背景
弊社ELEMENTSでは業務でのAIの活用を推進しており、この投資による業務の変化を可視化したい (そして、便利なものにどんどん投資できるようにしておきたい!)
私の所属するPASSチームでは、チケットの見積もりを書けてないので、AIに書かせてみてVelocityの変化を追いたい
やること
JIRAの課題(以降チケット)の作成・更新をトリガーに、ClaudeでStorypointを算出してチケットのStorypointフィールドを更新する
全体像
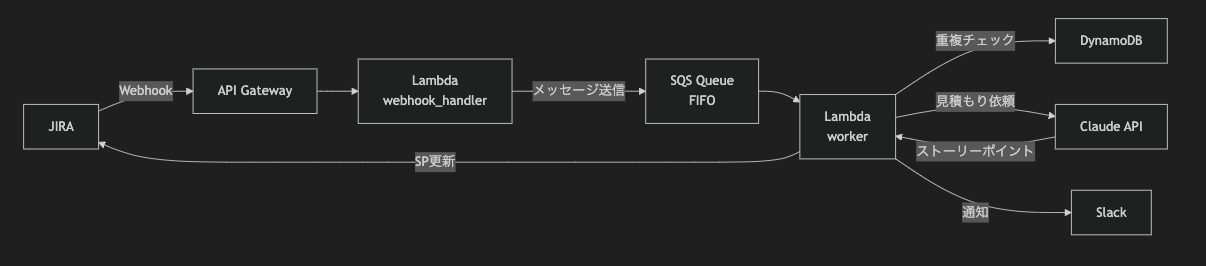
配慮したところ:
- LLMのコストを下げたいので、頻繁にチケットが更新されてもStorypointの算出は1回だけ行うようにする(LIFOで5分遅延させる)
- JIRAのチケットが作成・更新されるたびにWebhookが実行されるため、チケットの新規作成と説明欄の編集時のみ見積もりを行う
- 見積もりの設定時はプロジェクトのメンバーに通知が送られないようにnotifyUsersフラグをfalseにする
- 見積もり結果と判定理由をSlackに投稿して振り返れるようにしておく
必要な情報と権限
- JIRAの管理者権限 (webhook登録のために一時的に付与でもok)
- JIRAの該当Projectの管理者権限※ (?notifyUsers=false) パラメータ利用のため
※ 私の場合は今回の作業用に一時的に管理者権限をもらって、webhook設定後に管理者権限を削除してもらいました。
設定方法
API Gateway・Lambda関数・SQS・DynamoDBをデプロイ
handler.py
Lambda関数のサンプルです。
前述の通り、チケットの新規作成と説明欄の編集時のみキューイングします。
Webhook受取時に起動する関数になります。
import json
import logging
import os
import time
from typing import Any, Dict
import boto3
from botocore.exceptions import ClientError
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
try:
body = json.loads(event.get('body', '{}'))
if should_skip_processing(body):
logger.info("Skipping processing")
return {
'statusCode': 200,
'body': json.dumps({'message': 'skipped'})
}
issue_data = extract_issue_data(body)
if not issue_data:
logger.warning("No valid issue data found")
return {
'statusCode': 200,
'body': json.dumps({'message': 'No valid issue data'})
}
send_to_sqs(issue_data)
logger.info(f"Successfully queued issue: {issue_data['issueKey']}")
return {
'statusCode': 200,
'body': json.dumps({'message': 'Webhook processed successfully'})
}
except Exception as e:
logger.error(f"Error processing webhook: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({'error': 'Internal server error'})
}
def should_skip_processing(body: Dict[str, Any]) -> bool:
"""
Check if this webhook should be skipped.
Uses whitelist approach: only process if description changed or multiple fields changed
"""
changelog = body.get('changelog')
if not changelog:
return True # Skip if no changelog
items = changelog.get('items', [])
if not items:
return True # Skip if no changes
# Log changelog for debugging
logger.info(f"Changelog items: {json.dumps(items, ensure_ascii=False)}")
# 新規作成を判定
if len(items) > 1:
logger.info("Multiple fields changed - processing")
return False
# Process if description field changed
description_changes = [item for item in items if item.get('fieldId') == 'description']
if description_changes:
logger.info("Description field changed - processing")
return False
logger.info(f"Single field change (not description) - skipping: {items[0].get('fieldId')}")
return True
def extract_issue_data(body: Dict[str, Any]) -> Dict[str, Any]:
"""
Extract relevant issue data from webhook payload
"""
issue = body.get('issue')
if not issue:
return {}
fields = issue.get('fields', {})
return {
'issueKey': issue.get('key'),
'summary': fields.get('summary', ''),
'description': fields.get('description', ''),
'issueType': fields.get('issuetype', {}).get('name', ''),
'priority': fields.get('priority', {}).get('name', ''),
'project': fields.get('project', {}).get('key', ''),
'assignee': fields.get('assignee', {}).get('displayName', '') if fields.get('assignee') else '',
'reporter': fields.get('reporter', {}).get('displayName', '') if fields.get('reporter') else '',
'status': fields.get('status', {}).get('name', ''),
'labels': fields.get('labels', []),
'components': [comp.get('name', '') for comp in fields.get('components', [])],
'customFields': {
# JIRAの"ストーリーポイント"フィールドのIDです。 Postmanやcurlを使ってGET /rest/api/3/field で知ることができます
'storyPoints': fields.get(os.environ.get('STORY_POINT_FIELD', 'customfield_10026'))
}
}
def send_to_sqs(issue_data: Dict[str, Any]) -> None:
"""
Send issue data to SQS queue with LIFO deduplication
"""
issue_key = issue_data.get('issueKey', '')
if not issue_key:
logger.error("No issueKey found in issue data")
return
sqs = boto3.client('sqs')
queue_url = os.environ.get('SQS_QUEUE_URL')
if not queue_url:
raise ValueError("SQS_QUEUE_URL environment variable not set")
message_body = json.dumps(issue_data, ensure_ascii=False)
logger.info(f"Enqueuing message to SQS - Issue: {issue_data.get('issueKey', 'Unknown')}, Project: {issue_data.get('project', 'Unknown')}")
logger.info(f"SQS Message Body: {message_body}")
# FIFOキュー用の設定
project_key = issue_data.get('project', '')
current_time = int(time.time())
message_attributes = {
'issueKey': {
'StringValue': issue_key,
'DataType': 'String'
},
'project': {
'StringValue': project_key,
'DataType': 'String'
},
'timestamp': {
'StringValue': str(current_time),
'DataType': 'Number'
}
}
response = sqs.send_message(
QueueUrl=queue_url,
MessageBody=message_body,
MessageGroupId=project_key if project_key else 'default',
MessageDeduplicationId=issue_key, # issueKeyで重複排除
MessageAttributes=message_attributes
)
logger.info(f"Successfully sent message to SQS - MessageId: {response.get('MessageId', 'Unknown')}")
worker.py
workerのLambda関数です。
SQSのメッセージを受け取って起動します。
LIFOを実現するためにDynamoDBを使っているところがやや複雑になってます。
import glob
import json
import logging
import os
from typing import Dict
import boto3
import requests
from anthropic import Anthropic
from botocore.exceptions import ClientError
from config import Config
# Logging setup
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# Force INFO level for debugging
logging.getLogger().setLevel(logging.INFO)
# Initialize clients
sqs = boto3.client('sqs')
class JiraClient:
"""JIRA API client for updating story points"""
def __init__(self):
self.base_url = Config.JIRA_BASE_URL
self.auth = (Config.JIRA_USER_EMAIL, Config.get_jira_api_token())
self.headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
def update_story_points(self, issue_key: str, story_points: float) -> bool:
"""Update story points for a JIRA issue"""
url = f"{self.base_url}/rest/api/2/issue/{issue_key}?notifyUsers=false"
data = {
"fields": {
Config.STORY_POINT_FIELD: story_points
}
}
try:
response = requests.put(
url,
json=data,
auth=self.auth,
headers=self.headers
)
response.raise_for_status()
logger.info(f"Successfully updated story points for {issue_key} to {story_points}")
return True
except requests.exceptions.RequestException as e:
logger.error(f"Failed to update story points for {issue_key}: {str(e)}")
if hasattr(e.response, 'text'):
logger.error(f"Response: {e.response.text}")
return False
def get_issue_url(self, issue_key: str) -> str:
"""Generate JIRA issue URL"""
return f"{self.base_url}/browse/{issue_key}"
class SlackNotifier:
"""Slack notification client"""
def __init__(self):
self.webhook_url = Config.SLACK_WEBHOOK_URL
def send_story_point_notification(self, issue_key: str, story_points: float, reason: str, issue_url: str) -> bool:
"""Send story point notification to Slack"""
if not self.webhook_url:
logger.warning("Slack webhook URL not configured")
return False
message = f"{issue_url}\nStoryPoint: {story_points}\n判定理由: {reason}"
payload = {
"text": message
}
try:
response = requests.post(
self.webhook_url,
json=payload,
headers={'Content-Type': 'application/json'}
)
response.raise_for_status()
logger.info(f"Successfully sent Slack notification for {issue_key}")
return True
except requests.exceptions.RequestException as e:
logger.error(f"Failed to send Slack notification for {issue_key}: {str(e)}")
return False
class StoryPointEstimator:
"""Estimate story points using Claude API"""
def __init__(self):
self.anthropic = Anthropic(api_key=Config.get_claude_api_key())
self.docs_content = self._load_project_docs()
def _load_project_docs(self) -> str:
"""Load all markdown files from docs directory"""
docs_content = []
try:
# Try multiple possible docs paths
possible_paths = [
Config.DOCS_PATH,
'./docs',
'/opt/docs',
os.path.join(os.path.dirname(__file__), 'docs')
]
docs_path = None
for path in possible_paths:
if os.path.exists(path):
docs_path = path
logger.info(f"Found docs directory at: {path}")
break
if not docs_path:
logger.warning(f"No docs directory found. Tried paths: {possible_paths}")
return "No project documentation available."
# プロンプトに含めるプロジェクト情報と見積もりの基準を記したドキュメント
md_files = glob.glob(os.path.join(docs_path, '*.md'))
logger.info(f"Found {len(md_files)} markdown files in {docs_path}")
for file_path in md_files:
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
docs_content.append(f"=== {os.path.basename(file_path)} ===\n{content}\n")
logger.info(f"Loaded doc: {file_path}")
except Exception as e:
logger.error(f"Failed to read {file_path}: {str(e)}")
if not docs_content:
logger.warning(f"No documentation files found in {docs_path}")
return "No project documentation available."
return "\n".join(docs_content)
except Exception as e:
logger.error(f"Failed to load project docs: {str(e)}")
return "Failed to load project documentation."
def estimate_story_points(self, summary: str, description: str) -> Dict:
"""Estimate story points for a JIRA issue"""
from prompts import get_estimation_prompt
prompt = get_estimation_prompt(
summary=summary,
description=description,
project_docs=self.docs_content
)
try:
response = self.anthropic.messages.create(
model=Config.CLAUDE_MODEL,
max_tokens=Config.CLAUDE_MAX_TOKENS,
temperature=Config.CLAUDE_TEMPERATURE,
messages=[
{
"role": "user",
"content": prompt
}
]
)
# Parse response
response_text = response.content[0].text
# Try to extract JSON from response
import re
json_match = re.search(r'\{[^}]+\}', response_text, re.DOTALL)
if json_match:
result = json.loads(json_match.group())
logger.info(f"Story point estimation: {result}")
return result
else:
# Fallback if JSON not found
logger.warning("Could not parse JSON from Claude response")
return {
"storypoint": 3,
"reason": "デフォルト値を使用しました。Claude APIの応答を解析できませんでした。"
}
except Exception as e:
logger.error(f"Failed to estimate story points: {str(e)}")
return {
"storypoint": 3,
"reason": f"エラーが発生したため、デフォルト値を使用しました: {str(e)}"
}
def process_message(message_body: Dict) -> bool:
"""Process a single SQS message"""
try:
issue_key = message_body.get('issueKey')
summary = message_body.get('summary', '')
description = message_body.get('description', '')
if not issue_key:
logger.error("Issue key not found in message")
return False
logger.info(f"Processing issue: {issue_key}")
logger.info(f"Summary: {summary}")
logger.info(f"Description: {description}")
# Initialize JIRA client
jira = JiraClient()
# Estimate story points
logger.info("Starting story point estimation...")
estimator = StoryPointEstimator()
estimation = estimator.estimate_story_points(summary, description)
logger.info(f"Estimation result: {estimation}")
# Update JIRA
success = jira.update_story_points(
issue_key,
float(estimation.get('storypoint', 3.0))
)
if success:
slack = SlackNotifier()
issue_url = jira.get_issue_url(issue_key)
slack.send_story_point_notification(
issue_key,
float(estimation.get('storypoint', 3.0)),
estimation.get('reason', 'デフォルト値を使用しました'),
issue_url
)
return success
except Exception as e:
logger.error(f"Error processing message: {str(e)}")
return False
def lambda_handler(event, context):
"""AWS Lambda handler for SQS events"""
for record in event.get('Records', []):
try:
message_body = json.loads(record['body'])
issue_key = message_body.get('issueKey')
message_timestamp = None
if 'messageAttributes' in record:
timestamp_attr = record['messageAttributes'].get('timestamp')
if timestamp_attr:
if 'StringValue' in timestamp_attr:
message_timestamp = int(timestamp_attr['StringValue'])
elif 'stringValue' in timestamp_attr:
message_timestamp = int(timestamp_attr['stringValue'])
logger.info(f"Processing message for issue {issue_key} with timestamp {message_timestamp}")
# Check if this is the latest message for this issue
if not is_latest_message(issue_key, message_timestamp):
logger.info(f"Skipping outdated message for issue {issue_key}")
continue
success = process_message(message_body)
if success:
mark_as_processed(issue_key)
else:
logger.error(f"Failed to process message: {record['messageId']}")
except Exception as e:
logger.error(f"Error processing record: {str(e)}")
return {
'statusCode': 200,
'body': json.dumps('Processing complete')
}
def is_latest_message(issue_key: str, message_timestamp: int = None) -> bool:
"""
Check if this message is the latest for the given issue
"""
if not issue_key:
return True # Process if no issue key
dynamodb = boto3.client('dynamodb')
table_name = os.environ.get('DYNAMODB_TABLE_NAME', 'pass-jira-webhook-dev-issue-tracking')
try:
# Get the latest timestamp from DynamoDB
response = dynamodb.get_item(
TableName=table_name,
Key={'issueKey': {'S': issue_key}}
)
if 'Item' not in response:
# No record found, this is the first message
# Record current message timestamp
update_issue_timestamp(issue_key, message_timestamp)
return True
item = response['Item']
# Check if already processed
if item.get('processed', {}).get('BOOL', False):
logger.info(f"Issue {issue_key} already processed")
return False
# Compare timestamps if available
if message_timestamp and 'timestamp' in item:
db_timestamp = int(item['timestamp']['N'])
logger.info(f"Timestamp comparison - Message: {message_timestamp}, DB: {db_timestamp}, Diff: {db_timestamp - message_timestamp}s")
if message_timestamp < db_timestamp:
logger.info(f"Message timestamp {message_timestamp} is older than DB timestamp {db_timestamp}")
return False
else:
# Update timestamp if this message is newer
update_issue_timestamp(issue_key, message_timestamp)
return True
except ClientError as e:
logger.error(f"Error checking latest message for {issue_key}: {str(e)}")
# Continue processing if DB check fails
return True
def update_issue_timestamp(issue_key: str, timestamp: int = None) -> None:
"""
Update the timestamp for an issue in DynamoDB
"""
if not timestamp:
timestamp = int(time.time())
dynamodb = boto3.client('dynamodb')
table_name = os.environ.get('DYNAMODB_TABLE_NAME', 'pass-jira-webhook-dev-issue-tracking')
ttl_time = timestamp + 86400 # 24時間後にTTLで自動削除
try:
dynamodb.put_item(
TableName=table_name,
Item={
'issueKey': {'S': issue_key},
'timestamp': {'N': str(timestamp)},
'processed': {'BOOL': False},
'ttl': {'N': str(ttl_time)}
}
)
logger.info(f"Updated timestamp for issue {issue_key} in DynamoDB with timestamp {timestamp}")
except ClientError as e:
logger.error(f"Error updating timestamp for {issue_key}: {str(e)}")
# Continue processing even if DynamoDB update fails
def mark_as_processed(issue_key: str) -> None:
"""
Mark an issue as processed in DynamoDB
"""
dynamodb = boto3.client('dynamodb')
table_name = os.environ.get('DYNAMODB_TABLE_NAME', 'pass-jira-webhook-dev-issue-tracking')
try:
dynamodb.update_item(
TableName=table_name,
Key={'issueKey': {'S': issue_key}},
UpdateExpression='SET processed = :p',
ExpressionAttributeValues={':p': {'BOOL': True}}
)
logger.info(f"Marked issue {issue_key} as processed")
except ClientError as e:
logger.error(f"Error marking {issue_key} as processed: {str(e)}")
# Continue even if update fails
prompts.py
worker.pyから参照します
"""
Prompts for Claude API story point estimation
"""
def get_estimation_prompt(summary: str, description: str, project_docs: str) -> str:
prompt = """あなたはソフトウェア開発プロジェクトのストーリーポイント見積もりの専門家です。
以下の情報を基に、JIRAの課題に対するストーリーポイントを見積もってください。
## プロジェクト仕様書
""" + project_docs + """
## 課題情報
**タイトル**: """ + summary + """
**説明**: """ + description + """
## ストーリーポイントの基準
- 1ポイント: 非常に簡単なタスク(1-2時間程度)
- 2ポイント: 簡単なタスク(半日程度)
- 3ポイント: 標準的なタスク(1日程度)
- 5ポイント: やや複雑なタスク(2-3日程度)
- 8ポイント: 複雑なタスク(1週間程度)
- 13ポイント: 非常に複雑なタスク(2週間程度)
## 考慮すべき要素
1. 実装の複雑さ
2. 必要な技術的知識
3. 他のシステムとの依存関係
4. テストの難易度
5. 不確実性やリスク
必ず以下のJSON形式で回答してください:
{
"storypoint": 見積もったポイント数(整数),
"reason": "見積もりの根拠を日本語で説明"
}
JSONのみを出力し、他の説明は不要です。
"""
return prompt
def get_refined_estimation_prompt(summary: str, description: str, project_docs: str) -> str:
"""
より詳細な見積もりプロンプト(必要に応じて使用)
"""
prompt = """あなたはアジャイル開発チームのテックリードです。
以下のJIRA課題に対して、チームの生産性を考慮したストーリーポイントを見積もってください。
## プロジェクト背景
""" + project_docs + """
## 対象課題
**タイトル**: """ + summary + """
**詳細**: """ + description + """
## 見積もり基準(フィボナッチ数列)
- 1: 単純な設定変更、小さなバグ修正
- 2: 簡単な機能追加、明確なバグ修正
- 3: 標準的な機能実装、通常の複雑さ
- 5: 複数コンポーネントにまたがる変更
- 8: 大きな機能追加、設計が必要な作業
- 13: エピック級の大きな変更
## 評価の観点
1. **技術的複雑性**: コードの難易度、アーキテクチャへの影響
2. **作業量**: 必要な変更箇所の数、コード行数の見込み
3. **依存関係**: 他のシステムやチームとの調整の必要性
4. **不確実性**: 要件の明確さ、技術的なリスク
5. **テスト**: テストケースの作成難易度、影響範囲
これらを総合的に判断し、以下の形式で回答してください:
{
"storypoint": ポイント数(整数),
"reason": "見積もりの詳細な根拠"
}
"""
return prompt
プロンプトに含めるために用意しているmarkdownは、プロジェクトのシステム構成や要件を2000文字くらい書いてあります
(これもLLMで各リポジトリを読ませて書かせると楽です)
また、ストーリーポイントの見積もりにおける基準も下記のように設定してあります。
# タスク複雑度ガイド
## ストーリーポイント見積もり基準
### 1ポイント
2ポイントの半分以下の程度のタスク
- 例:
- 表示文言の修正
- Swagger(OpenAPI)の項目ラベル変更
- 既存CSSのclass名変更
- 定義済みデータの差し替え
- 所要時間目安: 0.5人日未満(1〜2時間程度)
### 2ポイント
- 例:
- データベース構造に影響しない既存APIの修正(バリデーション追加、ロジック変更)
- 画面のテキスト変更やコンポーネント入れ替え(状態管理は既存のまま)
- 軽微なログ出力の見直し
- 外部ライブラリのマイナーバージョンアップ
- 所要時間目安: 1人日
### 3ポイント
- 例:
- データベースにカラム追加し、それに紐づく一連のCRUD/APIを修正
- 外部APIとの接続なしで、1画面 or 1APIを新規実装
- 状態管理(例: Redux, Recoil)を持つ画面要素の追加
- 検索条件の追加 + 並び順の変更など、業務ロジック変更を伴う画面改修
- 環境変数まわりの設計変更
- 所要時間目安:1.5〜2人日
### 5ポイント
- 例:
- 外部APIとの連携を伴う新規機能の開発
- フロント・バックエンド両方の修正が必要な仕様変更
- 既存画面の大幅改修(構成再設計、レイアウト再配置など)
- 権限管理まわりの制御追加(API側と画面両方に影響あり)
- 所要時間目安: 2〜3人日
### 8ポイント
- 例:
- 他チームや外部サービスとの調整が必要なプロセス変更
- 既存機能のアーキテクチャ的な見直し(例:単一API → GraphQL統合など)
- マイグレーションを含むデータモデルの再構築
- 1機能全体の新規設計(画面・API・DB含む)
- 所要時間目安: 3〜5人日
### 13ポイント
- 例:
- プロダクトの認証/認可まわりを刷新
- チーム内の基盤刷新(ロギング、監視、CI/CD構成の大幅変更)
- 全社共通モジュールの入れ替え・設計変更
- 複数サービス間でインターフェース仕様を調整し直す必要があるもの
- パフォーマンスチューニングを伴う全体的な負荷対策(事前検証が難しい)
- 所要時間目安: 5人日以上〜
## 見積もり時の考慮事項
- 技術的な新規性
- 依存関係の複雑さ
- テストの難易度
- ドキュメント作成の必要性
SQS
FIFO遅延キューを使います。
設定値はFIFOですが、先程のpythonコードでLIFOを実現してあります。
resource "aws_sqs_queue" "jira_webhook_queue" {
name = "${var.project_name}-${var.environment}-queue.fifo"
fifo_queue = true
content_based_deduplication = false # Use MessageDeduplicationId instead
deduplication_scope = "queue" # Deduplication at queue level
fifo_throughput_limit = "perQueue"
visibility_timeout_seconds = 900 # 15 minutes (Lambda timeout + buffer)
message_retention_seconds = 1209600 # 14 days
max_message_size = 262144 # 256 KB
delay_seconds = 300 # 5分の遅延
receive_wait_time_seconds = 0
kms_master_key_id = "alias/aws/sqs"
redrive_policy = jsonencode({
deadLetterTargetArn = aws_sqs_queue.jira_webhook_dlq.arn
maxReceiveCount = 3
})
tags = {
Name = "${var.project_name}-${var.environment}-queue"
Environment = var.environment
Project = var.project_name
}
}
DynamoDBは issueKey (String) をパーティションキーにしておきます。
JIRAのWebhookを設定
Atlassianのドキュメントに従い、課題の作成時と更新時にWebhookを設定します。
先程の hander.py に紐づくAPI Gatewayをエンドポイントに設定します。
動作確認
チケットを作成して5分後にStorypointのフィールドが埋まっていれば成功です。
精度について
雑に10件ほどタスクを抽出して人手で付与したstory pointとAIが付与したものを比較しました。

人の見積もりとAIの見積もりを10件で比較したところ、概ね近い精度を示しました。
大きくずれたのは「print修正」や「通知タイミング修正」など一部の軽微なタスクで、
逆に「有効期限の変更」や「API作成」のように要件が具体的なものはAIの見積もりが人と近かったです。
完全に一致したケースも2件あり、平均的には±1の誤差に収まっていました。
全体として、AIの見積もりは人の感覚を大きく外さず実用レベルにあると言えそうです。
コストについて
試しに500件ほどトリガーさせてみましたが、$11.83でした。
outputが少ないので、気にするような金額にはならなそうです。
判定結果をより精緻にするには
LLMの見積もりがイマイチだった場合、JIRA上でstorypointを手動で修正することができます。
(=手動で編集しても、説明欄の文言を変えない限りはLLMに上書きされないように書いてある)
この変更をwebhookのスクリプトで検知して溜めておくことで、ギャップを埋めるための情報として使えそうです。
生産性が測れるか?
チケットにならない軽微な対応や問い合わせもあるので、生産性という言葉にするとやや語弊があるかもしれませんが、PR数やコミット数を測るよりは生産性に近いものになったと思います。

JIRAのベロシティレポートにはなぜか反映されなかったので(ラグあり?)、集計してSpreadSheetで確認したところ特に忙しかった3月は高く出ており、プレッシャーによる外部要因で一時的にチームの処理性能が上がることはあるよなあという感想です。
また、AIエージェントについては2025/3の頭にClineを始めとしてClaude CodeやDevinなどを導入しまして、2025/4の頭に1名離職しているため、その後のVelocityがある程度維持できている要因を支えていると見ることもできます。 (ところで、弊社はエンジニアを積極採用中です)
あるいは、AIエージェント導入によって出た余裕による投資の効果が遅効して出てくる可能性もあるため、今後も状況を見ていきたいと思います。

Discussion