[CUDA] NVIDIA GPUやCUDA周りの互換性を理解したかった
よくわからなかったので、調べて整理しようとした試み。
Compute Capability
GPU ハードウェアがサポートする機能を識別するためのもので、例えば RTX 3000 台であれば 8.6 であるなど、そのハードウェアに対応して一意に決まる。
アーキテクチャの世代が新しくなり、機能が増えるほど、この数字も上がっていく。
以下のリンク先に、Compute Capability と機能の対応表があるが、これを見ると(少なくとも執筆時点で) Compute Capability 7.x 以上でテンソルコアが使えるといったことがわかる。
それぞれの機種がどの値かは以下のサイトから確認できる。
NVIDIA Driver のバージョン
Compute Capablity
一般向けの Compute Capability との関連性は見つからなかったが、データセンタ向けの資料には Maxwell から Hopper の全てで 450.36.06+ から latest までサポートしているとある。
自分は未だに Pascal の GPU (GTX 1080) を使っているが、Driver Version は 525.60.13 まで上げられているし、実感ともあっている。
その他
OS や Linux カーネルのバージョンによって動いたり動かなかったりする方が多そう。
CUDA Toolkit のバージョン
NVIDIA Driver
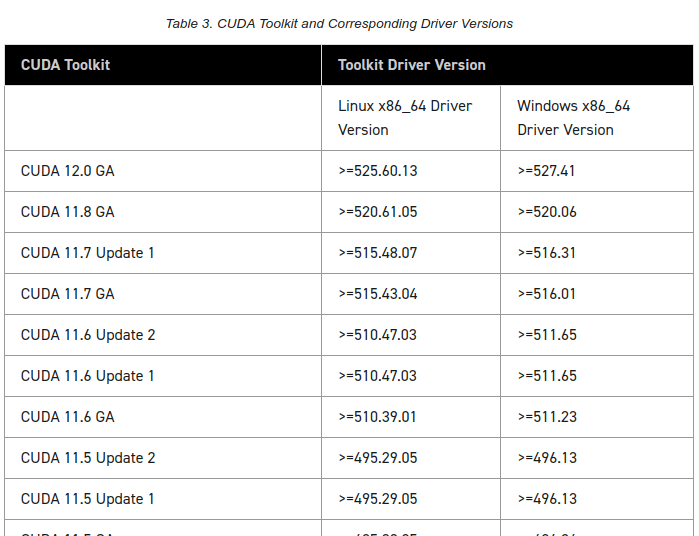
CUDA Toolkit のバージョンとドライバのバージョンの互換性は以下にあった。
これをみると上のバージョンの CUDA Toolkit を使うほど、必要なドライバのバージョンも上がっていく傾向にあることがわかる。
逆に言うと、この表を見る限りはドライバのバージョンを上げることによるデメリットはなく、可能な限り最新にしておけばよさそう。
Compute Capability
一方で、Compute Capability に関しては制限がある。以下は再びデータセンタ向けの資料だが、Compute Capability が上がるほど、必要な CUDA Toolkit のバージョンも上がってしまう。
まあこれは当然で、新たな機能、アーキテクチャに対応しようとすれば互換性が切れるのは仕方がない。
| Hardware Generation | Compute Capability | CTK Support |
|---|---|---|
| Hopper | 9.x | 11.8 |
| NVIDIA Ampere GPU Arch. | 8.x | 11.0 |
| Turing | 7.5 | 10.0 |
| Volta | 7.x | 9.0 |
| Pascal | 6.x | 8.0 |
| Maxwell | 5.x | 6.5 |
また、CUDA 12.0 で CUDA Libraries が Compute Capability 3.5, 3.7 (Kepler) で使えなくなるなど、前方互換性が常に保たれるわけではなさそう。
実際にやってみたが、CUDA 11.0 だと 9.0 向けには当然コンパイルできず、3.5 は Warning が表示された。
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Wed_Jul_22_19:09:09_PDT_2020
Cuda compilation tools, release 11.0, V11.0.221
Build cuda_11.0_bu.TC445_37.28845127_0
$ nvcc hello.cu -arch sm_35
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
$ nvcc hello.cu -arch sm_90
nvcc fatal : Value 'sm_90' is not defined for option 'gpu-architecture
一方 CUDA 12.0 だと 9.0 向けにコンパイルできたが、3.5 向けにはできなくなっていた。
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Mon_Oct_24_19:12:58_PDT_2022
Cuda compilation tools, release 12.0, V12.0.76
Build cuda_12.0.r12.0/compiler.31968024_0
$ nvcc hello.cu -arch sm_35
nvcc fatal : Value 'sm_35' is not defined for option 'gpu-architecture'
$ nvcc hello.cu -arch sm_90
バイナリの互換性に関しては後述する。
その他
NVIDIA が提供していない OS だと入れづらい。汎用 PC なら Docker を使えば大体なんとかなると思う。
もっと詳しく
一旦流したが、CUDA Toolkit と Compute Capability の互換性をより正確に理解するためには、「nvcc の -archと -code とは何か」を理解しておく必要がある。
以下のような適当な Hello World を書いて実行することを考える。
#include <cstdio>
__global__ void cuda_hello(){
std::printf("Hello World from GPU!\n");
}
int main() {
cuda_hello<<<1,1>>>();
cudaDeviceSynchronize();
return 0;
}
私が使っている GPU の Compute Capability は 6.1 なので -arch compute_61 -code sm_61を指定すると正しく実行できる。
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Mon_Oct_24_19:12:58_PDT_2022
Cuda compilation tools, release 12.0, V12.0.76
Build cuda_12.0.r12.0/compiler.31968024_0
$ nvcc hello.cu -arch compute_61 -code sm_61 && ./a.out
Hello World from GPU!
# 以下と同様
# nvcc hello.cu -gencode arch=compute_61,code=sm_61 && ./a.out
なぜ 2 つも指定する必要があるのか疑問に思うかもしれない。これらには以下のような違いがある。
- arch: 中間表現である PTX (Parallel Thread eXecution) をどのように生成するか決定するための指定
- code: PTX から生成されるアセンブリである SASS[1] と、さらにその先のバイナリ(cubin)を生成する指示
また、PTX には Compute Capability に関して後方互換性があり、compute_xy 向けに生成されたものは sm_xy以上向けにコンパイルができる。
そういう意味で compute_xy は virtual architecture、 sm_xy は real architre とドキュメントでも区別されている。
例えば、あまり意味はない(むしろ最適でないコードが吐かれる可能性がある)だが以下のようにすることもできる。当然逆は失敗する。
$ nvcc hello.cu -arch compute_50 -code sm_61 && ./a.out
Hello World from GPU!
$ nvcc hello.cu -arch compute_61 -code sm_50
nvcc fatal : Incompatible code generation requested: arch='compute_61', code='sm_50'
PTX には後方互換性はあると書いたが、バイナリの方は互換性は制限されている。例えば、sm_50 向けに吐くと何も出力されない[2]。
以下のドキュメントによるとデスクトップ向けに限り、マイナーバージョンに関して後方互換性があるよう
$ nvcc hello.cu -arch compute_50 -code sm_50 && ./a.out
ここで、疑問に思うかもしれない。あの秘密主義の NVIDIA が配布している共有ライブラリはなんで動くんだ、と。
種を明かせば単純な話で、あらゆるターゲット向けに吐いてまとめているだけだ[3]。
cuobjdumpというコマンドで中を見れば一目瞭然。
$ cuobjdump /usr/local/cuda/lib64/libcublas.so --list-elf | head
ELF file 1: tmpxft_0004f6b1_00000000-0.sm_50.cubin
ELF file 2: tmpxft_0004f6b1_00000000-1.sm_60.cubin
ELF file 3: tmpxft_0004f6b1_00000000-2.sm_61.cubin
ELF file 4: tmpxft_0004f6b1_00000000-3.sm_70.cubin
ELF file 5: tmpxft_0004f6b1_00000000-4.sm_75.cubin
ELF file 6: tmpxft_0004f6b1_00000000-5.sm_80.cubin
ELF file 7: tmpxft_0004f6b1_00000000-6.sm_86.cubin
ELF file 8: tmpxft_0004f6b1_00000000-7.sm_90.cubin
ELF file 9: tmpxft_0004f6b1_00000000-8.sm_50.cubin
ELF file 10: tmpxft_0004f6b1_00000000-9.sm_60.cubin
また、調べてみると PTX も含まれていることもわかる。
一見すると中間表現だから不要ではとも思えるが、PTX の後方互換性がある性質から、sm_91 以降が出ても最低限 JIT して実行できるようになっている。
$ cuobjdump /usr/local/cuda/lib64/libcublas.so --list-ptx | head -n5
PTX file 1: libcublas.1.sm_90.ptx
PTX file 2: libcublas.2.sm_90.ptx
PTX file 3: libcublas.3.sm_90.ptx
PTX file 4: libcublas.4.sm_90.ptx
PTX file 5: libcublas.5.sm_90.ptx
逆に、コンパイルオプションを付けないと意図せず JIT で動いていたということもありそうなので注意。
$ nvcc hello.cu && ./a.out
Hello World from GPU!
$ cuobjdump a.out
Fatbin elf code:
================
arch = sm_52
code version = [1,7]
host = linux
compile_size = 64bit
Fatbin elf code:
================
arch = sm_52
code version = [1,7]
host = linux
compile_size = 64bit
Fatbin ptx code:
================
arch = sm_52
code version = [8,0]
host = linux
compile_size = 64bit
compressed
ちなみに PTX を吐いて実行するには -code にも virtual architecture を指定すればよい。
$ nvcc hello.cu -arch compute_50 -code compute_50 && ./a.out
Hello World from GPU!
$ cuobjdump a.out
Fatbin ptx code:
================
arch = sm_50
code version = [8,0]
host = linux
compile_size = 64bit
compressed
参考
まとめ
まとめようとしてむしろ散らかった気もする。
-
こちらは何の略か不明。Shader ASSembly だとか何だとか (https://stackoverflow.com/questions/9798258/what-is-sass-short-for)。当然 CSS のアレではない ↩︎
-
ターゲットによって動いたり動かなかったりする ↩︎
-
イメージサイズ膨らんでる気がするのはもしかしてこれ?(ちゃんと調べてないので気のせいかもしれない) ↩︎
Discussion