はじめに
株式会社 Elith で Computer Vision Reseacher をしている下村です。
今年の9月24日から9月27日にカナダ・エドモントンで開催された高度道路交通システム分野の主要国際会議であるIEEE ITSC 2024 に参加し、本田技術研究所との共同研究の成果である「How to extend the dataset to account for traffic risk considering the surrounding environment」を発表しました。本記事では、その発表内容の解説と今後の研究展望について述べます。
研究概要
本研究では、走行シーンにおける自然言語記述を通じて、道路構造に起因する静的な交通リスクを考慮し説明するためのデータセット拡張手法を提案しています。提案手法では、効率的なデータ選択を実現するために、GISデータと機械学習モデルの説明性を活用し、交通リスクの高い地域を選定します。さらに、機械学習モデルの説明性を利用して、交通事故リスクの予測に高い寄与度を持つ道路構造情報を抽出することで、道路構造に起因する静的な交通リスクを考慮した説明が可能になります。
研究背景
走行シーンにおいて、視覚情報を基にした周囲の状況認識は、自動運転や先進運転支援システム(ADAS)の安全な実現において、特に複雑で車両の走行量が多い市街地や大都市のシナリオで不可欠な技術です。
既存のシステムは、道路交通システムが十分に発達した地域では実運用に耐える安全性を提供します。しかし、多くのシステムはカメラやLiDARベースの手法であり、これらのセンサーで認識可能な物体にのみ対応しています。そのため、停車車両の影や交差点などの死角から突然飛び出す歩行者や車両に対応するのが難しく、センサーに映った時には対応が間に合わないケースがあります。また、道路交通システムが十分に発展していない地域では、こうしたシステムが十分な安全性を提供することが難しい状況です。したがって、安全な自動運転の実現には自動運転アルゴリズムの改良のみならず、道路交通システム(インフラ)の改善も重要だと考えられます。
道路交通システムの改善には、一般的に以下のようなフローが採用されます。
- 交通事故多発地点などの道路交通システムに問題がある箇所を列挙。
- 人手による現地調査を通じて情報を収集・分析。
- 必要に応じて道路交通システムの改善施策を実施。
上記のような従来の方法では、実際に道路交通システムの改善が行われるまでに多くの人手と時間を要します。そこで、フローの1および2を自動化することでコスト削減とプロセスの高速化を図るためのデータセット構築手法とベースラインとなるフレームワークを提案しました。
フレームワーク
本章では、提案するフレームワークについて紹介します。

提案手法のフレームワーク概要
データセットの構築
本研究では、既存のカメラ画像と対応するGISデータを用いて、交通リスク分析のためのデータセットを構築しました。このデータセットは、将来的な応用を視野に入れ、任意のサイズにスケール可能な形式を念頭に置き、GPT-4を活用して自動生成しています。
道路交通システムの改善に役立つデータセットを構築するにあたって、改善の必要がない地域のデータ(ノイズ)を除外するため、オープンアクセス可能なGISデータおよび統計データを活用しました。
データセットの構築フローは以下のようになります。
- GISデータを説明変数、交通事故の発生の有無を目的変数とする分類モデルを構築。
- 未学習の地域に対して交通事故発生確率を予測し、発生確率の高い座標の画像を抽出。
- 抽出された画像と対応するGISデータ、そしてプロンプトをGPT-4 Visionに与え、画像に含まれる交通リスク情報を生成。
以下では、上記のフローについて詳細に解説します。
1.交通事故発生予測モデルの構築
本研究では、オハイオ州運輸局が公開している交通事故データと道路ネットワーク情報を使用しています。また、アメリカ地質調査所およびオレゴン州立大学が提供する地形、気象、土地利用データも、交通事故発生時の特徴量として活用しています。これらの特徴量を基に、勾配ブースティングモデルの一つであるXGBoostを用いて交通事故発生予測モデルを構築しました。
2.高リスク地点の画像抽出
学習済みモデルを用いて、オハイオ州の一部地域における交通事故発生確率を予測します。対象地点には道路ネットワークの座標情報が活用され、以下の画像のようにヒートマップとして可視化することも可能です。本研究では、高リスク地点の抽出を目的にして利用していますが、将来的には走行中の危険地点の警告システムとしても活用できると考えています。

交通リスクマップ
3.GPT-4 Visionを用いた交通リスク説明データセットの構築
本研究では、車両や歩行者に起因する動的なリスクだけでなく、道路標識や道路構造などに起因する静的なリスクを考慮することに焦点を当てています。静的な交通リスクとしての道路構造や地域情報を説明する正解キャプションを生成する際には、エゴカー周辺の有効な環境情報をプロンプトとして提供します。また、交通リスクの説明に効果的な環境情報を選定するため、交通事故発生予測モデルの学習に使用した特徴量の貢献度を活用しています。
また、特徴量の貢献度を評価するために、ゲーム理論のShapley値を応用した手法であるSHAPを使用して計算を行いました。最終的にキャプション生成に使用した特徴量は以下の通りです。

キャプション生成に利用した特徴量
次に、データセット構築時のプロンプトについて説明します。従来の研究では、走行中の周辺車両と同様に道路構造や静止物体が交通リスクの説明において重要な要素であるにもかかわらず、十分なアノテーションや説明が付与されていないことが課題とされています。本研究では、この点に着目し、静的リスク要因を考慮した道路環境リスク分析のためのキャプションデータセットの拡張を検討しています。
プロンプト手法としては、通常のFew-shotやCoT(Chain-of-Thought)などが一般的なLLMで有効ですが、本研究ではGISデータに含まれる数値データと画像内に映る物体を関連付けることが重要です。そこで、画像とGISデータの統合を可能にするため、新たに「Grounded Few-shot CoT」を提案しました。この手法では、キャプション生成の際に従うべき厳密なルールをspecificationsとして定義し、Few-shot ExampleにGISデータを考慮した理想的なサンプルを記述します。さらに、推論を段階的に行うために、「Let’s think step by step.」の文言を追加しています。
一般的に、CoTの効果を最大限に発揮するには60B以上のパラメータが有効とされていますが、GPT-4 Visionでのキャプション生成において、事前にCoTによる推論を用いたキャプションを生成することで、今後学習するVLMに対して、高品質かつ論理的な誤りが少ない知識を蒸留することが可能だと考えています。

GFCoTプロンプトの設計方法
交通リスクの説明モデル
本研究では、GPT-4 Visionによって生成されたキャプションを用いて学習するモデルとして、BLIPを採用しました。LLaVAをはじめとする高精度な手法が多く提案されていますが、今回はランニングコストや計算資源、Fine-tuningの難易度を考慮し、これらの手法の使用は見送りました。
各プロンプト手法で構築したデータセットの再現評価
定量的評価
以下の図に示すように、道路構造情報を考慮した静的な交通リスクの説明において、我々が提案するGFCoT(Grounded Few-shot Chain-of-Thought)を用いて作成した学習データを使用することで、GPT-4 Visionが生成する文章と意味的に高い類似性を持つ文章を生成できることを確認しました。
一方で、Recallの値が低くなる理由として、GPT-4 Visionを用いてデータセットを構築する際にCoT(Chain-of-Thought)を使用することで、連鎖的な思考が行われた結果、生成される文章に画像から直接読み取れる情報以外の要素が含まれてしまうことが原因だと考えています.
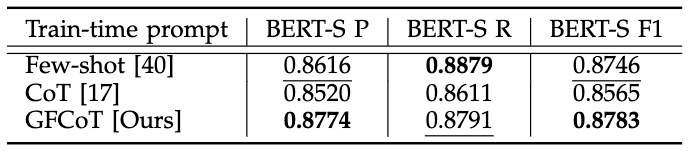
定量的評価結果
定性的評価

定性的評価結果
Few-shotで生成したデータセットを用いて学習したモデルの出力は、道路構造による危険性に言及できているものの、道路構造を理由とした交通リスクにおいて論理的な意味構造に誤りが見られます。一方、CoT(Chain-of-Thought)を用いたモデルの出力では、与えられたシーンについて詳細に説明することは可能ですが、道路構造情報を活用した交通リスクの説明には不十分な点が見受けられます。GFCoT(Grounded Few-shot CoT)を用いたモデルの出力では、シーンに含まれる交通リスクを説明しつつ、道路構造情報から想定される事故形態を論理的に述べることが可能になっています。
現状の課題と今後の展望
現状、オープンアクセス可能なGISデータや事故の統計データを取得可能な地域のみに適応可能な限定的な手法となっています。また、ベースラインとして利用したBLIPモデルはパラメータ数も少なくハンドリング性は高いですが、モデルの性能としては改善の余地が多くあります。
GISデータや事故の統計データを取得できない地域での活用を考えると、モデルの汎化性能の向上やシーンのコンテキスト情報に対する理解力の改善が必要となってきます。Elithでは、これらの問題の解決に向けて取り組んでいます。
おわりに
本記事では、安全な自動運転の基盤作りとして、道路交通システムの改善を高速化するための「How to extend the dataset to account for traffic risk considering the surrounding environment」を紹介しました。
最後に少し宣伝です。株式会社Elithは、最先端のAI技術をビジネスに実装して価値を創出するテックカンパニーです。最近では、VLMやLLMを活用した交通システムやドメインシフトに関する社会課題の解決に向けた研究に注力しています。
VLMやLLMを用いた研究開発にご興味のある方は、ぜひX(旧Twitter)経由やElithのWebページ経由からお気軽にお問い合わせください。
ITSC Photos


参考文献
-
XGBoost: A Scalable Tree Boosting System [T.Chen+, KDD2016]
-
A Unified Approach to Interpreting Model Predictions [T.Chen+, NeurIPS2017]
-
Language Models are Few-Shot Learners [T.Brown+, NeurIPS2022]
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models [J.Wei+, Arxiv2022]
-
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation [J.Li+, ICML2022]
-
LLaVA: Large Language and Vision Assistant Visual Instruction Tuning [H.Liu+, NeurIPS2023]

Discussion