はじめに
自然言語処理(NLP)の分野において、**文埋め込み(Sentence Embeddings)**は文章の意味を数値ベクトルで表現する重要な技術です。本記事では、Sentence-Transformersライブラリを使用して日本語文章の埋め込みを計算し、UMAPによる次元削減、クラスタリング分析、そしてTensorBoard Projectorを用いたインタラクティブな可視化までの一連のワークフローを実践的に解説します。
🎯 この記事で学べること
- Sentence-Transformersを使った多言語文埋め込みの基礎
- UMAPによる高次元データの可視化手法
- 複数のクラスタリング手法(K-Means、DBSCAN、階層クラスタリング)の比較
- TensorBoard Projectorを使ったインタラクティブな埋め込み空間の探索
- 日本語文章データに対する実践的な分析手法
技術スタック
本プロジェクトで使用する主要なライブラリ:
sentence-transformers>=5.1.0 # 多言語文埋め込みモデル
umap-learn>=0.5.9 # 次元削減アルゴリズム
tensorflow>=2.20.0 # TensorBoard Projector連携
matplotlib>=3.10.6 # データ可視化
japanize-matplotlib>=1.1.3 # 日本語フォント対応
scikit-learn # クラスタリングアルゴリズム
numpy>=2.2 # 数値計算基盤
プロジェクト概要
今回のプロジェクトでは、100個の日本語文章を11のカテゴリー(技術、自然、金融、文化、健康、環境、キャリア、日常生活など)に分類し、以下の分析を行います:
- 文埋め込み計算: paraphrase-multilingual-MiniLM-L12-v2モデルによる384次元ベクトル化
- 次元削減: UMAPアルゴリズムで2次元に圧縮
- クラスタリング分析: 複数手法の比較とシルエット係数による評価
- 可視化: matplotlibによる散布図とクラスター別色分け
- インタラクティブ探索: TensorBoard Projectorでの3D可視化
実装のハイライト
1. 多言語対応の文埋め込み
from sentence_transformers import SentenceTransformer
# 多言語対応の軽量モデルを使用
model = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2")
# 文章をベクトル化(正規化済み)
embeddings = model.encode(sentences, normalize_embeddings=True)
ポイント: normalize_embeddings=Trueにより、後のコサイン類似度計算が内積で簡単に行えます。
モデル選択の判断基準
| モデル | 次元数 | 特徴 | 適用場面 |
|---|---|---|---|
| paraphrase-multilingual-MiniLM-L12-v2 | 384 | 多言語対応、軽量 | 日英混合テキスト |
| all-MiniLM-L6-v2 | 384 | 英語特化、高速 | 英語専用アプリ |
| all-mpnet-base-v2 | 768 | 高精度、重め | 品質重視のタスク |
2. UMAPによる効果的な次元削減
import umap
reducer = umap.UMAP(
n_neighbors=15, # 局所的な構造を保持
min_dist=0.1, # 点の最小距離
metric="cosine", # コサイン距離を使用
random_state=42
)
embeddings_2d = reducer.fit_transform(embeddings)
設計判断: コサイン距離は文章の意味的類似性に適しており、テキストデータの次元削減において優れた結果を示します。
🗺️ UMAPとは?
UMAP(Uniform Manifold Approximation and Projection) は、高次元データを低次元(通常2Dや3D)に変換する次元削減技術です。
なぜ次元削減が必要?
文埋め込みは通常384次元や768次元といった高次元ベクトルです。人間の目では384次元の空間を理解できないため、2次元の散布図に変換して可視化する必要があります。
UMAPの特徴
- 局所構造の保持: 似ている文章同士は変換後も近くに配置される
- 高速処理: 大量のデータでも比較的短時間で処理完了
- 非線形変換: 複雑な構造も適切に2次元に投影可能
パラメータの意味
-
n_neighbors=15: 近傍の点をいくつ考慮するか(大きいほど大域的構造重視) -
min_dist=0.1: 変換後の点同士の最小距離(小さいほど密集した配置) -
metric="cosine": 文章の類似度測定にコサイン距離を使用
簡単に言うと、UMAPは「意味が似ている文章を近くに、違う文章を遠くに配置する魔法の地図作り」です。
3. 複数クラスタリング手法の自動比較
本プロジェクトでは、4つの異なるクラスタリング手法を自動で比較し、シルエット係数に基づいて最適な手法を選択します:
clustering_methods = {
"K-Means (8クラスター)": ("kmeans", 8),
"K-Means (10クラスター)": ("kmeans", 10),
"DBSCAN (自動クラスター数)": ("dbscan", None),
"階層クラスタリング (8クラスター)": ("hierarchical", 8)
}
📈 シルエット係数とは?
シルエット係数(Silhouette Score) は、クラスタリングの品質を測る指標です。簡単に言うと、「同じクラスター内の点がどれだけ密集しているか」と「異なるクラスター間がどれだけ離れているか」を数値で表したものです。
- 値の範囲: -1.0 ~ 1.0
- 1.0に近い: 理想的なクラスタリング(同じグループ内は密集、異なるグループ間は離れている)
- 0.0付近: 曖昧なクラスタリング(境界が不明確)
- 負の値: 不適切なクラスタリング(間違ったグループに分類されている可能性)
例えば、機械学習の文章と料理の文章が明確に分かれていれば高いスコア、混在していれば低いスコアになります。
クラスタリングの結果(例)
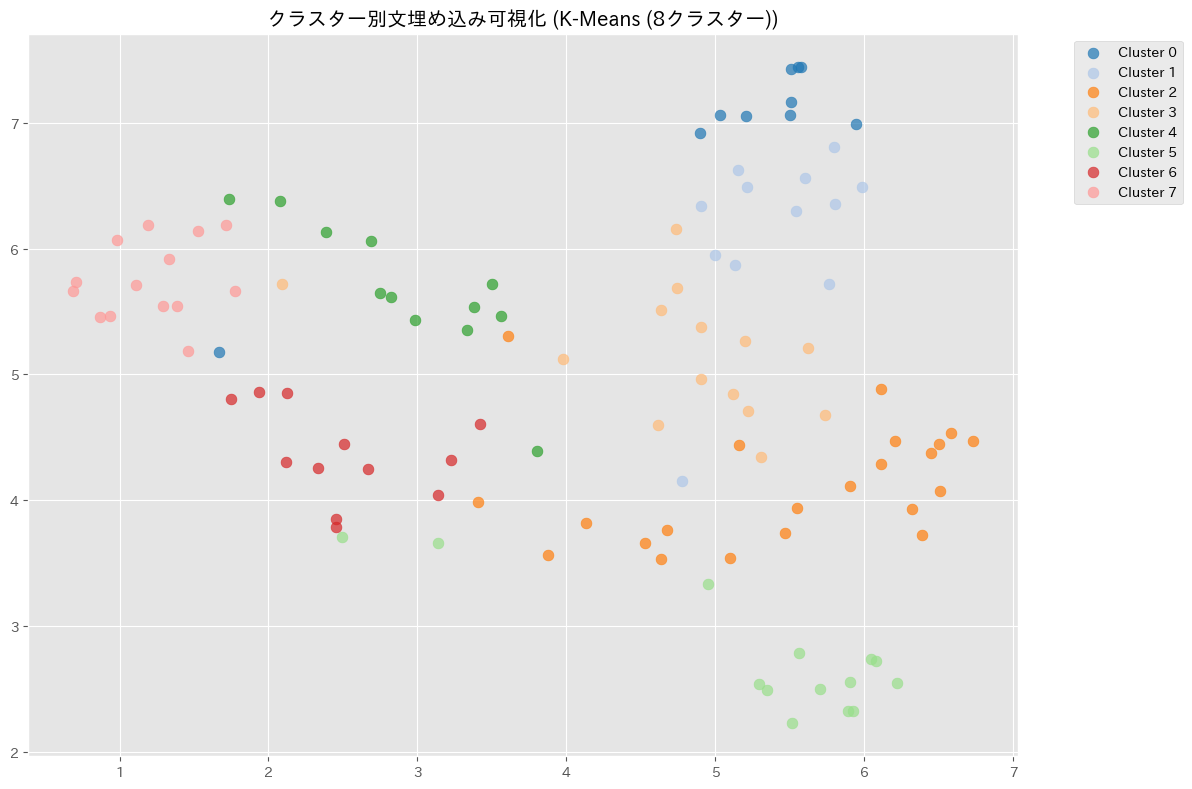
4. TensorBoard Projectorとの連携
TensorBoard Projectorを使用することで、ブラウザ上でインタラクティブな3D可視化が可能になります:
import tensorflow as tf
from tensorboard.plugins import projector
# 埋め込みをTensorFlow Variableとして保存
emb_var = tf.Variable(embeddings, name="sentence_embeddings")
ckpt = tf.train.Checkpoint(embedding=emb_var)
ckpt.save("logs/embeddings/embedding.ckpt")
# メタデータ(文章+クラスター情報)を保存
with open("logs/embeddings/metadata.tsv", "w") as f:
f.write("sentence\tcluster\n")
for sentence, cluster_id in zip(sentences, cluster_labels):
f.write(f"{sentence}\t{cluster_id}\n")
5. TensorBoard Projectorでのインタラクティブ可視化
TensorBoard Projectorを使用することで、ブラウザ上で埋め込み空間をインタラクティブに探索できます。以下に詳細な手順と確認ポイントを示します。
🚀 TensorBoard起動手順
-
ターミナルでTensorBoardを起動
tensorboard --logdir=logs/st_embeddingsuvを利用する場合はuv run tensorboard --logdir=logs/st_embeddings -
ブラウザでアクセス
http://localhost:6006 -
Projectorタブに移動
- 上部メニューから「PROJECTOR」タブをクリック
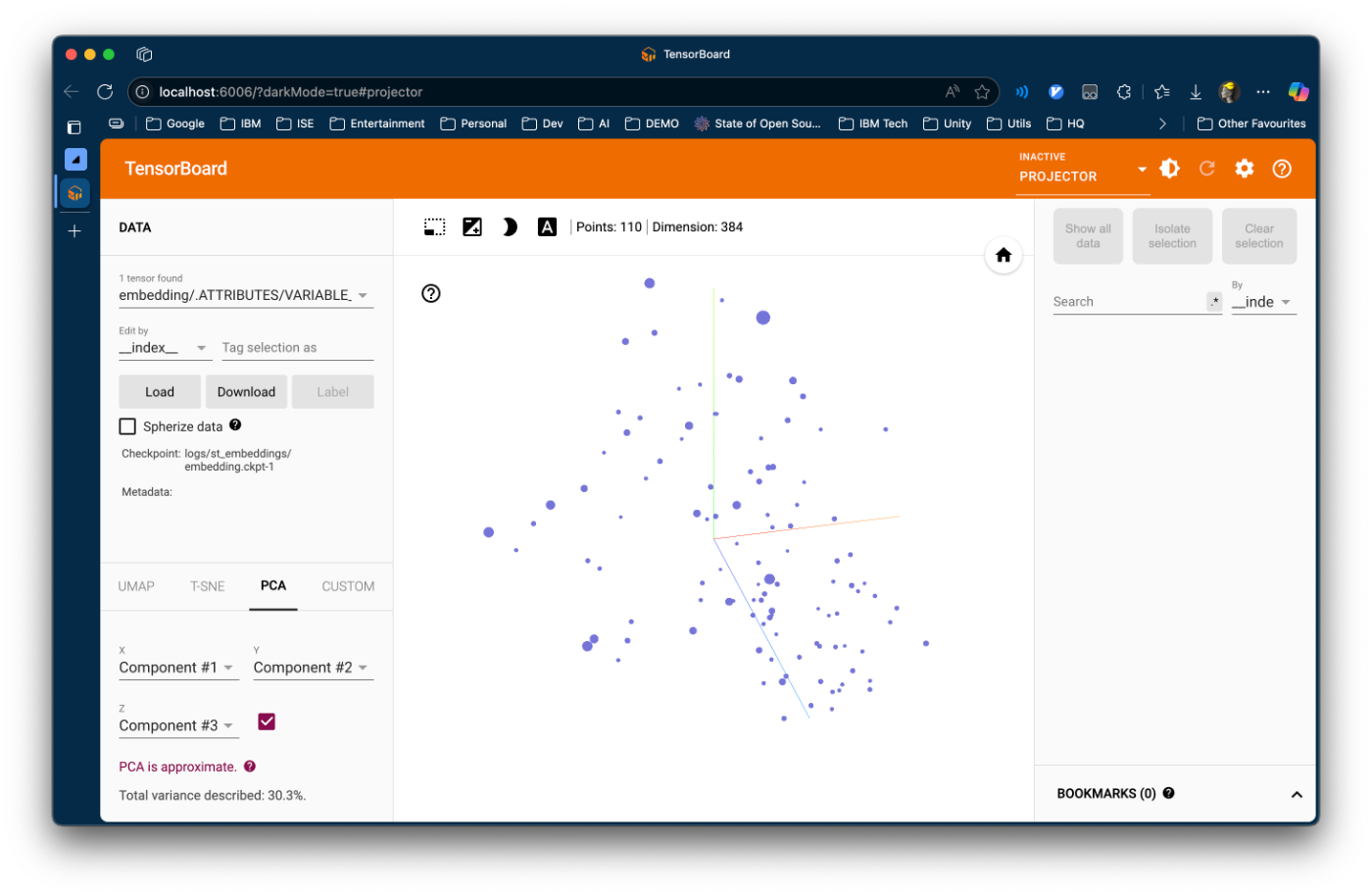
-
文字列を登録
- 左にある
Loadをクリックし、出力されたmetadata.tsvをアップロード
- 左にある

-
データの可視化
- テキストと頂点が可視化されていることを確認する

📊 TensorBoard Projectorの操作方法
- 回転: マウスドラッグで3D空間を自由に回転
- ズーム: マウスホイールまたはピンチ操作
- パン: Shiftキー + ドラッグで視点移動
可視化設定
-
次元削減手法の選択:
- PCA: 主成分分析による線形変換
- t-SNE: 非線形次元削減(局所構造重視)
- UMAP: 大域・局所構造のバランス(推奨)
データ探索機能
- 点の選択: 個別の文章をクリックして詳細確認
- 近傍検索: 選択した点に似ている文章を自動表示
- クラスター情報: メタデータでクラスター分類を色分け表示
可視化結果は以下の観点でスクリーンショットを保存することをお勧めします:
- 全体俯瞰図: 全クラスターの配置状況
- クラスター詳細: 特定クラスターの拡大表示
- 類似性確認: 選択した文章の近傍点ハイライト
この可視化により、文埋め込みモデルの性能を直感的に理解し、クラスタリング結果の妥当性を視覚的に検証できます。
まとめ
本記事では、Sentence-Transformersを用いた日本語文埋め込みの包括的なワークフローを実装しました。UMAPによる次元削減、複数のクラスタリング手法の比較、TensorBoard Projectorでのインタラクティブ可視化という一連の流れにより、文章の意味的構造を多角的に分析することができました。
このアプローチは、文書分類、類似文章検索、コンテンツ推薦など、様々な実用的アプリケーションの基盤となる技術です。また、可視化と定量的評価を組み合わせることで、モデルの動作を直感的に理解し、改善点を特定することが可能になります。
Github Repo
以下のgithub repoを参考にしてください。

Discussion