Mastodonの文字数測定は何を使っているか
Rails側
def countable_length(str)
str.mb_chars.grapheme_length
end
grapheme_lengthを使っている
grapheme_length
Returns the number of grapheme clusters in the string.
https://api.rubyonrails.org/v6.0.2.2/classes/ActiveSupport/Multibyte/Chars.html#method-i-grapheme_length
'क्षि'.mb_chars.length # => 4
'क्षि'.mb_chars.grapheme_length # => 3
というわけで書記素クラスタを考慮した感じでやっているらしい
Web側
stringz というライブラリを使っている
stringz
Javascript has a serious problem with unicode. Even ES6 can’t solve the problem entirely since some characters like the new colored emojis are three bytes instead of two bytes. Sometimes even more! "👍🏽".length returns 4 which is totally wrong (hint: it should be 1!). ES6's Array.from tried to solve this, but that even fails: Array.from("👍🏽") returns ["👍", "🏽"] which is incorrect. This library tries to tackle all these problems with a mega RegExp.
https://www.npmjs.com/package/stringz
[..."string"]でうまくバラせないやつもバラせるやつらしい
mega RegExp と書いてあるが、stringzが正規表現を持ってるわけではなく、char-regex を使っている。
つまり、stringzはそのラッパーである。
最近のJS環境なら組み込みのIntl.Segmenterで書記素クラスタを考慮した感じでバラすことができる
このように:
function getLengthWithIntlSegmenter(str) {
const segmenter = new Intl.Segmenter('en', { granularity: 'grapheme' });
let count = 0;
for (const segment of segmenter.segment(str)) {
count++;
}
return count;
}
しかしstringzのベンチマークに組み込んでみたところめちゃくちゃ遅かった
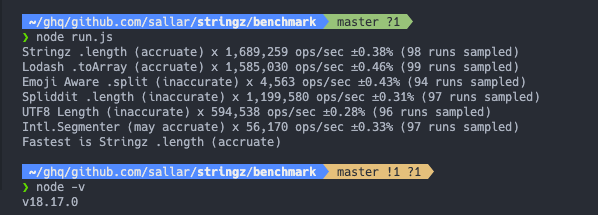
ネイティブだから早いというものでもないらしい
余談だが、sindresorhus[1]による同様のことをするstring-lengthというライブラリは5.xではchar-regexを使っていて、6.xではIntl.Segmenterを使うように書き換えられた。
-
https://github.com/sindresorhus node関係でたくさんライブラリを作ってて、それらがたくさんダウンロードされてるすごい人 ↩︎