リアルタイム画像生成:StreamDiffusion
こんにちは!初めての記事となりますが、2023年12月に発表された画像生成技術の最新ブレイクスルー「StreamDiffusion」について深掘りしていきます。この技術がなぜエキサイティングなのか、そしてどのようにして従来の限界を打ち破ったのかを解説します。
💡 StreamDiffusionとは何か?
StreamDiffusionは論文「StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation」で提案された、リアルタイムインタラクティブ画像生成のためのパイプラインレベルのソリューションです。従来の拡散モデルが抱えていた「生成に時間がかかる」という大きな課題を解決し、驚異的な処理速度を実現しました。
最大の特徴は、その名前が示す通り「ストリーミング」のように途切れることなく、リアルタイムで画像を生成できる点です。これにより、AIアートツールやゲーム、ライブストリーミングなど、これまでは処理速度の制約で実現が難しかった分野への応用が期待されています。
🚀 圧倒的なパフォーマンス
StreamDiffusionの性能は単純に言って「バケモノ級」です。次のGIF画像はご覧になればお分かりいただけたでしょうか?まさにリアルタイムで驚異的なスピード生成できると言えるでしょう。
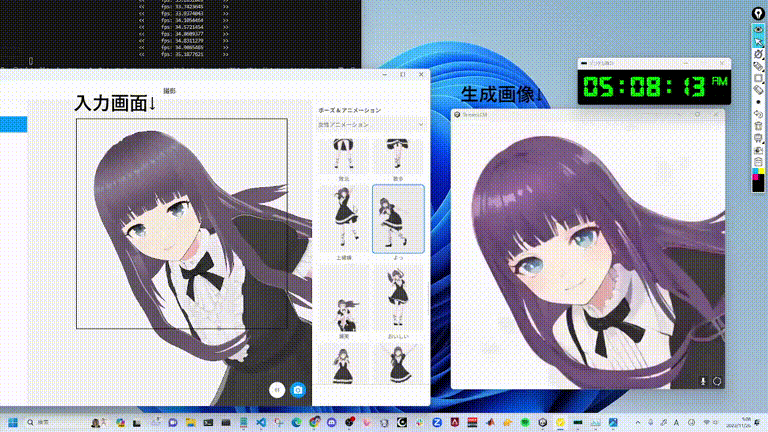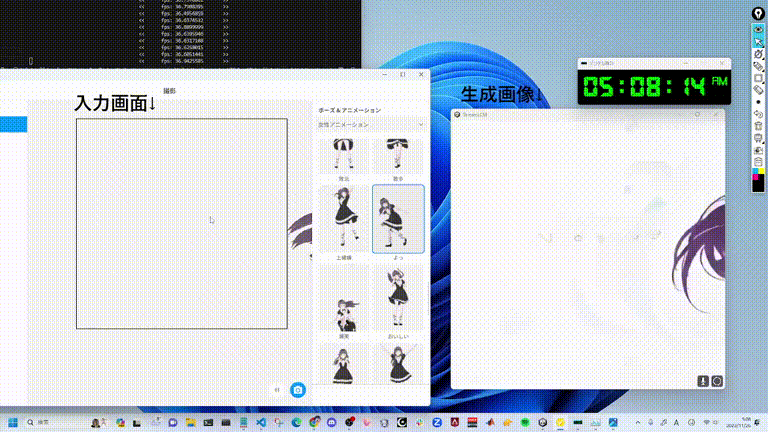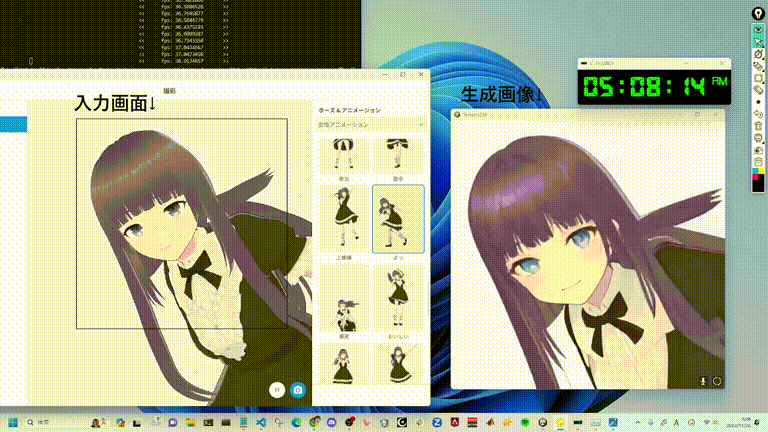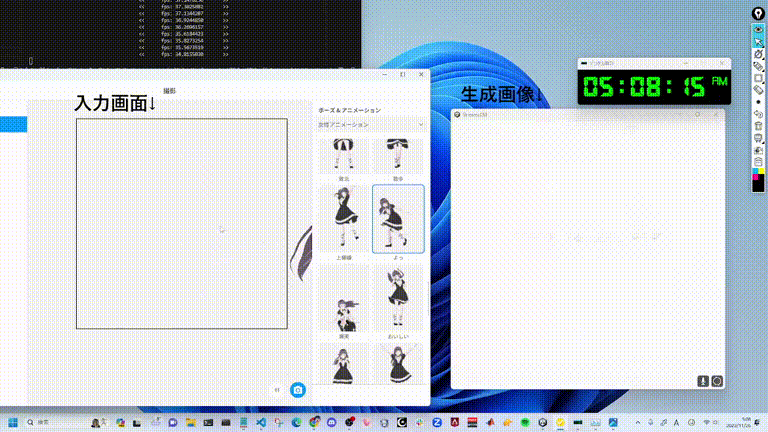
具体的な数字も見てみましょう:
- 単一RTX 4090 GPUで最大91.07 FPSを達成(秒間91フレーム!)
- Diffusersライブラリの
AutoPipelineと比較して59.56倍のスループット改善 - 消費電力の削減:RTX 3060で2.39倍、RTX 4090で1.99倍の効率化
これらの数値が示すのは、単なる小さな改善ではなく、パラダイムシフトといえるレベルの進化です。特に消費電力の削減は、大規模なAIモデルの運用コストが問題視される現在において、非常に重要な進歩と言えるでしょう。
🔧 技術的な革新:StreamDiffusionの6つのコア技術
StreamDiffusionがどのようにしてこの驚異的なパフォーマンスを実現したのか、その秘密を解き明かしていきましょう。
1. ストリームバッチ戦略:拡散モデルの常識を覆す発想
従来の拡散モデル(Stable Diffusionなど)は以下のようなパイプラインで動作します:
- テキストプロンプトをCLIPでエンコード
- ランダムノイズを生成
- デノイジングステップをシーケンシャルに実行(例:50ステップ)
- VAEを通じて潜在空間から画像空間へデコード
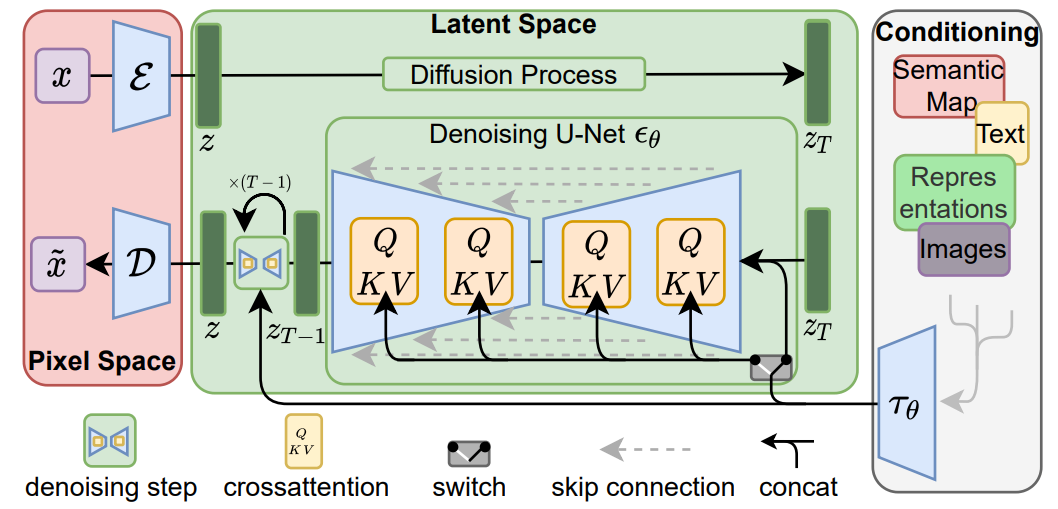
このプロセスでボトルネックとなっていたのが、3番目の「シーケンシャルなデノイジング」でした。各ステップが前のステップの結果に依存するため、並列化が難しいと考えられていたのです。
StreamDiffusionはバッチ処理という革新的アプローチを導入しました。具体的には:
# 従来のアプローチ:
ノイズ → step1 → step2 → step3 → ... → step50 → 画像
# StreamDiffusionのアプローチ:
[batch1: ノイズ1→step1, ノイズ2→step2, ..., ノイズN→stepN] →
[batch2: 中間結果1→stepN+1, 中間結果2→stepN+2, ...] → ...
このアプローチにより、GPUの並列処理能力を最大限に活用し、処理速度を劇的に向上させることに成功しました。これは「なぜ今まで誰も思いつかなかったのか?」と思わせるほどエレガントな解決策です。
2. 残差クラシファイアフリーガイダンス(RCFG):計算効率の大幅な改善
Stable Diffusionなどの拡散モデルでは、テキストプロンプトに忠実な画像を生成するために「Classifier-Free Guidance(CFG)」という技術が使われています。これは通常、以下の計算を必要とします:
ノイズ予測 = (1+w) * 条件付きノイズ予測 - w * 無条件ノイズ予測
ここでwはガイダンス係数と呼ばれるパラメータです。
従来のCFGでは、各デノイジングステップで2回のU-Net計算(条件付きと無条件)が必要でした。これに対しStreamDiffusionは「残差クラシファイアフリーガイダンス(RCFG)」という新しいアプローチを導入しました:
- 自己ネガティブRCFG:元の入力画像を参照として使用
- ワンタイムネガティブRCFG:最初のステップでのみネガティブ条件を計算
この改良により、n回のデノイジングステップに対して、従来の2n回ではなくわずかn回のU-Net計算で済むようになりました。これは計算負荷を半分に削減する革命的な最適化です!
3. 入出力キュー:パイプラインの最適化
高速な画像生成では、モデルの推論だけでなく、前処理(プロンプトのエンコード、VAEエンコード)や後処理(VAEデコード)も重要なボトルネックになりがちです。
StreamDiffusionは「入出力キュー」という仕組みを導入し、これらの処理を並列化しました:
- 入力キュー:プロンプトのエンコーディングやVAEエンコードをバックグラウンドで処理
- 出力キュー:生成された潜在表現をバックグラウンドでデコード
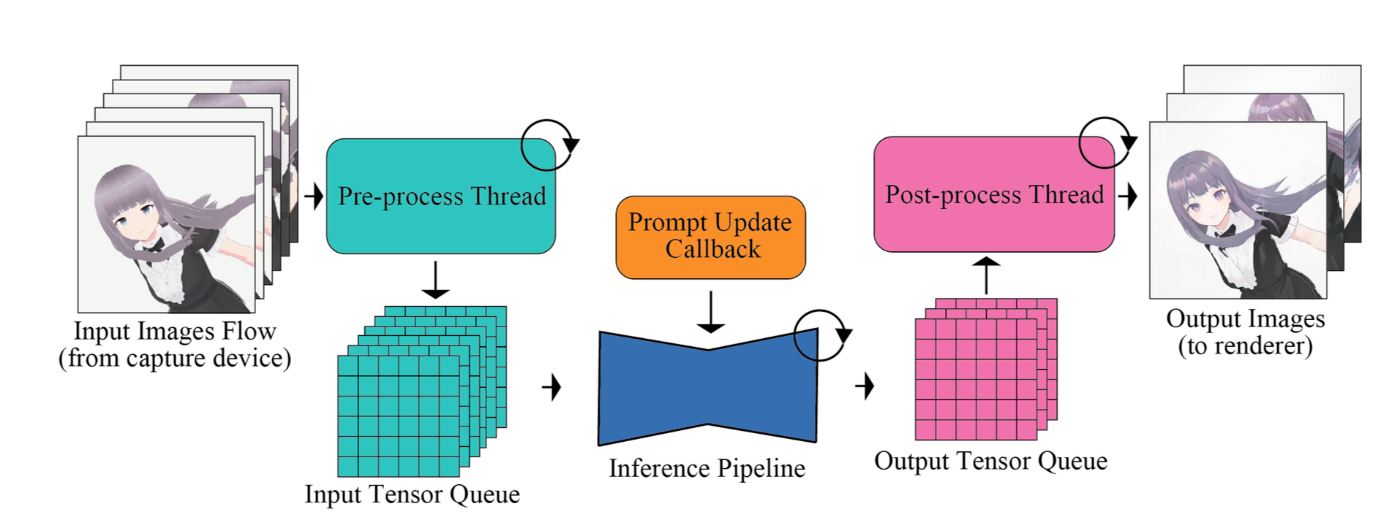
これにより、メインのU-Net推論パイプラインがこれらの処理を待たずに連続して動作できるようになり、全体のスループットが向上しました。まさに「流れ作業」の効率化と言えるでしょう。
4. 確率的類似度フィルター(SSF):スマートなリソース節約
ライブ映像処理などの応用では、連続するフレーム間で大きな変化がないことがよくあります。StreamDiffusionはこの事実を利用した「確率的類似度フィルター(SSF)」を導入しました。
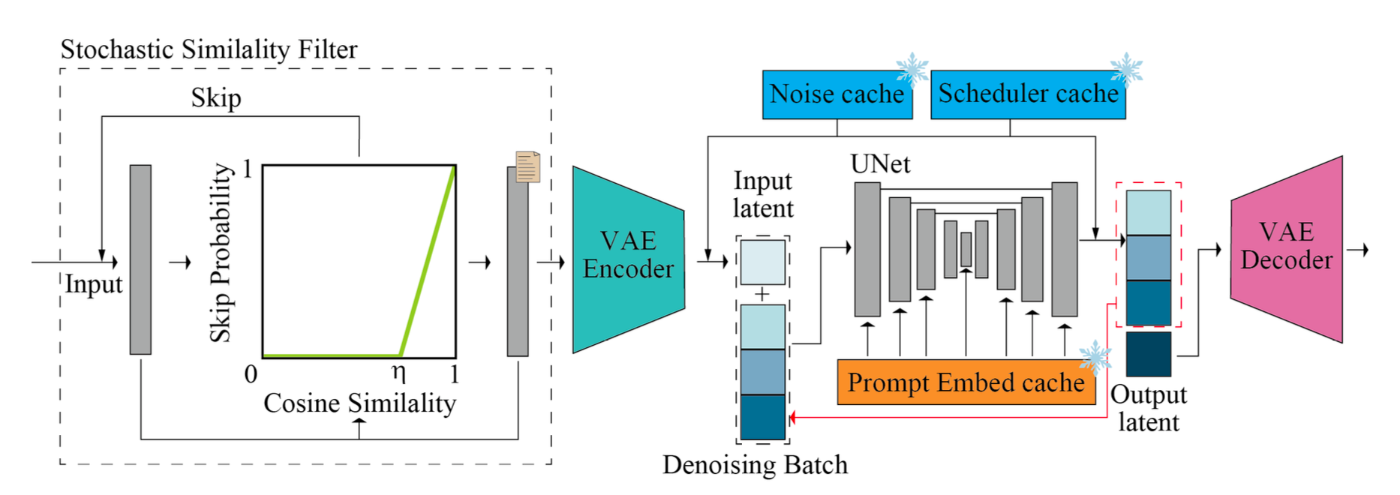
このフィルターは連続するフレーム間の類似度を計算し、以下の確率でフレームの再生成をスキップします:
P(skip|It, Iref) = max(0, (SC(It, Iref) - η)/(1 - η))
ここでSCはコサイン類似度、ηは閾値パラメータです。
これにより、静止シーンや変化の少ないシーンでGPUの計算リソースを大幅に節約し、消費電力を最大2.39倍削減することに成功しました。省エネと高パフォーマンスを両立させる優れた工夫です!
5. 事前計算手順:起動時間の短縮
画像生成プロセスには、毎回同じ計算を繰り返す部分があります。StreamDiffusionでは、これらを事前に計算してキャッシュする戦略を採用しています:
- プロンプト埋め込みキャッシュ:使用頻度の高いプロンプトのCLIPエンコーディングを保存
- サンプリングノイズキャッシュ:初期ノイズパターンを事前生成
- スケジューラー値キャッシュ:拡散スケジュールの値を前もって計算
これらの最適化により、リアルタイム処理の際のオーバーヘッドを大幅に削減しています。
6. モデル加速ツール:ハードウェア最適化
最後に、StreamDiffusionは以下のモデル最適化技術を採用しています:
- NVIDIA TensorRT:GPUに特化した最適化コンパイラを使用
- 軽量なオートエンコーダー(TAESD):標準的なVAEより軽量な代替モデルを採用
- 静的バッチサイズと固定入力寸法:ハードウェアリソースを最大限活用するための最適化
これらの最適化により、単一デノイジングステップでは59.6倍、4ステップのデノイジングでも25.8倍の高速化を達成しました。まさに「チューニングの芸術」と言えるでしょう!
🔄 StreamDiffusionが触発した後続技術
2023年12月に公開されたStreamDiffusionは、多くの研究者にインスピレーションを与え、いくつかの派生技術が生まれています:
- StreamMultiDiffusion:複数のテキストプロンプトからの生成を効率的に行うための平均集約技術を導入
- StreamV2V:ビデオからビデオへの変換を高速化するため、過去フレームの特徴を保存する「特徴バンク」を実装
これらの技術は、StreamDiffusionの基本アイデアを拡張し、より多様なユースケースに対応できるようにしたものです。拡散モデルの実用化に向けた進化が急速に進んでいることを示しています。
💼 実用的なアプリケーション
StreamDiffusionの驚異的な速度は、これまで実現が難しかった多くのアプリケーションの可能性を開きました:
- リアルタイムゲームグラフィックス:プレイヤーの行動に応じて動的に環境や物体を生成
- ライブビデオストリーミング:リアルタイムでの映像スタイル変換や拡張
- AIアシスト描画:ブラシストロークをリアルタイムで高品質な画像に変換
- メタバース:動的で豊かな仮想環境の即時生成
- リアルタイムカメラフィルター:従来のフィルター以上の複雑な変換効果
これらのアプリケーションは、従来の拡散モデルでは「待ち時間が長すぎる」という理由で実用的ではありませんでした。StreamDiffusionの登場により、AIを活用したリアルタイムクリエイティブツールの新時代が到来したと言えるでしょう。
📝 まとめ:AI画像生成の新たなフロンティア
StreamDiffusionは単なる速度改善ではなく、拡散モデルの応用可能性を根本から拡張する画期的な技術です。その革新的なアプローチにより:
- 秒間91フレームという前例のない生成速度を実現
- 消費電力を大幅に削減し、環境負荷とコストを低減
- リアルタイムインタラクティブなAI画像生成の実用化への道を開拓
拡散モデルの研究は2021年頃から急速に進展してきましたが、StreamDiffusionはその「実用化」という新たなフェーズの到来を告げる重要な節目と位置付けられるでしょう。
今後は、この技術がさらに洗練され、より幅広いハードウェアでの動作や、さらに複雑なタスクへの応用が期待されます。AI画像生成の未来がどこまで広がるのか、今から目が離せません!
参考リソース
皆さんはStreamDiffusionをどのように活用してみたいですか?コメント欄でアイデアをシェアしてくださいね!
この記事は2025年3月に執筆されました。AI技術は急速に進化しているため、最新の情報については公式リソースを参照してください。
Discussion