はじめに
TROCCO は 2018 年にローンチしてから成長を続け、2024年には1日20万個のデータ転送ジョブを実行するプラットフォームに進化しています。
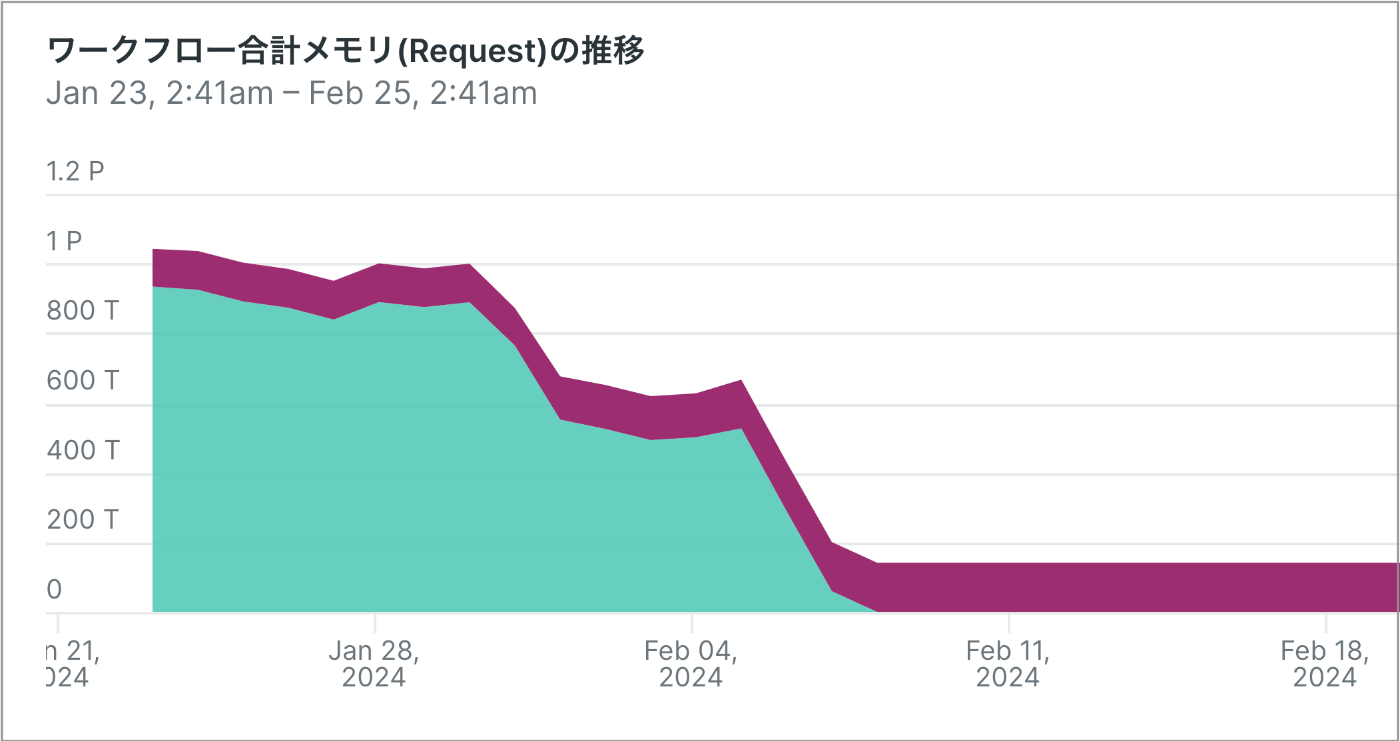
進化の歴史の中で、1000 GB 以上 のメモリ確保量を削減をした事例があります。
(※ 縦軸の値は集計期間が大きいためまとめられています)
移行後、1年近く安定して運用実績を残せたため
- アーキテクチャ移行の歴史を記録に残すこと
- 安全に移行するプロセスの知見共有
を目的として記事にしました。
前半はシステム個別の課題の話ですが、後半の移行の考え方は多くの人に役に立つものではないかと思います。
改善した機能(TROCCO のワークフロー)
TROCCO はデータ分析基盤の総合支援 SaaS です。具体的には、MySQL や Salesforce や Google Ads、Amazon S3 など様々なデータソースから、BigQuery や Snowflake のようなデータウェアハウスにデータを流し込む ETL/ELT 処理をマネージドに実現するサービスです。
TROCCO の機能の1つにワークフローがあります。CI/CD ツールのパイプラインのような処理を GUI 上で作れる機能で、ノードを組み合わせて、データ転送の前後関係、並列実行、ループ、ネストなどを実現できます。

内部のサーバアプリケーションは Airflow のようなワークフローエンジン OSS は使わずフルスクラッチで実装しており[1]、各ノードのデータ転送の進捗管理の役目をしています。
今回アーキテクチャ移行をしたのはこのワークフローの進捗管理プロセスです。
旧ワークフローの問題点
TROCCO ではメイン機能である転送ジョブ[2]を Kubernetes Job (on EKS) で動かしています。(以後 k8s job と表記します)
ワークフローの進捗管理プロセスは、初期段階では転送ジョブと同じアーキテクチャでリリースされました。つまり 1回のワークフロー実行で 1つの k8s job (進捗管理プロセス)を実行します。

しかし利用数が増えるに伴い、問題が顕在化してきました。
1. 無駄なリソース占有
- ワークフローの利用数が多くなれば、線形的にリソースが増えてしまう
- 転送エラーが発生した場合、リトライ待ち時間を設定できるが、リトライ待ちの間もリソースを占有し続けてしまう
2. EC2 障害時に再実行できない
- 転送時のエラーなど、アプリケーション内エラーはハンドリングしてリトライ可能だが、AWS の EC2 障害によって k8s job が突然死した際に (k8s job 自体にリトライ機能は存在するが)、プロセスの多さや status 管理の複雑さから再実行するにはリスクが高く、インフラ障害時は処理を再開できない仕様にしていた[3]
- 結果、運用対処をするしかなく、地味な運用負担になっていた
上記の問題が大きく膨れ上がってきたため、問題解決、つまりアーキテクチャ移行を決定しました。
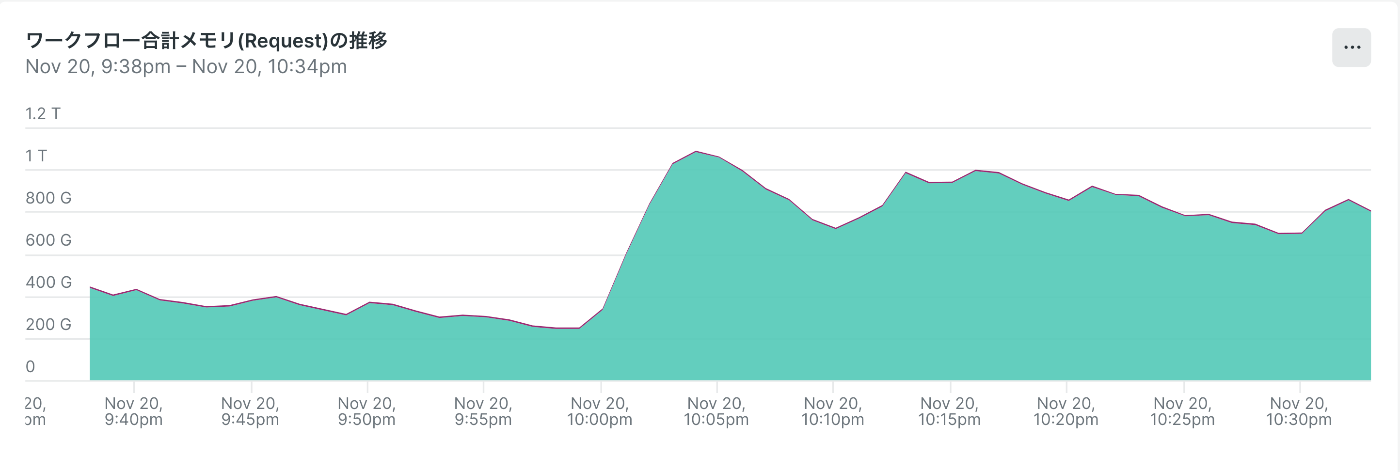
ワークフローのみで 1T 以上のメモリを使っている図。需要によっては 1.5T 程度まで増えることも
リソース占有 への対応
改善アーキテクチャ
旧アーキテクチャは1回のワークフロー実行で 1つの k8s job を実行する仕様だったため
改善アーキテクチャは進捗管理プロセスの Kubernetes Job を Deployment 化し、
複数のワークフローを1つのプロセスでまとめて管理できるようにしました。(以後 k8s deployment と表記します)

コンポーネントが 2つに分かれます。
- Manager
- 1つの pod で複数のワークフローの進捗管理行うコンポーネント
- ワークフロー起動時に、どの Manager で管理するかを決定する[4]
- Rebalancer
- Manager の数をスケールさせた場合や、Manager が応答不能と判断した場合に Manager が管理するワークフローの再割り当てを行うコンポーネント
- 他にも特殊な条件下では Manager が 1分以上処理を占有することがあり、長時間 1つのワークフローの進捗管理に時間を割くと、その Manager に割り当てた他のワークフローの進捗管理が始まらないため、再割り当てを行う
1つの Manager が複数のワークフローをまとめて進捗管理するため、リソース効率に大きな改善が見込めます。
移行方法の選定
安全な移行のために、カナリアリリース[5]が有力な候補にあがりました。
一般的なカナリアリリースでは全てのリクエストを対象に少しずつ移行割合を増やしていきますが、契約プランの入口である Free プランとそれ以外のプランでは、扱っているワークフローの規模が大きく違うため、なるべく小規模なワークフローから移行した方が安全という理由で、Free プランからカナリアリリースをすることを決めました。
具体的には
- Free プランの 1% を新アーキテクチャに移行する
- 順に移行割合を増やしていき、Free プランの 100% を新アーキテクチャに移行する
- Free プランが完了すれば、それ以外のプランの割合を順に移行していく
- Professional プラン(最も大規模なワークフローを扱うプラン) は、他プランの移行が完了し、安定したことを確認してから移行する
といった流れです。
カナリアリリースにおける課題
カナリアリリースを行う際に、リリース先のアーキテクチャが異なるため、本番環境で新旧アーキテクチャを共存させ、アーキテクチャ間でリリース割合を変更していく必要がありました。
アーキテクチャ共存のリスク
新旧アーキテクチャの共存は、共存させるための専用ロジックの実装が必要になります。この共存ロジックはリスクが高く
- おもわぬバグが発生するリスクが上がる[6]
- 既存処理に新たなバグが見つかった際に、原因特定の難易度が上がる
- 自動テストの複雑度が上がる
- デプロイなど運用オペレーションも複雑になる
と、一時的にシステムの複雑度が大きく跳ね上がる ことが見込まれました。
しかし
- 移行に伴うシステム全体のメンテナンスは可能であれば避けたい
- ワークフローは重要なシステムのため、安全な移行をしたい
- コードを全体的に把握しながら、実現可能と判断した
- (おまけ程度だが共存時にワークフローでバグ報告があった際は、全て担当の自分が見切るという意気込み)
という理由で、共存デメリットを受け入れ、カナリアリリースを進めることを決めました。
実際に行った手法
実際には、新旧アーキテクチャを並列に並べてのその前段でリクエストを振り分けたわけではありません。今回はワークフローのみの移行で、影響範囲を一部の Class 内で収められる見込みがあったため、以下の工夫をしました。
- 旧アーキテクチャ用のロジック (Dispatcher) と新アーキテクチャ用のロジック (Manager) を同じコンポーネント内で動くように実装
- Feature Flag のような切り替えの仕組みで、新旧アーキテクチャのどちらのロジックを利用するか選択可能にした
- アカウントごとにどちらロジックを利用するか判定
(例: 10%を移行した場合、10%のアカウントが新アーキテクチャのロジックを利用する) - リリース割合は管理画面から設定可能

新旧アーキテクチャ用のアプリケーションを完全に分離する案ももちろんありましたが、ワークフローの機能変更やバグ修正が発生した際に、分離したアプリケーション間で追従が必要になったり、デプロイ運用や開発コミュニケーションコストが高くなるため、分離する方がデメリットが大きいと判断し、上記の方法を採用しました。
リリース割合の変更
リリース割合変更は管理画面を実装し、デプロイに依存せず変更をできるようにしました。問題発生時にその場で速やかに戻せるというは大きな価値です。

管理画面で割合変更が可能 (画像は旧プラン名で、現在のプラン名とは異なります)
EC2 障害時 への対応
2つ目の問題点、EC2 障害時に再実行できない仕様にしていた問題への対処の話です。
今回はリソース占有の話がメインテーマなので、こちらはさらっとだけ触れます。
障害時のワークフロー運用
例えばワークフローを1つ実行すると
- ワークフロー全体の進捗管理プロセス
- ワークフロー内の各ノード (転送ジョブ) を実行するプロセス
- ワークフローから実行した別のワークフローの進捗管理プロセス、および各ノードのプロセス
- さらに別のワークフロー実行など、複数回ネスト可
と、多くのプロセスが同時並列で実行され、プロセスごとにトランザクション管理、status 管理、エラーハンドリングをする必要があります。加えて、エラー時に自動リトライ、またはエラー時はスキップして後続のプロセスを起動するなど、遷移もさまざまです。
この分散されたプロセスの進捗管理を、EC2 障害時にも冪等を維持するのは高度な保証レベルだったため、リリース初期段階では EC2 障害時は運用での対応をしていました。
どう改善を進めたか
以下の観点で改善を進めることで、障害時にも再実行可能にしました。
- トランザクションのスコープに問題がないか見直し
- 状態を持っていたロジックを特定し DB に永続化
- 各ロジックのステップ(主に status が変わる境目)で EC2 のクラッシュを想定し、その状態で再実行された場合の挙動のチェック
特に status が変わる境目で、自身のプロセス以外に他の多くのプロセスの状態を考慮する必要があり、様々なエッジケースへの対応が必要でした。
ただのアプリケーション改善といえばそれで終わりなのですが、前述のアーキテクチャ移行に伴って、上記の観点をどちらにせよ全て見直さなければいけかったため、「アーキテクチャ移行と一緒に検討できた」という意味でベストなタイミングでした。
移行
カナリアリリースの恩恵により、アーキテクチャ移行に伴うシステムメンテナンスは行わず、全てオンラインリリースで移行は成功しました。
効果
新アーキテクチャへの移行は大きな効果を得られました。
- ワークフローのみで 1000〜1500 GB 要求していたメモリが、15 GB 程度に減りました。これは TROCCO 全体の信頼性向上、コスト削減が成功したことを意味します。[7]
- EC2 障害でも進捗管理プロセスを再実行可能になり、運用負担が減りました。[8]
- 副次的効果として、k8s job の起動時間がなくなった分、ワークフローの起動速度が高速になりました。
(※ 最初の画像と同じ。縦軸の値は集計期間が大きいためまとめられています)
学びと教訓
アーキテクチャ共存コスト
今回、うまくいった事例を紹介しましたが、アーキテクチャ共存コストは、非常に高いことは認識しておかなければなりません。
- 一時的にシステムの複雑度が大きく跳ね上がるデメリットを受け入れる必要があります。
- 共存のためだけのロジック実装やバグ修正をしなければならないですし、自動テストやデプロイも複雑になりマインドシェアも奪われます。
- システムの重要度、共存の見通しが立つかなど、慎重な判断が必要です。
一方で、安全な移行を実現するためには、大いに役に立ちました。
カナリアリリースは改めて有用
カナリアリリースは想定どおり有用でした。
- ワークフローの規模(プラン)ごとの移行は、ビジネス影響を小さくする意味で重要でした。
- 割合を速やかに変更できる管理画面も便利でした。
さいごに
私は TROCCO に週3でJOINしており、数ヶ月かけて設計/実行およびリリースまで完了しました。「週3って何ぞや...?」と気になった人は 採用情報 ポチってみると良いんじゃないかと思います。
この記事は
TROCCO® Advent Calendar 2024 兼
SRE Advent Calendar 2024 の12/21の記事でした。
-
外部サービスからデータを取得し、加工して他の外部サービスに送信する機能。ワークフロー図の1つのノード(ハコ)が転送ジョブ。 ↩︎
-
EC2 障害と書くとレアケースのように見えるが、毎時何十台とスケールアウト/インしており、サーバ台数が多いと定期的に発生する。 ↩︎
-
Manager が管理するワークフローの対象を決め打ちします。決め打ちせず Manager 自身で動的にその場で決定する仕組みも考えられますが、status 管理で維持したい polling 速度を実現するためには現実的ではなく、速度面からこの仕組みを採用しています。 ↩︎
-
アプリケーションをリリースする際に、旧バージョンのアプリケーションと並行稼働させ、一部のユーザーだけを新バージョンにアクセスさせるデプロイ方法。 ↩︎
-
実際に生まれた共存バグの例: 一部の割合を新アーキテクチャに移行した際に、移行したタイミングではまだ実行途中のワークフロー(旧アーキテクチャ)がエラーになり、ワークフローの自動リトライ機能が発火した場合、特定の条件を満たすと、新旧アーキテクチャの両方でリトライが実行されてしまい重複実行になるバグが生まれました。このように共存は非常にセンシティブでした。 ↩︎
-
厳密にはアプリケーションのメモリ利用量ではなく k8s pod が Request するメモリの合計量。 ↩︎
-
正確にはアーキテクチャ移行をせずとも実現可能だが、移行に伴いアプリケーションの status 管理を堅牢にした結果論として。 ↩︎

Discussion