
RAG (Retrieval Augmented Generation) システムは、事前に構築された知識ベースから、必要な情報を検索し、その情報をLLM (大規模言語モデル)に参照させることで回答を生成します。RAGシステムの構築において、知識ベースから情報を取得する「Retrieval」のステップが重要です。回答に必要な情報に対して取得(Retrieve)した情報が不十分な場合、当然ですが最終的な回答も満足のいくものにはなりません。また情報の不足が目立ないように、知識ベースの情報の全てをLLMに入力するアプローチも考えられますが、雑多な情報で溢れかえってしまうと回答精度の低下につながるということが知られています。("Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models" (Levy et al., 2024))
1. エージェント
LLMにおける最重要論文の1つに "ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al,. 2022)" があります。ReActと呼ばれているものの基本的な設計と有用性を明らかにした論文であり、エージェントと呼ばれています。
ReActはLM(言語モデル)自身が観察した情報から推論し、その結果を経て行動することを可能にする機構です。つまり自律的に考えて動くことが可能になります。
ReAct論文では、質疑応答や事実検証といった試験で、通常のLLMを扱う際に見られるハルシネーションやエラー伝播といった問題の克服が確認されました。また意思決定タスクのベンチマークであるALFWorld、WebShopにおいても優れたスコアを記録していることが報告されており、ReActが汎用的なタスク解決能力を有するフレームワークであることが示されています。また、各ステップの意思決定の軌跡が言葉で残されるため、思考過程の解釈が容易である点も長所として挙げられています。説明可能なAI(Explainable AI; XAI)が求められるシーンにおいては、思考の過程がテキスト情報として残ることは非常にありがたい特徴です。
ReActではLLMに対して、言語による推論(Reasoning)のトレースとタスクに対するアクションを交互に生成するように要求します。ReActの推論の様子を示した図では、質問に対して思考(Thought 1)→行動(Act 1)→結果の観察(Obs 1)→思考(Thought 2)→行動(Act 2)…という一連の動作を経て最終的に "Finish" というアクションを選択することで、回答を決定します。
ReActは、LlamaIndexやLangchainで提供されているエージェント機能により容易に実装が可能です。以下はGoogle検索ツールをReActエージェントに与えて、UberとLyftの2021年の収益成長の比較・分析のタスクを与える例です。
UberとLyftの2021年の収益成長の比較・分析のタスクを与える例
- ユーザーからUberとLyftの2021年の収益成長を比較し分析せよというタスクが与えられます。
プロンプト: Compare and contrast the revenue growth of Uber and Lyft in 2021, then give an analysis
- ループ1:
- Thought: I need to use a tool to help me compare the revenue growth of Uber and Lyft in 2021.
- Action: google_search
- Action Input: {'input': "What was Lyft's revenue growth in 2021?"}
- Observation: Lyft's revenue growth in 2021 was 36%.
- ループ2:
- Thought: I need to use a tool to help me compare the revenue growth of Uber and Lyft in 2021.
- Action: google_search
- Action Input: {'input': "What was Uber's revenue growth in 2021?"}
- Observation: Uber's revenue growth in 2021 was 57%.
- ループ3:
- Thought: I need to use a tool to help me compare the revenue growth of Uber and Lyft in 2021.
- Action: finish_and_response
- Action Input: {'input': "In 2021, Lyft's revenue growth was 36% while Uber's revenue growth was 57%. This indicates that Uber experienced a higher revenue growth compared to Lyft in 2021."}
- 回答:
In 2021, Lyft's revenue growth was 36% while Uber's revenue growth was 57%. This indicates that Uber experienced a higher revenue growth compared to Lyft in 2021.
以上は、LyftとUberの財務に関する情報を参照し、収集した情報を統合して分析させる例でした。このようにReActのフレームワークを利用することで、情報取得に関するアクションも洗練され得られる情報の精度も高まることが期待されます。
2. ツール
さきほど紹介したReActのActionに用いられたGoogle検索ツールのように、エージェントにツールを与えることで、LLMの可能性は大きく広がります。エージェントに与えることのできるツールはGoogle検索に限りません。基本的にあらゆるソフトウェアをツールとして扱わせることができるため、コード実行環境、知識ベース、分析ツールなどの様々なツールを与えておくことで、エージェントの行動範囲を広げ、より高度な情報処理が可能になります。
(Source: https://medium.com/scisharp/understand-the-llm-agent-orchestration-043ebfaead1f)
Voyager (Xiao et al,. 2023) では、LLMがいかに自在にツールを扱えるかが示されました。マインクラフトのように複雑なゲームでも操作できるということが証明され、ここからWebブラウジングをさせたり、他のツールを扱わせたりする関連研究へと発展していきました。
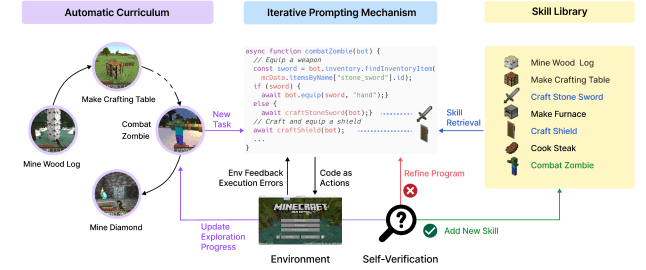
(Source: https://medium.com/scisharp/understand-the-llm-agent-orchestration-043ebfaead1f)
一方でLLMに便利なツールを与えたとしても、最初からその使い方をLLMが知っているわけではないので正しく
扱えないことが多いです。ChatGPTではCode InterpreterやDALLEのようなツールが適切なタイミングで採用されますが、お
そらく追加学習によって上手く使えるようにしています。
この課題を克服するために、基盤モデルに追加学習する形でツールの使い方を覚えさせるアプローチで Toolformer
(Schick et al., 2023) という手法が開発されました。ToolformerではWikipedia検索やカレンダー情報参照、翻訳、計算機などの機能を外部に持たせ、必要に応じてLMがそうしたツールを呼び出すことができるようにチューニングされています。しかしながらToolformerのようなファインチューニングを必要とする手法は非常にコストがかかります。また最高性能のモデルはしばしばオープンソースとして公開されていないため、性能が劣後するモデルを使わざるを得ません。
これに対して モデルを追加学習する必要のない手法である ART (Paranjape et al., 2023) が提案されました。ARTでは、TASK LIBRARYというプロンプト集と、TOOL LIBRARYというツール集を用意します。TASK LIBRARYはいくつかのツールを組み合わせてタスクを実行する事例集としての役割を持っています。つまりツールをただ与えるのではなく、タスクの説明とツールの使用例をセットで記録しておき、モデルがそれを参考にすることで使い所と使い方を間違えにくくしているのです。
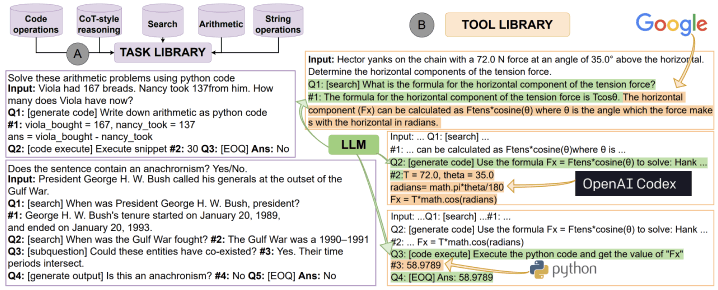
(Source: https://arxiv.org/abs/2303.09014?ref=ja.stateofaiguides.com)
3. Corrective-RAG
冒頭に書いた通り、RAGにおいては必要な情報を漏れなく参照するということが非常に重要であり、技術的に最も注力すべき部分です。ツールを用いることで情報の参照精度を高めるCorrective-RAGという手法があります。
Corrective-RAGでは、正しい情報取得(Retrieve)を評価するためのモデルを作成し、検索評価器(Retrieval Evaluator)としてRAGに組み込みます。Retrieval Evaluatorは、Retrieveの結果を正しい(Correct)曖昧(Ambiguous)間違い(Incorrect)の3つに振り分けます。正しいと判断された情報はそのまま生成の参考とし、間違いと判断された情報は却下してもう一度情報取得のアクションを取ります。
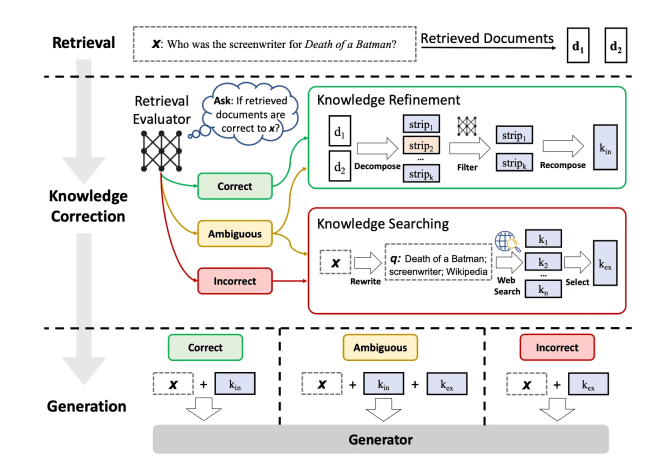
(Source: https://arxiv.org/abs/2303.09014?ref=ja.stateofaiguides.com)
Corrective-RAGのようにRetrieveの結果を評価するというアイデアはごく自然な発想ですが、多くのRAGシステムではこれが実現されていません。一般的なRAGのRetrieveは1回だけであり、試行錯誤のような過程を踏むことはありません。例えると、背表紙だけを見て1冊の本を手に取り、そこから変えることなく、その1冊の中に書いてある知識だけで仕事をこなすことを強いられているようなものです。本の選択が間違っていることに気付いた時に、改めて選定しなおすようなチャンスを与えることが重要であるということは人間であればごく普通のことであり、RAGの機構にもそういった配慮が必要です。
株式会社Dynagonのテックブログです。生成AI、RAG、Vectorデータベース等のOSS・論文紹介や、生成AIのユースケース紹介・考察を発信しています。
Discussion