[AWS]VPC続き・EC2の構成
前回から引き続き、AWSとVPCを勉強していきます!
わけわからな過ぎて、文字が目を滑る!!!
こちらの動画でなんとか意識を取り戻してきました。
おさらい
VPC
AWS上の自分専用ネットワーク
サブネット
VPCをさらに細かく分けたネットワーク
CIDR
サブネットはCIDRを使用する。IPアドレスの範囲を指定する。
アベイラビリティゾーン
AZと略す。基地局のある場所。サブネットはAZ上に作成できる。
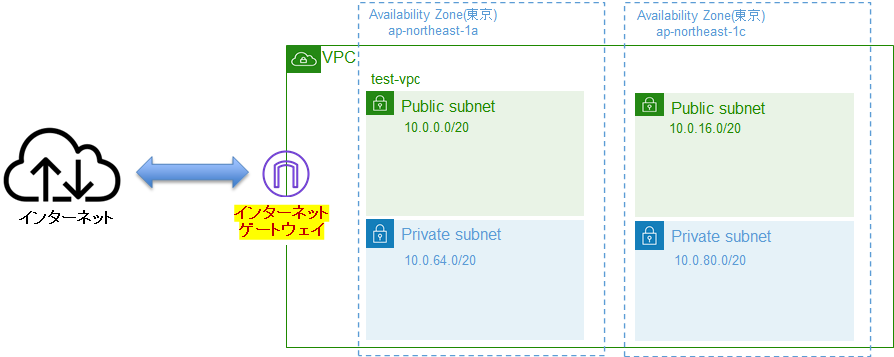
下記から引用。
ルートテーブル
サブネット用の道案内。
サブネットのルータがあり、ルータはドアの役目。
ルートテーブルは、AWSのリソースがどこに通信しにいくのかそのルールを決める。(誰がどこにいけるかの地図。)
このサブネットは、インターネットに出られるよ。(これをパブリック)
これはインターネットの世界につながってない(これはプライベート)
インターネットゲートウェイ
学校に例えると、正門。クラウドの世界とインターネットの世界をつなぐ出入口。
パブリックサブミットをインターネットにつなぐ。
EC2
AWS上でサーバを実行するための技術。
- EC2は、AWSのデータセンター内にある単一物理サーバ上で実行する
- AWSの物理サーバ内には、複数の仮想サーバがある。これを「EC2インスタンス」と呼ぶ
- EC2インスタンスを作成したいユーザは、まずサブネットを指定する
- サブネットを指定することでAZが決まる。このAZ内にAWSがある。
HVM(ハードウェア仮想化方式)
- 仮想マシンが本物のPCのように動く方式
- 物理サーバー上で ハードウェアを完全に再現(エミュレーション) して仮想マシンを動かす
- どんなOSでも動く(WindowsやLinuxをそのまま入れられる)
- 最新のハードウェアの機能をすぐに活用できる
- 多少オーバーヘッド(余計な処理の負荷)はあるが、最近は技術の進化でほぼ気にならない
📌 例
「ゲーム機のエミュレーター」に似てる。
例えば、パソコン上でPlayStationのゲームを動かすエミュレーターを使うと、本物のPlayStationのハードウェアを ソフトウェアで再現 する。
HVMでは、物理サーバーのハードウェアをソフトウェアで再現し、どんなOSでも動かせるようにしているイメージ。
PV(準仮想化方式)
- 仮想マシンが物理サーバーと直接やりとりする方式
- OSが仮想化を意識して動作し、一部のハードウェアを 直接利用 する
- その分、HVMに比べて オーバーヘッドが少なく、高速
- ただし、OSを 物理サーバーの環境に合わせてカスタマイズ しなければならない
- 最近のHVMの技術向上により、PVは ほぼ使われなくなった
EC2インスタンスタイプの命名規則
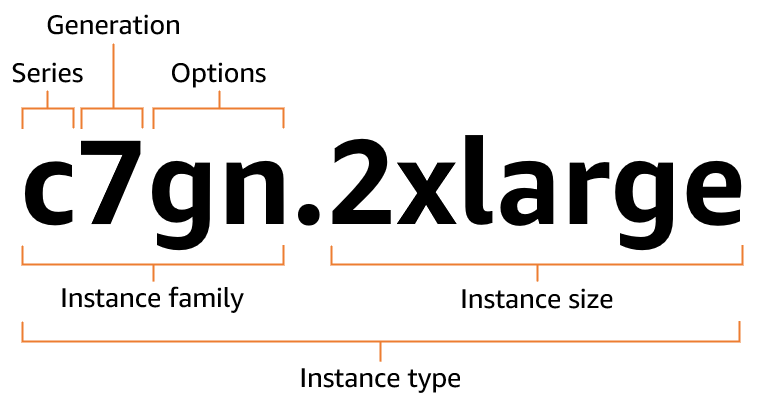
下記より引用。
インスタンスファミリー
EC2内にあるハードウェア。利用目的に合わせて、どれを使用するか選択する。
| 区分 | ファミリー名 | 特徴 |
|---|---|---|
| 汎用 (General Purpose) | t4g, t3, t3a, t2 | コスト最適化向けのバースト性能があるインスタンス(スモールアプリや開発環境向け) |
| m7g, m6g, m5, m5a, m5n, m4 | バランスの取れた性能(CPU、メモリ、ネットワークのバランスが良く、多目的に使用可能) | |
| コンピューティング最適化 (Compute Optimized) | c7g, c6g, c6i, c5, c5a, c5n, c4 | 高いCPU性能が求められる処理(Webサーバー、ゲームサーバー、動画エンコードなど) |
| ストレージ最適化 (Storage Optimized) | i4g, i3, i3en | 高速なローカルSSDストレージ付き(NoSQLデータベース、ログ処理など) |
| d2, d3, d3en | 大容量HDDストレージ搭載(ビッグデータ、データレイク向け) | |
| メモリ最適化 (Memory Optimized) | r7g, r6g, r5, r5a, r5n, r4 | メモリ集約型アプリケーション向け(インメモリデータベース、ビッグデータ解析など) |
| x2gd, x1e, x1 | 超大容量メモリ向け(SAP HANAなどのエンタープライズアプリケーション) | |
| u6i, u6g | 最大24TBの超大容量メモリ搭載(大規模インメモリデータベース向け) | |
| 高速コンピューティング (Accelerated Computing) | p5, p4, p3 | GPU搭載(機械学習、ディープラーニング、HPC向け) |
| inf2, inf1 | AWS独自のInferentiaチップ(低コストの機械学習推論向け) | |
| trn1 | AWS Trainium搭載(機械学習のトレーニング最適化) | |
| f1 | FPGA搭載(特殊なハードウェアアクセラレーションが必要なワークロード向け) |
インスタンス世代
- 新しいものほど数字が大きい
- 新しいものほど性能が高い上に安い(じゃあ新しければ新しいほどいいじゃん🤔)
追加機能
d :
インスタンスストアを追加している。
インスタンスストアとは、インスタンスに追加されたローカルストレージ(SSD/HDD)
EC2を停止・終了するとデータが消える。一時データとして使用される。
n :
ネットワーク帯域幅を追加したインスタンスファミリー
ネットワーク帯域幅とは、インスタンスのネットワーク通信速度を向上させたもの。
「n」がつくインスタンスは、高速なネットワーク帯域幅(帯域幅 = 通信速度) を持つ。
データ転送が多いシステムに向いている。
例:
- 分散システム(Kubernetes, Hadoop)
- リアルタイム処理(動画配信、ストリーミング)
- 大規模なデータ転送(データベースのバックアップなど)
分散システムとは
複数のコンピュータを連携させて、まるで1つかのように動かす。
「Hadoop」は基本情報で出てきた。
a :
IntelではなくAMDのCPUを搭載したインスタンスファミリー。
IntelもAMDもどちらもCPUを作成している会社。
Intel(インテル) は、世界最大級の半導体メーカー。インテル入ってるのインテル。
AMDは、Intelのライバル。コスパが良く、マルチスレッド性能に優れる。
インスタンスサイズ
AWSのEC2インスタンスの「大きさ」 を決めるもの。
例えば m5 ファミリーなら:
| サイズ | vCPU(仮想CPU) | メモリ(GB) |
|---|---|---|
m5.large |
2 vCPU | 8 GB |
m5.xlarge |
4 vCPU | 16 GB |
m5.2xlarge |
8 vCPU | 32 GB |
m5.4xlarge |
16 vCPU | 64 GB |
large(基本) →xlarge(大) →2xlarge(さらに大) →4xlarge(もっと大)…- 数字が大きくなるほど CPU・メモリも増える。
T2 インスタンス一覧
| サイズ | vCPU(仮想CPU) | メモリ(GB) |
|---|---|---|
t2.nano |
1 vCPU | 0.5 GB |
t2.micro |
1 vCPU | 1 GB |
t2.small |
1 vCPU | 2 GB |
t2.medium |
2 vCPU | 4 GB |
t2.large |
2 vCPU | 8 GB |
t2.xlarge |
4 vCPU | 16 GB |
t2.2xlarge |
8 vCPU | 32 GB |
AWSの範囲になってから、なかなか理解ができず、進みが遅くなってつらい😭
解決策としては、Youtubeだったり、AIやインターネットを活用して、その理解できない単語をいろんな覚悟から見つめるしかないんだと思った。焦らないことが重要。
Discussion