Information Retrieval | 08 Evaluation in information retrieval
この章のまとめ
- 情報検索の評価は、IRシステムの効果を測定し、適切なテクニックを選択するための重要なプロセスである。
- 評価のためには、有効なテストコレクションを使用し、関連文書と非関連文書を区別する方法やラン- キングされた検索結果を評価する手法が必要である。
- ユーザーの効用は、ユーザーの幸福度や満足度を測定し、システムの品質を評価するための重要な尺度である。
- ユーザーの効用は、検索結果の関連性だけでなく、ユーザーインターフェースのレイアウトや応答性などの要素にも影響される可能性がある。
Information retrieval system evaluation
標準的な方法でアドホック情報検索の有効性を測定するには、次の3つの要素からなるテストコレクションが必要。
- 文書コレクション
- クエリとして表現可能な情報ニーズのテストスイート
- 各クエリ-文書ペアに対する関連性判定、標準的には関連または非関連のバイナリ評価
Gold Standard Judgement (Ground Truth Judgement)
- 情報システムの評価は関連性で判定される。
- テストコレクション内の文書は、ユーザーの情報ニーズに関連するかどうかのバイナリ分類が与えられる。
- この判定は、関連性のGold StandardまたはGround Truth判定と呼ばれる。
- テスト文書コレクションと情報ニーズのテストスイートは、合理的なサイズである必要がある。
- 一般的な目安として、50個の情報ニーズは通常、十分な最小限であると考えられている。
- 文書の関連性は、クエリではなく情報ニーズに対して評価される。
- 単にクエリ内のすべての単語を含んでいるからといって関連しているわけではない。
- したがってシステムを評価するには、情報ニーズの明確な表現が必要。
- まずは関連性をバイナリ値(関連する or 関連しない)のみを取り扱う。
- 関連性はスケールでも評価可能。
パラメータの適切な調整方法
- 多くのシステムには、システムのパフォーマンスを調整するために調整できるさまざまな重み(パラメータとしてしばしば知られる)が含まれている。
- チューニング用のコレクション上でパラメータを調整し、システムの評価は別のコレクションを用いる。
- パラメータの調整にあたっては、1つ以上の開発テストコレクションを持ち、パラメータをその開発テストコレクションでチューニングする。
- テスターはそれらの重みでテストコレクションに対してシステムを実行し、その結果をパフォーマンスの不偏推定値として報告する。
Standard test collections
標準的なテストコレクションは、情報検索システムの評価に使用される一連のテストコレクションであり、次のようなものがあります。
1. Cranfieldコレクション
- 情報検索効果の定量的な測定を可能にする先駆的なテストコレクション
- 1950年代後半からイギリスで収集された
- このコレクションには1398件の航空力学ジャーナル記事の要約、225件のクエリ、およびすべての(クエリ、文書)ペアの徹底的な関連性判断が含まれる。
2. Text Retrieval Conference(TREC)
- アメリカ国立標準技術研究所(NIST)が1992年以来、大規模なIRテストベッド評価シリーズを実施して収集されたテストコレクション。
- 最もよく知られているのはTREC Ad Hocトラック
- 1992年から1999年の最初の8回のTREC評価に使用されたもの。
- これらのテストコレクションには、6枚のCDに1.89百万のドキュメント(主に、新聞記事)が含まれており、450の情報ニーズに対する関連性判断が含まれる。
- 各テストコレクションは、このデータの異なるサブセットに定義される。
3. NII情報検索システム(NTCIR)のテストコレクション
- TRECコレクションと同様のサイズのさまざまなテストコレクション
- 東アジア言語とクロス言語情報検索に焦点を当てている。
4. Cross Language Evaluation Forum(CLEF)
ヨーロッパ言語とクロス言語情報検索に焦点を当てた評価シリーズ。
5. Reuters-RCV1
テキスト分類において、最も使用されているテストコレクションの1つ。
6. 20 Newsgroups
さまざまなニュースグループからの記事を含むテキスト分類コレクションで、広く使用されている。
Evaluation of unranked retrieval sets
非ランク付け検索セットの評価では、精度と再現率という2つの基本的な尺度が使用されます。精度は、検索された文書のうち関連性のある文書の割合を示し、再現率は、関連性のある文書のうち検索された文書の割合を示します。
Precision(精度)
精度は、次の式で表されます。
Recall(再現率)
- 関連する文書のうち、システムが正しく取得できた割合
再現率は、次の式で表されます。
Recall = \frac{\text{全検索文書数}}{\text{関連する文書数}} = P(全検索文書数|関連する文書数)
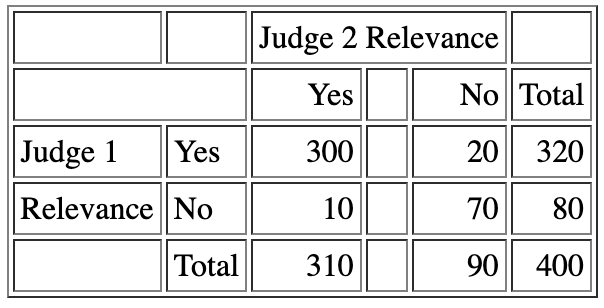
Contigency Table
これらの尺度は、以下のような対応表を見ることで明確になります。
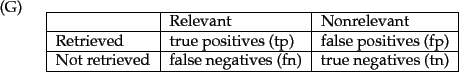
PrecisionとRecallのトレードオフ関係
- 精度と再現率は、一般的に互いにトレードオフの関係にある。
- 典型的なウェブユーザーは、最初のページのすべての検索結果が関連していることを望むが、関連のあるすべての文書を知ることや見ることには興味はない。
- 一方で、法律事務助手や情報分析家などの専門家は、可能な限り高い再現率を得ることに関心があり、それを得るためには比較的低い精度の結果を許容します。
F measure 〜PrecisionとRecallのバランスをとる尺度〜
-
精度と再現率のバランスを取るための単一の尺度として、F mearusreがある。
- 精度と再現率の加重調和平均であり、以下の式で表される。
-
\alpha \alpha\in[0,1] \beta \beta^2\in[0, \infty]
F = {{\frac{1}{\alpha\frac{1}{P} + (1-\alpha)\frac{1}{R}} }}\\where \quad \beta^2 = \frac{1-\alpha}{\alpha}
-
- 精度と再現率の加重調和平均であり、以下の式で表される。
-
バランスの取れたF尺度は以下の
F_1 F_{\beta=1}
F_{\beta=1} = \frac{2PR}{P+R} - 精度と再現率を等しく重視。
- つまり、
\alpha = 1/2 \beta = 1
- つまり、
-
\alpha
- 精度と再現率を等しく重視。
\beta
- 均等な重み付け(すなわち、
\alpha = 1/2 \beta = 1 -
\beta < 1 -
\beta > 1 - 再現率を強調したい場合には、
\beta=3 \beta=5
- 再現率を強調したい場合には、
-
調和平均の利用
-
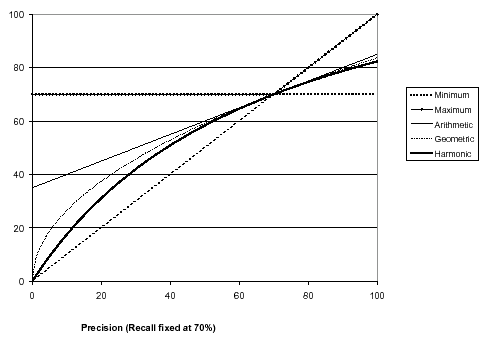
このグラフは、ハーモニック平均を他の平均と比較。
- このグラフは、再現率が70%の固定値の下で、精度と再現率の各種平均を比較。
- ハーモニック平均は、再現率と精度の2つの指標の平均を取る方法の1つ。
- 再現率は、関連する文書のうち、システムが正しく取得できた割合を示し、
- 精度はシステムが取得した文書のうち、実際に関連する文書の割合を示す。
- ハーモニック平均は、再現率と精度の2つの指標の平均を取る方法の1つ。
- このグラフは、再現率が70%の固定値の下で、精度と再現率の各種平均を比較。
-
ハーモニック平均は、極端な値に引きずられることなく、データセット全体の特徴をより正確に表す。
ハーモニック平均が極端な値に対してより敏感 -
なぜハーモニック平均が他の平均と比較して使われるのか、理解するためには、ハーモニック平均と算術平均の違いを考える必要がある。
- 算術平均は、値を合計して個数で割る単純な方法。
- ハーモニック平均は、値の逆数を取り、その逆数の平均して、その結果の逆数を計算する方法。
- ハーモニック平均の特徴
- 個々の要素の値が近い場合に高い値を示す。
- 個々の要素の値の差が大きい場合には低い値を示す。
- 特に極端な値が含まれるデータセットで有効。
- ハーモニック平均の特徴
Evaluation of ranked retrieval results
- 検索エンジンのランク付けされた検索結果を評価する方法について説明。
- 特に、精度(Precision)、再現率(Recall)、F値(F Measure)、平均精度(MAP: Mean Average Precision)、R-精度(R-Precision)、ROC曲線(ROC Curve)、および正規化割引累積利得(NDCG: Normalized Discounted Cumulative Gain)などの評価指標に焦点を当てる。
- これらの指標は、検索エンジンや情報検索システムの性能を評価し、比較するために広く使用されている。
- 各指標は、システムがどのように関連性のある情報を効果的に見つけ出し、提供できるかを異なる視点から測定する。
精度(Precision)と再現率(Recall)
- 精度(Precision)
- 検索結果のうち、関連性があると正しく判断されたドキュメントの割合。
- 再現率(Recall)
- 関連性のあるドキュメント全体に占める、検索結果に含まれる関連ドキュメントの割合。
- これらは通常、セットベースの指標として計算されますが、ランク付けされた検索結果の評価には、これらを拡張するか、新しい指標を定義する必要がある。
Precision-Recall Curves(精度-再現率曲線)
- 精度、再現率、F値はセットベースの指標です。これらは、ランク付けされていないドキュメントのセットを使って計算される。
- 検索エンジンで標準となっているランク付けされた検索結果を評価するためには、これらの指標を拡張するか、新しい指標を定義する必要がある。
- ランク付けされた検索の文脈では、適切な検索ドキュメントのセットは自然と上位k件の検索ドキュメントによって与えられる。
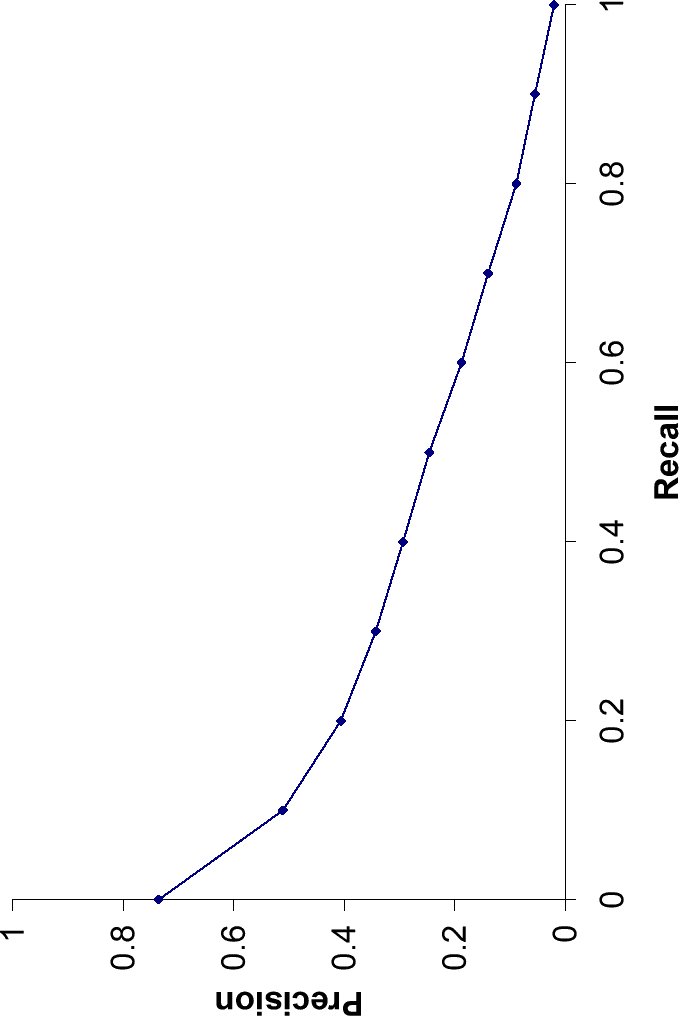
- 各セットに対して、精度と再現率の値をプロットすることで、図8.2に示されるような精度-再現率曲線を描くことができる。
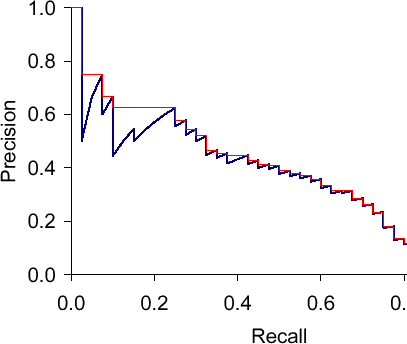
- 精度-再現率曲線は特徴的なのこぎり歯の形をしています
- もし
(k+1) k - もし
(k+1)
- もし
interpolated precision(補間精度)
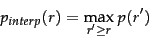
- 上記の変動を取り除くことはしばしば有用
- 変動の除外を行う標準的な方法は**interpolated precision(補間精度)**を用いること
- ある再現率レベル
r p_{interp} r' \ge r - 例:再現度が0.1の時に精度が0.4、再現度が0.3の時に精度が0.6の場合、再現度が0.1の時の補間精度は0.6となる。(注.再現度が0.3以上の時に精度が0.6を上回らないとする。)
- ある再現率レベル
平均精度(Mean Average Precision / MAP)
平均精度(MAP: Mean Average Precision)は、情報検索システムや検索エンジンの性能を評価するために用いられる重要な指標の一つです。MAPは特に、システムがどの程度効率的に関連するドキュメントを識別し、ランク付けできるかを測定するために使用されます。この指標は、複数のクエリや情報ニーズにわたるシステムの平均的な精度を反映します。
MAPの計算方法
- MAPは特に複数のクエリを扱う際の性能のバランスを考慮した指標であり、システムの全体的な効果を評価するのに適している。
- MAPは最大1。1に近いほど検索精度が高いといえる。
- 関連ドキュメントが検索結果の上位に集中する程、MAPの値は1に近づく。
-
Q -
|Q| -
m_j j -
R_{jk} j k - 通常、集合
R_{jk}
- 通常、集合
-
{Precision}(R_{jk}) k \text{Precision}(R_{jk}) = \frac{\text{k(=k番目の関連ドキュメント)}}{R_{jk}に含まれる文書数}
-
MAPを計算するには、まず各クエリについて平均精度(AP: Average Precision)を計算し、それからそのAPの平均を取ります。
- APの計算
-
\frac{1}{m_j} \sum_{k=1}^{m_j} \text{Precision}(R_{jk}) - この平均精度は、その時点までに見つかった関連ドキュメントの数
k k - あるクエリに対して、関連するドキュメントが検索結果のリストのどの位置にあるかを見ていく。各関連ドキュメントが見つかるたびに、その時点での精度(その時点までに見つかった関連ドキュメントの数を、その時点までの全ドキュメントの数で割った値)を計算
- 平均精度は、この精度を平均している(=
m_{j}
- この平均精度は、その時点までに見つかった関連ドキュメントの数
-
- APを平均化してMAPを算出
- すべてのクエリについてこの平均精度(AP)を計算し、これらの平均精度の算術平均を取ることでMAPを求める。
- APの計算
MAPの解釈
- 関連するドキュメントがまったく検索されなかった場合、上記の式での精度値は0とされます。
- 個々の情報ニーズに対して、平均精度は補間されていない精度-再現率曲線の下の面積を近似し、したがってMAP(Mean Average Precision:平均平均精度)はクエリセットに対する精度-再現率曲線の下の平均面積と大まかに一致します
- 上記の指標は、すべての再現率レベルでの精度を考慮。つまり、全ての関連するドキュメントについて、それぞれが検索結果リストに現れる各時点での精度を計算。
- しかし、ユーザーにとって重要なのは最初のページや最初の3ページにどれだけの良い結果があるか。つまり、検索結果上位の精度が重要。検索結果全体で検索システムを評価する意義は小さい。(注:MAPは関連する文書が上位に集中する程値が高くなるので、間接的には文書の関連度による順位づけを考慮して評価している。)
- これは、「Precision at
k - 「Precision at
k
MAPの観察から得られる示唆
MAPの結果を観察すると以下の傾向ががみえてくる。これが示唆するものは、情報検索システムの評価を行う際には、テスト情報ニーズのセットが十分に大きく多様であることが重要。テストセットが偏っていると、システムの実際の性能を正確に反映できないため、幅広いクエリをカバーすることで、より公平かつ正確な評価が可能になる。
-
同一情報ニーズに対して異なるシステム間でMAPスコアのバラツキは小さい
異なる情報検索システム間で同一の情報ニーズに対するMAPスコアを比較した場合、一般にMAPスコアのバラツキが小さい。これは、異なるシステムが似たような品質の検索結果を提供する傾向にあることを示しています。 -
異なる情報ニーズに対して同一システム内でMAPスコアのバラツキは大きい
同じ情報検索システムにおいても、異なる情報ニーズに対するMAPスコアには大きなばらつきがあることが指摘されている。これは、システムがあるクエリには非常に良い結果を提供できる一方で、別のクエリに対してはそれほど良くない結果を提供する可能性があることを意味します。
Precision at K
- Precision at kは、検索結果の上位k件における関連ドキュメントの数をもとに精度を計算する指標。これは、最大でk個のドキュメントを考慮して精度を算出することを意味する。
- この指標では、全ての関連ドキュメントを基に精度を計算するわけではなく、上位k件のドキュメントの中で関連するものがどれだけあるかに焦点を当てる。したがって、関連ドキュメントが検索結果の上位k件以内にすべて含まれていない場合、その情報は精度の計算には反映されない。
- kの値によって精度にばらつきが出ることがある。例えば、関連ドキュメントが多く含まれているが上位k件には少ない場合や、その逆の場合など、kの設定によって精度の値が変わる。これは、関連ドキュメントの総数が精度の計算に大きな影響を与えるため、kによっては精度が不安定になることを示す。
11点補間平均精度
- 再現率が0、0.1、0.2、...、1.0の11の固定点での補間精度の算術平均。
R-精度
検索システムが特定のクエリに対してどれだけ関連性の高いドキュメントを上位に返すことができたかを評価。R-精度は、検索システムの性能をより直接的に反映する指標として有用。
あるクエリに対して関連する文書が
具体的には、検索結果の上位
ここで、
-
r K -
K -
R精度の分母は既知。Precision at Kの分母は任意。
ROC曲線
-
ROC曲線は、真陽性率(感度)と偽陽性率(
1 - {Specifity} - 感度は再現率の別の用語。
- 偽陽性率は
fp/(fp+tn)
-
ROC曲線は常にグラフの左下から右上にかけて進みます。良いシステムの場合、グラフは左側で急激に上昇します。
-
ランク付けされていない結果セットにおいて、特異性(
tn/(fp + tn) -
つまり、図8.2の「興味深い」部分は
0 < {Recall} < 0.4 -
多くの分野では、ROC曲線の下の領域を報告することが一般的な総合測定値となっており、これはMAPのROCアナログです。精度-再現率曲線は時々、緩くROC曲線として言及されます。これは理解できますが、正確ではありません。
正規化割引累積利得(NDCG)
- NDCGは、非二値的な関連性の概念(つまり、ドキュメントが「非常に関連がある」「ある程度関連がある」「関連がない」など複数の関連レベルを持つ場合)を考慮に入れた指標。
- 特に機械学習を用いたランキング手法(例えばSVMランキング)と組み合わせて使用される。
- 上位k件の検索結果に対して評価され、関連性の度合いに基づいて重み付けされた利得の累積を正規化して計算。
-
Precision at k
-
- クエリのセット
Q R(j,d) j d
すると、
ここで、
Assessing relevance
-
システム評価のための基本要件
- テスト情報ニーズは、テストドキュメントコレクションのドキュメントに関連し、システムの予測使用に適していなければならない。
- これらの情報ニーズは、ドメイン専門家によって設計されるのが最適である。クエリ用語のランダムな組み合わせは避けるべき。
-
関連性評価の収集
- 情報ニーズとドキュメントに基づき、関連性評価を収集する。これは時間とコストがかかる作業。
- 小規模コレクションでは各クエリとドキュメントペアに対する徹底的な関連性判断が可能。大規模コレクションでは、一部のドキュメントに限定して評価が行われることが多い。
-
プーリング法による標準的アプローチ
- 複数の異なるIRシステムから返された上位
k
- 複数の異なるIRシステムから返された上位
-
人間による関連性判断の限界と成功の要因
- 人間はクエリに対するドキュメントの関連性を絶対的に判断する装置ではないが、IRシステムの成功は個々の人間のニーズを満たす能力に依存する。
- 審査員間の関連性判断に対する合意度を測定することは重要であり、カッパ統計がその一般的な尺度となる。
-
カッパ値の意味
- カッパ値が1なら完全な合意、0なら偶然による合意、負ならランダム以下の合意を意味する。
- カッパ値が0.8以上は良い合意、0.67から0.8はまあまあの合意、0.67以下は疑わしい評価基盤とされる。
- TREC評価や医療IRコレクションでの審査員間合意は通常「まあまあ」の範囲にあり、これはテストセット作成者がより詳細な関連性ラベリングを求めない理由の一つ。
kappa
Observed proportion of the times the judges agreed
Pooled marginals
Probability that the two judges agreed by chance
Kappa statistic
Critiques and justifications of the concept of relevance
-
システム評価の利点
- 固定された設定の中でIRシステムとシステムパラメータを変更し、比較実験を行える。
- 形式的なテストは安価であり、システムパラメータ変更の効果を明確に診断できる。
- 信頼できる形式的な尺度があれば、手動調整ではなく機械学習によって効果を最適化できる。
- 形式的尺度がユーザーの要望を十分に記述していない場合、ユーザー満足度の向上には繋がらないが、標準的な形式的評価尺度は十分に有効であり、最近のIRの形式的評価尺度の最適化研究は成功を収めている。
-
抽象化に潜む問題
- ドキュメントの関連性が他のドキュメントと独立して扱われるが、関連性の評価は二値的であり、ドキュメントの情報ニーズへの関連性は絶対的で客観的な判断とされる。
- 関連性の判断は主観的であり、人間の評価者は理解と注意の失敗に影響されうる。
- 検索結果を見始めた際にユーザーの情報ニーズが変化しないという仮定があり、結果はコレクション、クエリ、関連性判断セットの選択に大きく偏る可能性がある。
-
改善の可能性
- INEX、TRECのトラック、NTCIRなど、最近の評価では関連性の序数概念を採用し、わずかに関連するドキュメントと高度に関連するドキュメントを区別している。
- 関連性と周辺関連性の区別に関する問題があり、特定の他のドキュメントを見た後でもドキュメントが独自の有用性を持つかどうかが重要である。
A broader perspective: System quality and user utility
- このセクションでは、定量的評価を可能にする他のシステム側面と、ユーザー有用性の問題について触れる。
- 形式的な評価指標は、私たちの最終的な関心事である人間の有用性の指標(各ユーザーが提起する情報ニーズに対してシステムが提供する結果にどれだけ満足しているか)と差がある。
- 人間の満足度を測定する標準的な方法は、様々な種類のユーザースタディを通じて行われる。
- タスク完了までの時間などの客観的な定量的指標
- 検索エンジンに対する満足度スコアなどの主観的な定量的指標
- 検索インターフェイスに関するユーザーコメントなどの定性的指標
System issues
情報検索システムの検索品質以外にも、情報検索システムを評価するための実用的なベンチマークが多数ある。これらには次のものが含まれる。
- クエリ言語の表現力を除くこれらの基準はすべて直接測定可能であり、速度やサイズを定量化できます。さまざまな種類の機能チェックリストを使用すると、クエリ言語の表現力を半精度にすることができます。
情報検索システム評価のためのベンチマーク
- インデックス付けはどれくらいの速度で行われるか?
- つまり、ドキュメントの長さにわたる特定の分布に対して 1 時間あたり何件のドキュメントにインデックス付けが行われるか?
- 検索速度はどれくらいか?
- つまり、インデックスサイズの関数としての待ち時間はどれくらいか?
- クエリ言語はどの程度表現力豊かか?複雑なクエリの速度はどれくらいか?
- 文書の数、または広範囲のトピックにわたって情報が分散されているコレクションの数という点で、その文書コレクションはどのくらいの大きさか?
User utility
- 理想としては、システムの関連性、速度、ユーザーインターフェイスに基づいて、ユーザーの総合的な幸福度を定量化する方法が欲しい。
- これには、幸せにしたい人々の分布を理解することが含まれ、これは完全に設定に依存する。
- ウェブ検索エンジンの場合、幸せな検索ユーザーとは、欲しいものを見つける人々である。そのようなユーザーの間接的な指標として、同じエンジンに戻る傾向がある。
ユーザーの戻り率を測定することは効果的な指標であり、他の検索エンジンをどの程度使用したかも測定できればさらに効果的である。 - しかし、広告主も現代のウェブ検索エンジンのユーザーである。彼らは、顧客が自分のサイトをクリックして購入すると幸せである。
- 電子商取引ウェブサイトでは、ユーザーは何かを購入したいと考えている可能性が高い。したがって、購入までの時間や、購入者になる検索者の割合を測定することができる。
- ショップフロントウェブサイトでは、購入が行われればユーザーと店舗所有者の両方のニーズが満たされるかもしれない。
- 一般的に、エンドユーザーの幸福か、電子商取引サイト所有者の幸福かを最適化しようとしているかを決定する必要がある。通常、支払いを行っているのは店舗所有者である。
- 「エンタープライズ」(企業、政府、学術)イントラネット検索エンジンの場合、関連する指標はユーザーの生産性、つまりユーザーが必要な情報を探すのに費やす時間である可能性が高い。
- ユーザーの幸福を測定することは難しく、これが標準的な方法論が検索結果の関連性を代理指標として使用する理由の一部である。
Refining a deployed system
- 展開されたIRシステムの改善には、ユーザー満足度を示す指標をもとに、システムの異なるバージョンをテストする方法が頻繁に用いられます。
- A/Bテストは、一つの変更点に焦点を当て、トラフィックの小さな割合をランダムに異なるシステムに向けることで実施されます。
- 例えば、ランキングアルゴリズムの変更をテストする場合、ランダムなユーザーサンプルを変更版システムにリダイレクトし、トップ結果へのクリック頻度などを評価します。
- A/Bテストは、単一変数テストを実行する基礎であり、変更された各パラメータが肯定的または否定的な効果を持つかどうかを明確にします。
- ライブシステムのテストは、変更がユーザーに与える効果を容易かつ安価に測定でき、大きなユーザーベースを持つことで、非常に小さな効果も測定可能にします。
- A/Bテストは、展開、理解、管理職への説明が容易であるため、広く使用されています。
Results snippets
スニペットの有用性
- 検索結果の提示には、スニペット(ドキュメントの短い要約)が用いられる。これはユーザーにとって有益な情報を提供する目的がある。
- スニペットにはドキュメントのタイトルと自動抽出された要約が含まれ、ユーザーがドキュメントの関連性を自身で判断できるようにする。
- 要約には静的要約と動的要約の二種類があり、静的要約はクエリに関係なく常に同じ内容を提供し、動的要約はユーザーの情報ニーズに応じてカスタマイズされる。
静的要約
- 静的要約はドキュメントの一部やメタデータを元に作成され、インデックス作成時に抽出・キャッシュされることが多い。
動的要約
- 動的要約は、特にユーザーが情報ニーズに関してドキュメントを評価するのに役立つドキュメント内の「ウィンドウ」を表示する。
- 動的要約の生成はIRシステムの使いやすさを向上させるが、システム設計の課題も伴う。事前に計算できないため、動的要約を生成するためのコンテキストを再構築するのが難しい場合がある。
- スニペット生成は迅速でなければならず、文書の固定サイズのプレフィックスのみをキャッシュすることが一般的である。これは、文書が更新された後の変更がキャッシュやインデックスに反映されない問題を引き起こす可能性がある。
- 適切なスニペットを選択することは慎重な配慮を要し、ユーザーが完全なフレーズを含むスニペットを好む傾向にある。
参考文献
Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008.
Discussion