🔖
Information Retrieval | 19 Web search basics
1. Background and history
ウェブの背景と歴史:
- ウェブは規模、協調の欠如、参加者の多様性など、多くの点で類例のない特性を持つ。
- ハイパーテキストの発明は、1940年代にVannevar Bushによって構想され、1970年代には実際のシステムとして実現された。これは、1990年代にWorld Wide Webが形成される前の出来事である。
- Webの使用は、シンプルでオープンなクライアントサーバーデザインに基づいており、HTTPプロトコルとHTMLマークアップ言語を使用している。
Webクローラーの基本的な動作:
- クライアント(ブラウザなど)がウェブサーバーにHTTPリクエストを送信する。
- URL(Uniform Resource Locator)が指定され、プロトコル、ドメイン、パスなどの情報が含まれる。
- サーバーはリクエストに応じてHTMLファイルを返し、クライアントはそれを解析してコンテンツを表示する。
ウェブ情報の発見:
- ウェブ情報の発見には、フルテキストインデックス検索エンジンとカテゴリ分類が用いられた。
- インデックス検索エンジンはキーワード検索を提供し、ランキング機構を使用して検索結果を提供する。
- カテゴリ分類は階層的なカテゴリラベルでウェブページを分類し、ブラウズすることができるが、スケーラビリティに課題がある。
Web検索エンジンの初期:
- 最初のWeb検索エンジンは、スケーラビリティの課題に焦点を当て、数千万件のドキュメントをインデックス化し、クエリに迅速に応答することが求められた。
- しかし、ウェブ上のコンテンツ作成の独自性により、検索結果の品質と関連性に課題が残った。これに対処するために、新しいランキングやスパム対策の技術が生まれた。
2. Web characteristics
ウェブの特性:
- ウェブの爆発的な成長をもたらした基本的な特徴は、中央の制御がほとんどなく、分散されたコンテンツの公開であり、これはウェブ検索エンジンがこれらのコンテンツをインデックス化して取得する際の最大の課題となった。
- ウェブページの著者は、数十種類の自然言語と数千種類の方言でコンテンツを作成し、さまざまな形式のステミングやその他の言語操作を要求した。
- コンテンツ作成は、編集に訓練されたライターだけの特権ではなくなり、数千万人に開かれた結果、文法やスタイルの多様性が生じた。
- ウェブページには、色やフォント、構造において野生的な変化が見られ、プロフェッショナルが作成した企業のホームページを含め、一部のページは画像のみで構成され、インデックス可能なテキストがなかった。
ウェブページのテキストの内容:
- ウェブ上のコンテンツ作成の民主化は、ほとんどすべての主題についての意見の新しいレベルの粒度を意味し、真実、嘘、矛盾、仮定が大規模に存在した。
- 信頼できるウェブページはどれかという問いに対して、全体的な答えはない。さまざまなユーザーによって異なる信頼性があり、ユーザーによっては、The New York Timesの報道が信頼できると感じるかもしれないが、他のユーザーはThe Wall Street Journalを好むかもしれない。
ウェブページの静的と動的な特性:
- 1995年末までに、Altavistaは約3,000万の静的なウェブページをクロールしてインデックス化していた。
- 静的なウェブページとは、そのページのリクエストごとに内容が変化しないものであり、例えば、毎週ホームページを手動で更新する教授のページがこれに該当する。
- 一方、動的なページは、通常、データベースへのクエリに応じてアプリケーションサーバーが機械的に生成するものであり、URLに「?」が含まれることが特徴である。
2-1. The web graph
ウェブグラフ:
- 静的なHTMLページとそれらの間のハイパーリンクからなる静的ウェブは、各ウェブページがノードであり、各ハイパーリンクが有向エッジである有向グラフとして見ることができる。
- 図19.2では、ウェブグラフから取り出した2つのノードAとBが示されており、それぞれウェブページに対応し、AからBへのハイパーリンクがある。ここで、ウェブグラフのすべてのノードと有向エッジの集合をウェブグラフと呼ぶ。
- ページA上のハイパーリンクの起源の周囲には、通常、一定のテキストがある。このテキストは、ページAのHTMLコードでハイパーリンクをエンコードする<a>(アンカー)タグのhref属性に一般的に含まれており、アンカーテキストと呼ばれる。
- この有向グラフは一般的に強連結ではなく、一部のページのペアでは、ハイパーリンクをたどって一方のページから他方のページに進むことができない。ページへのハイパーリンクをインリンク、ページからのハイパーリンクをアウトリンクと呼ぶ。ページへのインリンクの数(またはインディグリー)は、平均で約8から15の間になることが多い。同様に、ウェブページのアウトディグリーは、それからのリンクの数で定義される。
ウェブグラフの特徴:
- ウェブページへのリンクはランダムに分布していないことが豊富な証拠がある。すべてのウェブページがリンクの先をランダムに選択する場合、ウェブページへのリンクの数の分布はポアソン分布に従うはずだが、実際にはそうではない。
- 代わりに、リンクの数がインディグリー
i 1/i^\alpha \alpha
ウェブの構造に関する重要なポイント:
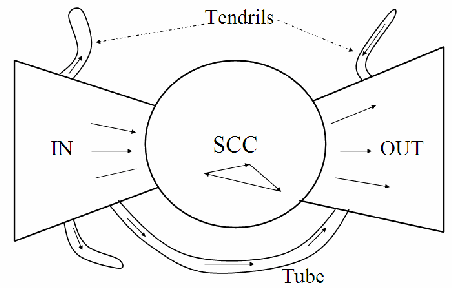
- 複数の研究によると、ウェブページをつなぐ有向グラフは弓形をしている可能性がある。
- この弓形構造には、IN、OUT、SCCという3つの主要なカテゴリーのウェブページがある。
- INからSCCへの移動、SCCからOUTへの移動、SCC内の任意のページから他のSCC内の任意のページへの移動は可能である。
- しかし、SCC内のページからINのページに移動したり、OUTのページからSCC内のページに移動したりすることはできない。
- いくつかの研究では、INとOUTのサイズはほぼ同じであり、SCCはやや大きいことが報告されている。
- 大部分のウェブページはこれらの3つのセットのいずれかに属している。
- 残りのページは、INからOUTに直接つながる小さなページの集合であるチューブ、およびINからどこにもつながらない、またはどこからもOUTへつながらないテンドリルに分かれる。
- 図19.4がこのウェブの構造を示している。
2-2. Spam
初期のウェブ検索におけるスパムの問題:
- ウェブ検索は広告主と購入者を結びつける重要な手段であることが明らかになった。
- ユーザーは不動産購入を目的として特定のキーワードで検索し、それに対応するウェブページが上位に表示されることが期待される。
- 不動産の売り手やエージェントは、特定のキーワードで上位にランク付けされるためにウェブページのコンテンツを操作する動機がある。
スパムの定義とその背景:
- スパムは選択されたキーワードの検索結果で上位に表示されるために、ウェブページのコンテンツを操作することを指す。
- スパマーはキーワードの反復などのトリックを使用して、検索エンジンのランキングを操作しようとする。
- スパムはウェブ上のコンテンツ作成の動機の多様性から生まれる。
スパム対策と進化:
- 検索エンジンはキーワードの反復を大量に除外するなどの対策を取り、スパマーはより洗練されたスパム技術を開発してきた。
- スパマーの技術はクローキングなどの複雑な手法に進化し、検索エンジンのランキングを欺くことが可能になった。
- スパムは経済的な動機から生まれ、検索エンジン最適化(SEO)と呼ばれる業界も発展している。
クローキングとは:
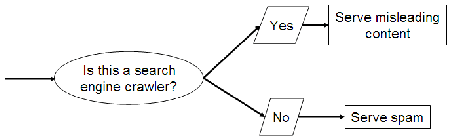
- クローキングでは、スパマーのウェブサーバーは、httpリクエストがウェブ検索エンジンのクローラー(ウェブページを収集する検索エンジンの一部)から来るか、ユーザーのブラウザから来るかに応じて異なるページを返す。
- ウェブ検索エンジンのクローラーからのリクエストの場合、ウェブページは誤ったキーワードで検索エンジンにインデックスされる。
- ユーザーがこれらのキーワードで検索し、ページを表示する場合、検索エンジンにインデックスされたコンテンツとはまったく異なるコンテンツが表示される。
- このような検索インデクサーの欺瞞は、従来の情報検索の世界では見られないものであり、ページの発行者とウェブ検索エンジンとの関係が完全に協力的ではないことに起因している。
スパムと検索エンジンの攻防:
- スパマーと検索エンジンの間での攻防は絶え間ないものであり、これにより敵対的情報検索の研究分野が生まれた。
- 検索エンジンはリンク分析などのテクニックを使用して、スパマーのテキスト操作に対抗している。
3. Advertising as the economic model
初期のウェブ広告:
- 早い段階では、主要なウェブサイトにおいて、企業はグラフィカルなバナー広告を掲載していた。
- 広告の目的はブランディングであり、視聴者に企業のブランドに対する良い印象を与えることであった。
- 広告は主にCPM(千回毎の表示数に対するコスト)ベースで価格が設定されていた。
- 一部のウェブサイトでは、広告のクリック回数に基づいて価格を設定するCPC(クリック単価)モデルを採用していた。
Goto(後のOverture)の登場:
- Gotoは、クエリ「q」に関連するウェブページを表示したい企業からの入札を受け入れていた。
- Gotoはクエリ「q」に対する入札を行った広告主のページを、入札額によって順序付けして返す仕組みを採用していた。
- ユーザーが広告をクリックすると、広告主が用意したウェブページにリダイレクトされ、購入を促すことが目的とされた。
スポンサード検索と純粋な検索の統合:
- 純粋な検索エンジンとスポンサード検索エンジンの統合が進んだ。
- 現在の検索エンジンは、純粋な検索結果とスポンサード検索結果を別々に表示している。
- スポンサード検索結果の取得とランキングは、情報検索とマイクロ経済学のアイデアを組み合わせて行われている。
広告主の課題と対策:
- 広告主は、検索エンジンがランキングをどのように行うかを理解し、マーケティングキャンペーン予算を適切に割り当てる必要がある。
- 一部の参加者は、システムを悪用して広告主の利益を得ようと試みており、その中にはクリックスパムと呼ばれる形態も含まれている。
- クリックスパムとは、正当な検索ユーザーからのものではないスポンサード検索結果へのクリックを指します。例えば、悪賢い広告主は、競合他社の広告予算を使い果たそうと、その競合他社のスポンサード検索広告を繰り返し(ロボットクリックジェネレータを使用して)クリックすることを試みるかもしれません。
4. The search user experience
ウェブ検索のユーザーエクスペリエンスの重要性
- 伝統的な情報検索とは異なり、ウェブ検索のユーザーは一般的にウェブコンテンツの異質性やクエリ言語の構文、クエリの作成方法についてほとんど知らない(または関心がない)。
- 平均して、ウェブ検索での検索クエリのキーワード数は2〜3語であり、構文演算子(ブール演算子、ワイルドカードなど)はほとんど使用されない。
ウェブ検索エンジンの成長とユーザートラフィックの重要性
- ウェブ検索エンジンは、ユーザートラフィックを引き付けることが重要であり、これによりスポンサード検索からの収益が増加する。
- Googleは、他社に対して自身の成長を促すために2つの原則を確立した。
- 関連性に焦点を当て、特に最初の数件の検索結果での精度を重視する。
- 軽量なユーザーエクスペリエンスを提供し、検索クエリページと検索結果ページがすっきりしており、ほとんどがテキストで構成され、非常に少ないグラフィカル要素が含まれている。
4-1. User query needs
ユーザークエリのニーズ
- 情報クエリ:広範なトピックに関する一般的な情報を求めるクエリ。例えば、白血病やプロヴァンスなど。
- ナビゲーションクエリ:特定のエンティティのウェブサイトやホームページを探すクエリ。例えば、ルフトハンザ航空など。
- トランザクションクエリ:ウェブ上での取引の前段階となるクエリ。製品の購入、ファイルのダウンロード、予約の作成など。
クエリのカテゴリ分類の課題
- クエリがどのカテゴリに属するかを判断することは困難であり、これはアルゴリズムによる検索結果だけでなく、スポンサード検索結果の適切さにも影響する。
- ユーザーは情報的(およびある程度のトランザクション的)クエリに関して、検索エンジンの包括性に関心を持っている。
5. Index size and estimation
インデックスサイズと推定
- インデックスサイズの増加は包括性の増加につながるが、特定のページが索引されるかどうかは重要であり、すべてのページが同じ情報量ではない。
- ウェブ検索エンジンがインデックス化するウェブページの割合を理解することは困難である。
- ウェブページは動的で無限に存在するため、その割合を推定することは困難。
- ウェブサーバーは無限に多くの有効なウェブページを生成する方法があり、その中には悪意のあるものも含まれる。
- インデックスサイズの相対比を推定する方法は複数存在するが、正確な推定は困難。
- インデックスサイズの推定手法の一つとして、「捕獲-再捕獲法」という古典的な手法がある。
- この手法は、検索エンジンのインデックスからランダムにページを選択し、別の検索エンジンのインデックスにそのページが存在するかどうかをテストすることに基づいている。
- ただし、この手法にはいくつかの仮定があり、正確な推定が難しい。
インデックスサイズの推定手法
-
2つの検索エンジン
E_1 E_2 -
実験を通じて、ランダムに選択した
E_1 E_2 E_2 E_1 -
これにより、
E_1 x E_2 y -
式(245)は、
E_1 E_2
x |E_1| ≈ y|E_2| - ( x ) は検索エンジン ( E_1 ) のインデックスの一部である ( E_2 ) のインデックス内にあるページの割合を表します。
- ( y ) は検索エンジン ( E_2 ) のインデックスの一部である ( E_1 ) のインデックス内にあるページの割合を表します。
- ( \vert E_1 \vert ) は検索エンジン ( E_1 ) のインデックスのサイズ、つまりインデックスされているページの総数を表します。
- ( \vert E_2 \vert ) は検索エンジン ( E_2 ) のインデックスのサイズ、つまりインデックスされているページの総数を表します。
- この式は、2つの検索エンジンのインデックスサイズがほぼ同じである場合に成り立ちます。つまり、( E_1 ) と ( E_2 ) のインデックス内のページの割合が同じであると仮定しています。
-
式(246)は、
E_1 E_2
\frac{|E_1|}{|E_2|} \approx \frac{y}{x} - この式は式 (245) を再配列し、( E_1 ) のインデックスサイズと ( E_2 ) のインデックスサイズの比を ( x ) と ( y ) の比で表したものです。
- これにより、( E_1 ) と ( E_2 ) のインデックスサイズの比が、各検索エンジンのインデックス内でのページの割合の比とほぼ等しいことが示されます。
- つまり、( E_1 ) が ( E_2 ) よりもページを多くインデックスしている場合、( x ) は1に近くなり、( y ) は1より大きくなります。逆に、( E_2 ) が ( E_1 ) よりもページを多くインデックスしている場合、( x ) は1より小さくなり、( y ) は1に近くなります。
-
-
インデックスサイズ推定のためのサンプリング手法について説明されている。
-
ランダム検索、ランダムIPアドレス、ランダムウォークなど、複数の手法が紹介されている。
-
各手法にはバイアスが含まれており、完全なランダム性を確保することは困難。
-
ランダムクエリによるサンプリングは特に注目されており、文書ランダムウォークがその改善版として提案されている。
-
これらの手法は、検索エンジンのインデックスサイズ比を推定するための有効な手段であるが、バイアスの影響を理解することが重要である。
-
推定方法にはいくつかのアプローチがあるが、いずれも完璧ではない。
- ランダム検索、ランダムIPアドレス、ランダムウォーク、ランダムクエリなどの手法がある。
-
ランダムクエリ
- ランダムクエリは、ウェブ検索エンジンのインデックスからランダムなページを選択する方法として注目されているが、実装には注意が必要である。
- ウェブページの長さにバイアスがかかる。
- 検索エンジンのランキングアルゴリズムからのバイアスが生じる。
- 検索エンジンがテストクエリに適切に対応しない可能性がある。
- 検索エンジンがロボットスパムとしてテストクエリを拒否する可能性がある。
- 新しい研究では、これらの問題を解決するために、統計的手法や異なるサンプリング方法が提案されている。
ランダムウォークサンプリング
- ランダムクエリの改良方法として、文書ランダムウォークサンプリングがある。
- 文書ランダムウォークは、文書から派生した仮想グラフ上のランダムウォークに基づいており、文書間の共通キーワードに基づいてグラフが構築される。
- この手法では、グラフが具体的に構築されるわけではなく、ランダムウォークによって文書が選択される。
- この手法は、ランダムウォークによってより広範囲な文書がサンプリングされるため、他の手法よりもバイアスが少ない可能性がある。
インデックスサイズと推定の課題
- インデックスサイズを正確に推定することは困難であり、多くの仮定やバイアスが存在する。
- 現在の手法では、バイアスを最小限に抑えるための努力が続けられているが、完璧な解決策はまだ存在しない。
- インデックスサイズの推定は、ウェブ検索エンジンの性能や競争力を理解する上で重要であるが、その推定結果を解釈する際には慎重さが必要である。
6. Near-duplicates and shingling
重複の問題とシングリング
- 重複の存在: ウェブには同じコンテンツの複数のコピーが含まれている。推定によれば、ウェブ上のページの40%が他のページの重複であるとされている。
- 重複の検出: 重複を検出する最も単純な方法は、各ウェブページについて、そのページの文字の簡潔な(たとえば64ビットの)指紋を計算することです。そして、2つのウェブページの指紋が等しい場合、それらのページが等しいかどうかをテストし、等しい場合は片方を他方の重複コピーと宣言します。
- 近似重複の問題: ウェブ上で広く見られる重要な現象は、近似重複です。多くの場合、1つのウェブページの内容は、他のページとほぼ同じであり、最終更新日時などのわずかな違いがあるだけです。このような場合でも、2つのページが十分近いと見なす必要があります。
シングリングによる近似重複の検出
-
シングルの定義: 正の整数
k d d k d k - シングルの類似性の検出: 2つの文書が近似重複であると見なされる条件は、それらのシングルのセットがほぼ同じである場合です。この条件を正確に定義し、すべてのウェブページのシングルのセットを効率的に計算および比較する方法を開発します。
- ハッシングの応用: ハッシュの応用により、シングルの集合のJaccard係数が大きい組み合わせを検出します。これにより、2つの文書が近似重複している可能性が高いペアを素早く特定できます。
シングリングのアルゴリズム
- ランダムな置換: 64ビット整数から64ビット整数へのランダムな置換を使用し、ハッシュされたシングルの集合に対してこの置換を適用します。
- 確率的なテスト: シングルの集合のJaccard係数を計算し、事前に設定されたしきい値を超える場合、それらの文書を近似重複と宣言します。
重複文書のクラスタリング
- 類似文書の特定: シングルのオーバーラップが大きい文書のペアを特定し、それらを近似重複の「構文的クラスター」にグループ化します。
- スケッチの効率的な計算: シングルのオーバーラップの数を効率的に計算するために、スケッチを事前処理し、空間の無駄を削減します。
参考文献
Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008.
Discussion