RAG(Retrieval Augmented-Generation)は、多くのエンタープライズで注目されていることでしょう。その中核を担う技術がベクトルデータベース(以降、VectorDB)です。そもそもVectorDBとは何か、どういった役割を担っているのか等を整理し、言語モデルとの関係性についてご紹介します。
VectorDBとは
VectorDBは、ベクトル形式のデータを効率的に格納・検索・分析できるデータベース(DB)です。VectorDBは、自然言語処理・画像認識等、機械学習技術の発展が進む中で、高次元ベクトルを扱う技術として利用されてきました。
DBとしてより認知度が高いリレーショナルデータベース(RDB)は、行・列から構成されるテーブル形式のデータ構造となっており、言語や数値が格納されています。そして、データにアクセスする際は、SQL等のクエリ言語を用いて行・列を直接指定します。こういった特徴からもわかる通り、RDBは視覚的にイメージしやすいのが特徴です。
一方、VectorDBは数値([0, 0.3, 1, 0.8, 0]のようなベクトル情報)の集合でしかなく、データそのものを見ても何を表しているのかわかりません。検索方法も、クエリ言語を用いて行・列を指定するのではなく、クエリベクトル(類似ベクトルを見つける元となる検索ベクトル)に類似するベクトルデータを計算して抽出することになります。VectorDBは、高次元データの取り扱いに優れており、計算スピードもRDBに比べると早い点が強みとなります。
なぜいまVectorDBが注目されているのか?
ここ最近、VectorDBスタートアップが続けざまに資金調達に成功しています。後半でご紹介しますが、VectorDBの中でも広く利用されているPinecone、Milvus(企業名はZilliz)、Weaviate、Qdrant、Chromaは、いずれもここ1年間のうちに、直近の資金調達ラウンドを実施しました。
VectorDBに対して注目が集まっている背景に、大規模言語モデルの流行が挙げられます。2022年11月に、OpenAIがChatGPTを発表し、法人から個人まで広く支持を集めたことをきっかけに、世界的に大規模言語モデルをビジネス活用する動きが加速しています。
では、大規模言語モデルの流行とVectorDBがどのように関わっているのでしょうか。それを理解するうえで、OpenAI・ChatGPT・GPTというキーワードからスタートするのが近道であるように思います。
まず、発表から半年以上経過した今でも毎日のようにニュースを賑わせているChatGPTですが、これはOpenAIという営利企業が開発したAIチャットボットです。自然言語で質問・命令を投げかけると、あたかも裏側に人間がいるのではないかと思ってしまうほど自然な言語で返答します。このAIチャットボットの脳みそにあたる部分が、GPTという言語モデルになります。GPTは「Generative Pre-Trained Transformer」の略で、大量のテキストデータを学習して自然言語処理タスクに強くなった深層学習モデルの一種です。ChatGPTは、読んで字のごとく、GPTをチャット形式で利用できるようにしたアプリケーションです。
OpenAIは、ChatGPTとは別に、GPTという言語モデルを開発者が利用できるように、API(Application Programming Interface)を公開しています。このAPIには、「Completion」と「Embeddings」の2種類があります。ChatGPTのイメージに近いのは前者の「Completion」で、これは「ある文書に穴ぼこが空いており、文脈や前後の単語からその穴ぼこを埋めて完成させる(Completion)」という機能を持ちます。
VectorDBにより直接的に関連しているのが、後者の「Embeddings」というAPIです。これは「データをベクトル空間に埋め込む」という意味合いで「Embeddings」と名付けられています。OpenAIのAPIは固有名詞として大文字から始まる「Embeddings」と名付けられていますが、以降、本レポートでは、「ある情報をベクトルに変換する」という意味で「embedding」という一般名詞を利用します。
VectorDBは、あるクエリベクトルに対して類似度の高いベクトルを抽出する、という形で利用されることが一般的ですが、その前後で発生する「自然言語をクエリベクトルに変換する」、「ベクトルを自然言語に変換する」というプロセスで、GPTのような大規模言語モデルが必要になります。
ChatGPTは、少し専門的なことを質問すると「あたかも正解かのように、真実ではないことを回答」(これをHallucination=幻覚と言います)しますが、これは、ChatGPTが事前学習しているテキストデータの中に、確度の高い答えがないためです。そこで、ChatGPTに、外部記憶装置としてVectorDBをくっつけると、より確度の高い(クエリベクトルと結果ベクトルの類似度がより高い)結果を返すことができます。
「ドラえもん(大規模言語モデル)に四次元ポケット(VectorDB)をくっつけた」ようなイメージが近いかもしれません。また、ドラえもんは、よく四次元ポケットから「あれがない、これがない」と騒ぎながらアイテムを取り出している印象がありますが、VectorDBも、データの格納方法が適切でないとデータ抽出に時間がかかってしまったり、関係の薄いものを取り出してしまったりすることがあります。そこで、VectorDBの性能が重要になってきます。
言語モデルとembedding
「言語をベクトル変換する」と書いたものの、いざ何をしているのか考えると、直感的に理解するのは簡単ではありません。言語とは、単語・文・段落等から構成されるものであり、単語をベクトル変換するのか、はたまた文・段落をベクトル変換するのか、によっても意味合いが異なってきます。
例えば、「アメ」という単語に付与されるベクトルは、固定的なもの(例えば、文脈に限らず[0, 0, 1]のようなもの)なのか、あるいは「アメ」が「雨」「飴」どちらかによって異なるベクトルであるべきなのか、等の疑問が湧いてきます。
この章では、さまざまな言語モデルがトライしてきた、単語をベクトル表現する方法について、時系列が古い順に紹介していきます。なお、embeddingとはあくまで「ベクトル変換」を指し、言語情報に限らず画像・音声のような情報のベクトル変換もembeddingに含まれます。ただし、今回は言語のembeddingをメインでお話します。
One-Hot Encoding
One-Hotとは、デジタル回路において、1が1つだけで、他が全て0であるようなビット列の呼称です。つまり、単語を0と1のベクトルだけで表現することになります。例えば「イヌ」「ネコ」「トリ」という3つの単語がある場合、「イヌ」を[1, 0, 0]、「ネコ」を[0, 1, 0]、「トリ」を[0, 0, 1]のように表現します。ただし、この方法は、ある単語に番号をつけているだけのようなもので、単語の意味や単語同士の関連性は全く表現できませんでした。
TF-IDF(Term Frequency - Inverse Document Frequency)
TF-IDFは「ある文書中に、その単語がどれくらい多い頻度で出現するか」(TF=Term Frequency)と、「全文書中に、ある単語を含む文書がどれくらい少ない頻度で出現するか」(IDF=Inverse Document Frequency)の掛け算で算出される統計的尺度で、「各単語が、文書内でどれくらい重要か」を表します。
以下、文書A〜Cに、次のように単語が出現する場合を考えてみます。
- 文書A:「イヌ」「イヌ」「イヌ」「サル」「キジ」
- 文書B:「イヌ」「ネコ」「ネコ」「イヌ」
- 文書C:「イヌ」「タヌキ」「キツネ」
まず、「イヌ」は、文書Aに3/5の確率で登場する一方、全文書に登場するためIDFが低くなります。一方、「ネコ」は文書Bにしか登場しないためIDFが高くなります。「タヌキ」も文書Cにしか登場せずIDFは「ネコ」同等に高いですが、文書Bの中で「ネコ」は2/4を占める一方で、「タヌキ」は文書Cの中で1/3であるため、「ネコ」に比べると「タヌキ」はTFが低くなります。
TF-IDFを利用した言語モデルでは、文書に含まれる単語にTF-IDFをベクトル情報として付与します。例えば、「小さなネコが大きなネコに追いかけ回され、結果的にイヌに助けられた」という文書があった場合、「ネコ」と言う単語を表すベクトルには、高いTF-IDFスコアが含まれ、「イヌ」は「ネコ」の次に高いTF-IDFスコアが付与されます。これによってその文書の中心的なトピックを捉えることが可能になります。一方、これはOne-Hot Encodingにメタ情報が少し加わった程度で、相変わらず単語の意味や単語間の関連性を理解することはできませんでした。
Word2Vec(Word-to-Vector)
Word2Vecは、2013年にGoogleが公開した「Efficient Estimation of Word Representations in Vector Space」という論文で発表されたモデルです。
Word2Vecのベースとなっているのが、2000年頃に登場した「分散表現」という考え方です。これが、いまのGPTにもつながっている「文字・単語を高次元のベクトル空間に埋め込み、その空間上の1つの点として捉える」という手法で、単語(Word)をベクトル(Vector)空間に埋め込む、ということでWord2Vecと名付けられています。
まず、この概念を視覚的に捉えるために、「Embedding Projector」というサイトをご覧ください。これは、ある単語がベクトル空間の中でどこに位置付けられるかを模したグラフになります。試しに「money(お金)」という単語を入力してみると、近辺に「bank(銀行)」「wealth(富)」「payment(決済)」といった「お金にまつわる単語」が登場します。
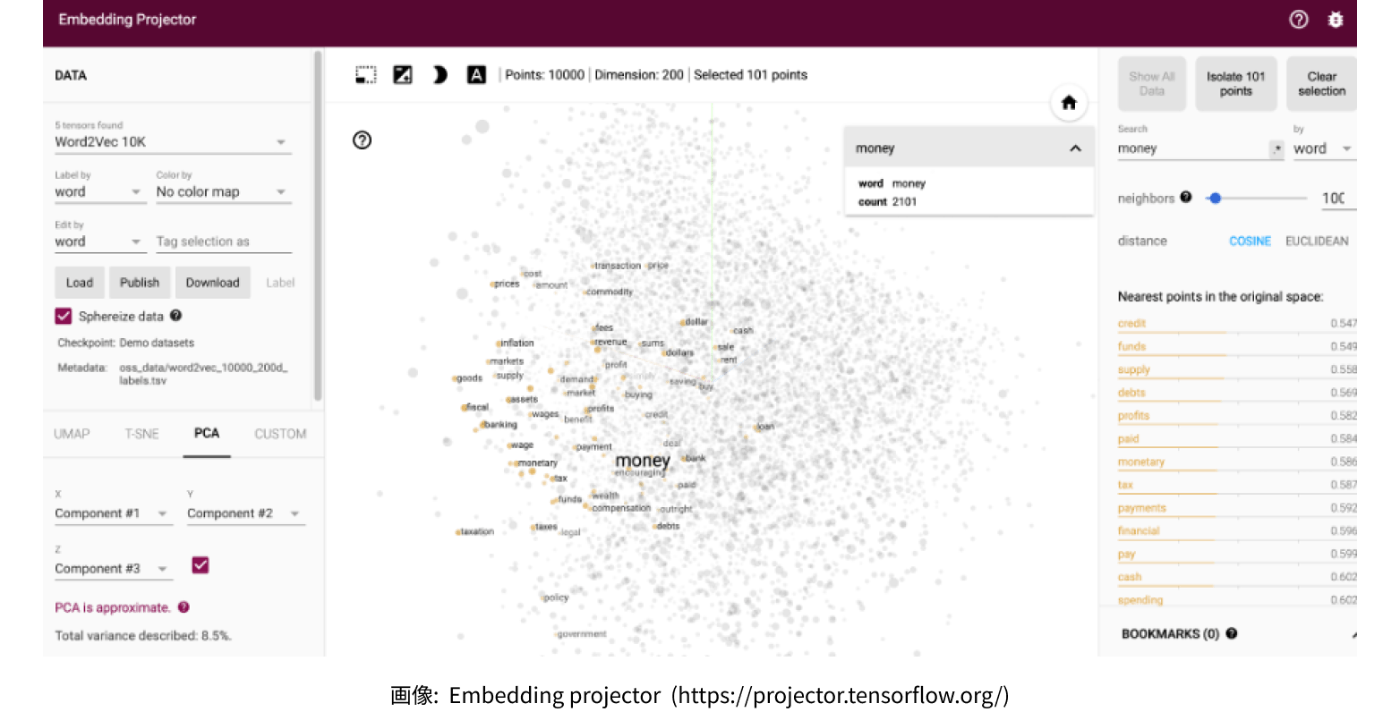
また、「einstein」と入力すると、近辺には「neumann」「maxwell」「gauss」等の科学者が並びます。ただし、これは、「あるデータセット」を学習した結果に過ぎないため、異なるデータセットを学習すれば違うベクトル空間が出現することになります。例えば、einsteinの伝記ばかりを学習させれば、他の科学者の名前より、物理学の単語や数式等が近いベクトル空間に登場するかもしれません。

Word2Vecは「CBOW(Continuous Bag of Words)」と「Skip-gram」という2つのモデルから構成されています。それぞれの役割は明確で、CBOWは「周辺の単語から、ある単語を予測」、Skip-gramは「ある単語から、周辺の単語を予測」します。例えば、CBOWは「ネコはXを追いかける」のXを予測し、Skip-gramは「ネコ」という単語から「は」「ネズミ」「を」「追いかける」といった単語を予測します。

モデルの役割はわかりましたが、これがどうembeddingにつながるのでしょうか?
上記2つのモデルは、大量のテキストデータを元に学習していきます。例えば、CBOWの場合、「ネコはネズミを追いかける」という一文を「ネコは」「ネズミを」「追いかける」という単位(これを「チャンク」と言います)に分割し、「ネズミを」というフレーズを予測するための問題文のようなもの(「ネコは」「Xを」「追いかける」)を作成します。
そして、ニューラルネットワークがXに当てはまる単語を予測します。ニューラルネットワークは、予測結果と実際の正解(「ネズミ」)との誤差を計算して、ネットワークの重みづけを調整していきます。これを繰り返すと、ニューラルネットワークの重みづけが最適に近づいていきます。
Word2Vecにおけるembeddingとは、このニューラルネットワークの重みづけに他なりません。「ネズミ」という単語が持つベクトルは、「ネコが」「追いかける」という文脈の中で頻出しやすいと予測するネットワークの重みづけ、ということになります。
Word2Vecの革新性は「単語同士を意味的に関連づけられる」ようになった点にあります。有名な話では、「”King” - “Man” + “Woman = “Queen”」という推論ができるようになったことが知られています。これは、恐らく「King is a royal man」「Queen is a royal woman」等のテキストデータを大量に学習していった結果、King・Man・Woman・Queenそれぞれの単語が持つベクトルの関係性がわかるようになったためです。

FastText
FastTextは、2017年に、Facebook AI Research(現在のMeta AI Research)が公開した「Enriching Word Vectors with Subword Information」という論文で発表されたモデルです。Word2Vecの延長線上にある技術ですが、Word2Vecが抱えていたある課題を解決しました。それが、「語形変化」への対応です。
Word2Vecでは、例えば「go」という動詞があったとして、「goes」や「going」を別単語として認識していました。FastTextは、1つの単語をさらに小さな構成要素(subword)に分解しました。例えば、「goes = go + oe + es」、「going = go + oi + …」のようなイメージです。これによって、単語の分類が細かくなり、学習データセットになかった未知の単語、あるいはタイプミス・スラングにも対応できるようになりました。例えば、「going to」を「gonna」と略すことがありますが、subword単位で学習していると、「gonna」は「”gonna”という単語ではなく、”go”の後ろにsubwordがくっついている」と認識できるようになります。
ELMo(Embeddings from Language Models)
ELMoは、2018年にUniversity of Washingtonが「Deep contextualized word representations」という論文で発表したモデルです。ELMoが、Word2VecやFastTextと異なった点は、ある単語が持つベクトルを「静的」なものから「動的」なものに変化させたところです。Word2Vecモデルでは、ある文書における「ネコ」という単語が持つベクトルは固定的です。一方、現実世界には多義語が多くあり、「単語の意味は文脈の中で動的に決定されている」のが実情です。例えば、英語の「bank」という単語には、「銀行」だけでなく「河岸」という意味があり、「お金の話をしているのか」、「アクティビティの話をしているのか」によって、どちらを指すのかは変わってきます。ELMoは、文脈に応じて、単語に付与するベクトルを動的に生成する機構をつくりました。
具体的に、ELMoは次の画像ようなモデル構造を採用しています入力層(E1, E2, …, EN)と出力層(T1, T2, …, TN)の間にLSTM(Long-Short Term Memory)というノードが並んだ隠れ層があります。

この隠れ層におけるLSTMの状態を数値で表したものがベクトル情報になります。上図からも分かる通り、隠れ層内部でLSTMは相互に影響を与えており、入力の順番を変えるだけでベクトルも変わってきます。例えば、「私はパリに行ってエッフェル塔を見た。そこは、とても美しかった。」という文の場合、恐らく「そこ」が指すのは「エッフェル塔」です。
一方、「私はエッフェル塔があるパリに行った。そこは、とても美しかった」という文の場合、「そこ」が指すのは「エッフェル塔」ではなく「パリ」です。このように、単語が登場する順番等の時系列情報も考慮に入れながら、動的にembeddingを行えるようになりました。
Transformer
Transformerは、2017年にGoogleが公開した論文「Attention Is All You Need」で公開されたモデルです。時系列的にはELMo(2018年)より前に登場しているのですが、Transformerこそが、現在の大規模言語モデルを支える主流技術となったため、最後に回しました。
ELMoのようにLSTMを用いたモデルは、精度が向上した一方で、隠れ層の複雑な処理によってembeddingに時間がかかること、そして、それを高速化しようとしてもなかなか難しいことが、課題として残りました。そこで注目されたのが、Attentionという機構です。これは、文書の中で大事なところだけに注目(Attention)する、という仕組みです。具体的には、単語が持つ静的な固有ベクトルに、文脈における重要度を表す動的な文脈ベクトルを付加します。そういった意味では、TF-IDFやELMoが組み合わさったようなコンセプトかもしれません。
Attentionという機構自体は2015年に考案されていましたが、Transformerは、Attentionを複数用いたMulti-Attentionという仕組みを採用した点が画期的でした。Muti-AttentionにGPUを用いることで、文書の中で複数の重要単語に同時並行で注目できるようになりました。これによって、高い精度をスピーディに発揮することができるようになりました。
Transoformerの理解を深めたい方はぜひ『ChatGPTの頭の中』(スティーヴン・ウルフラム、高橋聡訳、稲葉通将監訳、早川書房)をご一読ください。
言語モデルとベクトルデータベースの役割
少し回り道してしましましたが、改めて言語モデルとVectorDBの関係を整理してみます。ある言語をembeddingするのは、言語モデルが担う役割です。embeddingされたベクトルを検索・分析しやすい状態で格納するのがVectorDBです。
VectorDBは、インデックスを生成し、ベクトルを格納します。このインデックス生成が、VectorDBの持つ主要な役割の1つです。インデックスは、ベクトルを管理する単位で、ベクトルの次元数、ベクトルの類似性検索に使用する手法、ベクトルに付与するメタデータの型等を設定します。
まず、ユーザーが「ネコに関する情報を教えて」のような自然言語クエリを投げかけるとします。これを言語モデルがembeddingし、クエリベクトルを生成します。クエリベクトルと類似するベクトルが、VectorDBの中で探索され、取り出されます。このとき、クエリベクトルに類似するベクトルを探索する手法には、いくつかの種類があります。
例えば、kd-tree、ball-tree、LSH(Locality-Sensitive Hasing)、HNSW(Hierarchical Navigable Small World)、等が代表例です。
- kd-treeはk-dimensional treeの略称です。データをk個の軸で分類していき、最終的に探索しているデータに近いデータを発見します。大量の軸でデータを分類していくため、階層が深くなりやすく、次元数(軸)が増えると効率が低下すると言われています。
- ball-treeは、データを特定の軸で分類していくという意味ではkd-treeに似ていますが、データのひとまとまりを球で表現するという点が特徴です。あるクエリベクトルを中心とする球を考え、そこから表面までの距離が等しいデータを1つのまとまりとします。さらに、そのデータのまとまりは、中心からの距離という観点で分類されていきます。これが繰り返されていくうちに、空間的に近いデータにたどりつく、というロジックです。kd-treeに比べて高次元のデータを扱いやすい、と言われています。
- LSHは、ハッシュ関数を利用した手法です。ハッシュ関数とは「特定のデータを別の値に変換する」関数です。LSHでは、ベクトル情報が近いデータを同じハッシュ値にマッピングするように設計されています。
- HNSWは2014年頃に登場した技術で、大規模なデータに対して高いパフォーマンスを発揮する探索技術として注目を集めており、多くのVectorDBに採用されています。
HNSW(Navigable Small World Graph)
HNSWは、Probability Skip List(確率スキップリスト) + Navigable Small World Graph(ナビゲート可能な小世界グラフ)で構成されています。

Probability Skip Listとは、以下の図を参照しながら考えると理解しやすいかと思います。まず、小さい順に並ぶ数字の中から、11という数字を探すというミッションを考えます。図の左側にある各レイヤー(階層)が止まれる数値は決まっており、上位レイヤから下位レイヤにいくほど止まれる数値が「密」になっています。
例えば、レイヤー3は、スタートからエンドまでの間に5の地点にしか止まりません。その1つ下層のレイヤー2は5・19に止まります。その1つ下層のレイヤー3は、5・11・19に止まります。検索を行う時、上位レイヤからスタートし、到達したい数値を超えてしまったら、1つ下のレイヤに下がります。それを繰り返すうちに、11に止まることのできるレイヤに当たります。今回の場合、レイヤ3から始まり、5の次がエンドだったためレイヤ2に下がり、レイヤ2で5の次が19だったためレイヤ1に下がり、レイヤ1で5の次が11だったので、そこでミッション終了となります。これは、スタート地点から1・2・3・etcと探していくよりも試行回数が少なくスピーディです。

HNSWは、Probability Skip Listからインスピレーションを得て進化したNavigable Small World、と言えます。以下の図が構造を端的に表しています。1番上のレイヤにあるEntry Pointから入り、そのレイヤで最もクエリベクトルに近似するポイントから下のレイヤに降ります。また同じように最も近似するポイントまで移動し、見つかったらそこから下のレイヤに降ります。最終的に最下層レイヤまで下がっていき、最も近似するポイントに到達します。

個人的には、まだ仮説の域を出ませんが、エンタープライズシステム・大規模言語モデルとシームレスにつながるVectorDBはホットなトピックの1つとなると思います。その場合、特に企業内のサイロ化したシステムとの連携を行う中で、セキュリティ・処理速度の向上等、高い要素技術が求められます。
まだまだ、技術的な発展がたくさんありそうな分野なので、本Newsletterでは今後の進展を引き続きお届けします。
株式会社Dynagonのテックブログです。生成AI、RAG、Vectorデータベース等のOSS・論文紹介や、生成AIのユースケース紹介・考察を発信しています。
Discussion