初めまして!
株式会社 Elith で Computer Vision Reseacher をしている下村です。
今回は、Open-Vocabulary Object Detection の論文について、学習データに焦点を当てた手法を中心に概要を紹介します。本記事内で使用する図は参考文献から引用しています。
Open-Vocabulary Object Detection とは
Open-Vocabulary Object Detection (OVD) は、事前に定義された物体クラスに制限されず、任意のテキスト (Open-Vocabulary) で指定された未知の物体クラスを検出するタスクです。この手法は、従来の弱教師あり学習やゼロショット学習に比べて高い精度を達成します。
この手法は、2021年のコンピュータビジョンやパターン認識に関する国際会議 CVPR(Computer Vision and Pattern Recognition) で「 Open-Vocabulary Object Detection Using Captions 」の論文で初めて提案されました。その後も、Open-Vocabulary に関する多くの研究が行われ2023年 CVPRの論文投稿数は前年度と比べ500%(5 -> 18 本) 増加し盛り上がりを見せています。
OVD と従来手法との違い
-
弱教師あり学習
弱教師あり学習では、部分的なラベルや不完全なデータを用いてモデルを学習します。しかし、これには限界があり、特定の物体クラスに対する精度が低い場合が多いです。 -
ゼロショット学習
ゼロショット学習は、学習データに含まれていないクラスの物体も識別できるように設計されています。しかし、一般的に未知のクラスに対する精度が低いため実用には限界があります。 -
OVD の優れた点
OVD は、任意のテキストで指定された未知の物体クラスに対しても高い精度で検出が可能です。これは、弱教師あり学習やゼロショット学習では達成困難でした。
Open-Vocabulary Object Detection Using Captions[A.Zareian+, CVPR2021]
本論文では、画像キャプションデータを使って豊富な語彙情報と画像特徴の類似度を高めるような事前学習 (Grounding) により精度の向上を実現しています。
以下に OVD の概要図を示しています。
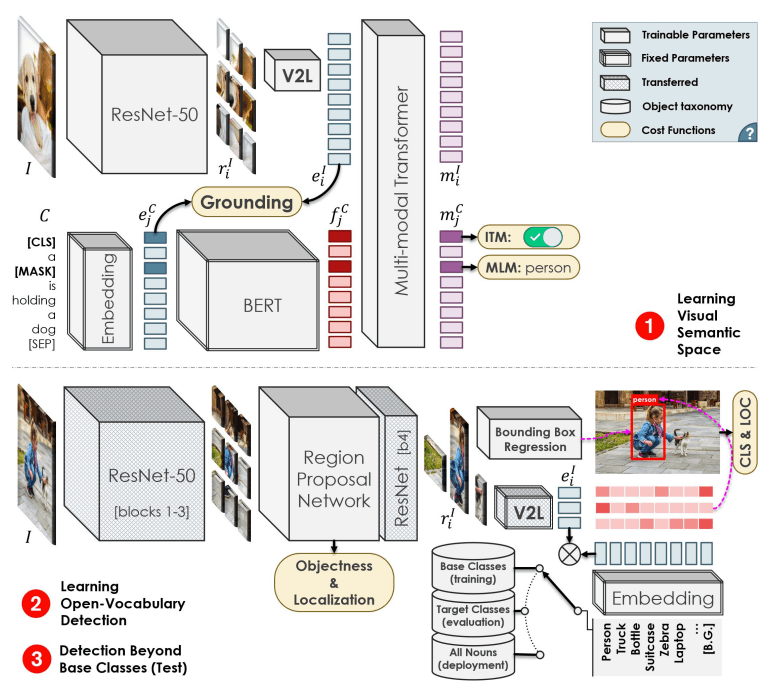
OVD モデルアーキテクチャ
OVD の学習はモデルは大きく二つのフェーズに分かれています:
-
Visual Semantic Space の事前学習: ここで Grounding を行い、画像とテキストの埋め込み空間の一貫性を高めます。
- Grounding の重要性: 画像キャプションデータを用いて、豊富な語彙情報と画像特徴の一貫性 (Grounding) を強化します。
- 学習の安定化: Image-Text Matching と Masked Language Model を組み合わせることで、学習過程を安定化させています。
- Open-Vocabulary Detection の学習: 特定の語彙に依存しない物体検出を行います。
Visual Semantic Space の事前学習
- 多様な Embedding: 画像は ResNet-50 と Vision to Language(V2L) 層を通過し Image embedding
e^I_i e^c_j - Multi-modal Transformer: 最終的に、これらの embedding を集約し Multi-modal Transformer に入力します。出力は画像と単語に対応する
m^I_i m^C_j - Implicit Matching Challenge: 各キャプション
e^c_j e^I_i
Weakly Supervised Grounding
本論文では、Weakly Supervised Grounding を採用します。具体的には、各画像-キャプションペアに対し、以下のように global grounding score
ここで
このスコアが高ければ、画像とキャプションが高い確率で一致しているという意味になります。このスコアを最大化し、一致しないペアに対しては最小化するように学習します。その際、バッチ内の他の画像を各キャプションの負例、他のキャプションを各画像の負例として扱います。
最終的な grounding 損失は以下のように定義します。
ここで
grounding 損失の最適化により、画像内の各領域を最も表現可能な単語と対応付けることが可能です。
Masaked Language Model
Visual Semantic Space の事前学習の際、grounding 損失のみではモデルが正しい画像-キャプションを選択するために必要な最小限の知識のみを学習してしまう問題があります。そこで、PixelBERT に従い、Masked Language Model (MLM) を採用しています。
- マスク処理: 各キャプションの単語を [MASK] に置き換えます。
-
単語予測: マスクされたトークンを
m^C_j

Masked Language Model
以上の手法により、OVD は高度な画像-テキスト一貫性 (grounding) と文脈に依存した言語モデリング能力を同時に獲得しています。これにより、未知のオブジェクトに対してもロバストな性能を発揮することが期待されます。
また、Image-Text Matching も併せて導入することで学習の安定化を図ります。
Image-Text Matching
最終的に Image backbone,V2L 層 ,Multi-modal Transformer は以下の損失関数を用いて最適化します。
-
\mathcal{L}_G(I) \mathcal{L}_G(C) -
\mathcal{L}_{MLM} -
\mathcal{L}_{ITM}
提案された損失関数によって、OVD は画像とテキストの高度な対応関係 (grounding)、文脈に依存した言語理解 (MLM)、そして画像とテキストの一致性 (ITM) を同時に最適化します。
提案手法での性能評価
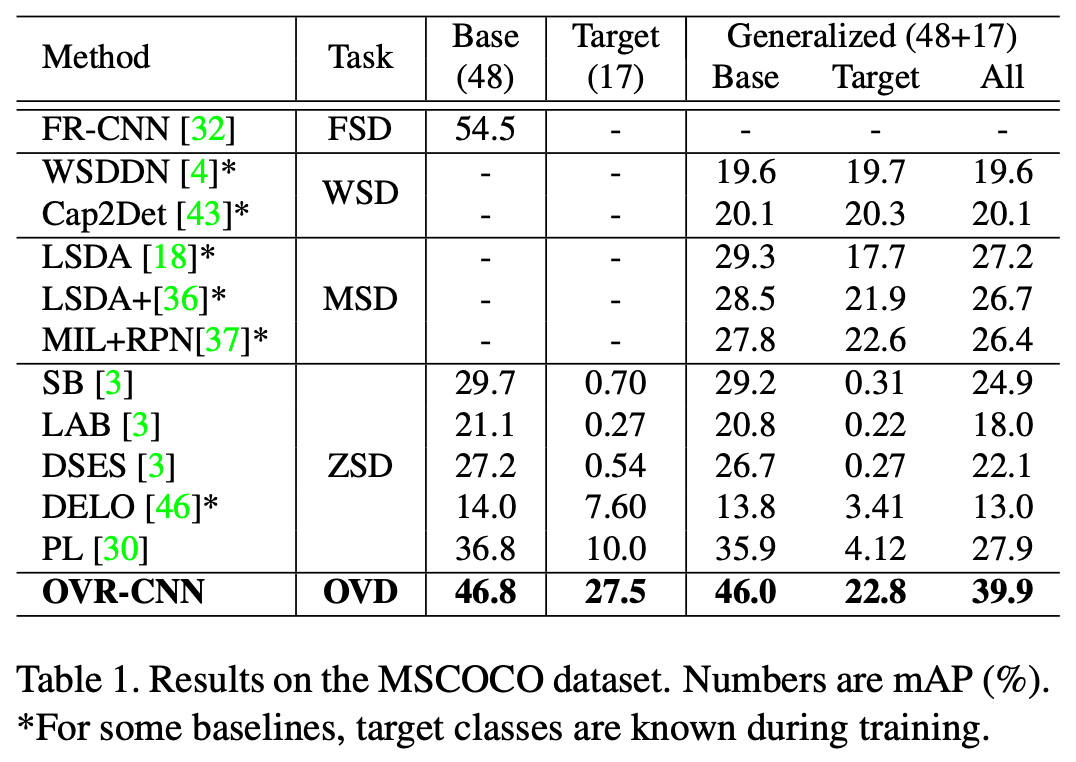
MSCOCO データセットでの定量的評価
提案手法の性能は極めて高く、MSCOCO データセットでの評価では、従来の手法に比べて mAP(Mean Average Precision) が10ポイント前後向上しています。mAP は、閾値ごとの適合率 Precision を加重平均し計算した AP を各クラスで平均します。
Open vocabulary Object Detection with Pseudo Bounding-box Labels[M.Gao+, ECCV2022]
物体検出の研究は急速に進展していますが、学習データの Bounding box アノテーションには多くの人的コストがかかります。本論文では、この問題に対する一解として、画像キャプションデータを用いて Pseudo-Bounding box を生成する手法を提案します。
Pseudo-Bounding box 生成プロセスの概要
以下に Pseudo-Bounding box 生成プロセスの概要図を示しています。
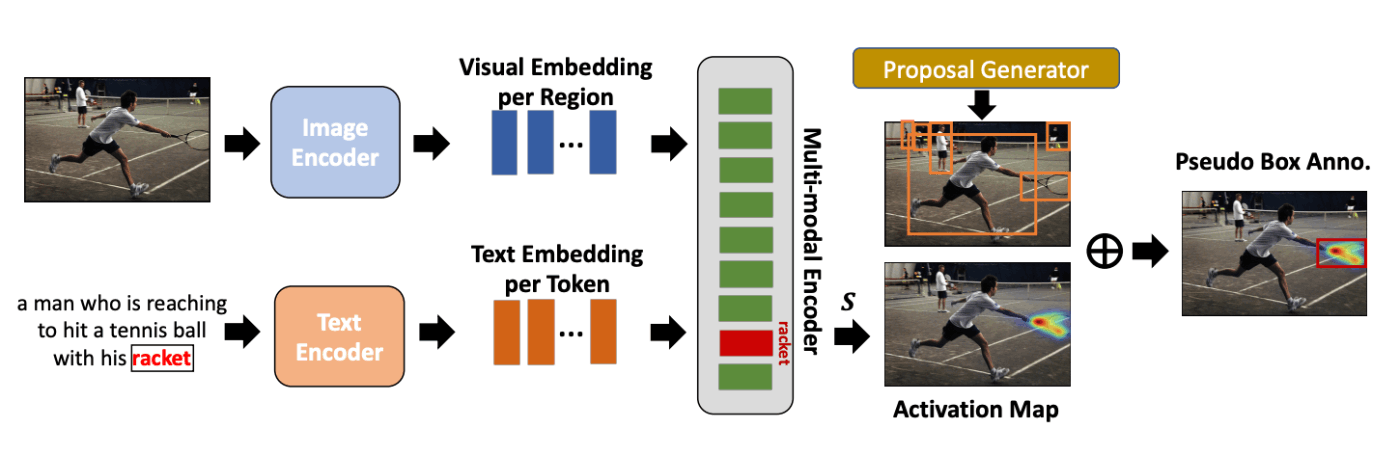
Pseudo-Bounding box生成プロセス
- 画像とキャプションのエンコーディング: 画像とキャプションペアをそれぞれ Image Encoder と Text Encoder に入力し、Embedding( 埋め込み ) を獲得します。
- マルチモーダルな特徴の獲得: Cross Attention を用いて、画像特徴とキャプション特徴の相互作用を通し、マルチモーダルな特徴を獲得します。
- Activation Map の計算: キャプション内に含まれる既知の単語 ( 図の場合は "racket" ) のActivation Map を Grad-CAM により計算します。
- Pseudo-Bounding Box の生成: Proposal Generator が生成した Bounding box と Activation Map の中から最も領域重複度が高い物体に対して、Pseudo-Bounding box を生成します。
以上の方法によって作られた大規模データセットを用いて検出機を学習します。
ネットワークの学習プロセス
検出機の学習概要図を以下に示します。
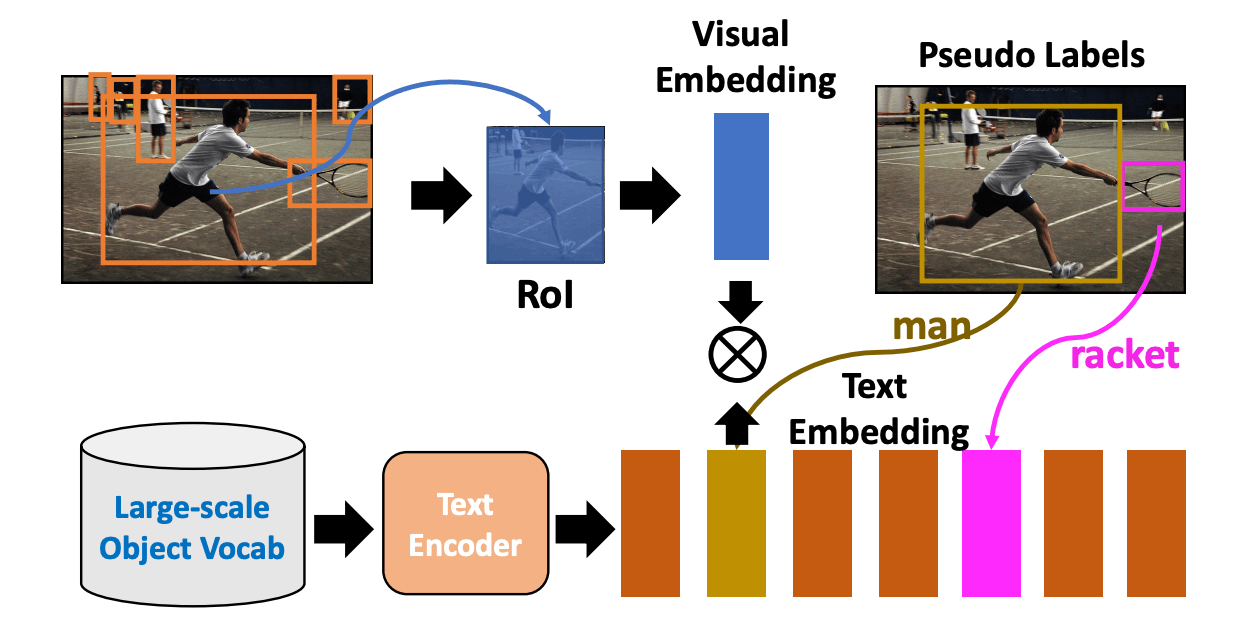
ネットワークの学習概要
- 画像エンコーディング: 入力画像は Image Encoder と Region Proposal Network(RPN) によって処理します。
-
領域ベースの Visual Embedding: RoI Align / RoI Pooling を Region Proposals に適応し、領域ベースの Visual Embedding
R=\{r_1,r_2,...,r_{Nr}\} N_r -
Text Embedding の獲得: 対応するキャプションを Text Encoder に入力し、Text Embedding
C=\{bg, c_1, c_2,...c_{Nc}\} N_c bg -
マッチング確率の計算: 同一オブジェクトの Visual Embedding と Text Embedding を近づけ、異なるオブジェクトの Embedding を遠ざけるように学習を行います。
r_j c_j
提案手法による性能評価
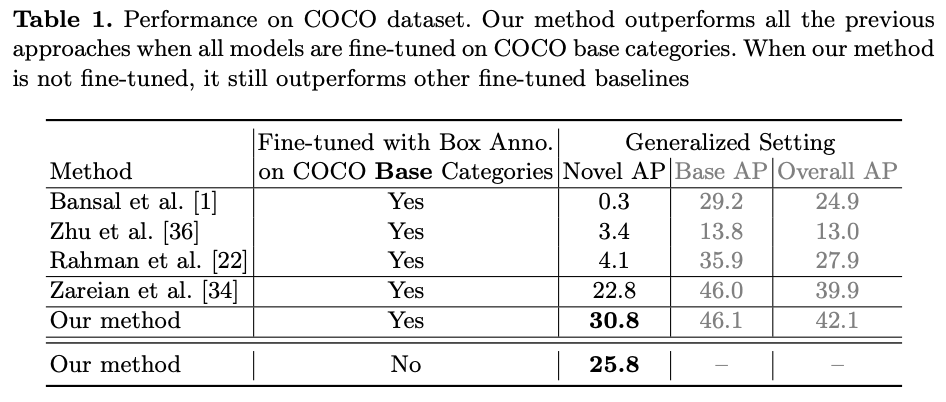
COCO データセットにおける定量的評価
表は COCO データセットにおける定量的評価結果になります。提案手法は、ファインチューニングの有無に限らず全てのベースライン手法の精度を大幅に上回っています。
また、以下の表は複数のデータセットでの定量的評価になります。COCO データセットに限らず、様々なデータセットに対しファインチューニングなしで従来手法を大幅に上回る結果となります。
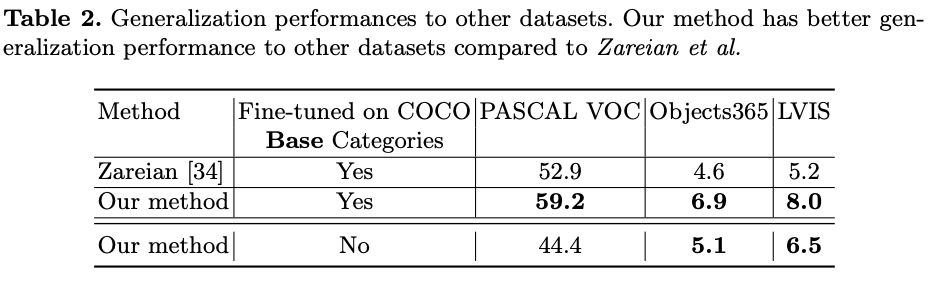
様々なデータセットでの定量的評価
Detecting Twenty-thousand Classes using Image-level Supervision[X.Zhou+, ECCV2022]
本論文では、物体認識データセットでは獲得な語彙数に限界がある問題を物体認識データセットの利用によって解決します。
データセットの規模と語彙サイズの限界
物体検出データセットは通常、高いコストをかけて作成します。しかし、物体認識データセットと比較すると、物体クラスと総画像枚数に大きな差があります。これにより、物体検出データセットの規模が小さく、語彙サイズにも限界が生じます。
LVIS と他のデータセットの比較
以下の図は、OVD のベンチマークデータセットである LVIS と、ImageNet や Conceptual Captions(CC) データセットとの比較を示しています。LVIS が各物体クラスの種類やサンプル数において大きく劣っていることが確認できます。
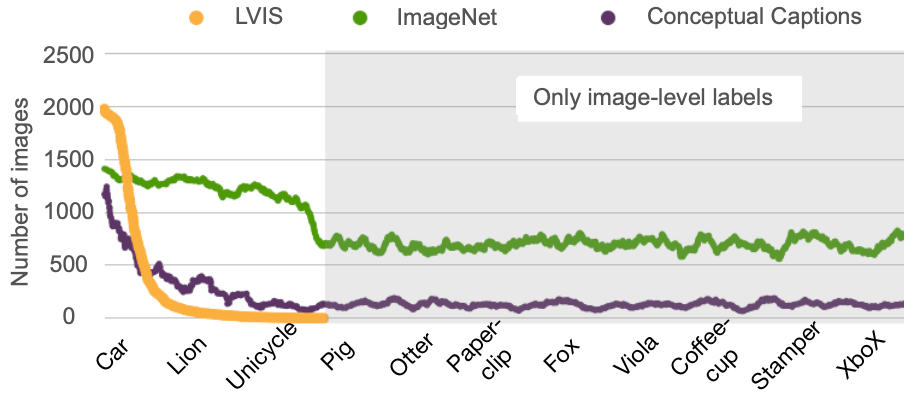
各データセットのクラスごとの画像枚数
提案手法:物体認識データセットでの学習
本研究では、物体検出モデル内の分類器を物体認識データセットで学習することにより、検出器の語彙を数万概念まで拡張します。
Bounding Box とラベルの付与
提案手法では、非常にシンプルな方法で画像認識データセットに Bounding box とラベルを付与します。
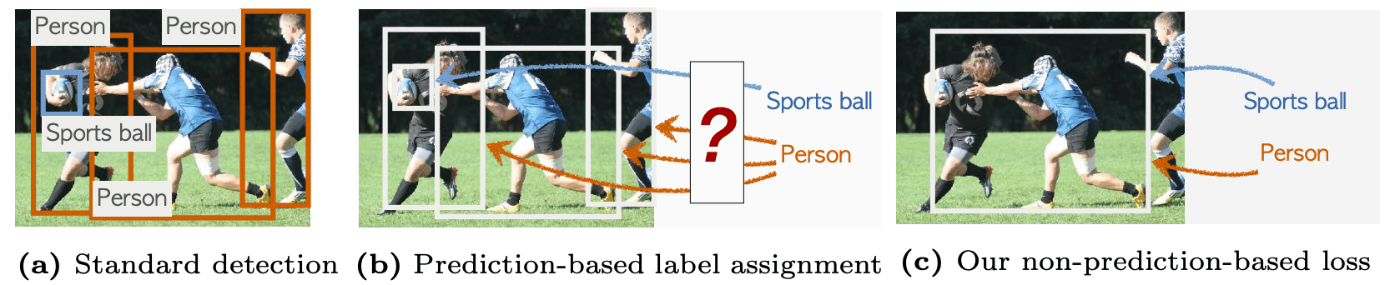
従来手法との Bounding Box 割り当て戦略の違い
(a) は一般的な教師あり物体検出を示し、ground-truth のラベル付き Bounding box が必要です。
(b) では、従来の弱教師あり学習を示し、学習済みモデルによるプロポーザルに対して画像ラベルを付与します。
(c) の提案手法では、画像ラベルを最大のプロポーザルに割り当てる非常にシンプルな方法を採用します。
Detic: 統合された物体検出と物体認識の学習方法
Detic(Detector with Image Classes) は、物体検出データセットと物体認識データセットを共同学習する手法です。以下の図に学習プロセスを示します。

Detic の学習プロセス
図の (a),(b) はそれぞれ物体検出データセットと物体認識データセットに対する処理を示します。
物体検出データセットに対する損失関数
図の (a) に示されているような物体検出データセットでは、2段階検出器の標準的な損失関数を用います。
物体認識データセットに対する損失関数
図の (b) に示すように、物体認識データの場合は最も大きいプロポーザルを用いて損失計算を行います。ここで
最終的な損失関数は以下のようになります。
Detic では、オブジェクトスコアが最大のプロポーザルを用いた損失関数も比較実験されています。この損失関数は以下のように定義されます。ここで、
提案手法による定量的評価
以下の表は、提案手法とベースライン手法との比較結果を示しています。
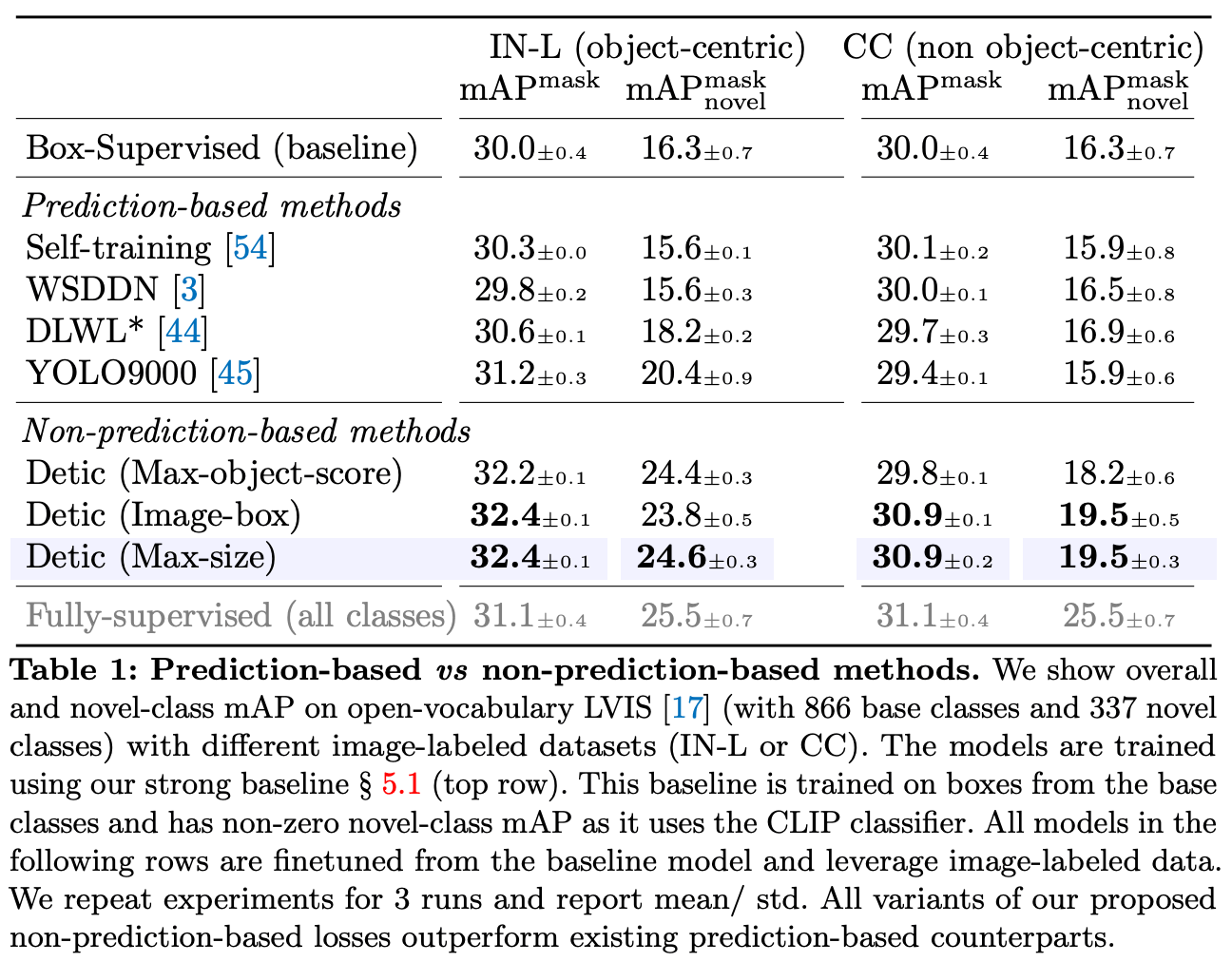
IN-L と CC での定量的評価
こちらは、Open-Vocabulary LVIS データセットと IN-L (ImageNet-21K と LVIS で重複する997クラスに限定したサブセット )、CC を用いた場合の定量的評価になります。
ベースライン手法と比較して、提案手法は精度が軒並み向上していることがわかります。最も大きいプロポーザルを用いた場合の精度が高い原因は、ターゲットとするオブジェクトを安定してプロポーザルないに収めることが可能な点です。また、オブジェクトに対し、学習期間を通して一貫性を持ったプロポーザルを提案できることです。
従来手法の限界として初期検出の依存性が考えられます。従来の方法では、予測した Bounding box に画像ラベルを割り当てるアプローチが取られていますが、これは初期検出の精度に大きく依存します。初期検出が信頼できる場合は、理想的である一方 Open-Vocabulary においては、十分に信頼できる初期検出が不可能です。
Open-Vocabulary Object Detection using Pseudo Caption Labels[M.Gao+, arXiv2023]
本論文では Pseudo-Caption Labeling 手法を提案します。
提案手法によってオブジェクトの名前だけでなく、その属性や関係性など、新しいオブジェクトに関する多角的な情報を提供します。
以下の図のように、人手で付与されたキャプションとは異なる表現を持つ情報が増えることで既知のオブジェクトクラス (犬や猫) だけでなく、未知のオブジェクトクラス (椅子) を表現する可能性が高くなります。
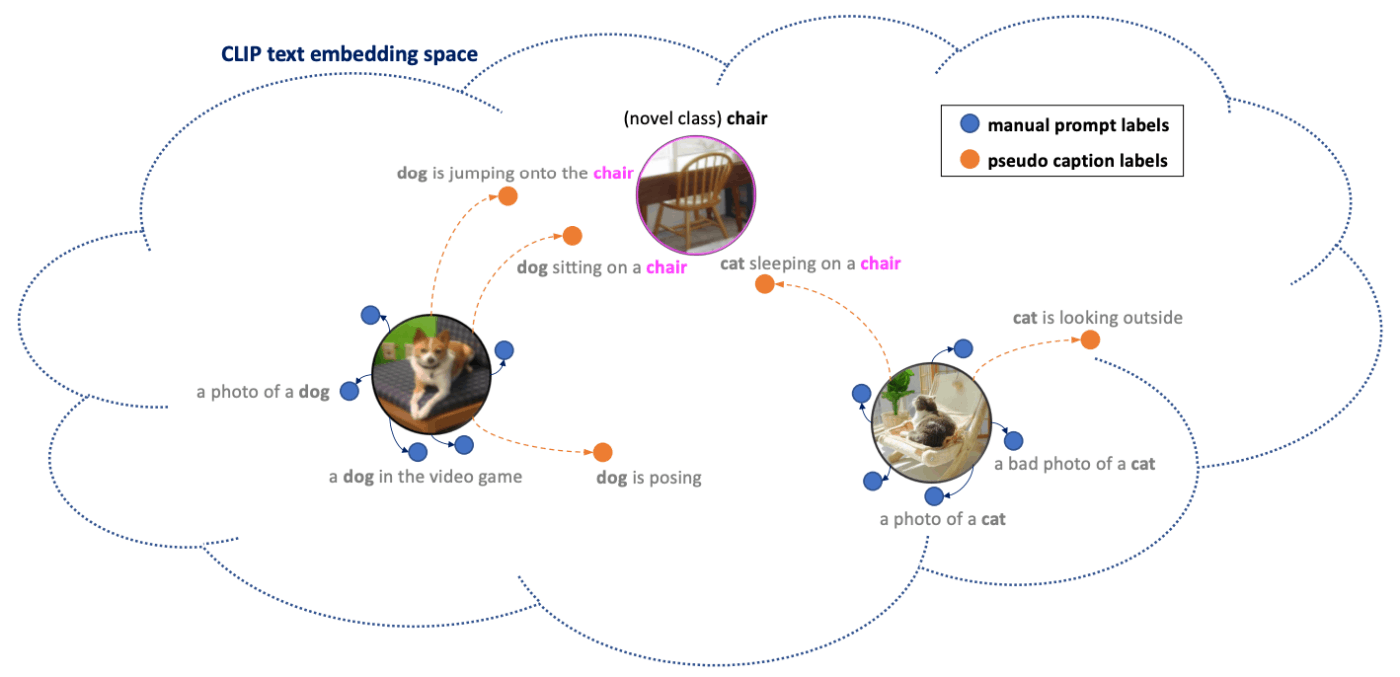
CLIP のテキスト潜在空間における犬・猫のオブジェクトインスタンスの Distillation points
Pseudo-Caption Labeling のフレームワーク
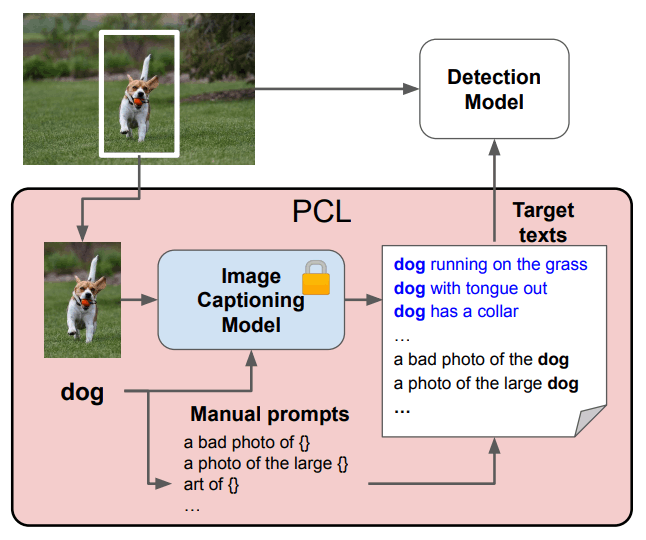
Pseudo-Caption Labeling のフレームワーク概要
Pseudo-Caption Labeling は以下の4段階のプロセスによって行われます。
- 画像からターゲットオブジェクトをクロップ。
- クロップした画像をキャプションモデルに入力。
- キャプション生成時に、ターゲットオブジェクトに明示的に言及するために、接頭辞にオブジェクト名を与える。
- ターゲットオブジェクトに関するキャプションを K 個集める。
キャプションモデルの工夫
通常画像キャプションモデルは、任意の画像
ここで,
学習データには Cenceptual Captions 3M, Cenceptual Captions 12M, MSCOCO, Visual Genome からなる大規模キャプションデータセットの組み合せから構成します。
このような大規模キャプションデータセット利用することで、キャプションデーモデルの視覚言語能力を向上させる一方で各データセットのキャプションスタイルの影響によりターゲットオブジェクトに無関係なキャプションを生成する可能性があります。
そのため、出力されるキャプションスタイルを制御するために以下のようなスタイル調整メカニズムを導入し以下のように定式化します。
ここで変数
提案手法の性能評価とアブレーション実験
Pseudo-Caption Labeling による精度向上
提案手法での定量的評価結果は以下の図に示されています。この結果から、Pseudo-Caption Labeling によって新規オブジェクトの検出精度が明確に向上していることが確認できます。
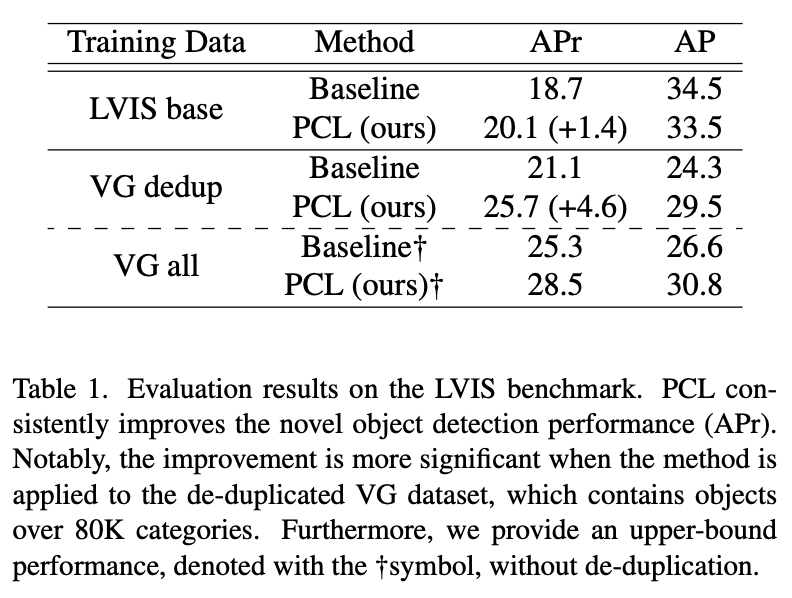
LVIS データセットでの提案手法での定量的評価
アブレーション実験
本論文では興味深いアブレーション結果が得られています。定量的評価を以下の図に示します。
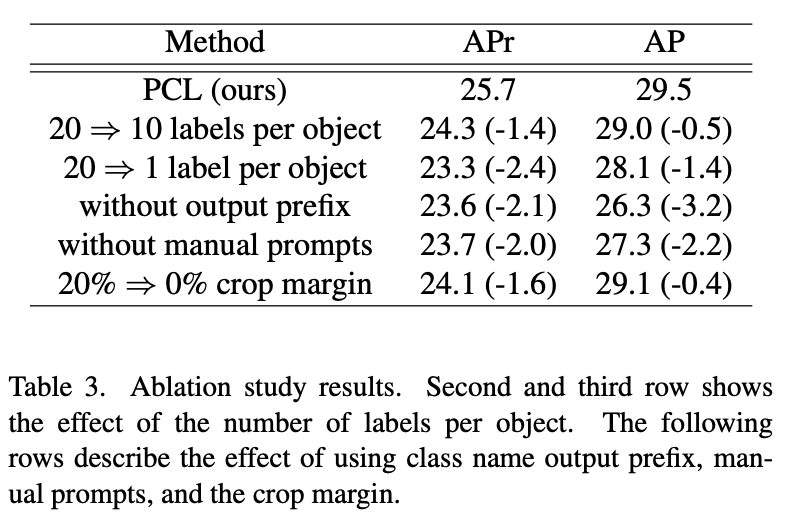
提案手法でのアブレーション解析
キャプション数と精度
図は、採用するラベル数に応じてモデルの精度がどのように変化するかを示しています。1行目の結果においては、20 個のラベルで学習したモデルが 80% の擬似キャプションと 20% の人手で付与されたキャプションを用いています。2・3行目の結果も合わせて、キャプション数が減少すると精度も比例して低下することが確認できます。
人手によるキャプションの重要性
特に注目すべきは、5行目の実験結果です。この実験では、人手で付与されたキャプションを一切使用せずに学習をしたところ、精度が大きく低下しています。これは、学習時と推論時に使用するキャプションには一貫性が求められているという重要な指摘です。
展望:V2L モデルの進歩と人手アノテーションの必要性
現在、V2L モデルの急速な進展により、人間に近いキャプションの生成が可能になっています。この進展によって、今後は人手によるアノテーションが不要になる可能性も高まっています。しかし、学習・推論を通してキャプションの一貫性がない場合は精度低下に繋がるため Pseudo-Caption の使い方には注意が必要です。
まとめ
本記事では、OVD について学習データに焦点を当てた手法を中心に概要を紹介しました。プロンプトの工夫や学習に使用するキャプションの工夫で、ドメインの変化や特定のシーンに zero-shot で対応が可能だと考えられます。OVD の研究は盛り上がりを見せており、CLIP や DETR・GPT の採用など今後の研究動向が楽しみな分野だと個人的に思います。
株式会社 Elith では、深層学習や機械学習を活用した社会問題の解決だけでなく、常に最新の技術動向を調査しています。
最後に宣伝となりますが、株式会社Elithは最先端のAI技術をビジネスに実装し、価値を生み出すテックカンパニーです。
最近ではLLMの活用に関して様々な取り組みをしており、多数のイベントにも登壇しています。
少しでも興味がある方は、X(旧Twitter)経由やElithのWebページ経由で、是非気軽にお話を聞きにきてください。
参考文献
- Open-Vocabulary Object Detection Using Captions[A.Zareian+, CVPR2021]
- Open vocabulary Object Detection with Pseudo Bounding-box Labels[M.Gao+, ECCV2022]
- Detecting Twenty-thousand Classes using Image-level Supervision[X.Zhou+, ECCV2022]
- Open-Vocabulary Object Detection using Pseudo Caption Labels[M.Gao+, arXiv2023]
- Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization[RR.Selvaraju+, CVPR2017]
- Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning[P.Sharma, ACL2018]
- Microsoft COCO: Common Objects in Context[T.Lin, ECCV2014]
- LVIS: A Dataset for Large Vocabulary Instance Segmentation[A.Gupta, CVPR2017]
- Visual genome: Connecting language and vision using crowdsourced dense image annotations[R.Krishna, IJCV2017]
- Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers[Z.Huang+, arxive2022]
- Learning Transferable Visual Models From Natural Language Supervision[A.Radford+, ICML2021]
- End-to-End Object Detection with Transformers[N.Carion+,ECCV2020]

Discussion