自作DBMSをする ~ACID特性をもつトランザクションを実装する~
今回自作DBMSを(途中まで)やってみました!
Database Design and Implementationを参考にACID特性をもつトランザクションを実装しました。以下ではこの本のことを頭文字をとってDDIと呼ぶことにします。
DDIにはJavaによる参考の実装がされていますが、それをそのまま写経するのはあまりやりたくなかったため、この本を読んでおおよその概要をつかみ、自分でクラス等を実装しなおしてC++で実装しました。
DDIではリレーショナルなデータベースを実装し、SQLをパースして、クエリを実際に処理するところまで解説されていますが、そこまでは進んでおらず5章のACID特性をもつトランザクションを実装するところまでやりました。以下のレポジトリに実装があります。気になる方は覗いてみてください!
1. 全体の設計
おおよそはDDIに沿っていますが、一部実装等が異なるところがあります。設計としては下のような図になっています。
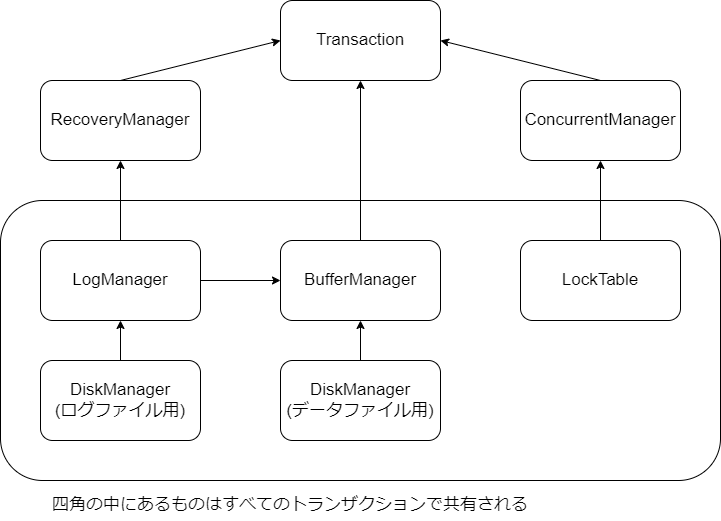
図中の矢印は矢印の先のクラスが矢印がでているクラスに依存しているということを意味します。図中のそれぞれは以下のような機能を持っています。
DiskManager
ブロック単位でのファイルへの書き込み、読み込みを行う。ブロックサイズは任意の大きさに設定することができる。
BufferManager
ブロックをメモリ上にキャッシュし、できるだけ効率的にファイルへの書き込み、読み込みを行えるようにする。ブロックをファイルに書き込むときに、対応するログファイルをフラッシュすることでWAL(Write Ahead Logging)を実現する。
LogManager
ログの書き込み、読み出しを行う。
RecoveryManager
トランザクションのロールバック、コミット、またリカバリを行う。ログファイルの内容を読んでこれらの処理を行う。
ConcurrentManager
ブロック単位のロックを掛けたり、ロックの解除を行う。これはトランザクションがSerializabilityを満たすようにロックを掛けるときに利用される。
Transaction
以上の実装を用いてトランザクションを実装する。ディスクへの読み書きをint, char, byte列などの単位で行う。
2. トランザクションはどのように効率性を実現しているか?
トランザクションを実装していて改めて気づいたことはトランザクションはできるだけファイルに触らずにデータを読み書きするようにする工夫に全力を尽くしているということです。
コミットされたトランザクションが書き込んだデータは永続的に読み出し可能でないといけないため, コミットする際に絶対にどこかではファイルに何かを保存する必要があります。しかしすべてのデータをファイルに書き込んでいるととても遅くなってしまうため、できるだけファイルを触らない工夫をしています。
トランザクションの一連の流れは次のようになります。
- トランザクション開始
- データファイルへの読み書き
- コミットもしくはロールバック
データファイルへの読み書き時にはその書き込みはBufferManagerを通じて行われます。BufferManagerはブロックをevictするとき以外は、メモリ上で処理を行います。また、2でログファイルへの書き込みも行われるが、この時にはログファイルはフラッシュはされず、バッファに書き込まれます(BufferManagerによってブロックがevictされるときにはフラッシュされる)。
トランザクションの実行中に必ずファイルに書き込むのは3においてコミットするときにログファイルをフラッシュするときです。コミットしたトランザクションのログが書き込まれていないとDurabilityを満たすことができないため、このフラッシュだけは絶対に必要です。
このようにできるだけファイルに触らないようにする努力を実装していて感じました。
3. 学び
今回トランザクションまで自作してみて学びがいくつかありました。
一つ目にDBMSは「できるだけ効率的にデータの読み出しと保存を行い、かつデータが永続化されるようにする」という普遍的な?課題にある程度解決策を与えていると思ったという点です。
効率的にデータを読み書きしたいだけならメモリのみ使ってやり取りすればいいだけですが、それを永続化するためにはメモリを使うだけではだめです。この効率性と永続性という二つの性質をできるだけ達成するためにバッファを使ったり、ログを使うなどの工夫を凝らしています。
二つ目に本の写経ではなくて一回本を読み込んでから自分で実装するという方針をとったことでその実装がなぜ必要なのか?ということに対する理解が深まったことです。
今まで本などの写経をしたときに感じていたこととして、とりあえず本を前から読んで実装を写していくのでその実装の必要性を理解せずにとりあえず実装をしているということがありました。今回の取り組みではここでこれを実装するからこの機能は最低でも必要といった形や、あとで機能を実装するときにやっぱりこの実装は必要だったなどという形で実装の必要性を理解しながら実装できました。
4. DDIと異なる部分 & 工夫点
補足にはなるが、DDIといくつかの点で異なるのでその点について挙げてみます。
Result型の導入
C++ではエラーハンドリングは通常例外を投げることで行われますが、GoやRustのように明示的にエラーであることを明示してエラー処理をしたかったためResult<V, E>型というものを導入しました(result.h)。
このブログにあるものをベースに実装しました。
これを導入することでエラーハンドリングおよび、デバッグがとても楽になりました。どこかでエラーが起こった場合はResultのエラーメッセージを出力することでどこからエラーが来たかわかるようになっており、バグの出所が明確になりました。その反面Goでのエラーハンドリングなどと同じように、
ResultV<int> x = Func();
if (x.IsError()) {
return x + Error("error when getting x");
}
のような冗長なコードが大量に発生してしまったことが欠点としては上げられます。あとResult型のせいでオブジェクトのコピーが大量に発生して速度的には不利になっているのではないかと思っています。ちゃんと計測したりしていないのでわからないですが、もしこれのせいでめっちゃ遅くなっているとかならなんとかしないとなと思います。現状では利点が欠点を上回ると思っているのでよしと思っています。
C++を完全に理解していないのでResult型のどこかでメモリリークなどの実装ミスがある可能性があるのですが、今のところこれで動いているので良しということにしています。どこかでC++のムーブコンストラクタなどについて勉強をし直してちゃんと実装をしたいとは思っています。
Logフォーマット
DDIでは文字列ベースのログを使っています。文字列ベースでも可能だが、できるだけログのサイズを小さくしたかったので、バイト列のログフォーマットを定義してそれを実装しました。自分で考えたログフォーマットはこれです。
初めに考えたものから実装していくうちに「ああ実はこれも必要だった」などという形でフォーマットが変わっていったので、結構大変でした。
Data型の導入
DataItem という抽象クラスをつくり、その派生クラスとしてInt, Charなどを実装しました。データの書き込みはconst DataItem&型に対して行えるのでこの派生クラスを実装するとデータの書き込みが行えるようになります。新しいデータ型とかを追加するときにこういう形の方が便利かなと思ったのでこのように実装してみました。
読み込みはデータ型ごとにReadInt, ReadCharなどの関数を使います。std::unique_ptr<DataItem>を返り値に持つような関数を読み込みの関数として実装してもよかったのですが、結局DataItemから値を取り出すにはバイト列から値を読み出すということをしないといけないため、やめることにしました。
Recoveryの仕方
DDIではUnDoのみでリカバリを行うような実装でしたが、僕の実装ではUnDoステージとReDoステージの二つを用いたアルゴリズムとなっています。UnDoのみのリカバリの場合、トランザクションをコミットする前にデータを書き込んだバッファをすべてフラッシュ(ディスクに書き込む)する必要があります。こうするとコミットの時にディスクの書き込みがとても発生する気がしたのでUnDoステージもReDoステージともに実装しました。
まとめ
トランザクションまで作ったがやり残したことがたくさんあります。たとえば
- デッドロックのより良い検出、解消の仕方
- (Non-)quiscent checkpointing
- バッファをevictするよりよいアルゴリズム(キャッシュアルゴリズム)
- トランザクションを実行中に電源をシャットダウンしてコミットされたデータが読み出せることを確認するテスト
などです。とりあえずトランザクションを使ってリレーショナルなデータベースの機能を実装してから徐々に取り組んでいけたら良いなと思っています!
Discussion