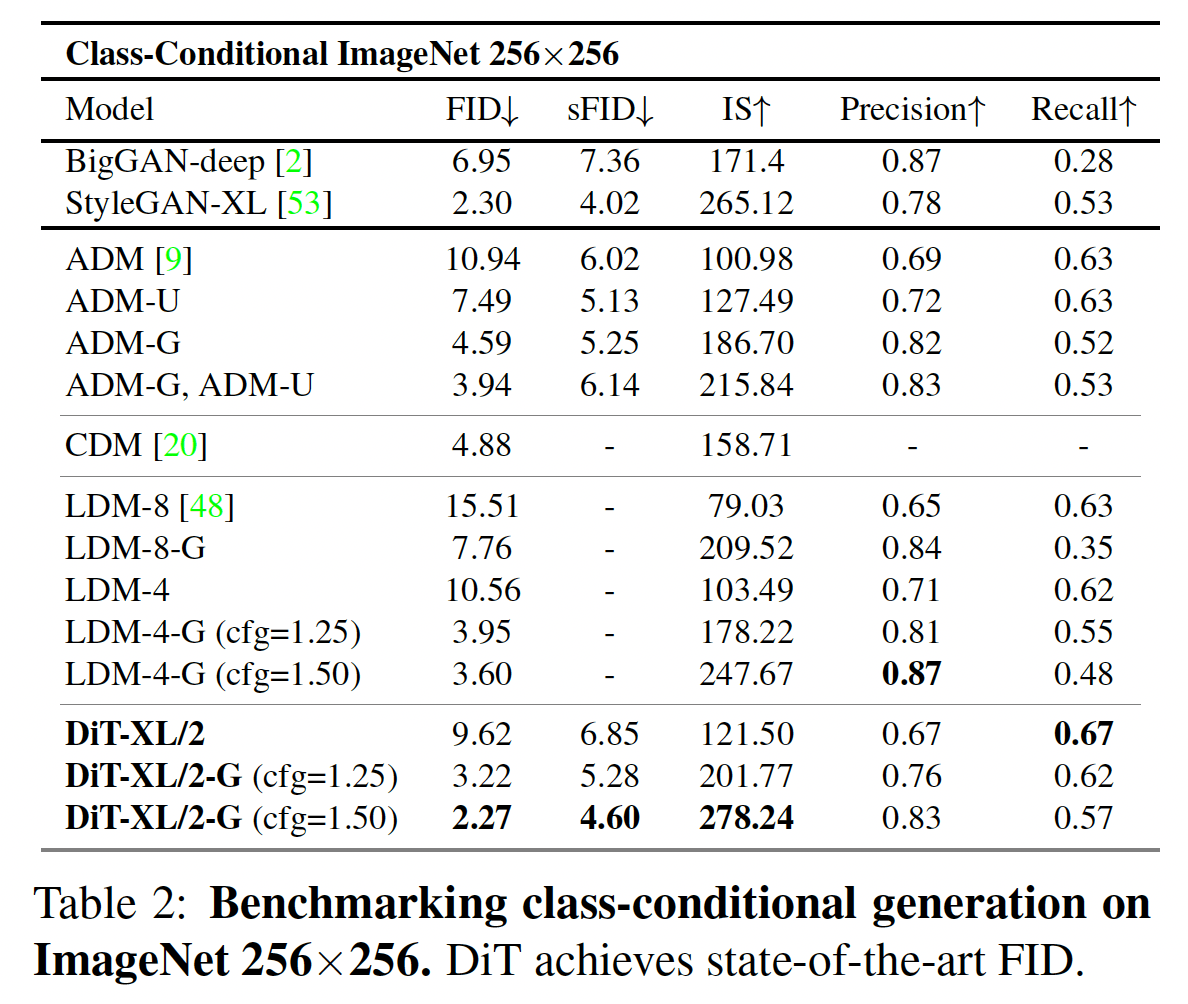
図9. 256×256の評価結果
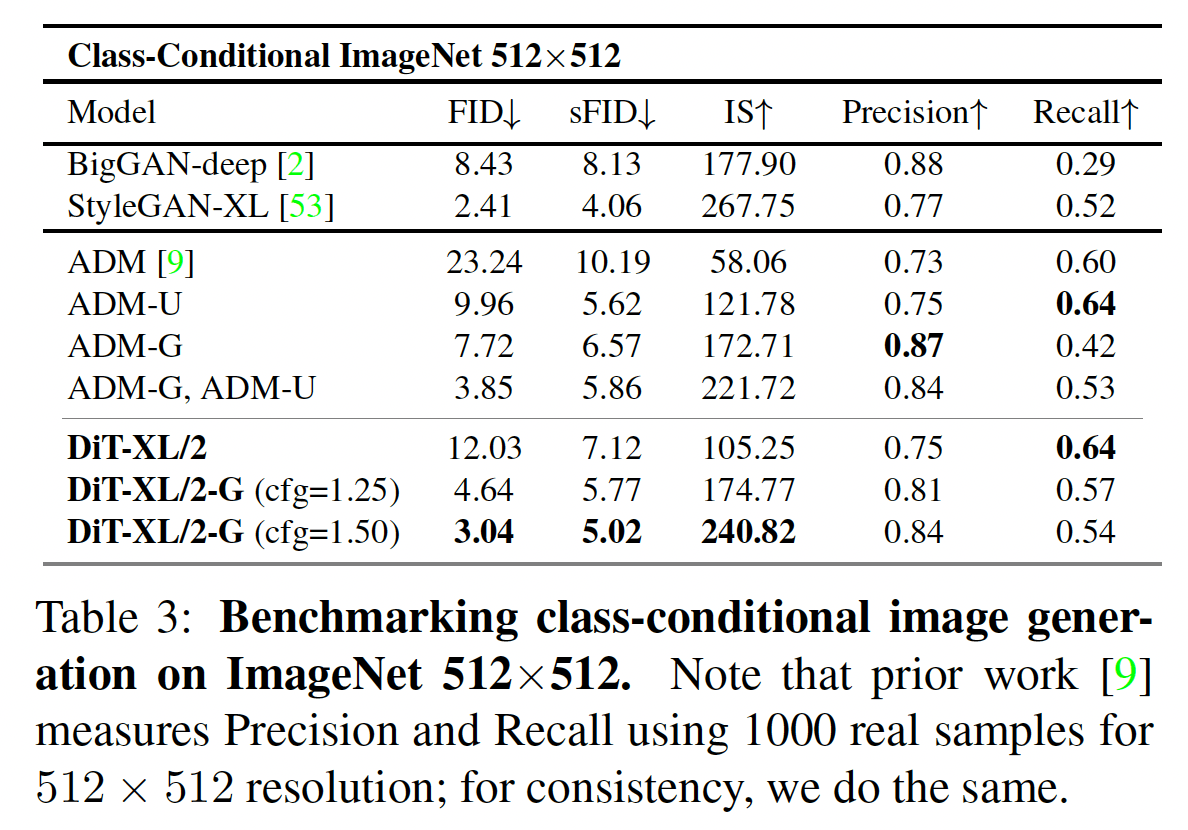
図10. 512×512の評価結果
生成された画像の一例を図11に示します。

図11. DiT による生成のサンプル
図からわかるように、Transformer のサイズを大きくすること、パッチサイズを小さくすること (パッチ数を多くすること) の両方が生成品質に寄与しています。
まとめ
DiT はノイズの予測を UNet から ViT に変更し、Sora は画像を時間方向に拡張するというどちらもシンプルなアイディアによるものでした。動画生成において今回のような非常に高いクオリティが出せた要因はモデルを大規模化したこと、データを大量に用いたことがほとんどだと考えられます。大規模言語モデルでもそうですが、コンピュータビジョンにも大規模化の波を感じました。
動画をプロンプトとして扱い、フレーム予測によって深度推定やセグメンテーションなどの様々なタスクを解く手法も提案されています。このような next frame predictionという枠組みは、言語モデルの next word prediction と対応します。そのため、タスクに関する説明や例示を用いた In-Context Learning や、特定のタスクに特化するための Instruction Tuning が画像タスクでも可能であると考えられます。
言語タスクの多くは ChatGPT の API によって機械学習を専門としないエンジニアにも広く使えるようになってきました。Sora の API が公開された場合、コンピュータビジョン分野においても同様に多くの人が今以上にアプリケーションを作りやすくなると考えられます。
参考文献
- T. Brooks et al., “Video generation models as world simulators,” 2024, [Online]. Available: https://openai.com/research/video-generation-models-as-world-simulators
- J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” Adv. Neural Inf. Process. Syst., vol. 33, pp. 6840–6851, 2020.
- A. Q. Nichol and P. Dhariwal, “Improved Denoising Diffusion Probabilistic Models,” in Proceedings of the 38th International Conference on Machine Learning, M. Meila and T. Zhang, Eds., in Proceedings of Machine Learning Research, vol. 139. PMLR, 18--24 Jul 2021, pp. 8162–8171.
- A. Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” in International Conference on Learning Representations, 2021. Available: https://openreview.net/forum?id=YicbFdNTTy
- W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4195–4205.
- S. Yang et al., “Video as the new language for real-world decision making,” Feb. 2024, [Online]. Available: https://openai.com/research/video-generation-models-as-world-simulators

Discussion