Google Cloud生成AIセキュリティ対策:AIエージェント観点(Secure AI Framework)
こんにちは。山下です。
自分達で作成したアプリケーションに生成AIを組み込んでサービス提供を行ったり、自分たちの業務で生成AIを活用して効率化を図っているケースが増えているかと思います。
さらにNext'25でも発表のあった通り、RAG/CAGや単なる外部へのアクションを超えたAIエージェントが多数実装がされ、それぞれのエージェント同士が連携し合うマルチエージェントの時代になろうとしています。
つまり、人間の相手がAIなだけでなく、AIの相手がAIといった時代が来るという事です。これは面白く更なる革新が期待できる一方で、セキュリティの脅威ポイントが増える事も意味しています。マルチエージェント時代に向けて、改めてレイヤーSAIF/OWASP Top 10 for LLMを基に整理していきたいと思います。また、その中でGoogleCloudで出来るセキュリティ対策も見ていきます。
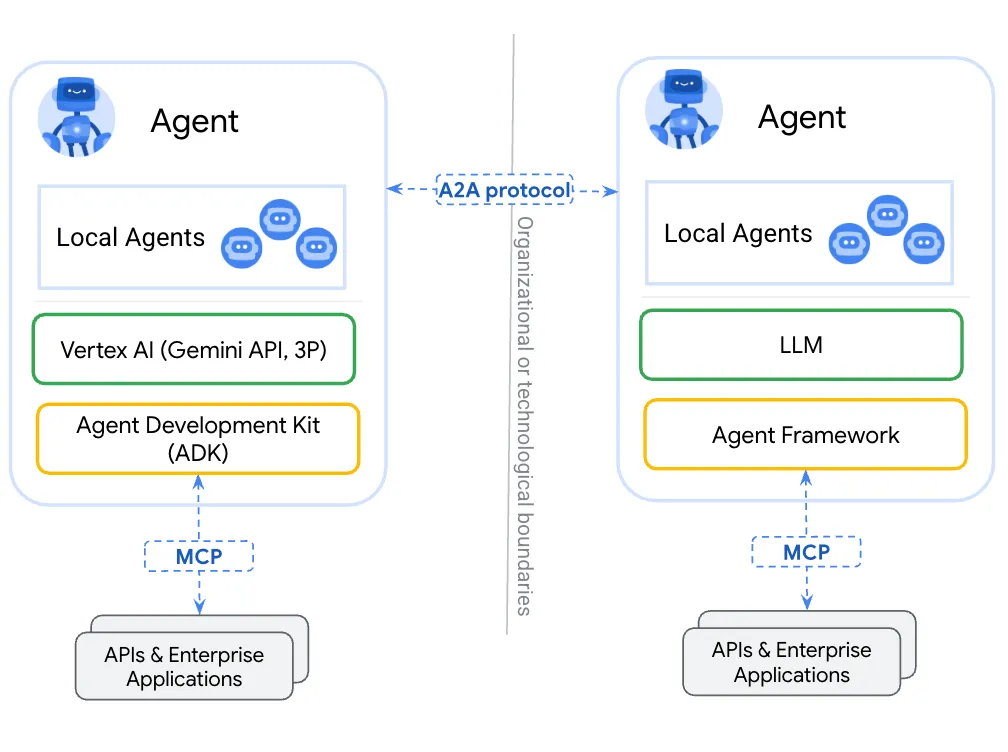
AIアプリケーションを構成するコンポーネント
Secure AI Framework
Googleの定義するAIセキュリティフレームワーク(SAIF)にAIアプリケーションを構成するコンポーネント一覧が定義されています。AIの基となる学習データから推論サービス/外部連携のレイヤーまでを示しています。内容は大きく以下の4つから構成されています。従来のアプリケーションに加えてAIアプリケーション固有の要素がいくつかこの中に追加されています。
| 工程 | 階層 | 内容 |
|---|---|---|
| モデル開発 | データ | 学習データ,推論データといったAIの材料またはサービスとして外部から受け取るデータ |
| モデル開発 | インフラ | 学習/推論データを格納するストレージ、モデル本体を格納するレジストリ、モデルを稼働させるサーバ |
| モデルサービング | モデル | 生成AI基盤モデル、回帰/分類/特定用途などの個別モデル、独自学習/チューニングしたモデル |
| モデルサービング | アプリケーション | フロントエンドサービス、バックエンドサービス、エージェント関連ロジック(RAG/Embedding, CAG, プロンプト処理, 外部APIへの連携) |
https://saif.google/secure-ai-framework/components

+マルチエージェント
SAIFでは一部アプリケーション層の”外部連携”として包含されていますが、マルチエージェントを構成する要素はさらに分解できます。特に気を付けたいのが、AIエージェントからAIエージェントへのやり取りです。自分達で作成/管理しているエージェントであれば対策が取れるのですが、相手のAIエージェントまでとなるとカバーできない領域が出てきます。まずはセルフコントロールできるものから考えてみたいと思います。
※構想段階であったりデファクトスタンダードに相当するものが見えていないため、追加や変更の可能性が高いので留意ください。
| SAIF階層 | コンポーネント | 内容 |
|---|---|---|
| アプリケーション | エージェントネットワーク | A2Aプロトコル、エージェントメッシュ、サーキットブレーカー等サービスメッシュに相当する層 |
| アプリケーション | エージェントフレームワーク | Google ADKやLangGraphのようなシングル、役割別のエージェント実装を行うためのフレームワーク |
| アプリケーション | 外部連携サーバ/クライアント | MCPを中心としたRAG/CAGや外部API、コンテキスト管理といったAIアプリケーションの外部と連携するための仕組み,実装 |
| アプリケーション/データ | 外部連携先データ,API | 外部連携しているRAG/CAGの基や推論先/アクションを実行するAPI、コンテキスト保存先など |
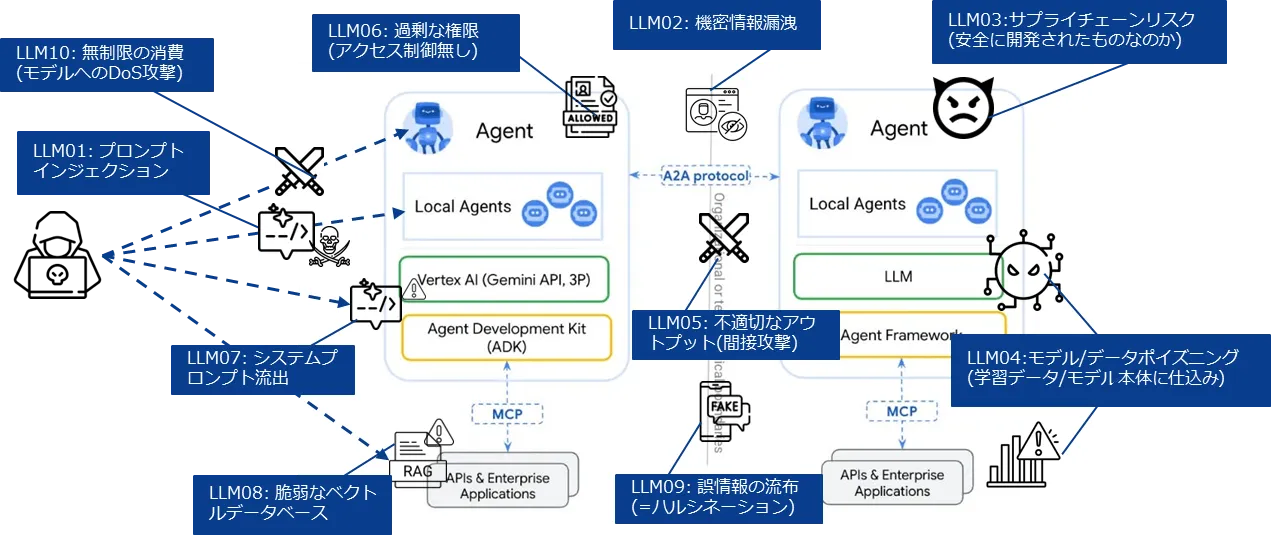
AIアプリケーションにおけるリスク
OWASP Top 10 for LLM
もはや定番?となりつつありますが、OWASP Top 10 for LLMには主要な攻撃やリスクについて上位10位の内容が公開されています。この内容をマルチエージェントに当てはめて考えていきたいと思います。SAIFでも15項目ほどリスクが定義されていますが、ほぼこの内容を包含したものになります。
| Top10内容 | 内容 | 対象 |
|---|---|---|
| LLM01: Prompt Injection | プロンプトを通じた攻撃、コンテンツフィルタリングの突破、個人/機密情報を聞きだす | プロンプト(Input Handling) |
| LLM02: Sensitive Information Disclosure | 個人/機密情報の漏洩を生成AIのアウトプットによって行われる | 出力結果(Output Handling) |
| LLM03: Supply Chain | 生成AIの学習/開発工程に脆弱性を含むデータやライブラリ、パッケージが含まれる、またはデプロイの仮定に含まれる | モデル/アプリケーション本体及び開発工程内のCIパイプライン,手動ビルド箇所、ソースコード等 |
| LLM04: Data and Model Poisoning | 学習データ/チューニングデータ、RAG/CAGに不正な情報や生成AIのコンプライアンスフィルタを突破するような情報を含ませモデルを改変する | モデル/学習,チューニングデータ/RAG,CAG |
| LLM05: Improper Output Handling | 生成AIのアウトプットを通じて外部連携システムに対して攻撃する、不正操作を行う | 出力結果(Output Handling)及び連携先アプリケーション |
| LLM06: Excessive Agency | 生成AIがアクセスするRAG/CAGや外部連携API、クラウドリソース等に過剰に認可を得てアクセスできてしまう | エージェント/プラグイン(外部連携ツール,RAG/CAG) |
| LLM07: System Prompt Leakage | 生成AIの初期指示を改変する事によりフィルタを突破したり、システムプロンプトに含まれた機密情報の漏洩がされてしまう | アプリケーション(モデルの初期呼び出し実装) |
| LLM08: Vector and Embedding Weakness | RAGに含まれるベクトル情報が取得されて情報漏洩に繋がったり、有害なコンテンツやモデル出力を操作するようなデータを混入させる | RAGデータベースそのものとその中身。広義にはCAGも対象。 |
| LLM09: Misinformation | いわゆるハルシネーション。ソースコードや法律、診療情報など重大な意思決定や本番稼働に関わる内容を過信してレビューしない | 出力結果(Output Handling) |
| LLM10: Unbounded Consumption | ユーザリクエストに制限を設けない事でトークンの過剰消費やDoSに繋がるアクセスが行われる | アプリケーション/Input Handling |
これをマルチエージェントに対して当てはめていくと以下のようになります。Input HandlingとOutput Handlingの対象が人間/AIエージェント間だけでなくAIエージェント同士にも適用されるようになります。そのため、LLM02,05,09のようなアウトプットに関わる内容にも目を向ける必要があります。
また、自分達の開発したAIエージェントが受けるセキュリティリスクはそのまま相手方のAIエージェントにも適用されます。つまり、LLM03のようにモデル開発の過程で攻撃や情報抽出を行うよう学習されたり、マルウェアをデプロイ時に含まれてしまうと間接的に接続先のAIエージェントが自分たちのAIエージェントに危害を加えてしまいます。
リスクへの対応
GoogleCloudで出来る対策案
各項目についてGoogleCloudで出来る案を考えていきたいと思います。Modelとのやり取りに関わる部分はModel Armorによってカバーできるものの、開発や学習タイミングでMLSecOpsといった新しいDevSecOpsの派生形、学習/推論に利用するデータやコンテキストなどに含まれるデータの内容を精査するDSPM(今後リリース予定)といった新しい観点が必要になります。
また、AIエージェントの質を損ねることはセキュリティリスクであるため、アウトプットの評価を定期的に実施し誤情報を防ぐ必要もあります。
| Top10内容 | 対象 | 対策 | GoogleCloudサービス |
|---|---|---|---|
| LLM01: Prompt Injection | プロンプト(Input Handling) | プロンプトフィルタリング/ガードレール定義 | Model Armor |
| LLM02: Sensitive Information Disclosure | 出力結果(Output Handling) | アウトプットフィルタリング | Model Armor |
| LLM03: Supply Chain | モデル/アプリケーション本体及び開発工程内のCIパイプライン,手動ビルド箇所、ソースコード等 | MLSecOps(SAST/SCA/DAST, Model/Artifactory Registry Scan, Evaluation, SBOM/MLBOM…etc) | Code Assist, Cloud Build, Artifact Registry Scan…等の予防, またSCCによるCNAPP(Posture Management/Threat Detection) |
| LLM04: Data and Model Poisoning | モデル/学習,チューニングデータ/RAG,CAG | DSPM/DLP(データ分類、暗号化、アクセス保護等) | Sensitive Data Protection, IAM, SCC DSPM(今秋リリース予定) |
| LLM05: Improper Output Handling | 出力結果(Output Handling)及び連携先アプリケーション | 連携先サービスへのWAF適用、外部エージェントからの通信フィルタリング | Cloud Armor/Model Armor |
| LLM06: Excessive Agency | エージェント/プラグイン(外部連携ツール,RAG/CAG) | 最小権限の原則,ID/リソースベースポリシー | IAM |
| LLM07: System Prompt Leakage | アプリケーション(モデルの初期呼び出し実装) | プロンプトフィルタリング及びエージェントコードスキャン | Code Assist, SASTによるソースコード内のシステムプロンプトスキャン,レビュー/ SCC CSPM |
| LLM08: Vector and Embedding Weakness | RAGデータベースそのものとその中身。 | データベースアクセス管理 | IAM |
| LLM09: Misinformation | 出力結果(Output Handling) | 定期的なモデルのアウトプット評価 | GenAI/GenKit Evaluation |
| LLM10: Unbounded Consumption | アプリケーション/Input Handling | フロントエンドに対するWAF、プロンプトに対するフィルタリング | Cloud Armor/Model Armor/Web Security Scanner |
SCCのサービス拡充とWiz買収による協業などまだ見えない部分も多くありますが、事前対策としてGoogleCloudで出来るものも多くあるため、出来るところから着手する、サードパーティー製品を考えてみるのも手だと思います。

まとめ
今回はSAIF/OWASPの観点を基にGoogleCloudで出来るAIエージェントセキュリティについて考えてみました。シングルエージェントであったり、自分たちが組んだエージェントだけであれば多くカバーできるのが分かりました。一方で、マルチエージェントが今後広がった際に、AIエージェントが接続する外部のAIエージェントやその接続に対してゼロトラストの考えを適用する必要があります。
Non Human Identityや今後リリースされるDSPMなどデータや認証/認可など、より責任共有モデルの上位レイヤーの対策も追加されていきます。トレンドを負いつつもそのリスクコントロールについても引き続きキャッチアップして記事を書きたいと思います。
Discussion