【Rails】N+1問題と、その解決方法を丁寧に説明する
概要
N+1 問題とその対策方法についてまとめました。
なるべく図や表を使ってわかりやすく解説できるように心がけました。
また、あくまでも、N+1を起こさないことに注力して書いていきます。
クエリの実行時間は今回は無視していきます。
「N+1 ってなんだっけ?」
「joins とか eager_load とかよく聞くけど、違いがわからん。」
という方の参考になればと思っています。
最初にまとめ
まず、N*1 とは
対象のレコードをすべて取得するクエリを1回+そのレコードの数N回クエリが発行されること
その解決方法として以下の3つがあります。
| joins | eager_load | preload | |
|---|---|---|---|
| テーブル結合の種類 | 内部結合 | 左外部結合 | しないが、関連オブジェクトを取得するクエリが別で発行される。 |
| テーブル結合の特徴 | 外部キーを持っているレコードのみ残す | 外部キーを持っていないレコードも残して結合する | しない |
| 関連オブジェクトのキャッシュ | しない | する | する |
| 返り値 | テーブル結合後の、結合元のオブジェクトたち(重複あり)。 | 結合元のオブジェクトすべて一意で返る。 | レシーバのオブジェクトすべて。 |
| 使用場面 | 絞り込んでの検索。 | 関連オブジェクトがそれほど多くないときの N+1 対策。 | 関連オブジェクトが多いときの N+1 対策。 |
N+1 とはなにか
N+1問題を一言で説明すると、
対象のレコードをすべて取得するクエリを1回+そのレコードの数N回クエリが発行されること
になります。
おそらく大体の記事がこの用に説明していると思いますが、これだけだとわかりにくいので、
図を使って説明していきます。
1対多
まずはモデルの関係が、1対多のときを見てみましょう。
ER 図
1人の User は、複数の Article を持てるとします。

アソシエーション
class User < ApplicationRecord
has_many :articles
end
class Article < ApplicationRecord
belongs_to :user
end
レコード
User は1人だけで、紐づいている Article は存在しないとします。

N+1 が起きるコードを実行
User.all.each do |user|
p user.articles.pluck(:title)
end
rail console で実行してみましょう。
irb(main):171:1* User.all.each do |user|
irb(main):172:1* p user.articles.pluck(:title)
irb(main):173:0> end
User Load (4.1ms) SELECT `users`.* FROM `users`
Article Pluck (3.0ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 1
[]
以下のクエリが発行されていることがわかります。
- すべてのユーザーを取得するクエリが1回
- id = 1 のユーザーのすべての記事のタイトルを取得するクエリが1回
ユーザーを増やしてみる
次に、ユーザーを2人にしてみましょう。

再び rails console で実行します。
irb(main):256:1* User.all.each do |user|
irb(main):257:1* p user.articles.pluck(:title)
irb(main):258:0> end
User Load (11.1ms) SELECT `users`.* FROM `users`
Article Pluck (5.5ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 1
[]
Article Pluck (2.3ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 2
[]
今度は以下のクエリが発行されていますね。
- すべてのユーザーを取得するクエリが1回
- id = 1 のユーザーのすべての記事のタイトルを取得するクエリが1回
- id = 2 のユーザーのすべての記事のタイトルを取得するクエリが1回
更にもう一人ユーザーを増やしてみる
更にユーザーを増やして、3人にしてみましょう。

rails console で実行します。
irb(main):262:1* User.all.each do |user|
irb(main):263:1* p user.articles.pluck(:title)
irb(main):264:0> end
User Load (7.2ms) SELECT `users`.* FROM `users`
Article Pluck (4.5ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 1
[]
Article Pluck (1.6ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 2
[]
Article Pluck (1.2ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 3
[]
以下のクエリが発行されています。
- すべてのユーザーを取得するクエリが1回
- id = 1 のユーザーのすべての記事のタイトルを取得するクエリが1回
- id = 2 のユーザーのすべての記事のタイトルを取得するクエリが1回
- id = 3 のユーザーのすべての記事のタイトルを取得するクエリが1回
このように、
対象のレコード(今回だと users)をすべて取得するクエリを1回+そのレコードの数N回
クエリが発行される状態。これを N+1 問題と呼びます。
実際は、1+N の方がイメージしやすいと思います。
ちょっと現場のコードっぽく
ここで、comments テーブルを1つ増やして見ましょう。
現場ではよく、current_user.articles みたいなコードを書きますよね。
ちょっとそれをイメージしたコードを書いていきます。
ER 図
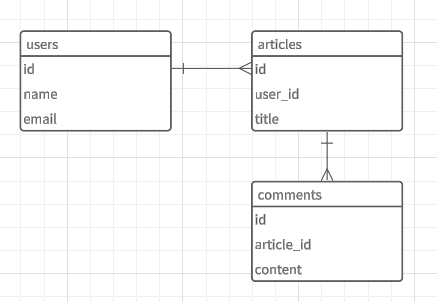
レコード

コード
# current_user は id 1番
current_user.articles.each do |article|
p article.comments.pluck(:content)
end
rails console で実行
irb(main):021:0> current_user = User.find(1)
User Load (35.4ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1
irb(main):029:1* current_user.articles.each do |article|
irb(main):030:1* p article.comments.pluck(:content)
irb(main):031:0> end
Comment Pluck (3.7ms) SELECT `comments`.`content` FROM `comments` WHERE `comments`.`article_id` = 1
[]
Comment Pluck (1.6ms) SELECT `comments`.`content` FROM `comments` WHERE `comments`.`article_id` = 3
[]
Comment Pluck (2.5ms) SELECT `comments`.`content` FROM `comments` WHERE `comments`.`article_id` = 4
[]
以下のようなコードが発行されていますね。
- ユーザー1に紐づく記事をすべて取得するクエリが1回
- id = 1 の記事のすべてのコメントの内容を取得するクエリが1回
- id = 3 の記事のすべてのコメントの内容を取得するクエリが1回
- id = 4 の記事のすべてのコメントの内容を取得するクエリが1回
ということで、こちらも
対象のレコードを(今回だと articles)すべて取得するクエリを1回+そのレコードの数 N 回
クエリが発行されています。
1対1
よく N+1 問題を説明している記事では1対多の関連付けのときの例がよくでていますが、
1対1でも起きます。
アソシエーション###
class User < ApplicationRecord
has_one :article
end
class Article < ApplicationRecord
belongs_to :user
end
レコード
rails console で実行
irb(main):106:1* User.all.each do |user|
irb(main):107:1* p user.article
irb(main):108:0> end
User Load (9.5ms) SELECT `users`.* FROM `users`
Article Load (4.2ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` = 1 LIMIT 1
nil
Article Load (5.1ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` = 2 LIMIT 1
nil
Article Load (1.8ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` = 3 LIMIT 1
nil
joins, eager_load, preload で N+1問題を解決する
N+1 問題がどんなものかわかったところで、最初の1対多の例に戻って
この N+1 問題の解決方法を見ていきましょう。
ER 図
class User < ApplicationRecord
has_many :articles
end
class Article < ApplicationRecord
belongs_to :user
end
それぞれの違い
ざっくりと違いを図にすると、こんな感じになります。

1つずつ見ていきます。
以下のようなレコードを考えてみましょう。

テーブル結合するもの

joins
まずはUser モデルに対して.joins(:articles) 実行してみましょう。
irb(main):163:1> User.joins(:articles)
User Load (4.3ms) SELECT `users`.* FROM `users` INNER JOIN `articles` ON `articles`.`user_id` = `users`.`id`
以下のような意味のクエリが発行されているのがわかります。
- users テーブルと articles テーブルを
INNER JOINして、users の情報すべて取得する。
INNER JOIN(内部結合)とは
ここで、INNER JOIN について説明します。INNER JOIN とは、
「結合先のテーブルで、外部キーを持っているレコードのみを残して結合する」
ことを言います。(内部、外部ややこしいですね...)
今回のレコードを例に見てみましょう。
こちらのテーブルでは id が2番の ユーザーは、記事を持っていません。
言い換えると、articles テーブルには、 user_id = 2 の外部キーを持つレコードが存在しません。
「結合先のテーブルで、外部キーを持っているレコードのみを残して結合する」
これが内部結合でしたので、結合結果のテーブルは以下のようになります。
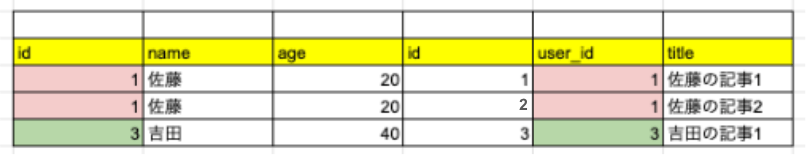
user_id=2 のユーザーのレコードが存在しなくなりましたね。
joins は関連オブジェクトをキャッシュしない
ここで、joins は関連オブジェクトをキャッシュしないという説明をします。
joins は、先ほど説明したように、テーブル同士を内部結合しています。
言ってしまえばそれだけで、この結合した大きいテーブルに対して、each を回していることになります。
つまり、ユーザーに紐づいている記事のオブジェクトをメモリに保持(関連オブジェクトをキャッシュ)するようなことはしません。
なので、joins は each 内でクエリを発行するような処理を書くと、N+1 が発生します。
irb(main):254:1* User.joins(:articles).all.each do |user|
irb(main):255:1* p user.articles.pluck(:title)
irb(main):256:0> end
User Load (14.9ms) SELECT `users`.* FROM `users` INNER JOIN `articles` ON `articles`.`user_id` = `users`.`id`
Article Pluck (2.8ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 1
["佐藤の記事1", "佐藤の記事2"]
Article Pluck (1.7ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 1
["佐藤の記事1", "佐藤の記事2"]
Article Pluck (1.2ms) SELECT `articles`.`title` FROM `articles` WHERE `articles`.`user_id` = 3
["吉田の記事1"]
- users テーブルと articles テーブルを INNER JOIN をして、 すべての users を取得するクエリ1回
- id = 1 の記事のすべてタイトルを取得するクエリが1回
- id = 1 の記事のすべてタイトルを取得するクエリが1回
- id = 3 の記事のすべてタイトルを取得するクエリが1回
図にするとこんな感じですね。

いつ jonis を使うのか
一見 joins の使い所がわからなくなりそうですが、使う場面としては、
「条件を絞り込んで検索したいとき」
になります。
例えば、「年齢が20歳で、プログラミングというタイトルの記事を書いたユーザー」というのを検索したいとします。
こんなレコードがあるとします。

age が20歳のユーザーが2人いますね。
joins を使わないで普通に検索しようとすると、こんな感じでしょうか。
User.where(age:20).select{ |user| user.articles.any?{ |article| article.title == "プログラミング"} }
確かに取得はできていますが、N+1が起きてしまいますし、コードもパッと見分かりづらいですね。
irb(main):363:0> User.where(age:20).select{ |user| user.articles.any?{ |article| article.title == "プログラミング"} }
User Load (3.0ms) SELECT `users`.* FROM `users` WHERE `users`.`age` = 20
Article Load (1.9ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` = 1
Article Load (1.2ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` = 3
=>
[#<User:0x0000ffffabe5e560
id: 1,
name: "佐藤",
email: "sato@example.com",
age: 20,
created_at: Tue, 23 Jan 2024 22:25:44.000000000 UTC +00:00,
updated_at: Tue, 23 Jan 2024 22:25:46.000000000 UTC +00:00>]
これを joins を使うと、このように書けます。
User.joins(:articles).where(age: 20, articles: { title: "プログラミング" })
コードもスッキリしていて、余計なクエリを発行しないようになっています。
irb(main):374:0> User.joins(:articles).where(age: 20, articles: { title: "プログラミング" })
User Load (5.1ms) SELECT `users`.* FROM `users` INNER JOIN `articles` ON `articles`.`user_id` = `users`.`id` WHERE `users`.`age` = 20 AND `articles`.`title` = 'プログラミング'
=>
[#<User:0x0000ffffab272a80
id: 1,
name: "佐藤",
email: "sato@example.com",
age: 20,
created_at: Tue, 23 Jan 2024 22:25:44.000000000 UTC +00:00,
updated_at: Tue, 23 Jan 2024 22:25:46.000000000 UTC +00:00>]
返り値について
今までは、テーブル結合と、発行されるクエリに焦点を当ててきましたが、ここで返り値の説明をします。
こちらは最終評価で何を返すでしょうか?
> User.joins(:articles)
レコードはこのような状態です。

正解はこちらです
> User.joins(:articles)
=>
[#<User:0x0000ffffaac8c8c8
id: 1,
name: "佐藤",
email: "sato@example.com",
age: 20,
created_at: Tue, 23 Jan 2024 22:25:44.000000000 UTC +00:00,
updated_at: Tue, 23 Jan 2024 22:25:46.000000000 UTC +00:00>,
#<User:0x0000ffffaac8c7b0
id: 1,
name: "佐藤",
email: "sato@example.com",
age: 20,
created_at: Tue, 23 Jan 2024 22:25:44.000000000 UTC +00:00,
updated_at: Tue, 23 Jan 2024 22:25:46.000000000 UTC +00:00>,
#<User:0x0000ffffaac8c698
id: 3,
name: "吉田",
email: "yoshida@example.com",
age: 40,
created_at: Tue, 23 Jan 2024 23:21:54.000000000 UTC +00:00,
updated_at: Tue, 23 Jan 2024 23:21:56.000000000 UTC +00:00>]
user_id=1 のオブジェクトが2つ返ってきていますね。
そして user_id=2 がいません。
なんかこんな状況、どこかで見ませんでしたか?
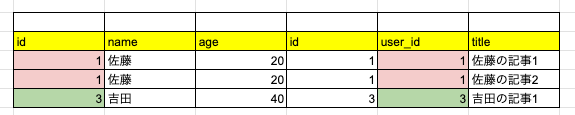
こちらですね!
そして、発行されている SQL がこちらでした。
User Load (5.1ms) SELECT `users`.* FROM `users` INNER JOIN `articles` ON `articles`.`user_id` = `users`.`id`
SELECT `users`.*
の部分から、内部結合後の users テーブルのオブジェクトだけを返していることが読み取れます。
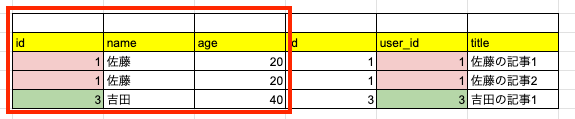
以上で、 joins は users と articles を INNER JOIN して、 users オブジェクトたちを返していることがわかりました。
eager_load
次に、eager_load について見ていきましょう。
eager_laod は、先程の joinis でしていた INNER JOIN(内部結合) に対して、LEFT OUTER JOIN(左外部結合)を行っています。
まずはその左外部結合から説明していきます。
LEFT OUTER JOIN(左外部結合)とは
左外部結合の定義は、
「結合先のテーブルで、外部キーを持っていないレコードも残して結合する」
になります。
また図を使って説明していきます。
こちらのレコードがあるとします。

「外部キーを持っていないレコードも残して結合する」ので、左外部結合を行うとこのようになります。
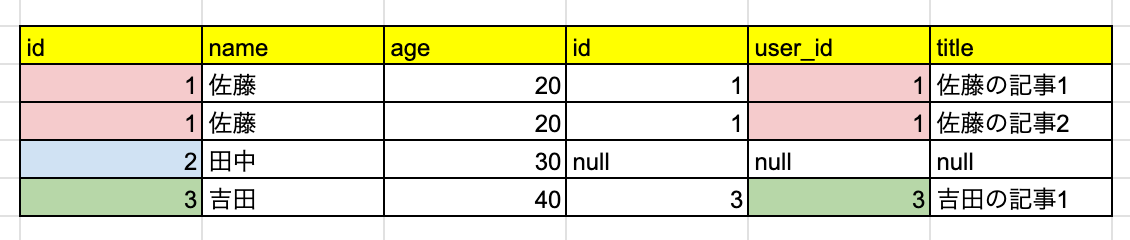
内部結合では、user_id=2 のユーザーは、記事を持っていなかったので、結合結果のテーブルには含まれていませんでしたよね。
左外部結合では、結合先のテーブルに外部キーを持つレコードがなくても、親のレコードを消さずに残しています。
そして user_id=2 の記事に関する情報はすべて null になります。
発行されるクエリを確認してみましょう。
実行するコードはこちら。
User.eager_load(:articles)
irb(main):007:0> User.eager_load(:articles)
SQL (11.4ms) SELECT `users`.`id` AS t0_r0, `users`.`name` AS t0_r1, `users`.`age` AS t0_r2, `articles`.`id` AS t1_r0, `articles`.`title` AS t1_r1, `articles`.`user_id` AS t1_r2 FROM `users` LEFT OUTER JOIN `articles` ON `articles`.`user_id` = `users`.`id`
ちょっと読みづらいクエリが発行されましたね...。
こちらも図で書いてみましょう。
作成されるテーブルはこちらです。

なんか難しそうなこちらのクエリは、AS を使って結合結果のテーブルのヘッダーの名前を決めていたんですね。ただそれだけだったのです。
SELECT `users`.`id` AS t0_r0, `users`.`name` AS t0_r1, `users`.`age` AS t0_r2, `articles`.`id` AS t1_r0, `articles`.`title` AS t1_r1, `articles`.`user_id` AS t1_r2
eager_load は関連オブジェクトをキャッシュする
joins では関連オブジェクトをキャッシュしないため、テーブル結合をしても N+1 問題が発生するとお話しました。
それに対して eager_load では、関連オブジェクトをキャッシュするので、同じコードではN+1 問題が発生しません。具体的に見ていきましょう。
実行するコードはこちら。
User.eager_load(:articles).all.each do |user|
p user.articles.pluck(:title)
end
irb(main):079:1* User.eager_load(:articles).all.each do |user|
irb(main):080:1* p user.articles.pluck(:title)
irb(main):081:0> end
SQL (38.6ms) SELECT `users`.`id` AS t0_r0, `users`.`name` AS t0_r1, `users`.`age` AS t0_r2, `articles`.`id` AS t1_r0, `articles`.`title` AS t1_r1, `articles`.`user_id` AS t1_r2 FROM `users` LEFT OUTER JOIN `articles` ON `articles`.`user_id` = `users`.`id`
["佐藤の記事2", "佐藤の記事1"]
[]
["吉田の記事1"]
どうでしょう。
先程の joins とは違い、最初にテーブルを結合するクエリしか発行されていません。
こちらで、eager_load は関連オブジェクトをキャッシュできてるということがわかります。
返り値について
さて、eager_load の返り値についても見ていきましょう。
User.eager_load(:articles)
joins では、結合結果のテーブルの、ユーザーのオブジェクトが返ってきていました。
ということは、eager_load でも、そのように返ってきそうですよね。
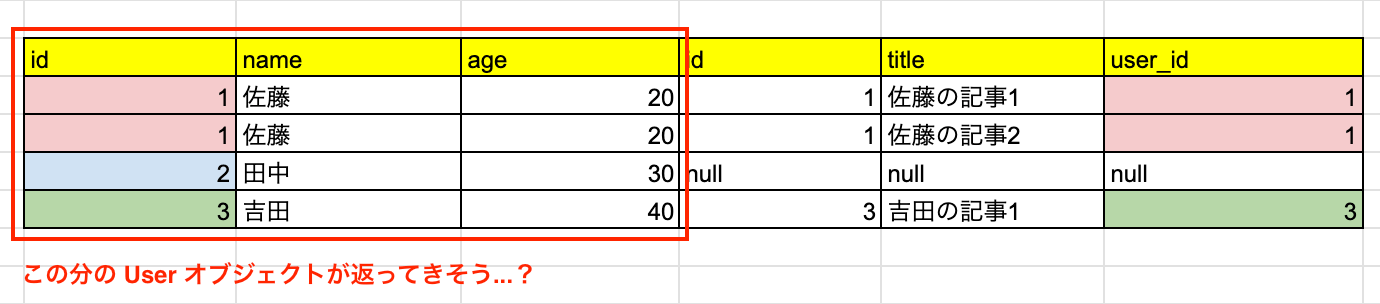
では実際にみてみましょう。
irb(main):153:0> User.eager_load(:articles)
=>
[#<User:0x0000ffffb5b845d8 id: 1, name: "佐藤", age: 20>,
#<User:0x0000ffffb5b8bef0 id: 2, name: "田中", age: 30>,
#<User:0x0000ffffb5b8bcc0 id: 3, name: "吉田", age: 40>]
あれ?
なぜか Uses オブジェクトが一意になって返ってきていますね。
これは、ActiveRecord が、eager_load をすると一意にして返すようにしているようです。この動きについては、自分もよく理解していないので、どなたかコメントいただきたいです...。
eager_load のコードを読んでみたのですが和集合や uniq をやっていそうなところはあるのですが、いまいち理解ができえおらず...。
この辺の知識持っている方いたら、ぜひコメントお願いします!
テーブル結合しないもの
さて、ここまでは joins, eager_load をみてきました。
これらはテーブル結合をするものでしたね。
次はこのテーブル結合をしない、preload をみていきましょう。

preload
preload はテーブル結合を行わず、関連オブジェクトのキャッシュだけを行います。
つまり、テーブルの状態は最初のまま何も変わりません。

それでは preload を使って発行されるクエリをみてみましょう。
irb(main):200:0> User.preload(:articles)
User Load (2.0ms) SELECT `users`.* FROM `users`
Article Load (1.8ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` IN (1, 2, 3)
2つのクエリが発行されていますね。
1つめのクエリは、ユーザーをすべて取得するためのクエリです。
ポイントは2番目のクエリですね。
Article Load (1.8ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` IN (1, 2, 3)
こちらのクエリで、 User オブジェクトに関連する Article オブジェクトを取得するクエリが発行されています。
ここで Article オブジェクトを取得してキャッシュしておくことで、eager_load のときのように、再度クエリを発行されることはなくなります。
実行するコード
User.preload(:articles).each do |user|
p user.articles.pluck(:title)
end
irb(main):209:1* User.preload(:articles).each do |user|
irb(main):210:1* p user.articles.pluck(:title)
irb(main):211:0> end
User Load (8.8ms) SELECT `users`.* FROM `users`
Article Load (2.7ms) SELECT `articles`.* FROM `articles` WHERE `articles`.`user_id` IN (1, 2, 3)
["佐藤の記事1", "佐藤の記事2"]
[]
["吉田の記事1"]
最初に発行された2つ以降、クエリが発行されていないことがわかります。
返り値について
preload の返り値についてもみてみましょう。
preload はテーブル結合しないので、User のオブジェクトがそのまま返ります。
User.preload(:articles)
irb(main):216:0> User.preload(:articles)
=>
[#<User:0x0000ffffb659f1a8 id: 1, name: "佐藤", age: 20>,
#<User:0x0000ffffb659f0b8 id: 2, name: "田中", age: 30>,
#<User:0x0000ffffb659ef28 id: 3, name: "吉田", age: 40>]
テーブル結合しないと何ができないのか
preload はテーブル結合をしないと説明をしてきました。
ではそもそも、テーブル結合する、しないでは何が違うのでしょうか。
それは、
結合先のテーブルの情報で、検索できるかどうか
のちがいになります。
joins
articles の情報で検索ができます。

> User.joins(:articles).where(articles: {title: "佐藤の記事
1"})
=> [#<User:0x0000ffffa665e400 id: 1, name: "佐藤", age: 20>]
eager_load

こちらも articles の情報で検索ができます。
> User.eager_load(:articles).where(articles: {title: "佐藤の記事1"})
=> [#<User:0x0000ffffa66941b8 id: 1, name: "佐藤", age: 20>]
preload

preload はテーブルの結合をせず、関連オブジェクトをキャッシュするだけだったので、
その関連オブジェクトの情報で検索(絞り込む)しようとするとエラーします。
> User.preload(:articles).where(articles: {title: "佐藤の記事1"})
(Object doesn't support #inspect)
User オブジェクトの情報のみで検索すると、普通にできます。
> User.preload(:articles).where(name: "佐藤")
=> [#<User:0x0000ffffa5464010 id: 1, name: "佐藤", age: 20>]
再度まとめ
今回のまとめをざっくりするとこんな感じです。
まず、N*1 とは
対象のレコードをすべて取得するクエリを1回+そのレコードの数N回クエリが発行されること
その解決方法として以下の3つがあります。
| joins | eager_load | preload | |
|---|---|---|---|
| テーブル結合の種類 | 内部結合 | 左外部結合 | しないが、関連オブジェクトを取得するクエリ別で発行される。 |
| テーブル結合の特徴 | 外部キーを持っているレコードのみ残す | 外部キーを持っていないレコードも残して結合する | しない |
| 関連オブジェクトのキャッシュ | しない | する | する |
| 返り値 | テーブル結合後の、結合元のオブジェクトたち(重複あり)。 | 結合元のオブジェクトすべて一意で返る。 | オブジェクトすべて。 |
| 使用場面 | 絞り込んでの検索。 | 関連オブジェクトがそれほど多くないときの N+1 対策。 | 関連オブジェクトが多いときの N+1 対策。 |
eager_load と preload の使い分けについては、関連オブジェクトの数によって検討したほうが良さそうですね。
Discussion