【初心者向け 104】実務に必要なHTTP知識
はじめに
本記事は、こちらの講座から勉強した内容をまとめ、抜粋しました。
Internet Network
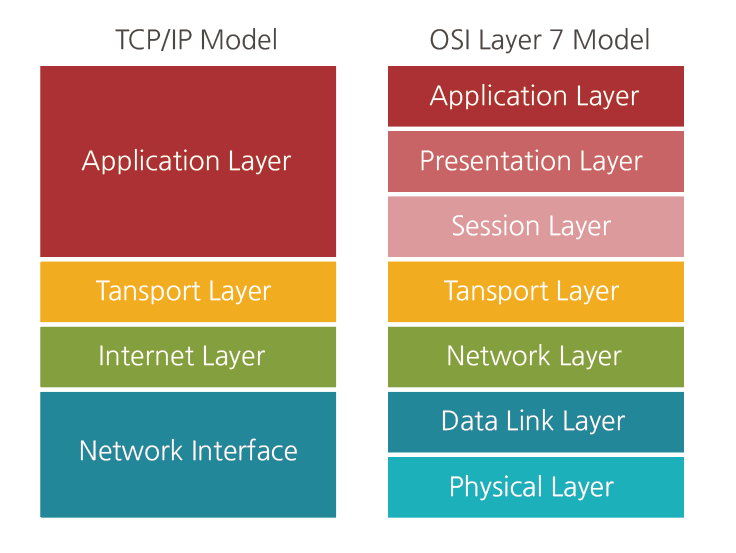
https://medium.com/harrythegreat/osi계층-tcp-ip-모델-쉽게-알아보기-f308b1115359
パケットとIP Protocolの限界
IP Protocolからクライアントがサーバーにデーターを転送する際にデーターを送る単位
出発IP、転送IPなどを作成し、中には送るデーターがあります。
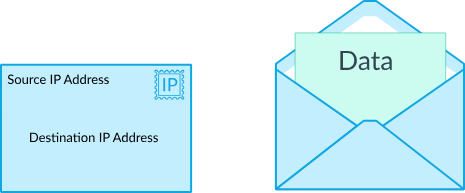
限界:
connectionless(パケットをもらう対象がない、ネットに繋がっていないなど)
unreliable (大容量で分割したパケットが順番にこなかったり、途中にパケットロス)
等の問題点があります。
TCP(Trasmission Control Protocol)
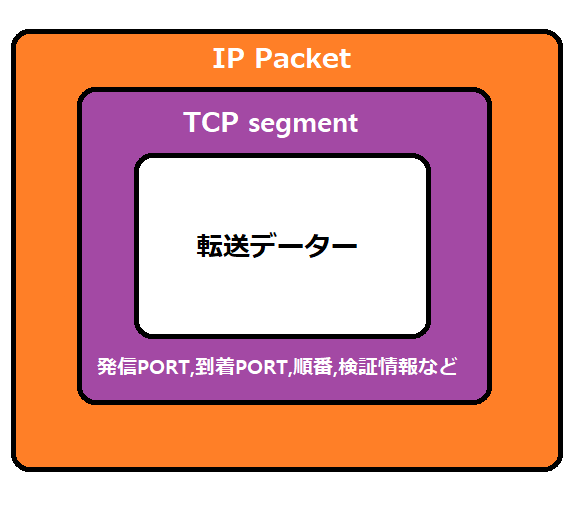
そのため、このようにIPパケットの中にTCPが入り、より安全性を確保します。
Trasmission Control Protocolという意味で、IP Protocolの限界を解決します。
TCP 3 way-handshakeという過程でsyn, synact, actでメッセージを交換し、検証を終われば、connectします。
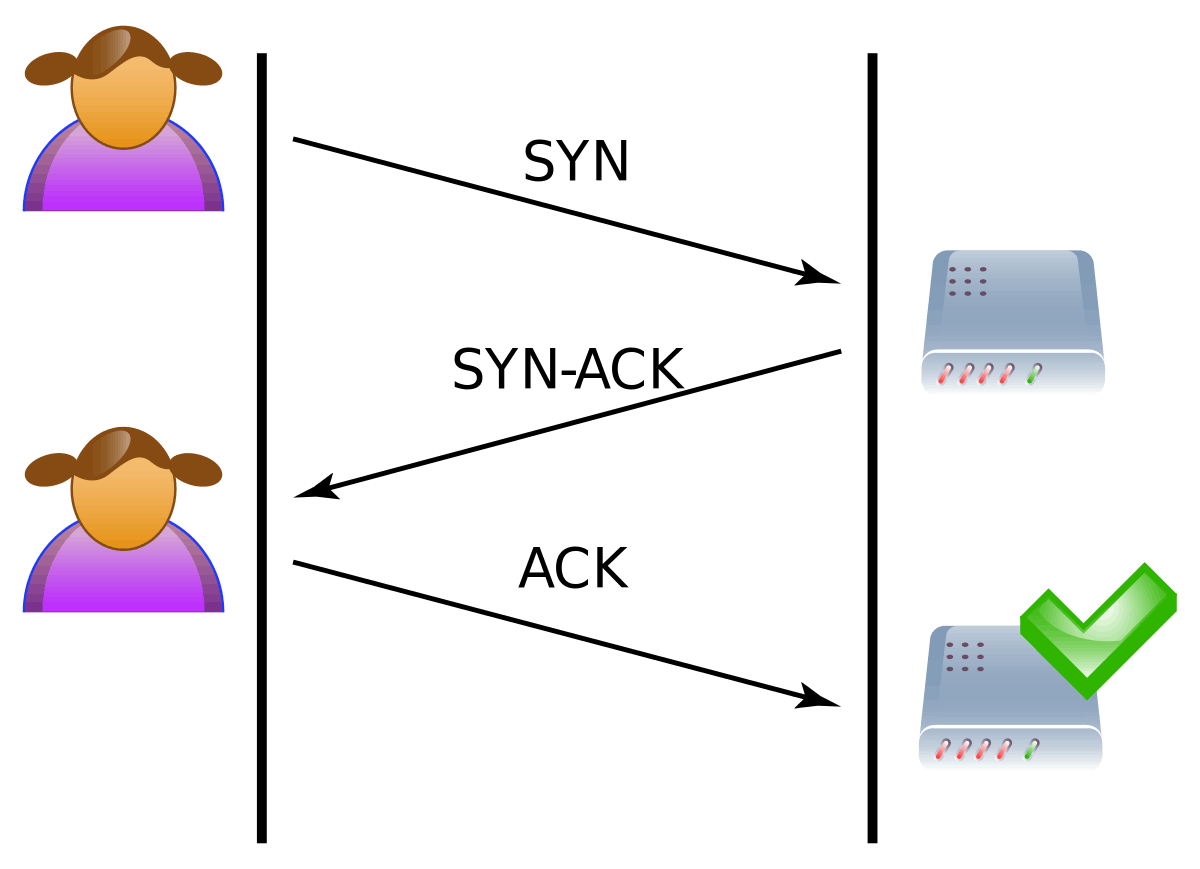
https://ja.wikipedia.org/wiki/3ウェイ・ハンドシェイク
UDP(User Datagram Protocol)
一つのipで、音楽を聴いたり、ゲームをする場合、それぞれ違うportをlistenします。
その場合は、ipのみでは、転送することに限界があるので、TCP,UDPはportを記載します。
しかし、TCPの場合、3 way handshakeで遅いことが短所で、より軽く機能が少ないUDPを活用する際もあります。IP+portみたいな軽いprotocolですが、逆に言えば、白い紙のように状態なのでアレンジすることができるので、規則が明確なTCPより柔軟で最近注目されいるProtocolです。
(HTTP3からはUDPを活用しているからです。)
URI(Unifrom resource idenfier)
Resourceを区別・職別する(indentify)統合された方式(uniform)

URLはURIの一部で、location、つまり位置を意味する。
url: resourceの位置
urn: resourceの名前
★http protocol flow★
clientがurl入力
➞
DNSサーバーからurlに該当するサーバーのip addressとportを取得
➞
clientのbrowerがHTTP request messageを生成

➞
Socket libraryを通して転送
➞
TCP/IP ( 3 ways handshake [syn + synact + act] , packet )

➞
包装されたpacketを開放し、サーバーからresponse messageを生成

➞
同じくtcp,ipパケット化後、clientに到着
➞
Clientのbrowerからresponse messageをrendering
http
1. Client - Server
基本の中で基本ですが、最近はViewとServerを徹底的に分けていることがtrendで、frontはUX・UIに集中します。
2. stateless
サーバーがクライアントの状態を保存しない。
長所:同じ機能のサーバーの無限拡張ができて、柔軟性を確保する(scale out)
短所:一機に送るデーターが多い。
状態を維持するloginの場合、session、cashで処理し、
その他は無状態を支持することが大事です。
3. connectless
requestとresponseが終わったらすぐconnectを切る
色々なリソースを節約することができる。様々なrequestに対応できる。
しかし、毎度htmlをダウンロードし切り、cssをダウンロードしきり、jsをダウンロードし、切なければいけないのではclientにはよくない。
http 2.0からはhtmlのファイルが完璧にダウウンロードが終わるまでconnectを維持するpersistent connectを使っています。
http 3.0はUDP基盤なので,3-way-handshakeが省略されるので、もっと早いです。
4. HttpMessage

https://hahahoho5915.tistory.com/62
start-line(request line/status line)
request line(request message)
method SP(空白)request-target SP HTTP-version CRLF(enter)
status line(response message)
HTTP-version SP status-code SP reason-pharase CRLF
header
header-field
keyとvalueの形です。
Javaでmap/pythonでdictionaryにheaderを処理する理由がやっとわかりました。
header-field = fieldname":" OWS(空白OK) field-value (OWS)
ex> Host(fieldname): www.google.com(field-value)
HTTPの転送に必要なすべてのmeta dataがあります。
空白(headerとbodyを区切るため)
Body
byteで表現できるすべてのメッセージ内容(html、xml、jsonだけなく、imageなど)
http method
http API 作成
悪い例
API URIデザイン
URI(Uniform Resource Identifier)
• 会員リストの取得 /read-member-list
• 会員の取得 /read-member-by-id
• 会員の登録 /create-member
• 会員の更新 /update-member
• 会員の削除 /delete-member
良い例
API URIの設計
リソース識別、URIの階層構造の活用
• 会員一覧の取得 /members
• 会員の取得 /members/{id}
• 会員の登録 /members/{id}
• 会員の更新 /members/{id}
• 会員の削除 /members/{id}
• 注記: 階層構造上で親をコレクションと見なし、複数の単語の使用が推奨されます(member -> members)
リソースと行為を分離
• リソースとそれに対する操作を分離
• リソース: 会員
• 操作: 参照、登録、削除、変更
HTTP Methodで行為を処理!
GET,POST
GETは照会、POSTは生成、生成をしなくてもサーバーと関係がある大きなプロセスにも呼び出すメソッドです。
POSTの場合、request parameterではなく、message bodyに内容が入ります。POST(resource追加成功時、status-codeは201をリターン)
PUT
1.リソースを完全代替します。(ない場合は生成します)
2.POSTと異なり、クライアントがresourseを知る必要があります。
例)
PUT/members/100 HTTP/1.1
POST/member HTTP/1.1
POSTの場合、新しい職別numberが生成されますが、PUTは既存の職別numberを知っている必要があります。手紙を特にアドレスを知るように!
PATCH、DELETE
PUTと異なり、PATCHはresourceを一部修正ができ、DELETEはresourceを削除します。
PATCHを支援しないサーバーもあるので、その際にはPOSTを呼び出します。POSTは無敵です。
安全性(Safe)、冪等性(impotent)

https://nordicapis.com/understanding-idempotency-and-safety-in-api-design/
安全性:resourceを変更しない。
冪等性:メソッドを何回呼び出しても結果は同じだ。
• ユーザー1: GET -> ユーザー名:A、年齢:20
• ユーザー2: PUT -> ユーザー名:A、年齢:30
• ユーザー1: GET -> ユーザー名:A、年齢:30
-> ユーザー2の影響で変更
冪等性は外部要因がリソースの変更までは考慮しません。
**GET、HEAD、POST、PATCHがCasheableですが、実際はGET、HEADのみCacheで具象することが多いです。
**
http method 活用
クライアントからサーバーへのデータの送信方法には大きく2つの方法があります
データーを転送する方法
クエリパラメータ経由のデータ送信
GET
一般的にはソート、フィルタリング(検索語句)に使用
メッセージボディ経由のデータ送信
POST、PUT、PATCH
会員登録、商品注文、リソースの作成、リソースの変更などに使用
データーを転送する状況
静的データの取得
画像、静的なテキストドキュメント
動的データの取得
主に検索、掲示板リストのソートおよびフィルタリング(検索語句)
HTMLフォーム経由のデータ送信
会員登録、商品注文、データ変更
HTTP API経由のデータ送信
会員登録、商品注文、データ変更
サーバー間通信、アプリクライアント、ウェブクライアント(Ajax)
API作成
Collection
client : POST/members
server:
HTTP/1.1 201 Created
Location:members/100
サーバーにPOSTでデーターを転送する際には、職別URIはサーバーから作るので、クライアントはURIが分からないです。
このようにサーバーが管理するresource directoryをcollectionをいいます。(members)**
Store
PUTの場合、クライアントはURIを分かることが前提になっています。 つまり、URIをクライアントが直接指定し、管理する形です。ファイル管理システムなどをPUTの典型的な事例です。
Form
html formのGET,POSTで転送する方式。Controllerを通して、Controll URIを生成します。
Controll URIは必ず動詞に決めます。
Collection vs Form
APIデザイン - POSTベースの登録
会員一覧 /members -> GET
会員登録 /members -> POST
会員情報取得 /members/{id} -> GET
会員情報変更 /members/{id} -> PATCH, PUT, POST
会員情報削除 /members/{id} -> DELETE
HTMLフォームの使用
会員一覧 /members -> GET
会員登録フォーム /members/new -> GET
会員登録 /members/new, /members -> POST
会員情報の取得 /members/{id} -> GET
会員情報編集フォーム /members/{id}/edit -> GET
会員情報の編集 /members/{id}/edit, /members/{id} -> POST
会員情報の削除 /members/{id}/delete -> POST
HTTP status Code
status code(response)
HTTPステータスコード
クライアントが送信したリクエストの処理状態をレスポンスで通知する機能
1xx (Informational): リクエストが受信され、処理中
2xx (Successful): リクエストが正常に処理されたという意味
3xx (Redirection): リクエストを完了させるには追加のアクションが必要
4xx (Client Error): クライアントエラー、不正な構文などによりサーバーがリクエストを実行できない状態
5xx (Server Error): サーバーエラー、サーバーが正常なリクエストを処理できない状態
2xx
200 OK : requestを成功した時。
201 Created:requestと通して、resourceを生成することを成功した時使い、Location:path/newURL をメッセージの本文に乗せます。
202 Accepted:requestは成功しましたが、実行は後でする時
204 No Content:requsetは成功したが、responseのbodyに何かを送る必要がない時 (sava機能)
通常は200,201を使います。様々なstatus codeを利用してもclientに負担になるらしいです。
3xx
Browserは3xxのResponse結果にLocation headerがあれば、そのLocationに自動的に移動します。
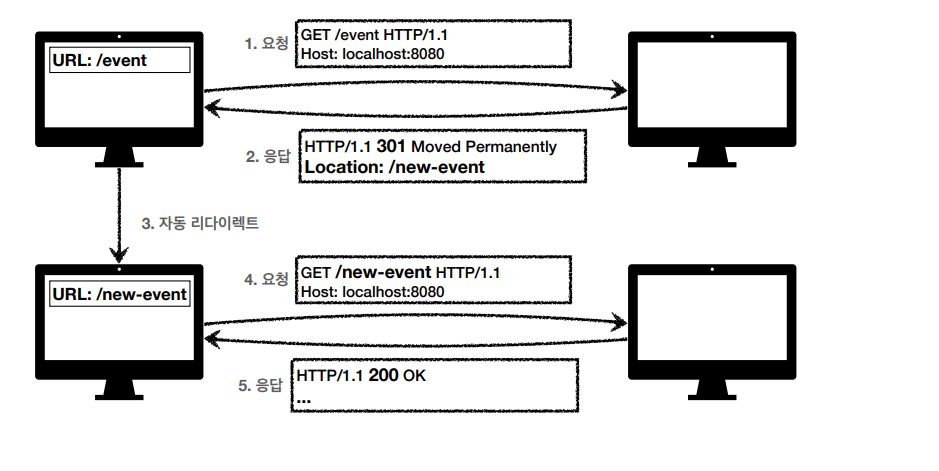
状況によって、永久的にredirectをするが、一時的にredirectをするかなどを決めることができます。
永続的リダイレクト(301,308)
リソースのURIが永続的に移動し、元のURLは使用せず、検索エンジンなども変更を認識
301 Moved Permanently
リダイレクト時にリクエストメソッドがGETに変更され、本文が削除される可能性があります。(MAY)
308 Permanent Redirect
301と同様の機能。
リダイレクト時にリクエストメソッドと本文が維持さます。
(最初にPOSTを送信した場合、リダイレクトもPOSTが維持されます。)
一時的なリダイレクション(302、307、303)
リソースのURIが一時的に変更されうます。検索エンジンなどではURLを変更することはいけないです。
302 Found
リダイレクト時にリクエストメソッドがGETに変更され、本文が削除される可能性があります。(MAY)
307 Temporary Redirect
302と同様の機能。
リダイレクト時にリクエストメソッドと本文が維持されます。(リクエストメソッドを変更してはならない。MUST NOT)
303 See Other
302と同様の機能で、リダイレクト時にリクエストメソッドがGETに変更
されます。303が一番理想的ですが、実際は302が一番よく使われるます。
★★★PRG(Post-Redirect-Get)★★★
注文などでPOST要請をする場合は、F5ボタンを押す場合、また同じPOST要請でサーバーにデーターが転送されるので、重複問題が行います。
絶対あってはいけないことですね。
そのため、使うパターンがPRGパターンです。
その他(300,304)
300 Multiple Choices: 使わないです
304 Not Modified
キャッシュの目的で使用するstatus codeです。クライアントにリソースが変更されていないことを通知します。
したがって、クライアントはローカルのキャッシュを再利用します。 (キャッシュにリダイレクトされます。)
条件付きGET、HEADリクエストに使用します。
4xx
クライアントエラーを意味します。
サーバーがクライアントのリクエストを誤った構文などの理由で処理できないので、エラーの原因がクライアントにあることを通知します。
401 Unauthorized
認証がされていない。(ログイン)
本来の意味であれば、Unauthorizedは、権限がないという意味でADMIN(管理者)のように特定なリソースにアクセスできないことを意味します。つまり、認証は終わっているが、権限がないと意味がですね。
Unathenticationがより正しい名前になりますが、まずは覚えておいてください!
403 Forbidden
サーバーからrequestを受け取りましたが、承認を断った。
アクセス権限がない。
先ほどの、Unauthorizeの意味と一致しているメッセージです。
★404 Not Found★
requestしたリソースがサーバーに存在ない。
誤字、、、URL誤字です。
アクセス権限がないクライアントにページを隠したい時も使われます。(本来なら403ですが、存在したいを隠したい時)
5xx
サーバーからのエラー
500 Internal Server Error
サーバーの内部問題。
503 Service Unavailable
サーバーを一時的に点検する際(ダウンする時)、
一時的なオーバー
一般HTTP Header(representaion header)
header: representaion header
➞表現するデータの付加情報、表現データーを解釈できる情報
body : representaion data
➞何かを表現するデーターするデーターであり、ぱpayloadとも呼びます。
Content
Content-Encoding: 表現データーを圧縮するために利用。
データーを転送する側から圧縮した後、headerを追加。
データーを読む際に、Content-Encodingの情報を見て、解凍します。
例)Content-Encoding: gzip,Content-Encoding: deflate, Content-Encoding: identity(圧縮をしない)
Content-Length :表現データーの長さ(byte単位)
Transfer-Encodingとは平行不可(T-Eの中にC-Lが含めているからです。)
Accept(content negotiation)
クライアントがサーバーに好みのContentの種類をrequestする方式
Accept : クライアントの好みのmedia type(xml,
Accept-Language : qが高いほど優先順位が高いです。qを省略する場合、1になります。
例)Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
情報
Referer(request): 現在のページの前にWEB Pageアドレス
A->Bに移動する際には、常にReferer:Aをheaderに含めてrequest するので、サイトに入ったルートを調べる際によく使われます。
User-Agent(request) : クライアントのapplication情報(web brower)
ログを通して、どのブラウザーからエラーがあるかを把握できます。
Server(response) : requestにresponseするオリジナルサーバー
Date(response) : messageが発生した時間
Retry-After(response) : 503のようにサーバーが稼働していない際にサビースがいつまで利用できないを教えることができます。
例) Retry-After: Fri, 31 Dec 1999 23:59:59 GMT
Authorization(request): clientの認証情報をサーバーに転送
。REST APIでよく使われます。
WWW-Authenticate(response) : 401 Unauthorizedができていない際に、必要な認証方法を定義します。
例)WWW-Authenticate: Newauth realm="apps", type=1,
title="Login to "apps"", Basic realm="simple"
Cookie Header
長所:状態を維持することができる。(いつもユーザー情報を総べてもらう必要がないです。)
短所:様々なCookieを転送する際に、大量のtrafficが発生するので、サーバーに負担があります。保安にも弱いです。
Set-Cookie(response) : サーバーからクライアントにcookieを転送します。(まずはclientにもらうことが前提)
Cookie(response) : クライアントがサーバーからもらったcookieをWEB Browerに保存しますが、次にHTTP Resquestをする際にはサーバーに自動的にサーバーに転送されます。
Set-cookie:sessionId= : ログイン時、成功した際にID
Set-cookie:expires= : Cookieの寿命期間。省略された場合、ブラウザー終了まで維持で、入力する場合はその日まで永続維持。
Set-Cookie: max-age= : Cookieの住妙時間
例)max-age=3600 (3600秒)
Set-Cookie:domain: 指定した場合、明示されている基準domain + subdomainも含まれています。
例)domain=example.org : example.orgもdev.example.orgもcookieでアクセス
Set-Cookie:Path : 記載時、経路を含めたサブ経路までCookieでアクセスすることができます。
Secure : Cookieはhttp,httpsを区別せずに転送しますが、Secureはhttpsのみ転送します。
HttpOnly : XSS攻撃を防ぎ、JSからのCookieアクセスを封じます。
SameSite : XSRF攻撃を防ぎ、requestのdomainとCookieのdomainが一致している場合のみCookieを転送します。
Cache Header
Renderingの時間を節約するため、保存するデーター、イメージなど
cache-control:max-age= : cacheの寿命。秒単位です。
しかし、60秒後、cacheのライフサイクルがを終わり、また、同じファイルをサーバーからダウンロードするのは効率は悪いですね!
その際に、活用することが検証headerです。
クライアントに昔あったcacheデーターと今サーバーが持っているデーターを検証します。
条件付きリクエスト1
1 Last-Modified(response) :
サーバーは最後の修正日をクライアントに送り、クライアントはCacheに保存します。
2 if-modified-since(response) :
クライアントはサーバーからもらったLast-Modifiedのvalueをif-modified-sinceのvalueに指定し、サーバーにrequestをします。
cache-control:max-ageに指定した時間が終わったら、各headerにデーターを付け、検証します。
3 304 Not Modified
互いのheaderのvalueが一致する場合はサーバーからデーターを転送するのは無駄です。そのため、responseはstart lineに304 Not Modifiedを付けて転送します。
修正したデーターがないので、HTTP Bodyはありません。
headerのデーターのみ転送するので、節約ができます。
条件付きリクエスト2
1 ETag(response)
サーバーはCache用ファイルに独自の名前をETage付けて、クライアントに送り、クライアントはETagをCacheに保存します。
2 If-None-Match(request)
クライアントはサーバーからもらったETagのvalueをIf-None-Matchのvalueに指定し、サーバーにrequestをします。
後は同じです。
Cache Controll Header
Cache-Control: no-cache : Cacheを保存することはOK!しかし、Cache(Froxy)サーバーではなく、本来のオリジナルサーバーと検証するという意味です。no-cacheという名前ですが、cacheがあります。
(Froxyサーバーは後で説明します。)
Cache-Control: no-store : データーに重要なデーターがあるので、保存しないことを通知し、早くメモリから削除。
Proxy-cache
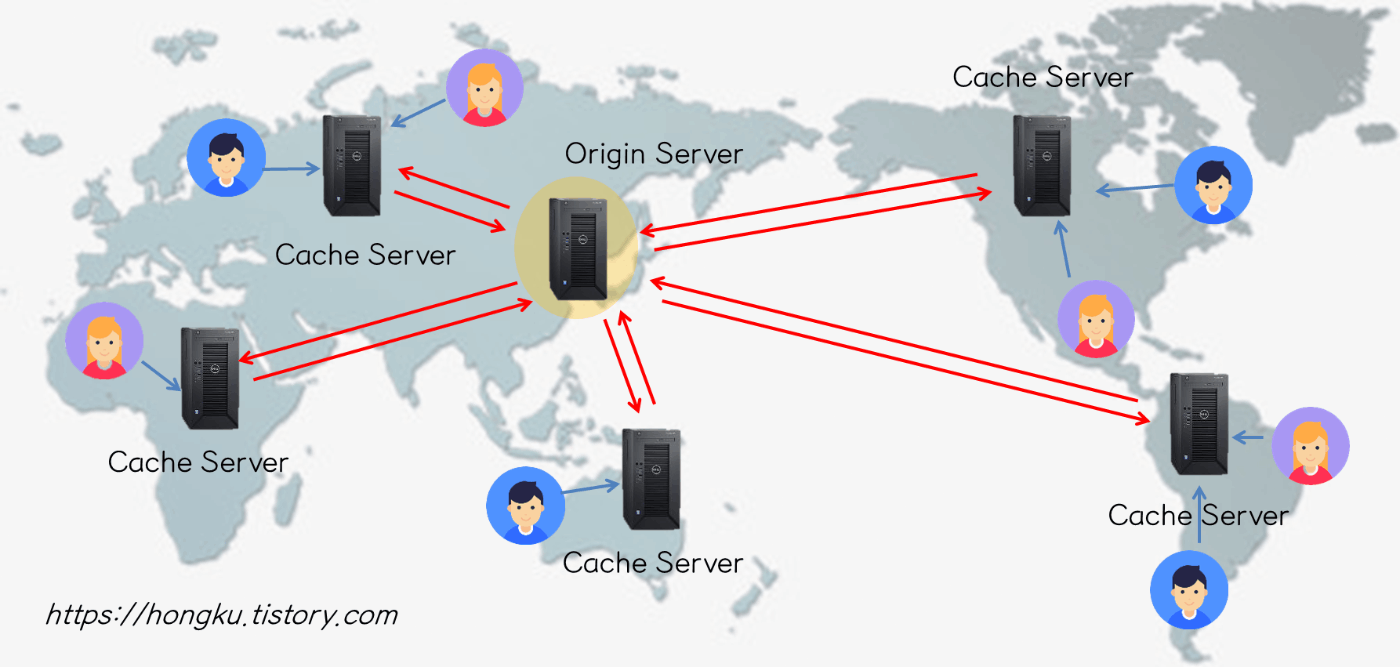
https://velog.io/@youngblue/CDN이란-무엇인가
Netflix, Youtubeの場合、本社はアメリカにあります。日本、韓国からオリジナルサーバーからのデーターをもらうためには時間がかかりますね。そのため、グロバールサービスの場合、様々な国にもサーバーを増設し、requestは自動的にFroxy(Cache)サーバーに繋がります。
Cache-Control: private : レスポンスは特定のユーザー専用であるため、プライベートキャッシュとして、ユーザーに保存されます。(default)
Cache-Control: public : ユーザーのデーターがFroxyサーバーのcacheに保存します。
Cache busting(cache無効化)
Cache-Control: no-cache, no-store, must-revalidate
Pragma: no-cache (HTTP 1.0の下のversion対応)
この組み合わせで、Cacheを無効かすることができます。
Cache-Control: must-revalidate :
オリジンサーバーへのアクセスが失敗した場合、必ずエラーが発生する必要があります - 504(ゲートウェイタイムアウト)。
Discussion