Meta XR Voice SDKを試す
はじめに
Meta XR Voice SDKを以下の条件で試してみる。
- M1 Mac
- Unity 6
- iPhone 15 Pro
Voice SDKの入手
Unity Asset StoreからSDKを入手できる。All-in-One SDKにも含まれている。
Meta - Voice SDK - Immersive Voice Commands
ちなみに、Unity Asset StoreにはVoice SDKという名前がつくアセットが他にも以下の3つあるが、これらは更新が2023年で止まっている。公式ウェブサイトのリンクから飛べるのは上記のアセットだけなので、ひとまずそれを試す。
Meta XR Voice SDK - Dictation
Meta XR Voice SDK - Telemetry
Meta XR Voice SDK - Composer
音声コマンドを試す
公式ウェブサイトに載っている音声コマンドのチュートリアルを試す。
チュートリアルに記載されていない気がするが、「Step 4: Linking the App Voice Experience to the Timer」をやる前に、Wit.aiウェブサイトでBuilt-inのIntentやEntityを追加する必要がある。そうしないと、Step4でintentやentityのデータを得られない(空のデータが返ってくる)ので先に進めなくなる。
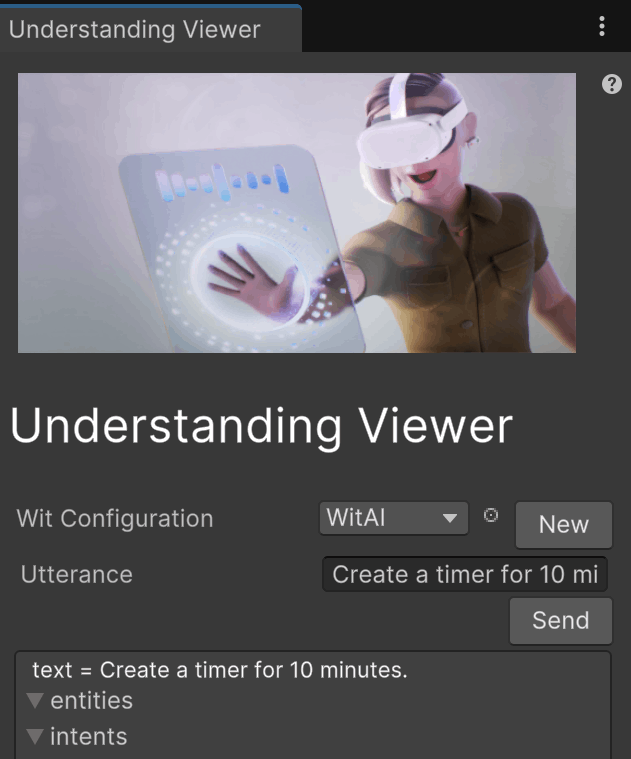
※ちなみにintentやentityはチャットボットで使われる用語で、こちらの記事で解説されてる。
以下のように、Wit.aiウェブサイトでIntentやEntityを追加する。

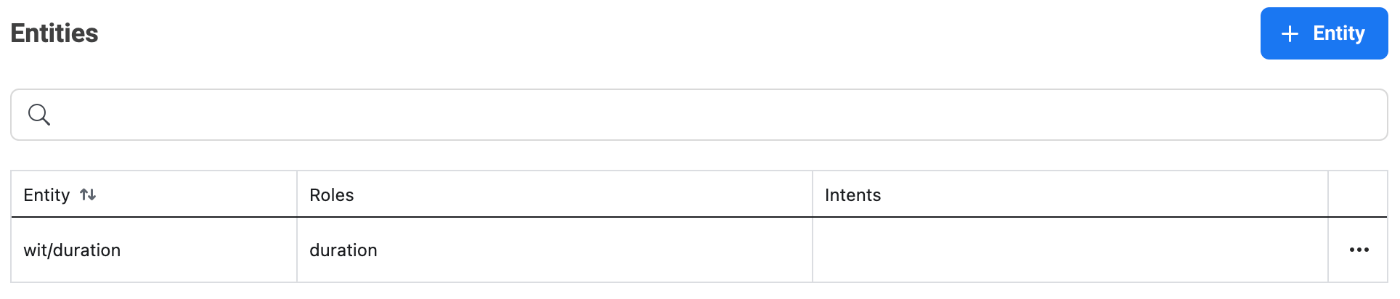
その後チュートリアルに沿ってシーンを作成したところ、無事タイマーを音声制御できた。
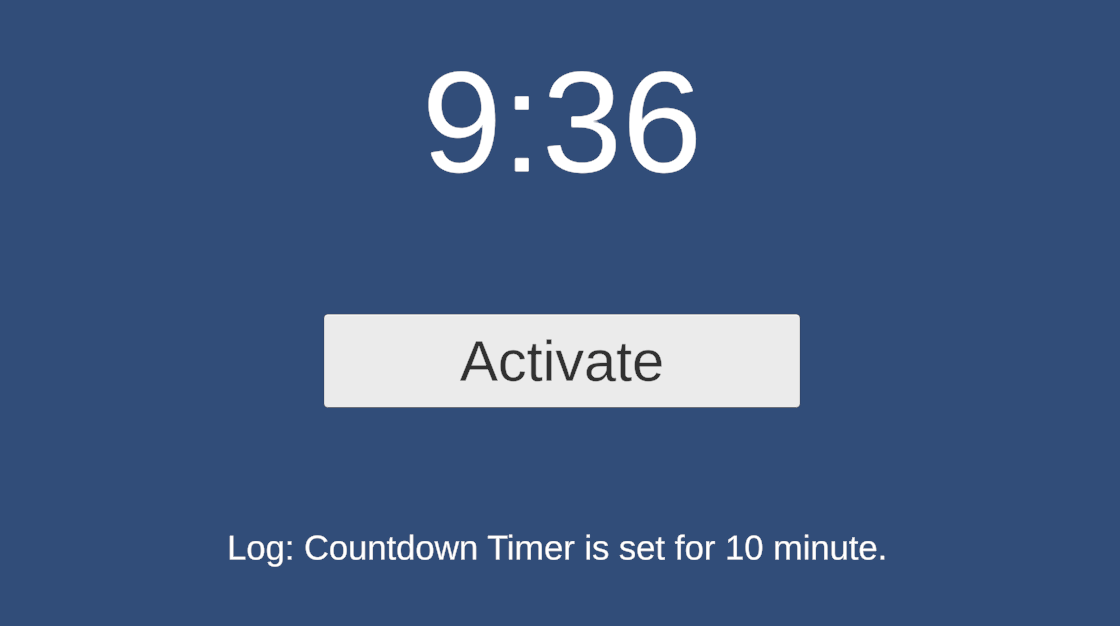
音声入力を試す
以下の音声入力機能に関する記事に沿ってシーンを作成したところ、その場で話した文章がテキストに無事変換された。
やったことの要約
- Wit.aiのサイトからアクセストークンを入手
- Unity上でVoice SDKの設定
- シーンにApp Voice Experience等を追加
日本語と英語の両方とも変換された。ただし、Wit Configurationアセットをそれぞれの言語向けに作成して、App Voice ExperienceのWit Runtime Configuration > Wit Configurationに指定するアセットを切り替える必要がある。英語向けのWit Configurationを指定して「こんにちは」と話すと、「Call me to」と変換された。
音声読み上げを試す
以下の記事を参考に音声読み上げ機能を試したところ、その場で入力した英語の文章が無事に読み上げられた。ただし、日本語の読み上げはまだ対応していない模様。
やったことの要約
- シーンにDefault TTS Setupを追加
- TTSSpeakerのSpeakメソッドを呼び出す
public InputField inputField;
public TTSSpeaker ttsSpeaker;
// ボタンがクリックされた時に、InputFieldに入力された文章を読み上げる
public void OnClick()
{
var text = inputField.text;
ttsSpeaker.Speak(text);
}
Composerを試す
Composerとは、グラフを使って音声インタラクションを設計できるWit.aiの機能らしい。
セットアップ
まず、Composerを使用するために必要なUnity Packageを以下のGitHubから入手してインポートする。 ところが、インポート後にエラーが発生。Voice SDKのアップデートによってファイルの命名規則が変わり(Facebook.Wit...→Meta.Wit...)、異なる名前のファイルが同じGUIDを共有してしまっている模様。
なので、古いバージョンのVoice SDK(Oculus Voice SDK v46.0)を以下のサイトから入手しインポートし直す。 改めてComposer用のUnity Packageをインポートしたところ、エラーは発生しなかった。
Witアプリのトレーニング
以下の記事に従って、Wit.aiウェブサイトでカスタムNLPモデルを作成する。
「Make yourself {color}」というutteranceの追加を4回くらい繰り返す。

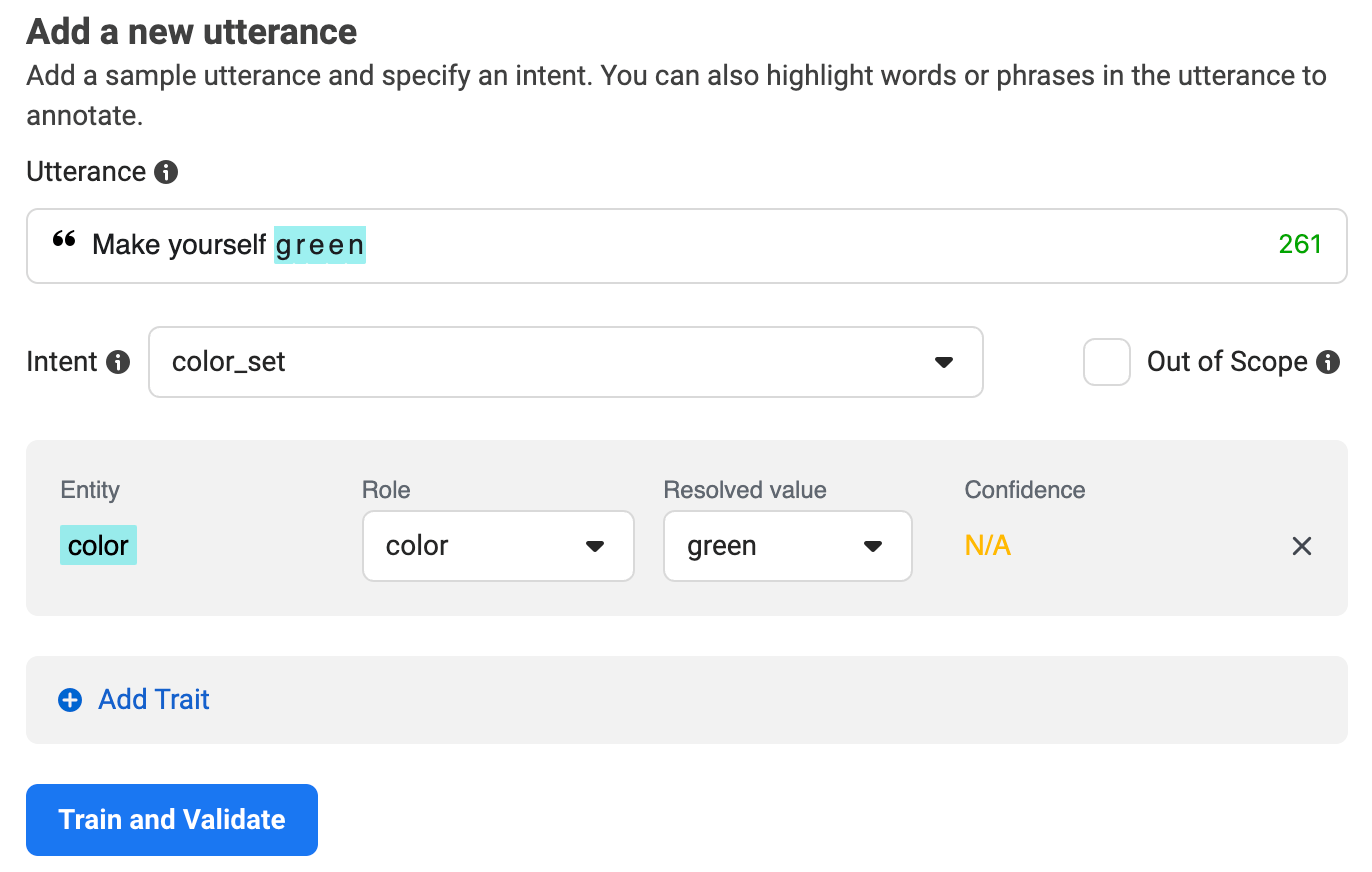

3回目から色のワードを認識し始めた。
Composer Graphの作成
以下の記事に従って、Wit.aiウェブサイトでComposer Graph(音声インタラクションの流れを示すグラフ)を作成する。
記事で明記されていない気がするが、G Response moduleを配置する際にActionフィールドにchange_colorと入力する。あとデプロイするのを忘れずに。

デモシーンの実行
Unityに戻り、Assets/Oculus/Voice/Lib/Wit.ai/Features/Composer/Samples/SingleCharacterDemo/SingleCharacterDemo.unityを実行する。
Activateボタンを押して「Make yourself red」と話すと、無事カプセルの色が赤に変わった。

まとめ
以上、Meta XR Voice SDKの各機能を試した。
- 音声をテキストに変換(Speech-to-Text)
- テキストを音声に変換(Text-to-Speech、英語のみ)
- 音声コマンド
- Composer(Oculus Voice SDK v46.0を使用する必要あり)
デザインガイドライン
公式ウェブサイトに、音声インタラクションを設計するうえでのTipsがまとまっている。
個人的に気になったTips
- 音声インタラクションをアクティベートする手段として、以下のような方法があるがそれぞれ長所と短所がある。
- 視線: 特定のオブジェクト(ex. ゲームにおける仲間のキャラクター)に視線を向けたときにアクティベートする。直感的な操作を可能にするが、視線検知の精度はあまり良くない。
- ハンドジェスチャ: ジェスチャ検知の精度は高いらしいが、ユーザの無意識なジェスチャも検知される可能性がある。
- その他: コンテンツの文脈に合わせた動作(ex. 魔法のランプをこする、魔法の鏡の前に立つ)によってアクティベートすれば没入感が高まるが、その動作によってアクティベートすることにユーザが気づかない可能性もある。
- 音声インタラクションにおけるエラーは予想されるよりはるかに多い(ユーザの発言が聞こえない、予想される発言意図と一致しない等)。同じエラーが繰り返された時にもさまざまな言い方でレスポンスできるよう設計する。システムから同じ言い回しのレスポンスが何度も返ってくると、没入感を損ねかねない。
公式サンプル・ツールキット
「Whisperer」という、Voice SDKを使ったゲームのサンプルが提供されている。
ハンドジェスチャと視線によって音声インタラクションをアクティベートしている。
また、VoiceSDK Toolkitも提供されている。
サンプルに入っている、マイクに息を吹きかけた時の音量に基づいて風車が回るシーンが面白かった。