Information Retrieval |07 Computing scores in a complete search system
Efficient scoring and ranking
- コンセプトは、重要な文書のみをスコア計算の対象として、計算を効率化・高速化しよう。
- 計算する文書をどうやって絞り込むかが重要。
Inexact top K document retrieval
概要
- 競合する文書のセットAを見つける。
K < |A| \leqq N - Aがクエリに対する上位スコアの文書を必ずしも含んでいるわけではない点に留意。
- ただし、Aには上位K件のスコアに近い多くの文書を含んでいる可能性がある。
- Aの中からスコアが最も高いK件の文書を返す。
スコアリング効率化&高速化のアイディア
-
これまで、N個の全ての文書をスコアリングして、その中からクエリに対するスコアが最も高い上位K件の文書を正確に取得する方法を解説。
- すなわち、全てのN個の全ての文書をスコアリングする必要があった。
- 「正確」なTop-K文書
- 正確ではあるが計算コストが大きくなる
-
代案として、クエリに対するスコアが最も高い上位K件の文書に含まれる可能性のあるK件の文書を生成する手法を検討。
- 「不正確」なTop-K文書
- 出力するK件の文書の計算コストを大幅に低減
- ユーザーが感じる上位K件の結果の関連性を実質的に変更しない。
- 最適なK件のスコアに非常に近いK件の文書を取得することで十分であることがわかります。
- コレクション内のN件の文書のほとんどのスコアを計算せずに、そのようなK件の文書を取得する手法について詳しく説明します。
-
コサイン類似度はユーザーが感じる関連性の代理指標に過ぎない。
-
ここでは、コサインスコアを計算せずに大量の文書を除外することを目的とした一連のアイデアを検討。
Index elimination
- 複数の用語を含むクエリ
q - 1つもクエリ用語を含まない文書は検索の結果候補から除外。
-
クエリ用語
q - IDFが事前に設定された閾値を超える用語を含むドキュメントのみをスコア計算。
- IDFは文書dにおける用語tの希少性。
- IDF値が低い用語の投稿リストは一般に長いので、これらが走査対象から除外されると、コサインを計算するドキュメントのセットが大幅に減る。
- IDF値が低い用語はストップワードとして扱われ、スコアには寄与しない。
- カットオフの閾値はクエリに応じて調整できる。
- IDFが事前に設定された閾値を超える用語を含むドキュメントのみをスコア計算。
-
多くの (特殊な場合としてはすべて) クエリ用語を含むドキュメントのみを走査対象とする。
- クエリ用語のすべて (または多数) を含むドキュメントのみをスコア計算。
- 出力に含まれるドキュメントの数が候補ドキュメント
K
Champion lists
Champion Lists = 用語
あるクエリ
例:
-
r - IDF値が上位
r t -
r -
r K -
K
-
-
r - ChampionListのサイズ(
r - 希少な用語が含まれるドキュメントは、その用語に関連している可能性が高く、検索結果としてユーザーに提示されるべき
- IDF値が上位
Static quality scores and ordering
- 文書
d q - 例:ユーザーからのレビュー数の多い記事に高いscoreを付与。
- 静的な品質スコア(static quality score)を
g(d) -
g(d)
-
net-score
-
g(d) sim(q,d) - 他の重み付けも可能。ヒューリスティックな有効性。
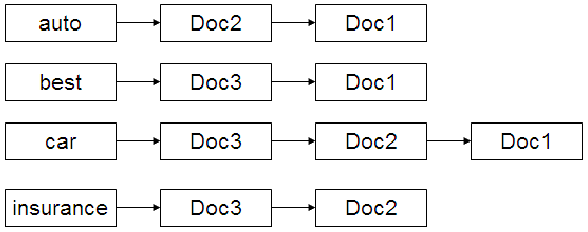
-
g(d) - Doc1、Doc2、Doc3 それぞれのstatic quality scoreが
g(1)=0.25, g(2)=0.5, g(3)=1 - 全てのposting listを共通ルールでソートすることによって効率的なポスティング交差アルゴリズムが実現可能。
チャンピオンリストの拡張方法
- 特定の用語に関連する文書の中からスコアが高いもの(Global Champion List)を選択して計算する方法。
- 高リストと低リストを用いることで、より関連性の高い文書(
g(d) m
-> いずれの方法も検索プロセスの速度と効率を向上させることが可能になる。
以下に2種類の具体的な手順を整理する。注:いずれも用語
① Global Champion Listに対して計算
- まず、適切に選ばれた値
r t g(d)+tf\_idf(t,d) r - このリストは全ての用語において共通の順序(文書IDまたはstatic quality scoreによる)でソートされている。
-
クエリ時には、これらのグローバルチャンピオンリストの和集合に含まれる文書のみに対してネットスコアを計算
- ネットスコアが大きくなりそうな文書に焦点を当てて効率的に計算。
② g(d) m
- 各用語
t g(d) - 一方のリスト(高リストと呼ぶ)には、用語
t tf t m - もう一方のリスト(低リストと呼ぶ)には、
t
- 一方のリスト(高リストと呼ぶ)には、用語
- クエリを処理する際には、まずクエリ用語の高リストのみをスキャンして、ある数以上のクエリ用語の高リストに載っている任意の文書のネットスコアを計算。
- このプロセスで
K - そうでない場合は、低リストのスキャンを続け、これらのポスティングリストにある文書のスコアを計算します。
Impact ordering
- Index elimination、Champion lists、Static quality scores and orderingを一般化した方法
- インパクト順序付けは、スコアリングにおいて用語頻度
{tf}_{t,d} idf t - 用語
t d - キーワードは「用語毎のスコアリング」。
- 共通ルールでソートされておらず、同時トラバースを行うことができないInexact top-K retrieval(不正確なトップK検索)に対して適用可能。
- 用語
t d {tf}_{t,d} t d - 文書の順序はポスティングリストごとに異なる(=用語毎に異なる)。したがって、全てのクエリ用語のポスティングリストを同時に走査してスコアを計算することができない。
- 用語ごとにスコアを積み上げ計算する。
計算を効率化するアイディア
1.
- クエリ用語
t - 固定数
r {tf}_{t,d}
2.
- 外部ループでスコアを蓄積する際に、
idf -
idf t - これらの変化が最小であれば、残りのクエリ用語からの蓄積を省略するか、またはポスティングリストの短いプレフィックスを処理。
Cluster pruning
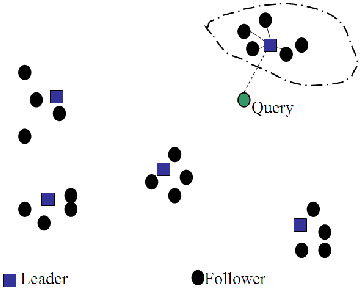
- クラスタリングプルーニングでは、文書ベクトルをクラスタリングする前処理ステップがある。
- クエリ時には、少数のクラスタ内の文書のみを候補として考慮し、それらの文書に対してコサインスコアを計算する。
① 前処理ステップ
- N個の文書からなる集合からランダムに
\sqrt{N} - リーダーではない各文書について、最も近いリーダーを計算します。
- リーダーではない文書をフォロワーと呼びます。直感的には、ランダムに選ばれた
\sqrt{N} \approx N/\sqrt{N} = \sqrt{N}
② クエリ処理
- クエリ
q L q \sqrt{N} - 候補セット
A L
ランダムに選ばれたリーダーを使用したクラスタリングは、ベクトル空間内の文書ベクトルの分布を反映する可能性が高く、文書が密集しているベクトル空間の領域は、複数のリーダーを生み出し、より細かいサブリージョンに分割する可能性があります。
クラスタリングプルーニングのバリエーションでは、追加のパラメータ
Components of an information retrieval system
- これまでに開発されたアイデアを組み合わせて、ドキュメントを取得してスコアを付ける基本的な検索システムを説明。
- ベクトル空間だけでなく、他のクエリ演算子を用いた検索にも触れる。
Tiered indexes
- Top-K検索でヒューリスティックス(例:インデックス削除)を使用する際、文書のセット
A K
-> 問題の一般的な解決策は、Tiered indexesの使用です。 - Tiered Indexesはチャンピオンリストの一般化。
概要
- Tiered indexesは、異なる品質(下記具体例においては
tf - より高い
tf tf - これにより、検索クエリを処理する際に、まず上位のTierから関連する文書を探す。上位のTierでは
K - Tiered indexesを使用することで、効率的にTop-Kの文書を見つけることができ、同時に検索処理の負荷を軽減することが可能になる。
具体例
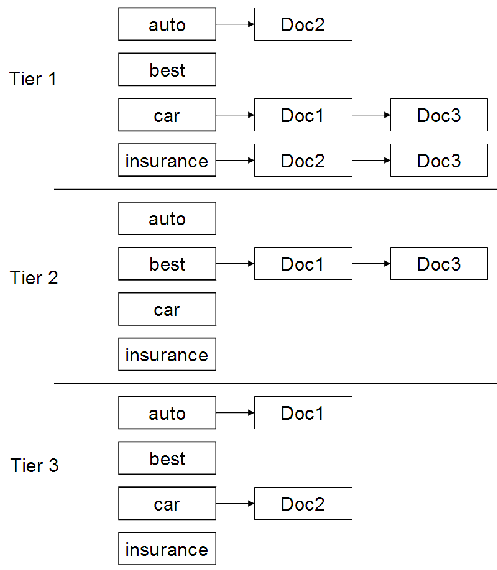
- 上記例では、Tier1の
tf tf - すなわちTier1インデックスは
tf tf - この例では、Tier内のPostingを文書IDによって順序付けることを選択。
- すなわちTier1インデックスは
Query-term proximity
- ユーザーは、クエリ用語が互いに近い位置で現れる文書を好む傾向にある。
- その文書がユーザーのクエリ意図に焦点を当てたテキストを含んでいる証拠だから。
- クエリ用語の近接性は、特にウェブ上でのフリーテキストクエリ(第19章)において重要。
概要
- 2つ以上のクエリ用語
t_1, t_2, \ldots, t_k - 文書
d \omega - 例えば、文書が単に「The quality of mercy is not strained」という文から構成されている場合、クエリ「strained mercy」に対する最小のウィンドウは4となる。
- 「mercy」から「strained」までのウィンドウには、合計で4つの単語(「mercy」、「is」、「not」、「strained」)が含まれる。
- 例えば、文書が単に「The quality of mercy is not strained」という文から構成されている場合、クエリ「strained mercy」に対する最小のウィンドウは4となる。
- 直感的に、
\omega d - 文書が全てのクエリ用語を含んでいない場合は、
\omega - また、ストップワードを除外して
\omega - 上記例の場合は、「is」、「not」をストップワードとして除外して、合計で2つの単語(「mercy」、「strained」)が含まれることとなる。
- このような近接性に重み付けされたスコアリング関数は、純粋なコサイン類似度からの逸脱であり、Googleや他のウェブ検索エンジンが明らかに使用している「ソフトな論理積」セマンティクスにより近いもの。
- 文書
\omega
- 最も単純な答えは、以下の第7.2.3節で紹介する「hand coding(手作業によるコーディング)」技術に依存。
- よりスケーラブルなアプローチは、整数
\omega
Designing parsing and scoring functions
- 検索インターフェース、特にWeb上の消費者向け検索アプリケーションでは、エンドユーザーからクエリオペレータを隠蔽する傾向がある。
issues
- さまざまな検索オペレータ用のインデックスを備えた検索システムがどのように扱うべきか
- 文書のスコアに影響を与える可能性のあるさまざまな要因をどのように組み合わせるべきか
概要
- 通常、クエリパーサーを使用してユーザーが指定したキーワードをさまざまなオペレータを含むクエリに変換し、それを基礎となるインデックスに対して実行する。
- この実行には、複数のクエリが基礎となるインデックスに対して行われることがあり、例えば、クエリパーサーは以下のような一連のクエリを発行する:
- ユーザーが生成したクエリ文字列をフレーズクエリとして実行し、3つの用語「rising interest rates」から成るベクトルをクエリとしてベクトル空間スコアリングでランク付けする。
- 「rising interest rates」というフレーズを含む文書が10件未満の場合、「rising interest」と「interest rates」の2つの2語フレーズクエリを実行し、これらもベクトル空間スコアリングでランク付けする。
- それでも10件未満の結果しか得られない場合、3つの個別のクエリ用語から成るベクトル空間クエリを実行する。
集約スコアリング関数の必要性
- これらのステップが発動されると、それぞれのスコア付けされた文書リストが得られ、それぞれの文書に対してスコアを計算。
- このスコアは例えば以下の計算方法の組み合わせを組み合わせる必要がある
- ベクトル空間スコアリング
- 静的品質
- 近接性の重み付け
- その他の要因からの寄与
- これらを組み合わせて最終的なスコアを計算するには、各スコアを蓄積する集約スコアリング関数が必要。
スコアリング関数とクエリパーサーを設計するための機械学習の利用
- クエリパーサーと集約スコアリング関数をどのように設計するかは設定によって異なる。
- 多くのエンタープライズ環境では、アプリケーションビルダーが利用可能なスコアリングオペレータのツールキットとクエリパーシングレイヤーを使用して、スコアリング関数とクエリパーサーを手動で設定する。
- 一方、Web検索では、文書コレクションが常に変化しており、スコアリング要因が数百に及ぶことがあり、手動でのスコアリングが困難である。
- これに対処するため、機械学習によるスコアリングの使用が一般的になりつつあり、これについては別の章で紹介。
Putting it all together
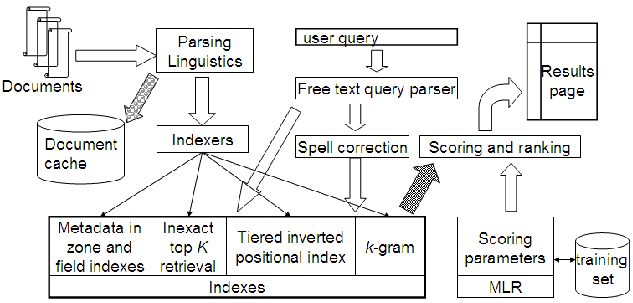
処理のステップを箇条書きにすると、以下のようになります:
- 文書はパーシングと言語処理(言語および形式の検出、トークン化、ステミング)のために入力される。
- パースされた文書のコピーが文書キャッシュに保持され、クエリの結果リストに各文書を伴うテキストスニペットの生成が可能になる。
- スニペットとは、検索結果に表示される文書の小さなテキストの断片であり、ユーザーにその文書がクエリにどのようにマッチするかの簡潔な説明を提供することを目的とする。
- トークンのストリームがインデクサーの銀行に供給され、各文書のメタデータを格納するゾーンおよびフィールドインデックス、(階層的な)位置インデックス、スペリング修正やその他の許容検索のためのインデックス、および不正確なTop-K検索を加速するための構造を含むインデックスの銀行が作成される。
- フリーテキストユーザークエリが直接およびスペリング修正候補を生成するモジュールを通じてインデックスに送られる。
- 検索された文書がスコアリングモジュールに渡され、機械学習に基づくランキング(MLR)を使用して文書のスコアが計算される。
- ランク付けされた文書が結果ページとして表示される。
Vector space scoring and query operator interaction
- この章ではベクトル空間スコアリングモデルがクエリオペレータとどのように関連しているかについて議論する。
- ベクトル空間モデルはフリーテキストクエリのためのパラダイムとして導入された。
- 検索エンジン構築時には、複数のクエリオペレータをサポートすることが考慮される。
- さまざまなクエリオペレータを実行するためにインデックスのどのコンポーネントを共有できるか、及びさまざまなクエリオペレータを混在させたユーザークエリをどのように扱うかを理解する必要がある。
- ベクトル空間スコアリングはフリーテキスト検索をサポートし、クエリオペレータなしで単語のセットとしてクエリが指定されることを可能にする。
- 古典的なフリーテキストクエリの解釈は、検索された文書に少なくとも1つのクエリ用語が存在することであった。
- 近年、Googleなどのウェブ検索エンジンは、クエリボックスに入力された用語のセットが、全てまたはほとんどのクエリ用語を含む文書のみを検索する論理積クエリの意味論を持つという概念を普及させている。
Boolean retrieval
復習
- ブール検索は、AND、OR、NOTのような論理演算子を用いて、特定の条件を満たす文書を正確に選び出すのに適した検索アルゴリズム
Vector space indexとの関係
- ブールインデックスはデフォルトで用語の重み情報を保持しない
- ベクトル空間インデックスにおける非ゼロのベクトル成分をブールインデックスのTrueとして扱うことで、ベクトル空間インデックスを用いてブールインデックスと同様の機能を実現できる。
- しかし、ブールインデックスを用いてベクトル空間インデックスを実現することはできない。
- 標準的なブールインデックスは重み情報を保持しないから
- 数学的には、いわゆるp-ノルムを使用してブールクエリとベクトル空間クエリを組み合わせることは可能。しかしこの事実を利用するシステムは現在のところ存在しない。
- 標準的なブールインデックスは重み情報を保持しないから
Wildcard queries
復習
- ワイルドカードクエリは、特にテキスト検索において柔軟な検索を可能にする強力な機能。
- ユーザーは、不明瞭な部分をワイルドカード(通常は*や?)で置き換えることによって、部分一致や前方一致など、あいまいなクエリを構成することができる。
- ワイルドカードで置き換えられた後の用語が複数あれば、全てクエリベクトル空間に追加される。
Vector space indexとの関係
- どちらも基本的に投稿と辞書(例えば、ワイルドカードクエリのためのトライグラムの辞書)を使用して実装できる。
- それ以外は異なる実装。
- 標準的なベクトル空間クエリに、例えばワイルドカードクエリのためのトライグラムの辞書を追加保持することで、ベクトル空間クエリを用いてワイルドカードクエリを実装できる。
- ワイルドカードクエリによって生成される複数の用語をベクトル空間内で扱い、それらをクエリベクトルに追加して、通常のベクトル空間検索と同様に文書をスコアリングしランク付けする。
Phrase queries
復習
- フレーズクエリは、文書内で特定の単語や用語が特定の順序で連続して出現することを検索条件とするクエリ。
Vector space indexとの関係
-
ベクトル空間検索は用語の出現頻度や文書内での分布を重視し、フレーズ検索は用語の正確な配置や順序を重視する。
-
一般的には、ベクトル空間検索用に構築されたインデックスは、フレーズクエリには使用できない。さらに、フレーズクエリに対するベクトル空間スコアを要求する方法はなく、文書内の各用語の相対的な重みのみがわかる。
- フレーズクエリについて、文書をベクトルとして表現することは本質的に情報の損失を伴う。文書内の用語の相対的な順序は、文書をベクトルとしてエンコードする際に失われる。
-
これら2つの検索パラダイム(フレーズとベクトル空間)は、場合によっては有用に組み合わせることができる(セクション7.2.3のクエリ解析の3ステップの例)。
参考文献
Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008.
Discussion