はじめに
Azure AI Foundryが提供するDeep Researchツールは、単なる検索エンジンではなく、情報の信頼性・関連性・最新性を評価し、構造化された回答を生成する高度なAIエージェント機能です。o3-deep-researchモデルとBing Groundingを組み合わせることで、専門家レベルの調査と分析を自動化できます。
背景と課題
Azure公式マニュアルのサンプルプログラムには、一回実行型のため対話の継続ができないという制約があります。
AzureのDeep Researchツールが、本来エージェントが持つべきユーザとの対話を通じて要件を明確化していく能力を持っているにも関わらず、公式サンプルでは「質問を投げて結果を受け取る」だけの単発処理になってしまっています。これでは、せっかくのインタラクティブな能力を活かせないという構造的な問題があります。
この記事で共有したいこと
そこで、Azure Deep ResearchとChainlitを組み合わせ、インタラクティブなチャット型アプリを作りました。
このアプリの実装を通じて得られたノウハウをお伝えしたいと思います。
- 長時間処理の安定化手法 ストリーミング処理の不安定性を検証し、ポーリングベースの実装で解決した経験と具体的な実装方法
- 対話型AIのUX設計 十数分かかる長時間処理における進捗表示と対話継続のUI設計
- 現実的なコスト感覚 実際の利用コスト
これらの知見は、Azure以外の技術スタックで長時間AI処理を扱う際にも応用可能な設計パターンとして活用いただけると思います。
Deep Researchとは?
Deep Research(ディープリサーチ)は、推論を使って大量のWeb情報を統合し、マルチステップの調査タスクで調査レポートを出力するAIエージェントです。従来のAIアシスタントが単発の質問応答に留まるのに対し、Deep Researchは複雑な調査プロセスを自律的に実行する点が特徴です。
現在、ChatGPT、Google Gemini、Perplexity、Gensparkなど、様々なベンダーが独自のDeep Researchツールを提供しています。また、オープンソースのDeep Research代替ツールも複数登場しており、この分野の競争が活発化しています。
Azure Deep Researchの特徴
そのなかで、AzureのDeep Researchツールは、OpenAI o3の高度な推論モデルをベースにweb browsingとdata analysisに最適化されたo3-deep-researchモデルを活用した高度な調査エージェントです。Bing SearchのWeb検索を組み合わせて複雑な調査プロセスを自律的に実行します。
私が実際に使って感じたAzureのDeepResearchツールの特長
私が実際に使って感じた良いと思ったのは以下の点です。
-
マルチステップワークフロー対応
反復的な情報収集、情報の関連付けと構造化などが既に内部実装されている。オープンソースのDeep Researchではこれらの仕組みをフローとして実装するため、複雑な構成となる。 -
ユーザ質問の曖昧さ解消
ユーザが漠然としたリクエストを投げても、エージェントが追加質問や仮定提示を通じて明確な調査課題に変換するステップが既に実装されている。オープンソースのDeep Researchではこの仕組みが含まれていないことがある。
Azure Deep Researchサンプルプログラムの構成
セットアップ
今回ご紹介するサンプルプログラムの実装は、以下の手順で行います。
- 初期構成: Azure AI Foundry上でDeep Researchツールを構成
-
エージェント作成: サンプルプログラムの
create_agent.pyを実行。Azure AI Foundryの画面から設定内容を確認 - 動作確認: Chainlit画面で動作確認
詳細な構築手順については、サンプルプログラムGitHubリポジトリのREADMEおよび公式マニュアルを参照してください。
公式マニュアルでは「コードのみのリリース」と記載されていますが、これはDeep Researchツールの初期構成段階を指しています。プログラムでDeep Researchツールを作成した後は、Azure AI Foundryの画面からエージェントの確認やプロンプトの編集が可能です。
サンプルプログラムではcreate_agent.pyを実行すると、Azure AI Foundryの画面からエージェントの設定やプロンプトの確認・編集ができるようになります。

Azure AI Foundryの画面例
Azure上の構成
Deep Researchの実態は、Azure AI FoundryのAIエージェントとDeep Researchツールの組み合わせです。
- Deep Researchツール エージェントが使用するツールで、内部でo3-deep-researchモデルとBing Groundingを活用
-
AIエージェント Deep Researchツールを使用するエージェント(ベースのLLMモデルは
create_agent.pyでエージェント作成時に指定。本実装ではgpt-4.1)
つまり、AIエージェント(gpt-4.1,gpt-4o等)がDeep Researchツールを呼び出し、そのツール内部でo3-deep-researchモデルによる高度な推論とBing Groundingによる情報収集が実行される構成になっています。

Azure Deep Researchの構成
APIインターフェース
上記の通り、Deep Researchツールは、Azure AI FoundryのAIエージェントが使うツールという位置づけのため、このエージェントへのアクセスは、Azure AI FoundryのSDK、APIが使用できます。これは通常のAzure AI Foundryエージェントを呼び出す際と同じインターフェースです。
SDKの詳細は公式マニュアルを参照してください。
DeepResearch実行プロセスの詳細分析
内部処理プロセスの分析
サンプルプログラムを実行すると、Deep Researchは内部で段階的なプロセスを実行し、それに応じてChainlit画面に進捗が表示されます。
実際に複数回実行して観察した結果、Deep Researchは内部で以下のような段階的なプロセスを実行していることが分かりました。
フェーズ1:課題定義・スコープ設定
- 目的: ユーザの漠然とした質問を具体的な調査課題に変換
- 処理内容:
質問の範囲、深度、対象期間などを特定
不明確な部分について追加質問を生成
ユーザとの対話を通じて調査の方向性を確定 - 特徴: この段階でユーザとのインタラクションが発生するため、対話型UIが必須
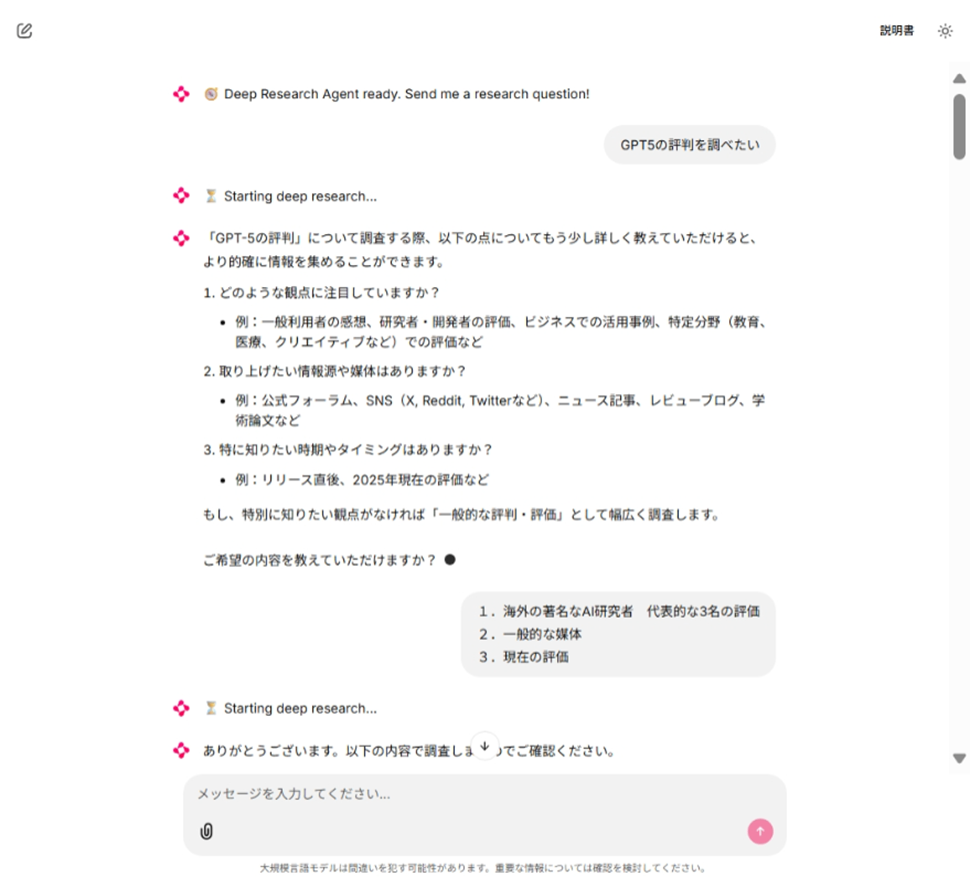
画面例1
フェーズ2:初期検索と情報収集
- 目的: 基礎となる情報を幅広く収集
- 処理内容:
要件に基づいて複数の検索クエリを自動生成(例:人物×観点、出来事×時期、モデル×能力)
Bing Groundingを使用してWeb検索を実行
収集した情報の信頼性と関連性を初期評価 - 特徴: 単一のキーワード検索ではなく、多角的なアプローチで情報収集

画面例2
フェーズ3:深掘りと構造化
- 目的: 初期収集情報から新たな疑問点を抽出し、追加調査を実行
- 処理内容:
追加で必要な情報領域を判断
論理的な関連性に基づいて情報を構造化 - 特徴: 人間の調査プロセスに近い反復的な深掘り

画面例3
フェーズ4:回答生成とレビュー
- 目的: 収集・分析した情報を統合し、高品質なレポートを生成
- 処理内容:
重要度に基づく情報の優先順位付け
出典と根拠を明示した論理的な回答構築
内容の整合性と完全性をレビュー - 特徴: 単純な情報の羅列ではなく、分析的な視点での統合

画面例4

画面例5

画面例6
処理時間の特徴
処理時間は、質問の複雑さや関連情報の量にもよりますが、個人的なテストでは概ね以下の通りでした。
- 全体の処理時間: 通常10〜20分程度
- 最も時間がかかるフェーズ: フェーズ2とフェーズ3(情報収集と深掘り)
この長時間処理という特性が、後述する技術的な実装上の課題(ストリーミング vs ポーリング)に直結することになります。
利用コストの実測値
Azure Deep Researchの利用コストは、o3-deep-research、エージェント用のgpt-4o/4.1、Bing Groundingの3つのコンポーネントで構成されます。
o3-deep-researchの詳細料金はAzure公式ブログを参照してください。
実際に動かしてみたところ、以下のような結果となりました。調査の複雑さや生成される報告書の長さにより、コストは変動します。
実測コストの一例
- 処理時間:約18分の調査タスク
- 総コスト:$9.94(約1,500円) (注)2025年8月時点の実績値です。
- 内訳:o3-deep-research、gpt-4.1、Bing Grounding
Deep Researchアプリの設計における考慮点と技術的実装
1. Chainlitによるインタラクティブな画面との統合
Deep Researchの特徴であるユーザ質問の曖昧さ解消と要件明確化には、対話機能が必須です。そこで、簡単にチャット型UIを構築できるChainlitを選択しました。
Chainlitの利点
- 迅速な開発: WebベースのチャットUIを数行のコードで実装可能
- リアルタイム更新: ストリーミング形式での逐次表示に対応
- セッション管理: ユーザごとの会話履歴と状態管理が容易
2. 長時間処理における安定的なポーリングベース実装
ストリーミング処理の問題点
公式マニュアルのサンプルプログラムは同期型の実装であり、非同期型で実装する場合、公式マニュアルでもストリーミング処理は非推奨とされています。
実際にruns.streamでストリーミング処理を検証したところ、20回のテストで19回が失敗という結果になりました。
失敗のパターン
- レポート作成段階での接続エラーが多発
- Azure AI FoundryのPlaygroundでも類似のエラーが発生(ただし、より早い段階で失敗)
ポーリングベース実装の採用
そこで、runs.createにより処理開始し、runs.getによるポーリングで進捗確認するポーリング形式で実装しました。
# ポーリング設定
POLL_INTERVAL_SEC = float(os.environ.get("POLL_INTERVAL_SEC", "1.5"))
RUN_TIMEOUT_SEC = int(os.environ.get("RUN_TIMEOUT_SEC", "1800")) # 30 minutes
# ステータス監視
run = agents_client.runs.get(...)
# Check if run is still in progress
if run.status in ("queued", "in_progress"):
# 処理継続
if run.status == "failed":
# エラー処理
この実装により、長時間処理でもエラーになることがなくなりました。
重要なポイント
長時間の非同期AI処理にはストリーミングは安定しないため、ポーリングベースで実装すべきです。
3. 処理時間が長いため、進捗表示と通知機能を実装
進捗表示の仕組み
Deep Researchは10〜20分の処理時間を要するため、ユーザが処理状況を把握できる進捗表示が必要不可欠です。
実装方法
-
テキストベース更新: プログレスバーではなく、
status_msg.stream_token()を使った逐次テキスト更新 -
段階的情報表示:
cot_summaryブロックやURL Citation行を逐次出力 -
最終結果の分離表示:
_display_final_resultsで別メッセージパネルに結果を表示
# Extract cot_summary blocks
# cot_summary取得処理
cot_block = f"cot_summary: {cot_content}"
if cot_block not in emitted_cot_set:
await status_msg.stream_token("\n\n-----\n" + cot_block)
タイムアウト管理
30分のタイムアウト設定により、無限待機を防止しました。調査が長引いてこのタイマーで終了してしまうことがあったので、もう少し長く設定してもよいかもしれません。
if time.time() - start_time > timeout_sec:
await status_msg.stream_token("\n⚠️ Timeout exceeded.")
break
制約事項
現状、ユーザによる処理キャンセル機能は実装していません。セッション内でのRunID管理は行っていますが、runs.cancel相当の処理は未実装です。
4. 出典・引用情報の適切な管理
出典情報の取得方法
回答の信頼性確保のため、出典情報はプロンプト指示ではなく、APIから直接取得して重複除去処理を実装し、レポート末尾に追加する方式を採用しました。
# Display references
if final_message.url_citation_annotations:
seen_urls = set()
references = []
for ann in final_message.url_citation_annotations:
url = ann.url_citation.url
title = ann.url_citation.title or url
if url not in seen_urls:
references.append(f"- [{title}]({url})")
seen_urls.add(url)
if references:
await output_msg.stream_token("\n\n### References\n" + "\n".join(references))
今後の改善課題
レポート内の引用番号と末尾の出典一覧の番号を対応させる機能は、今後の改善事項として残されています。
まとめ
Azure Deep ResearchとChainlitを組み合わせることで、長時間処理を前提とした対話型AIエージェントを実運用レベルで構築できることを実証しました。検証の結果、以下の3つの設計のポイントを軸にすることで、実運用レベルに耐える品質に近づけることができます。
これらの設計原則を踏まえた実装・運用により、Azure以外の技術スタックでも応用可能な汎用的な設計パターンとして活用できると思います。
設計のポイント
1. 安定性:長時間処理の安定化
ストリーミング処理の検証では、20回のテストで19回が失敗という明確な結果が得られ、単なる推測ではなく実際の検証に基づいて技術判断をしました。
Azure AI Foundryの長時間処理においては、ポーリングベースのアプローチが実用的な安定性を提供することを確認できました。
これは、他のクラウドAIサービスや長時間AI処理を扱う際にも応用可能な、重要な非同期処理パターンといえます。
2. ユーザビリティ:対話型AIのUX設計
AIの高度な能力も、適切なユーザインターフェースがなければ価値を発揮できません。本実装では以下の要素が実用性を大きく左右することを確認しました。
- 質問の曖昧性解消: エージェントとの対話による要件明確化
-
進捗の可視化:
stream_tokenによる逐次テキスト更新 -
出典情報のAPI取得と構造化表示: 出典情報のAPIからの取得と整理
特に、Deep Researchのような複雑な調査プロセスでは、単発の質問応答ではなく、継続的な対話を通じた要件精緻化が重要です。
3. コスト効率:現実的なコスト設計
o3-deep-researchの利用コスト(1回1500円〜3000円)は決して安くありません。しかし、専門的な調査を人手で行う場合の時間コスト(数時間〜数日)と比較すると、十分に競争力のある価格帯かもしれません。重要なのは、このコスト構造を理解した上で適切な利用場面を選択することです。
エンジニアリングの重要性
この実装を通じて痛感したのは、AIの能力向上と同様に、それを実用的なサービスとして提供するためのエンジニアリングの重要性です。AI技術の可能性を現実的な価値に変換するためには
- 実証的な検証: 理論だけではなく実際の動作確認に基づく技術選択
-
ユーザ体験の設計: AIの能力を最大限引き出すインターフェース設計
が必要です。
AI技術の進歩により、今後さらに高度な調査・分析エージェントが登場するかもしれませんが、その際も、本記事で紹介した設計原則—安定性、ユーザビリティ、コスト効率性—は変わらず重要な要素として活用できるのではと思います。
Discussion