10万オブジェクトを低レイヤーの力で描画する
問題のコード
using System.Collections.Generic;
using UnityEngine;
public class Performance : MonoBehaviour
{
public float speed = 0.1f;
public GameObject target;
List<GameObject> gameobjects = new List<GameObject>();
void Start()
{
for (int i = 0; i < 10000; i++)
{
gameobjects.Add(Instantiate(target, RandomPos(100), Quaternion.identity));
}
}
Vector3 RandomPos(float distance)
{
return new Vector3(Random.Range(-distance,distance), Random.Range(-distance, distance),Random.Range(-distance, distance));
}
private void FixedUpdate()
{
foreach(GameObject obj in gameobjects)
{
obj.transform.position -= (obj.transform.position - new Vector3(0,0,0)).normalized* speed;
}
}
}
なぜなのか
このようなコード、すべてのクローンしたオブジェクトを中心に集めるコードですが、かなり重たく、20FPSぐらいが出ています。
これらを最適化しましょう。まずは重い処理を見つけます。
Unityのプロファイラーを見てみます。

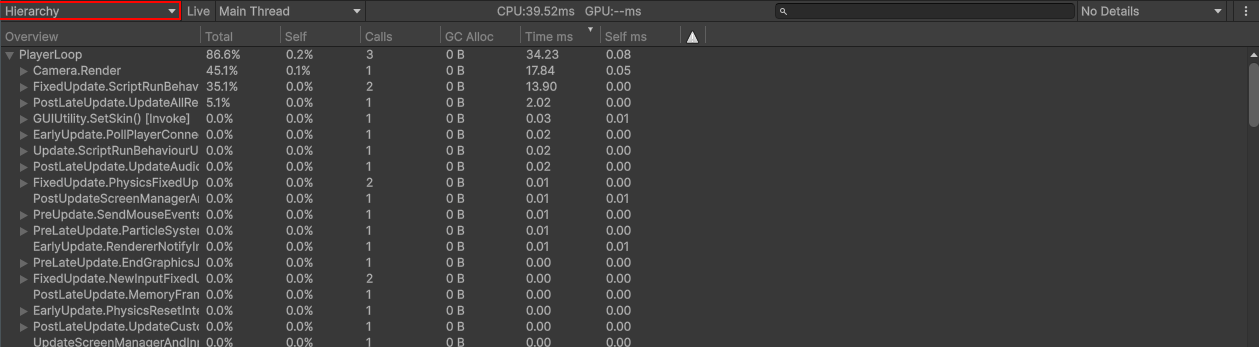
下の表示をタイムラインからヒエラルキーにすると、レンダーがかなりの処理をしていることがわかります。レンダラーで17msですので、60フレームにかかる時間は1020msです。
そして、スクリプトの14msも併せたら60フレームにかかる時間は1860msです。そのため、30FPSぐらいしか出せていないことがわかります。
デバッグ
自分はVulkanユーザーなのでRenderDocを使用します。
インストール後、UnityのGame部分を右クリックし、Load RenderDocを押せば使えるようになります。

カメラボタンを押せばrenderdocが起動します。
自分の場合ちゃんとvulkanになっています。

Capture Frame(s) Immediatelyを押せばフレームをキャプチャしてくれます。

コマンドを確認することができました。
キャプチャを確認

こちらを詳しく見ていくと...
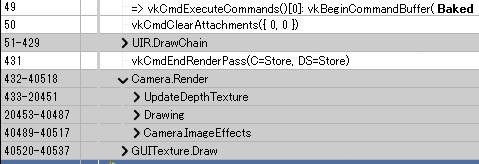
DepthとDrawの処理がとても重たいのがわかります。

vkCmdDrawIndexedが大量に呼ばれているのがわかりますね。
修正
これを解決するのですが、vulkanやってる方ならわかると思いますが、明らかにIndirectDrawの出番です。
ではやってみましょう。
Unityには不思議なGPUInstancingという機能があります。

DrawSRPBatcherという不思議なコールを使用します。
どうやら、CPUの大量のデータからGPU側にデータを渡し高速化するもののようです。
しかし、
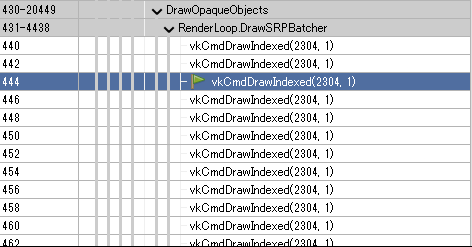
大量のコマンドをいまだに実行しているのでまだ微妙ですね。
Graphics.DrawMeshInstancedIndirect
というものが使用できそうです。
引数付きバッファ bufferWithArgs は、指定された argsOffset オフセットに5つの整数値(インスタンスあたりのインデックス数、インスタンス数、開始インデックス位置、ベース頂点位置、開始インスタンス位置)を持つ必要があります。
とdocsに書いてあります。そのため、
・index count per instance
・instance count
・start index location
・base vertex location
・start instance location
とできます。
そしてここのargsBufferはおそらくGPU側でのメモリが必要なのでComputeBufferを使用します。
argsBuffer = new ComputeBuffer(1, args.Length * sizeof(uint), ComputeBufferType.IndirectArguments);
argsBuffer.SetData(args);
のようにします。
public Mesh mesh;
private uint[] args = new uint[5];
args[0] = (uint)mesh.GetIndexCount(0);
args[1] = (uint)1000;
args[2] = (uint)mesh.GetIndexStart(0);
args[3] = (uint)mesh.GetBaseVertex(0);
args[4] = 0;
と書くことができます。
そして、位置情報を与えたいので
private ComputeBuffer positionBuffer;
private List<Matrix4x4> instanceTransforms = new List<Matrix4x4>();
foreach (GameObject obj in gameobjects)
{
instanceTransforms.Clear();
obj.transform.position -= (obj.transform.position - new Vector3(0, 0, 0)).normalized * speed;
instanceTransforms.Add(Matrix4x4.TRS(obj.transform.position, Quaternion.identity, new Vector3(1,1,1)));
}
positionBuffer = new ComputeBuffer(1000, 16 * sizeof(float));
positionBuffer.SetData(instanceTransforms.ToArray());
と書き、bufferを設定します。
それでマテリアルに設定しシェダーに送ります。
material.SetBuffer("_InstanceTransforms", positionBuffer);
そしたら、
Graphics.DrawMeshInstancedIndirect(mesh, 0, material, new Bounds(Vector3.zero, new Vector3(200, 200, 200)), argsBuffer);
最終的に描画処理を書きます。
シェダー
先にこちらを読んでください。
次に、シェダーを作ります。
Shader "Custom/IndirectShader"
{
Properties
{
_BaseColor ("Base Color", Color) = (1,1,1,1)
}
SubShader
{
Tags { "RenderType"="Opaque" "RenderPipeline"="UniversalPipeline" }
Pass
{
HLSLPROGRAM
ENDHLSL
}
}
}
これを基本として、
#pragma prefer_hlslcc gles
#pragma exclude_renderers d3d11_9x
#pragma multi_compile _ DOTS_INSTANCING_ON
#pragma vertex vert
#pragma fragment frag
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Lighting.hlsl"
を書きましょう。
StructuredBuffer<float4x4> _InstanceTransforms;
と書き、受け取るバッファーを定義します。
struct Attributes
{
float4 positionOS : POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct Varyings
{
float4 positionCS : SV_POSITION;
UNITY_VERTEX_OUTPUT_STEREO
};
先ほどのGPUInstancingですが、インスタンシングIDと言うものが必要であり、UNITY_VERTEX_INPUT_INSTANCE_IDというものも必要のようです。
GPUInstancingのCBUFFERというものがあり、GPU側のバッファーに移動させることができるようです。
UnityPerMaterialと言うものを使用すれば、シェダーと互換性が保たれるらしいです。
そのため
CBUFFER_START(UnityPerMaterial)
float4 _BaseColor;
CBUFFER_END
のように書きCBUFFER_STARTの中にPropertiesの値を書けばSRPと互換が保たれます。
Varyings vert (Attributes input,uint instanceID :SV_InstanceID)
{
Varyings output;
UNITY_SETUP_INSTANCE_ID(input);
UNITY_TRANSFER_INSTANCE_ID(input,output);
float4x4 instanceTransform = _InstanceTransforms[instanceID];
output.positionCS = TransformObjectToHClip(mul(instanceTransform, float4(input.positionOS.xyz, 1.0)).xyz);
return output;
}
これで、頂点を決定します。instanceIDは、そのままインスタンスの番号ですね。
half4 frag (Varyings input) : SV_Target
{
return _BaseColor;
}
あとはシンプルにUnlit
そして、

マテリアルのEnable GPU Instacingをオンにします。

vkCmdDrawIndexedIndirectが実行されているのがわかります。
しかし、まだ重たいです。
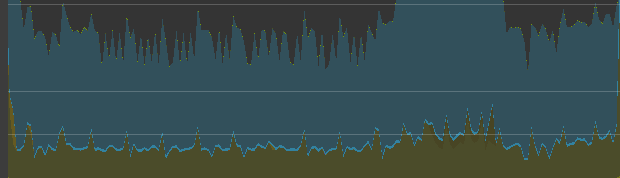
先ほどのレンダリングの処理は少なくなっていますが、圧倒的にスクリプトが重たいです。
そのため、
private void FixedUpdate()
{
int i = 0;
foreach (GameObject obj in gameobjects)
{
obj.transform.position -= (obj.transform.position - new Vector3(0, 0, 0)).normalized * speed;
instanceTransforms.Add(Matrix4x4.TRS(obj.transform.position, Quaternion.identity, new Vector3(1,1,1)));
}
}
この処理をGPUにやらせます。
instanceTransforms.Clear();
foreach (GameObject obj in gameobjects)
{
instanceTransforms.Add(Matrix4x4.TRS(obj.transform.position, Quaternion.identity, new Vector3(1, 1, 1)));
}
positionBuffer = new ComputeBuffer(count, 16 * sizeof(float));
positionBuffer.SetData(instanceTransforms.ToArray());
material.SetBuffer("_InstanceTransforms", positionBuffer);
このコードをStartにもっていきます。
そしたらこちらを
obj.transform.position -= (obj.transform.position - new Vector3(0, 0, 0)).normalized * speed;
シェダーの方で書きます。
output.positionCS = TransformObjectToHClip(mul(instanceTransform, float4(input.positionOS.xyz, 1.0)).xyz);
ここで、instanceTransformとfloat4(input.positionOS.xyz, 1.0)を補完しようとすると、ややこしいことになります。
hlslのlerpは、float4x4には対応しません。なので、float4x4のそれぞれのcolumを補完しないといけません。
そのため、ここでは、instanceTransformに小数点をかければ、補完と似たような動作ができるのを使います。
バッファーにdistanceを用意します。
StructuredBuffer<float> _distance;
output.positionCS = TransformObjectToHClip(mul(instanceTransform*_distance[0], float4(input.positionOS.xyz, 1.0)).xyz);
private ComputeBuffer distance;
float distance_v;
distance = new ComputeBuffer(1, sizeof(float), ComputeBufferType.IndirectArguments);
distance.SetData(new float[] { distance_v });
material.SetBuffer("_distance", distance);
distance_v -= 0.001f;
そしたら、驚き、120FPS出るようになりました。
100000個に変更しても40FPS出るので速度が倍になった感じですね。
ということで、パフォーマンスを低レイヤーで修正する例でした
Discussion