TypeScriptで学ぶ代数的データ型
代数的データ型とはなにか
代数的データ型とは、要素の個数の足し算と掛け算のアナロジーで語ることができる型のことを指すというふわっとしたコンセンサスがありますが、
厳密に「これが代数的データ型である」という定義はおそらくありません[1]。
また、代数的データ型はいわゆる関数型言語で実装されることが多い言語機能であり、
代数的データ型を重用するプログラミングスタイルは関数型の一派としてみなされる傾向がある[2]と思っています。
本記事では数学的な説明やアナロジーは用いず、なるべく具体的なコードを提示します。
そして、代数的データ型という言葉を「かつ」と「または」を表すことができる型として使います。
更に、「または」の型はコンパイラによって漏れなく徹底的にチェックされる必要があります。
詳細は後ほど説明します。
本記事の構成
まず、本記事における「代数的データ型」とはなにかを説明し、それをコードで表す方法を説明します。
次に、「代数的データ型」を実用する際に本記事が採用するコード化の手法を説明します。
最後に、「代数的データ型」の実用例を挙げます。
代数的データ型とそのエンコード
代数的データ型について説明する前に、「かつ」の型と「または」の型について説明します。
この用語は広く知られているものではなく、本記事で便宜上名前をつけたものです。
また、これらの型をコードで表現する方法についても併記します。
「かつ」の型
「かつ」を表す型は単純にオブジェクトの型で表すことができます。
ユーザーIDとユーザー名を持つデータを考えます。
const user = {
id: 1,
name: "Alice",
}
言い換えると、ユーザーは「IDを持つ」かつ「名前を持つ」と言えます。
TypeScriptでは先ほどのオブジェクトuserの型を次のように表すことができます。
type User = typeof user;
型Userは本記事で言うところの「かつ」を表す型です。
「かつ」の型のエンコード
先ほどはオブジェクト値から型を生成しました。
今回は最初に型を定義してからその値を生成してみましょう。
type User = {
id: number;
name: string;
};
const user: User = {
id: 1,
name: "Alice",
};
やっていることは先ほどと同じですが、先に型を定義しているのが異なります。
クラスを使っても同じことができます。
class User {
constructor(public id: number, public name: string) {}
}
const user = new User(1, "Alice");
このように、従来のプログラミング言語で「かつ」の型というのは日常的に使用されてきた型と言えます。
そして、日常的に使用している型とも言えます。
複雑な「かつ」の型
「かつ」の型では3つ以上のプロパティを組み合わせることができます。
また、既に定義した型を組み合わせることもできます。
ブログの記事は「記事IDを持つ」かつ「著者を持つ」かつ「タイトルを持つ」かつ……
というように、かつで表すことができます。
type Article = {
id: number;
author: User; // Userは定義済みとします
title: string;
body: string;
liked: number;
};
「または」の型
ユーザーは次の2種類に分類できるとします。
- ユーザー登録をしている会員
Member - ユーザー登録をせずに利用するゲストユーザー
Guest
言い換えると、ユーザーは「会員である」または「ゲストである」と言えます。
会員とユーザーのそれぞれの型は「かつ」の型として表されるとします。
- 会員はID、ユーザー名、メールアドレスを持つ
- ゲストユーザーはユーザー名のみを持つ
代数的データ型以外のアプローチ
「かつ」のエンコードによる代用
「または」の型は、先ほどの「かつ」のエンコードで代用することができます。
type User = {
id: number;
name: string;
mail: string;
}
例えば次のように使います。
const member: User = {
id: 1,
name: "Alice",
mail: "alice@mail.com"
}
問題はゲストユーザーを扱うときです。
const guest: User = {
id: -1, // ゲストユーザーにはIDが付与されない
name: "Bob",
mail: "", // ゲストユーザーはメールアドレス登録を行っていない
};
上記のように、使わないプロパティに対してダミーの値を与える必要があります。
インターフェースによるエンコード
会員とゲストの両方にユーザー名があることに着目してインターフェースにまとめます。
※あるいは要件によっては契約を空にしてマーカーインターフェースとして使うかもしれませんが……
interface IUser {
name: string;
}
このインターフェースを実装するクラスをそれぞれ作成します。
class Member implements IUser {
constructor(public id: number, public name: string, public mail: string) {}
}
class Guest implements IUser {
constructor(public name: string) {}
}
これにより、先ほどのゲストユーザーの例の問題が解決し、不使用となるプロパティを無くすことができます。
const member: IUser = new Member(1, "Alice", "alice@mail.com");
const guest: IUser = new Guest("Bob"); // 名前のみで作成できるようになった
データを作成する場合の問題は解決しました。
次は、データを使用する場合です。
インターフェースからは名前の情報しか読み取れないため、
例えばメールアドレスが必要な場合はキャストする必要があります。
function showMessage(user: IUser): string {
// このスコープではuser.nameしか利用できない
if (user instanceof Member) {
// ここでuser: Memberが確定するのでメールアドレスが利用できる
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
} else if (user instanceof Guest) {
// このスコープではuser: Guestが確定する
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
return "";
}
インターフェースは「開」であるので、コードの至るところで自由に追加できます。
class ThirdUser implements IUser { /* ... */ }
したがって、そのインターフェースを実装しているクラスに対してすべての処理を網羅できていることの保証は得られません。
この保証を得るためには、showMessageという関数をインターフェースの契約に含める必要があります。
interface IUser {
name: string;
showMessage(): string
}
先ほどのshowMessage関数の実装はそれぞれのクラスに移されます。
class Member implements IUser {
constructor(public id: number, public name: string, public mail: string) {}
showMessage() {
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
}
}
class Guest implements IUser {
constructor(public name: string) {}
showMessage() {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
}
これで保守性の問題は無くなりましたが、IUserが
- ユーザー情報(IDや名前)を保持する
- そのユーザーに対する振る舞い(どのようなメッセージを表示するか)を記述する
という2つの責務を負ってしまうことになります。
(IUserがメッセージに関するメソッドやプロパティを持つという契約に違和感はありませんか?)
クラスとユニオンによるエンコード
先ほどは先にインターフェースを定義してからその実装となるクラスを定義しました。
今度はその逆を行います。
つまり、先に個別のクラスを定義して、ユニオンで連結することで「または」の型を表現します。
class Member {
constructor(public id: number, public name: string, public mail: string) {}
}
class Guest {
constructor(public name: string) {}
}
type User = Member | Guest
これを使ってshowMessage関数も同様に実装します。
function showMessage(user: User): string {
if (user instanceof Member) {
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
} else if (user instanceof Guest) {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
return ""
}
インターフェースによる実装との大きな違いはこれが開ではなく「閉」であるという点です。
インターフェースによる実装では、第3のユーザーの型を追加する際、インターフェースIUserの定義を変更する必要はありませんでした。
ユニオンによる実装では、型Userに第3のユーザーの型を追加する場合、その型の定義を直接変更する必要があります。
class ThirdUser { /* ... */ }
type User = Member | Guest | ThirdUser
これは必ずしも欠点ではなく、裏を返すとユニオンによる実装では型Userとしてあり得るものを全て列挙できるので、
場合分けに漏れが出ないようにコンパイラに検査させることができます。
ここでTypeScriptの型システムを利用するため、never型を使います。
これにより、場合分けで考慮すべき事項がすべて網羅されているかどうかをコンパイラに検査させることができます。
type User = Member | Guest
function showMessage(user: User): string {
if (user instanceof Member) {
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
} else if (user instanceof Guest) {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
const _exhaustiveCheck: never = user
return ""
}
userに対する2つの場合分けをすり抜けるようなuserは存在しないので、
if文の後のuserはTypeScriptコンパイラによりnever型として認識されます。
never型の変数への代入が行われていますが、これはコンパイルされます。
もし、Userに第3のユーザーの型が追加された場合はif文の後でもuserがnever型とは認識されないため、
never型の変数への代入がコンパイルエラーとなります。
type User = Member | Guest | ThirdUser
function showMessage(user: User): string {
if (user instanceof Member) {
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
} else if (user instanceof Guest) {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
const _exhaustiveCheck: never = user
return ""
}
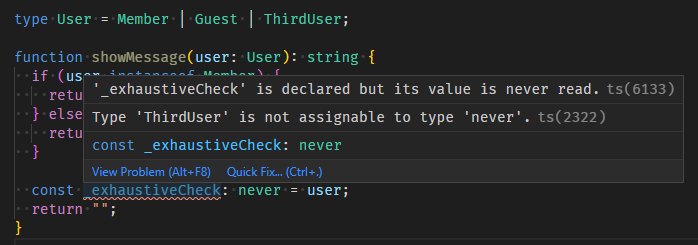
never型によるExhaustive Check
エラーメッセージの読み方ですが、下図の赤枠で囲んだところに漏れている場合が表示されています。
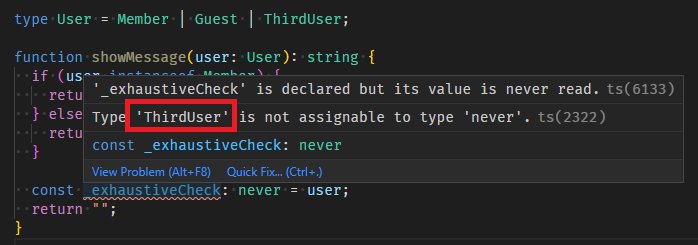
場合分け漏れ
このコンパイルエラーは場合分けを網羅することで解消できます。
type User = Member | Guest | ThirdUser;
function showMessage(user: User): string {
if (user instanceof Member) {
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
} else if (user instanceof Guest) {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
} else if (user instanceof ThirdUser) {
return `こんにちは3番目のユーザーさん。`;
}
const _exhaustiveCheck: never = user;
return "";
}
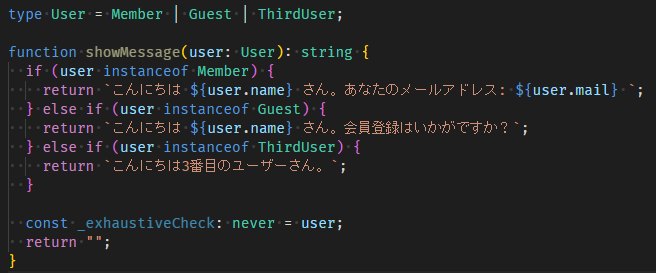
Exhaustive Checkのエラー解消
これにより、安全に機能追加を行うことができ、その影響範囲もコンパイラによって通知されます。
以下のようなヘルパー関数を用意しておくと便利かもしれません。
function exhaustiveCheck(bottom: never): never {
throw new Error("Exhaustive check failed.");
}
これは次のように使います。
type User = Member | Guest | ThirdUser;
function showMessage(user: User): string {
if (user instanceof Member) {
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
} else if (user instanceof Guest) {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
} else if (user instanceof ThirdUser) {
return `こんにちは3番目のユーザーさん。`;
}
exhaustiveCheck(user); // userの場合分け漏れをコンパイラにチェックさせる
}
コンパイルが通ればexhaustiveCheckが実行されることはありません。
タグ付きオブジェクトのユニオンによるエンコード
先ほどの例ではクラスを使いましたが、データを格納するという単一の責務を果たすだけであれば通常のオブジェクトで十分です。
ただし、ユーザーの種別を判別できる必要がありますので、プロパティを1つ足します。
このプロパティ名は何でも良いのですが、ここではtypeとします。
また、このような目的で追加されるプロパティはタグと呼ばれることがあります。
type Member = {
type: "Member";
id: number;
name: string;
mail: string;
};
type Guest = {
type: "Guest";
name: string;
};
type User = Member | Guest
ここで文字列のリテラル型を使用している点に注意してください。
型stringの値"Member"と、型"Member"は異なります。
前者は実行時にのみ存在する値なのでTypeScriptコンパイラはその値"Member"を知ることはできません。
後者はコンパイル時にのみ存在する情報なのでTypeScriptコンパイラは知ることができます。逆に、実行時に使用することはできません。
タグ付きオブジェクトを生成する方法は、通常のオブジェクトと同じです。
const alice: Member = {
type: "Member",
id: 1,
name: "Alice",
mail: "alice@mail.com",
};
IDEを使っていれば補完が効くため、リテラル型の恩恵を受けることができます。

リテラル型の補完
また、タイプミスがあった場合にはコンパイルエラーとして通知されるため、
謎の実行時エラーに頭を悩ませることもなくなります。
下図の例はタイプミスとして代表的な大文字と小文字の間違いです。

リテラル型とタイプミス
それでは、関数showMessageを再度実装します。
クラスではないのでinstanceof演算子を使用することはできません。
その代わりに新しく増やしたプロパティtypeを使います。
function showMessage(user: User): string {
if (user.type === "Member") {
// この時点でuser: Memberが確定するのでメールアドレスを利用できる
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
} else if (user.type === "Guest") {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
exhaustiveCheck(user);
}
不思議なことに、ここでもTypeScriptコンパイラはすべての場合を網羅していることを認識できるため、
exhaustiveCheckが機能します。
ここで、第3のユーザー型を追加してみましょう。
type ThirdUser = {
type: "ThirdUser";
/* ... */
}
type User = Member | Guest | ThirdUser;
すると、showMessage中のexhaustiveCheckが作動します。

タグ付きオブジェクトの場合分け漏れ
クラスによる実装とタグ付きオブジェクトによる実装を比べると、
後者はタグがオブジェクトの中に埋め込まれているため、シリアル化したときに
それが何の種別であったのかがすぐに分かるというメリットがあります。
ただし、本来一意であるべきのタグ名を重複させてしまってもコンパイルエラーとはならないという点に注意が必要です。
type User =
| { type: "Member"; id: number; name: string; mail: string }
| { type: "Guest"; name: string }
| { type: "Member" }; // タグ衝突
この欠点は次の章で解消します。
代数的データ型の実践的エンコード
ここまでで「かつ」の型と「または」の型に関する説明と、それをどのようにコード化するかを説明してきました。
また、「または」の型に対するexhaustiveCheckについても説明しました。
本記事における代数的データ型とは、「かつ」の型およびexhaustiveCheckを行うことができる「または」の型を
組み合わせて表現できる型のことを言うこととします。
本記事において、代数的データ型のエンコード方法は単純にオブジェクトを使用するものを採用します。つまり、
- 「かつ」の型はクラスではなくオブジェクトを使って表す
- 「または」の型は
typeというタグを付けたオブジェクトのユニオンを使って表す
という表現方法を採用します。
ここまでで議論してきたUser型をもう一度掲載します。
タグ付きオブジェクトのユニオンとして「または」の型を表現するとき、型の定義とタグの定義が重複しますので、
個別の型の定義は省略してタグのみとします。
type User =
| { type: "Member"; id: number; name: string; mail: string }
| { type: "Guest"; name: string };
ご覧の通り、「かつ」の型で作られたタグ付きオブジェクトの型を、「または」の型でまとめてUser型が作られています。
showMessage関数の実装に変更はありません。
function showMessage(user: User): string {
if (user.type === "Member") {
// この時点でuser: { type: "Member"; id: number; name: string; mail: string }
// が確定するのでメールアドレスを利用できる
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
} else if (user.type === "Guest") {
// このスコープではuser: { type: "Guest"; name: string }
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
exhaustiveCheck(user);
}
あるいはswitch文を使用することでuser.typeの重複を抑えることができます。
※個々のcase文に中括弧{ }は必ずしも必要というわけではありませんが、スコープを分けるために記載することを推奨します。
function showMessage(user: User): string {
switch (user.type) {
case "Member": {
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail}`;
}
case "Guest": {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
}
exhaustiveCheck(user);
}
第3のユーザー型を追加すると、exhaustiveCheckが作動します。
type User =
| { type: "Member"; id: number; name: string; mail: string }
| { type: "Guest"; name: string }
| { type: "ThirdUser"; /* ... */ };
レコードから「または」の型を生成する
「または」の型の有用性とそのシンプルさはここまで見てきた通りですが、
型の定義自体がどうしても冗長になってしまいます。
そこで、もっとシンプルに「または」の型を表現できるようにしてみましょう。
そこで以下の型Coproduct<T>を定義します。
type Coproduct<
T extends Record<keyof any, {}>> = {
[K in keyof T]: Record<"type", K> & T[K];
}[keyof T];
複雑な型定義は無視してしまって構いません。使い方を見ていきます。
使い方はCoproduct<T>のTの部分に、「または」の定義となるオブジェクトの型を書くだけです。
コロン:の左側はタグ名、コロン:の右側はタグ以外の型をオブジェクトの型として記載します。
type User = Coproduct<{
Member: { id: number; name: string; mail: string };
Guest: { name: string };
}>;
不思議なことに、上記のUserの定義と先ほど再掲したタグ付きオブジェクトのユニオンによるUserの定義は同じものになります。
つまり以下のコードがそのまま成立します。
type User = Coproduct<{
Member: { id: number; name: string; mail: string };
Guest: { name: string };
}>;
function showMessage(user: User): string {
switch (user.type) {
case "Member": {
return `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
}
case "Guest": {
return `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
}
exhaustiveCheck(user);
}
また、タグをレコードを用いて記載しているため、次のようなタグ名が重複するような定義はコンパイルエラーとすることができます。
type User = Coproduct<{
Member: { id: number; name: string; mail: string };
Guest: { name: string };
Member: {}; // Memberの定義が重複するのでコンパイルエラー
}>;
タグ付きオブジェクトのユニオンから個別の型を取得する
時には個別の型が必要になることもあるでしょう。
例えば、タグ"Member"であるUser値を生成してみます。
const alice: { type: "Member"; id: number; name: string; mail: string } = {
type: "Member",
id: 1,
name: "Alice",
mail: "alice@mail.com",
};
毎回この長々しい型定義を書くのは現実的ではありません。
User型として宣言することで妥協できるのであればそれでも良いでしょう。
const alice: User = {
type: "Member",
id: 1,
name: "Alice",
mail: "alice@mail.com",
};
しかし、もし妥協できないのであれば次の方法を使います。
まず、Individual<TCoproduct, Tag>を定義します。
type Individual<
TCoproduct extends Record<"type", keyof any>,
Tag extends TCoproduct["type"],
> = Extract<TCoproduct, Record<"type", Tag>>;
これにより、次のように使うことができます。
const alice: Individual<User ,"Member"> = {
type: "Member",
id: 1,
name: "Alice",
mail: "alice@mail.com",
};
もし頻繁に使うようであれば、Coproduct<T>を使う際に一緒に定義してしまうのがおすすめです。
type User = Coproduct<{
Member: { id: number; name: string; mail: string };
Guest: { name: string };
}>;
type Member = Individual<User, "Member">; // { type: "Member"; id: number; name: string; mail: string }
type Guest = Individual<User, "Guest">; // { type: "Guest"; name: string }
これにより、次のように簡潔に記述できます。
const alice: Member = {
type: "Member",
id: 1,
name: "Alice",
mail: "alice@mail.com",
};
暗黙のexhaustiveCheckと式化
TypeScriptにおいてif文もswitch文もどちらも「文」です。
したがって、その分岐の結果を変数に代入したい場合、
まずはif文やswitch文と同じスコープでletにより変数を宣言し、
if文やswitch文の中でその変数に値を代入する必要があります。
// const user: User = /* ... */
// 事前にletで宣言する必要がある
let message: string;
switch (user.type) {
case "Member": {
message = `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
}
case "Guest": {
message = `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
}
alert(message);
これの欠点は、letで変数を宣言したことにより、再代入を許してしまう点にあります。
// const user: User = /* ... */
let message: string;
switch (user.type) {
case "Member": {
message = `こんにちは ${user.name} さん。あなたのメールアドレス: ${user.mail} `;
}
case "Guest": {
message = `こんにちは ${user.name} さん。会員登録はいかがですか?`;
}
}
message = "evil message"; // 😈
alert(message);
また、exhaustiveCheckを使うこともできません。
これらの欠点を解消するためにmatch関数を定義します。
これも型や実装が複雑ですが、一度定義してしまえば実装の詳細は気にする必要はありません。
function match<TCoproduct extends Record<"type", keyof any>>(
value: TCoproduct,
) {
return function <TOut>(
patterns: {
[K in TCoproduct["type"]]: (
param: Omit<Individual<TCoproduct, K>, "type">,
) => TOut;
},
): TOut {
const tag: TCoproduct["type"] = value.type;
return patterns[tag](value as any);
};
}
これにより、先ほどの2つの欠点が解消できます。
具体的には、返り値をconstで受けることができ、
明示的にexhaustiveCheckを記述しなくても場合分け漏れをチェックさせることができます。
// const user: User = /* ... */
const message: string = match(user, {
Member: (member) =>
`こんにちは ${member.name} さん。あなたのメールアドレス: ${member.mail} `,
Guest: (guest) =>
`こんにちは ${guest.name} さん。会員登録はいかがですか?`,
});
ここで第3のユーザー型を追加してみます。
type User = Coproduct<{
Member: { id: number; name: string; mail: string };
Guest: { name: string };
ThirdUser: { /* ... */ };
}>;
場合分け漏れによりコンパイルエラーとなります。

暗黙のexhaustiveCheck
また、漏れはIDEによる補完で確認することができます。

パターンマッチングの補完
場合分けを網羅することでコンパイルエラーが解消されます。
const message: string = match(user, {
Member: (member) =>
`こんにちは ${member.name} さん。あなたのメールアドレス: ${member.mail}`,
Guest: (guest) =>
`こんにちは ${guest.name} さん。会員登録はいかがですか?`,
ThirdUser: (thirdUser) =>
`こんにちは。`,
});
代数的データ型の実用例
RemoteData
HTTP経由でデータを取得する際、データの取得中かどうかを表すloading、
取得したデータdata、あるいは取得に失敗した場合はその失敗理由を表すerrの3つのプロパティを考える必要があります。
これは従来のプログラミングでは「かつ」のエンコードによる代用が用いられてきました。
type HttpResult<TErr, TData> = {
loading: boolean;
err: TErr | null;
data: TData | null;
};
※nullの代わりにundefinedを用いるかもしれませんが話の本筋は変わりません。
この手法の欠点は、「かつ」のエンコードによる代用の節の繰り返しになりますが、
データを正しくモデリングできていないことにあります。
例えば、読み込み中の状態は次のようなデータで表します。
{
loading: true,
err: null,
data: null,
}
errやdataは不必要なので、ダミーの値としてnullを代入します。
読み込みに成功した場合は次のようなデータで表します。
{
loading: false,
err: null,
data: { /* ... */ },
}
これも、errは不必要なのでダミーの値としてnullを代入します。
HttpResult型の値が与えられたとき、通信に成功したかどうかを知るには
loadingの値とdataがnullかどうかの2つを調べないといけません。
これを代数的データ型でモデリングすることで解消しましょう。
How Elm Slays a UI Antipatternという記事で解説されている通り、
RemoteDataを使ってデータをモデリングします。
type RemoteData<TErr, TData> = Coproduct<{
NotAsked: {};
Loading: {};
Failure: { err: TErr };
Success: { data: TData };
}>;
これにより、RemoteData型の値が与えられたとき、通信に成功した場合は
単にタグSuccessの場合となります。
また、match関数を使うことにより、暗黙のexhaustiveCheckが走るため、
エラーハンドリング漏れなどを防ぐことができます。
古典的ADTの実装(Maybe, Either)
一応、MaybeやEitherなどを定義することもできます。
周辺の関数は自作する必要があるので実用に耐えられるかは疑問が残るところですが……
type Maybe<T> = Coproduct<{
Just: { value: T };
Nothing: {};
}>;
// pure
function Just<T>(value: T): Maybe<T> {
return {
type: "Just",
value,
};
}
const Nothing: Maybe<never> = { type: "Nothing" };
// とりあえずbindだけ実装
function bind<T, U>(mt: Maybe<T>, f: (t: T) => Maybe<U>): Maybe<U> {
return match(mt, {
Just: ({ value }) => f(value),
Nothing: (_) => Nothing,
});
}
function parseIntM(s: string): Maybe<number> {
const parsed = window.parseInt(s, 10);
return Number.isInteger(parsed) ? Just(parsed) : Nothing;
}
// Do記法 または パイプ演算子 の無い言語ではほぼ無謀
const ma = parseIntM("1");
const mb = parseIntM("2");
const mc = parseIntM("3");
const tripleSum =
bind(ma, (a) =>
bind(mb, (b) =>
bind(mc, (c) =>
Just(a + b + c)))
);
Reducer
React Hooks APIでThe Elm Architectureで解説している通り、
拙作のuse-teaライブラリを使うとき、Msgの定義がまさに代数的データ型です。
まず、アプリケーションの状態を表すモデルがあります。
type LoginFormModel = {
username: string;
password: string;
remember: boolean;
};
このモデルに対して変更を加えることができるアクションを列挙した型LoginFormMsgを定義します。
各アクションはまたはで繋ぐため、Coproduct<T>を使います。
type LoginFormMsg = Coproduct<{
SetUsername: { username: string };
SetPassword: { password: string };
SetRemember: { remember: boolean };
}>;
繰り返しになりますが、上記の定義は次の定義と同値です。
type LoginFormMsg =
| { type: "SetUsername"; username: string }
| { type: "SetPassword"; password: string }
| { type: "SetRemember"; remember: boolean };
現在の状態と、そのモデルに対して作用するアクションの2つから次の状態を計算します。
これはmatch関数を用いて簡潔に書くことができます。
const loginFormReducer = (
msg: LoginFormMsg,
model: LoginFormModel,
): LoginFormModel =>
match(msg, {
SetUsername: ({ username }) => ({ ...model, username }),
SetPassword: ({ password }) => ({ ...model, password }),
SetRemember: ({ remember }) => ({ ...model, remember }),
});
まとめ
TypeScriptで「代数的データ型」をコード化する手法と、その実用例を幾つか挙げてみました。
もし本記事が参考になりましたら、いいねあるいはコメントよろしくお願いします。
-
WikipediaのADTの記事を読む限り、
ProductとCoproductの複合で表される型のことを言うと思われます。 ↩︎ -
関数型プログラミングという言葉が広い意味で使われているという現状があると思います。
個人的にはカリー化や部分適用などの言語機能を備えていれば関数型言語と言って良いと考えています。
純粋関数うんぬんやモナディックプログラミングはまた別の話でしょう。
私は代数的データ型・パターンマッチングのファンではありますが、その他の関数型パラダイムのファンではありません。 ↩︎
Discussion
こちらについてコンパイルが通らないので
こちらが正しいのかなと思いました。
訂正ありがとうございます!
カリー化するかどうかで試行錯誤していたときのものが混ざってしまっていたようです。
「暗黙のexhaustivecheckと式化」についてmatch関数を実装するのはパターンマッチング好きとしてはとても良いと思うのですが、シンプルに考えれば、即時関数実行式で同じことが可能です
をこのように表せますし、exhautiveCheckも効きます