Open8
名寄せ調査
やりたいこと
自分の書いた特定のコンテキスト内での表記ゆれを検出したい
例えば
- 「料理する人」と「調理する人」は表記ゆれ
- 「基底クラス」と「抽象クラス」はok
としたい。
ただここを厳密に見分けられなくとも、表記ゆれ可能性としてリストアップ&人力での判定はok
その他調べた専門用語
- 埋め込みベクトル
- 連続量で分けるためのもの。特徴量のこと
GPT先生に聞いた
Jaccard係数アルゴリズム: このアルゴリズムは、2つの集合間の類似度を計算するために使用されます。名寄せの文脈では、データレコードの共通要素の割合を計算し、一定の閾値を超える場合にレコードを関連付けるために使用されます。
Levenshtein距離アルゴリズム: このアルゴリズムは、2つの文字列間の編集距離を計算します。文字列内の文字を挿入、削除、または置換することで、1つの文字列を別の文字列に変換するために必要な最小操作回数を測定します。これは、文字列ベースの名寄せに使用されます。
n-gramベースのアルゴリズム: このアルゴリズムは、文字列をn個の文字の連続した部分文字列に分割して、文字列間の類似度を計算します。これにより、単語やフレーズの類似性を捉えることができます。
Bloom Filterアルゴリズム: Bloom Filterは、要素が集合内に存在するかどうかを高速に判定するための確率的データ構造です。名寄せでは、大規模なデータセットを高速に処理する際に使用されます。
Fellegi-Sunterモデル: このモデルは、確率的レコードリンケージのための統計的なフレームワークです。フィールドごとの確率や重みを考慮して名寄せを行うことができます。
前3個は昔やったが期待するほどの結果は得られなかった。(n-gramはてきとうだったが)
そもそもレーベンシュタイン距離とかは誤字検出用な気がする
もうちょっとルールを作らずに手元にあるデータから意味的な表記ゆれを検出したい
BERT
前後関係を含めて学習するらしい
これは良いのではと思うも、うまい使い方がわからない。
今回対象となる文章群を次のように作成した
- sentence pieceで学習&分かち書き
- BERTで学習
- 学習済みのモデルから組み込みベクトルを取得。(コサイン)類似度の計算&TSNEで低次元化プロット
投稿記事の「クラス構造を考える(継承など)」「クラス構造を考える(集約など)」のplantuml部分など適当に削除して学習させた
※hash値:7a361fa
その後「クラス」との静的な文章類似度を出した。1が最も近いのでクラスっぽいという指標
→次元削減前の類似度で表示するとほぼ類似しない(最大0.1程度)結果になる。次元削減後に類似度を出さないといけないらしい。原理は知らないが、まあ多次元だから類似度は下がるのだろう

↓
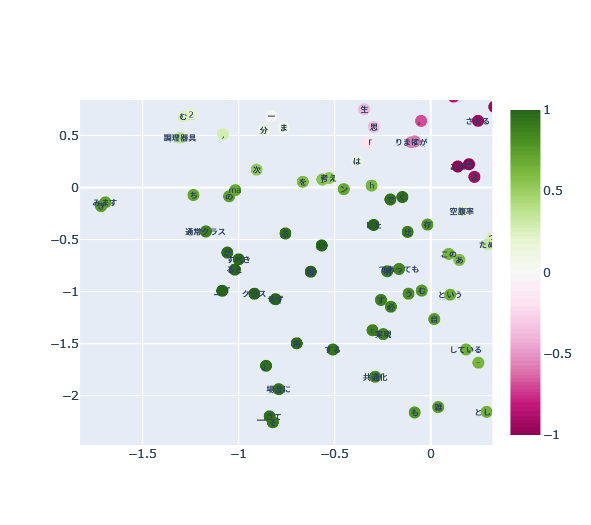
「通常クラス」、「共通化」などはまあ近い。
「せず」、「ると」、「「」などが近い理由が謎。文章的にも別に使い方が近いようには思えない。
名詞だけで良いのだが、うーん
外部サービス
とかはなんかいい感じっぽい(でも中身わからないので勉強にはならないしお金がかかるのは困る)
そのためいい感じのものを目指すことは可能なはず
Yahoo! 校正支援 Web API のほうは微妙