YOLOv8による画像判定
0. 記事の内容
群馬県産業技術センターではAI技術等をはじめとしたデジタル技術を広く県内企業の方にも活用頂けるようデジタルソリューションラボDSL [外部リンク] 等を通じて情報等の提供を行っています。ここでは、物体認識等に興味を持った技術者が容易に確認等が行えるように、静止画や動画、USBカメラ画像による確認手順や独自学習モデルの作成手順、Pythonプログラムによる利用例等について、YOLOv8を用いてまとめています。
1. はじめに
近年、プロ棋士を破った囲碁AIのAlpha Goにより注目されるようになった深層学習に基づいた物体検出が、産業界をはじめとした様々なところで利用され、その成果も広く知られるようになってきています。この第3次人工知能ブームは、2000年代から始まり機械学習や深層学習(ディープラーニング)により特徴付けられ、ビックデータを処理できるコンピュータの性能向上や機械学習の成果である顔認証、音声認識、検索機能を取入れたスマートフォンの普及などにより、日常生活をより良くする技術として、不可欠なものとなってきています。
一方、これらの機械学習や深層学習を実際に体験したり、製品に組み込んだりするためのツールも様々、開発されると供に、普通の人でも容易に利用できるようになってきています。
群馬県産業技術センターではAI技術等をはじめとしたデジタル技術を広く県内企業の方にも活用頂けるようにデジタルソリューションラボ DSL [外部リンク] 等を通じて広く情報等の提供を行っています。その一つとして、AI技術を用いた物体検出についても「AI環境の設定手順」としてYOLOv3をNVIDIA社のエッジコンピュータやWindowsパソコンへ設定するときの手順等についてインターネットの情報共有コミュニティの場であるZennで公開しています。
本手順書では、バージョンアップにより更に使い易くなったYOLOv8について学習済みモデルを用いた画像分類(Classification)、物体検出(Detection)、セグメンテーション(Segmentation)、物体追跡(Track)、姿勢推定(Pose)による物体認識に加え、画像分類、物体検出、セグメンテーションについて独自データによる学習モデルの作成手順、物体検出を利用したPythonのプログラミングについて示します。物体追跡については、改めて説明しませんが、静止画に対する物体検出を動画やUSBカメラ画像に適用すると、検出した物体に追従してゆく様子が分かります。
YOLOv8は、YOLOv3と比較して、環境設定や実行等が容易になっていますので、物体認識に興味を持ったときに、容易に確認や利用をすることが出来ます。本手順書が、実際に物体認識を体験したい方、自前のデータで物体認識をさせたい方、さらに、物体認識を利用したプログラムを作成したい方等の参考になればと思います。
但し、YOLOv8は、オーブンソースで提供され、無料で利用できまずか、ライセンスはAGPL-3.0であるため、商用で利用するときは、注意が必要です。
※ 本文中で、パスやアドレス等で「/」や「\」等が混在していますが、用いたフォントの違いによるものですので、適宜、読み替えて下さい。
2.環境設定
WindowsのインストールされたパソコンにYOLOv8をインストールし、実行するために必要な環境設定の手順を示します。
2-1. 確認環境
本手順書では、Windows 10 Pro (64-bit)に Virtual Box 5.2 を設定して、以下の仮想マシンの環境で確認を行っています。
(a) オペレーティングシステム Windows 10 Pro 64bit
(b) CPU Intel Core i7-4800MQ CPU @ 2.70GHz
(c) RAM 32GB
また、Pythonの仮想環境venvや、Anaconda-NavigatorのEnvironmentsによる仮想環境を利用しても実行可能です。
※ YOLOv8をインストールするときは、パソコンに設定されている既存の環境に影響を与えないように十分注意して行って下さい。
2-2. Pythonのインストール
YOLOv8をコマンドラインインターフェイス(CLI)で実行する場合は、Pythonの環境を必要としませんが、ここでは、YOLOv8をPythonのプログラムから実行したり、独自の学習モデルを作成したりするときに利用するアノテーション用のソフトlabelImgやlabelmeがPythonを必要とするため、ここでインストールを行います。
また、YOLOv8は、Pythonのバージョンが3.8以上で、PyTorchのバージョンが1.8以上に対応したパッケージのインストールが必要です。ここでは、labelImgやlabelmeを利用する関係からPythonのバージョン3.9.7をインストールします。
(1) ファイルのダウンロード
次のサイトより、python-3.9.7-amd64.exe をダウンロードします(図2-1)。
https://pythonlinks.python.jp/ja/index.html
図2-1 PythonのインストールプログラムのWebページ
(2) インストールの実行
a. ダウンロードしたpython-3.9.7-amd64.exeをダブルクリックして起動します。現れた画面で「Add python.exe to PATH」をチェックして、「Install Now」をクリックします(図2-2a)。
b. 「Setup was successful」の画面が現れたら、「Close」をクリックしてインストールを完了します(図2-2b)。ここで、表示されるメッセージの「Disable path length limit」の設定は通常、行う必要はありません。
(3) インストールの確認
コマンドプロンプトを起動し、次のコマンドを実行して、「Python 3.9.7」と表示されれば、インストールは正常に行われています(図2-3)。ここでは、カレントフォルダを作業用のworkにして、実行しています。
cd \work
python --version
(4) pipのアップグレード
本手順書では、YOLOv8等をpipを利用してインストールします。pipは、Pythonのパッケージのインストールなどを行うユーティリティです。ここでは、コマンドプロンプトを起動し、次のコマンドを実行して、pipをアップグレードします(図2-4)。
python -m pip install --upgrade pip
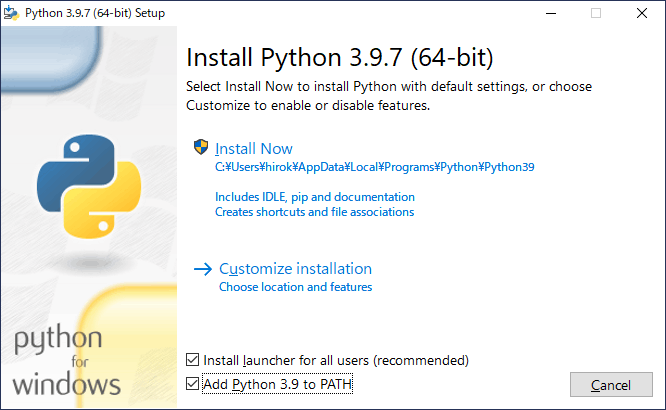
(a) インストールの設定
(b) インストールの終了
図2-2 Pythonのインストール

図2-3 Pythonのバージョンの確認
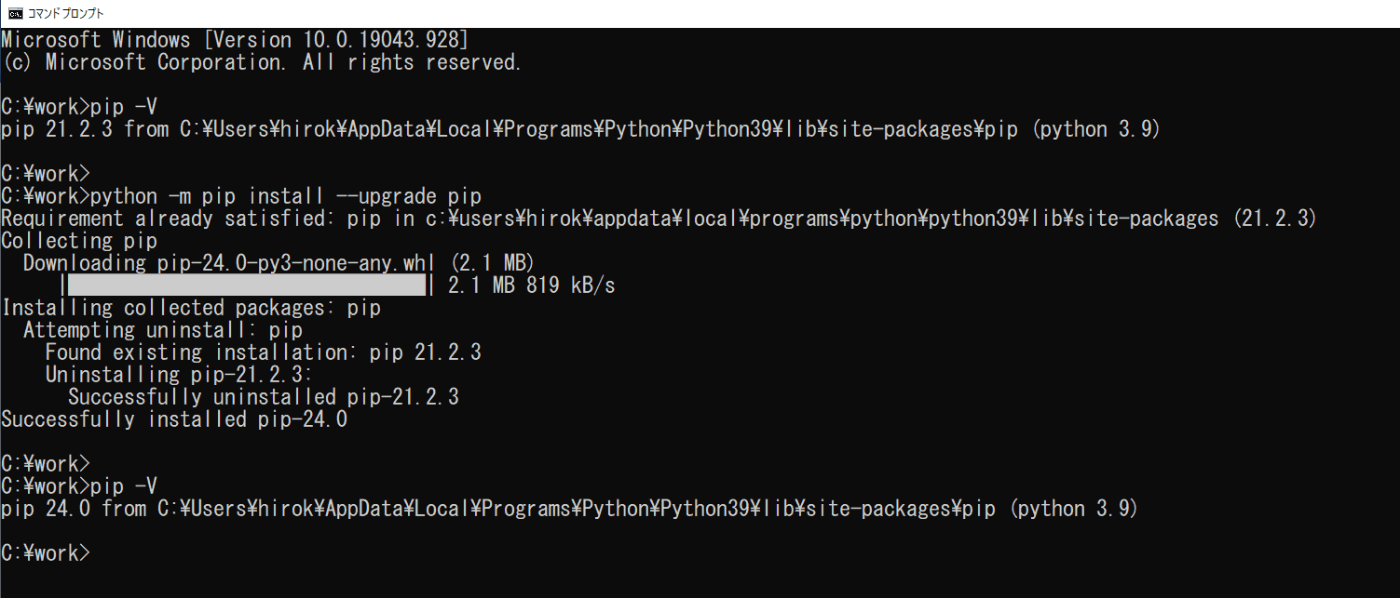
図2-4 pipの更新
2-3. YOLOv8のインストール
YOLOv8のインストールは、PyPI、または、GitHubのサイトを利用する方法があります。ここでは、PyPIのサイトからインストールを行います。
https://pypi.org/project/ultralytics/
コマンドプロンプトを起動し、次のコマンドを実行します。YOLOv8は更新が頻繁に行われているため、バージョン8.0.135を指定してインストールします(図2-5)。これは、4章で利用するアノテーションソフトlabelmeとの関係です。
pip install ultralytics==8.0.135
インストールの最後で、ダウンロードしたファイルをインストールするのに少し時間が掛かりますが、そのまま終了するのを待って下さい。
図2-5 ultralytics(YOLOv8)のインストール
3.学習済みモデルによる物体認識
3-1. 実行準備
YOLOv8で提供の事前学習されたモデルを利用して、静止画、動画、USBカメラからのリアルタイム映像に対して、物体認識を行います。
(1) 物体認識の実行
それぞれの場合について次の2種類の実行手順を示します。
コマンドラインインターフェイス(CLI)で行う方法
Pythonのプログラムで行う方法
(2) YOLOv8の提供する事前学習されたモデル
初回使用時にUltralytics のサイトから最新のモデルが自動的にダウンロードされます。
物体検出の場合、モデルの性能は次の順(添字の順、n < s < m < l < x )で増加しますが、その分、学習や推論に時間が掛かります。
YOLOv8n<YOLOv8s<YOLOv8m<YOLOv8l<YOLOv8x
ここでは、実行環境に負担の少ない「n」のモデルを利用します。
(3) 静止画と動画
静止画は、YOLOv8の紹介でよく利用されている「bus.jpg」を用います。Microsoft Edgeブラウザー等を用いて次のサイトにアクセスし、表示された画像に対し、マウスの右クリックメニューの「名前を付けて画像を保存」を選択し、ダウンロードします(図3-1)。
https://ultralytics.com/images/bus.jpg
動画は、次のサイトにアクセスし、表示された画像に対し、マウスの右クリックメニューの「名前を付けてビデオを保存」を選択し、ダウンロードします(図3-2a)。
https://storage.openvinotoolkit.org/data/test_data/videos/face-demographics-walking.mp4
また、ファイル名にマウスを合わせて右クリックメニューの「名前を付けてリンクを保存」を選択しても、ダウンロードできます(図3-2b)。各ファイルは作業フォルダのworkに移動させます。
図3-1 静止画ファイルのダウンロード
(a) 名前を付けてビデオを保存定
(b) 名前を付けてリンクを保存
図3-2 動画ファイルのダウンロード
3-2. 画像分類(Classification)
画像分類は、画像に何が映っているかを推論するもので、対象物が画像のどこにあるかは、示されません。
(1) 静止画
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します(図3-3)。
cd \work
yolo task=classify mode=predict model=yolov8n-cls.pt source='./bus.jpg'
初回の起動では、モデルをダウンロードするため時間がかかります。
推論の結果は、実行画面の最後の方の次のメッセージからどこに出力されたか分かります。
Results saved to runs /classify/predict
これより、実行時のフォルダwork内に、なければ新たにrunsフォルダが作成され、その中のclassifyフォルダのpredictフォルダに、画像が保存されます(図3-4)。ここで、predictフォルダは、実行に従って付加された番号が変更されて行きます。また、結果の画像ファイルの左上には、推論されたクラスとその信頼度が追加されています。
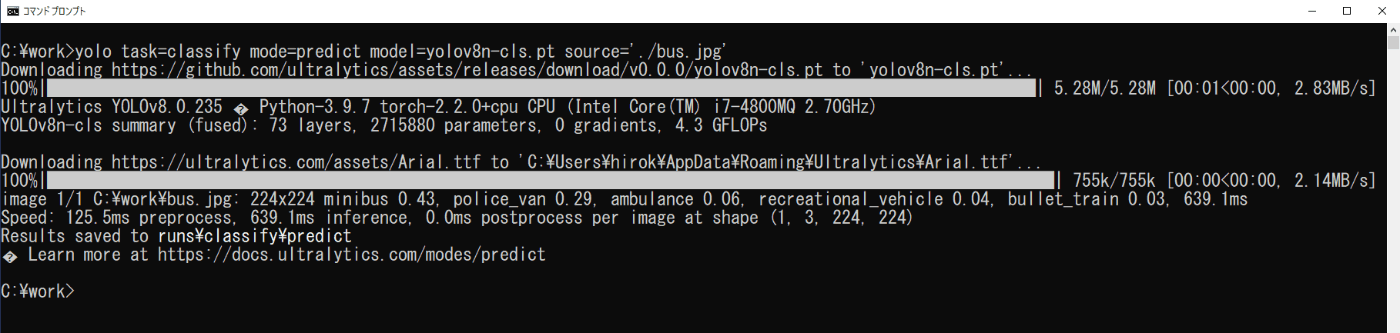
図3-3 画像分類の実行(静止画)

図3-4 画像分類の推論結果
b. Pythonプログラムで実行
リスト3-1のプログラムを「メモ帳」等のテキストエディタで入力し、ファイル名を「classify01.py」としてworkフォルダに保存し、コマンドプロンプトを起動して、workフォルダに移動して次のコマンドを実行します(図3-5)。
python classify01.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-cls.pt')
# Predict with the model
source = "./bus.jpg"
results = model.predict(source, save=True, save_txt=True, save_conf=True)
リスト3-1 プログラムリスト (classify01.py)
プログラムのmodel.predict()で用いられている引数については、以下のサイトを参照して下さい。
https://docs.ultralytics.com/ja/modes/predict/#inference-arguments
プログラムで用いたものは以下の内容です。
save : 注釈付きの画像や動画をファイルに保存します。
save_txt : 検出結果をテキストファイルに保存します。
save_conf : テキストファイルに信頼度スコアを含めます。
推論の結果は、実行画面の最後の2行から出力先が分かります。predictフォルダは、実行により順に番号が割振られ、ここではpredict2となっています。また、save_txtとsave_confの設定により、labelsフォルダの「bus.txt」ファイルに推論されたオブジェクト名とその信頼度が出力されます(図3-6)。

図3-5 Pythonでの画像分類の実行
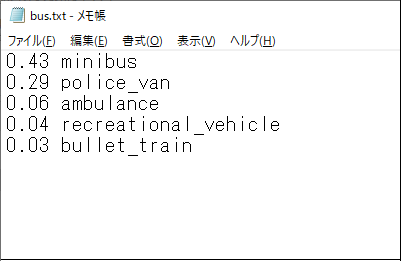
図3-6 bus.txtファイルの内容
(2) 動画
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します。
yolo task=classify mode=predict model=yolov8n-cls.pt source='./face-demographics-walking.mp4'
推論結果は、実行したコマンドプロンプトにフレームごとにクラスとその信頼度が示される(図3-7)と共に、\work\runs\classify\predict3フォルダに保存された動画にクラスとその信頼度が示されていますので、それを再生することで確認できます(図3-8)。また、コマンドに「show=True」を追加することで、実行時に動画を表示させることもできます(図3-9)。
yolo task=classify mode=predict model=yolov8n-cls.pt source='./face-demographics-walking.mp4' show=True
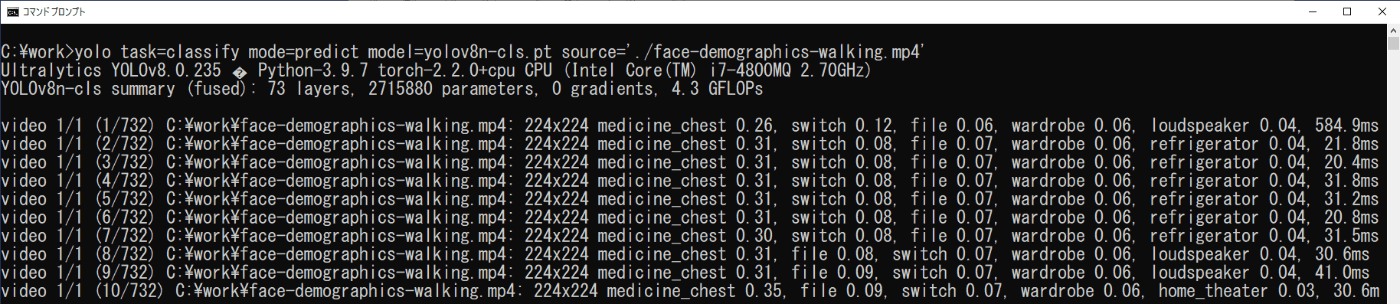
図3-7 画像分類の実行(動画)
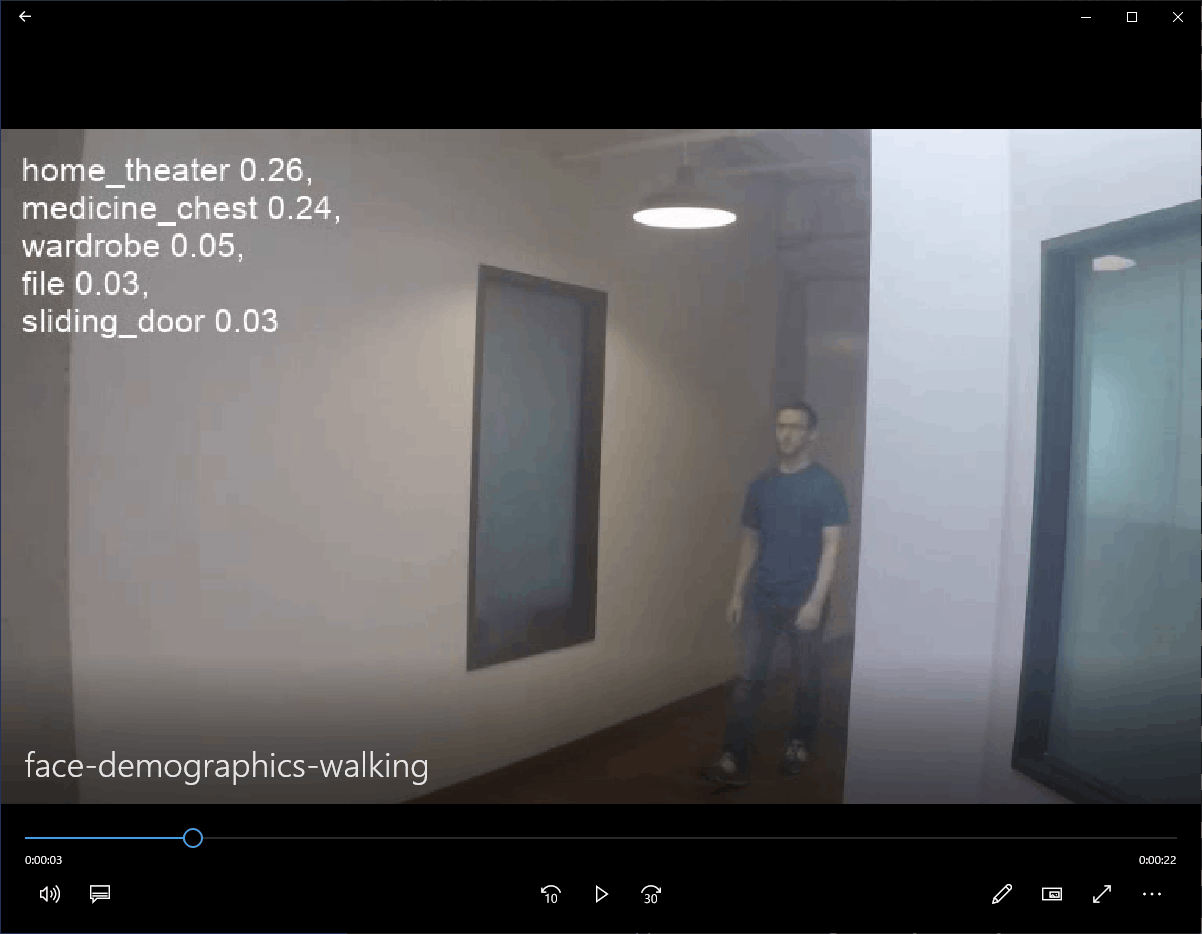
図3-8 推論結果の再生
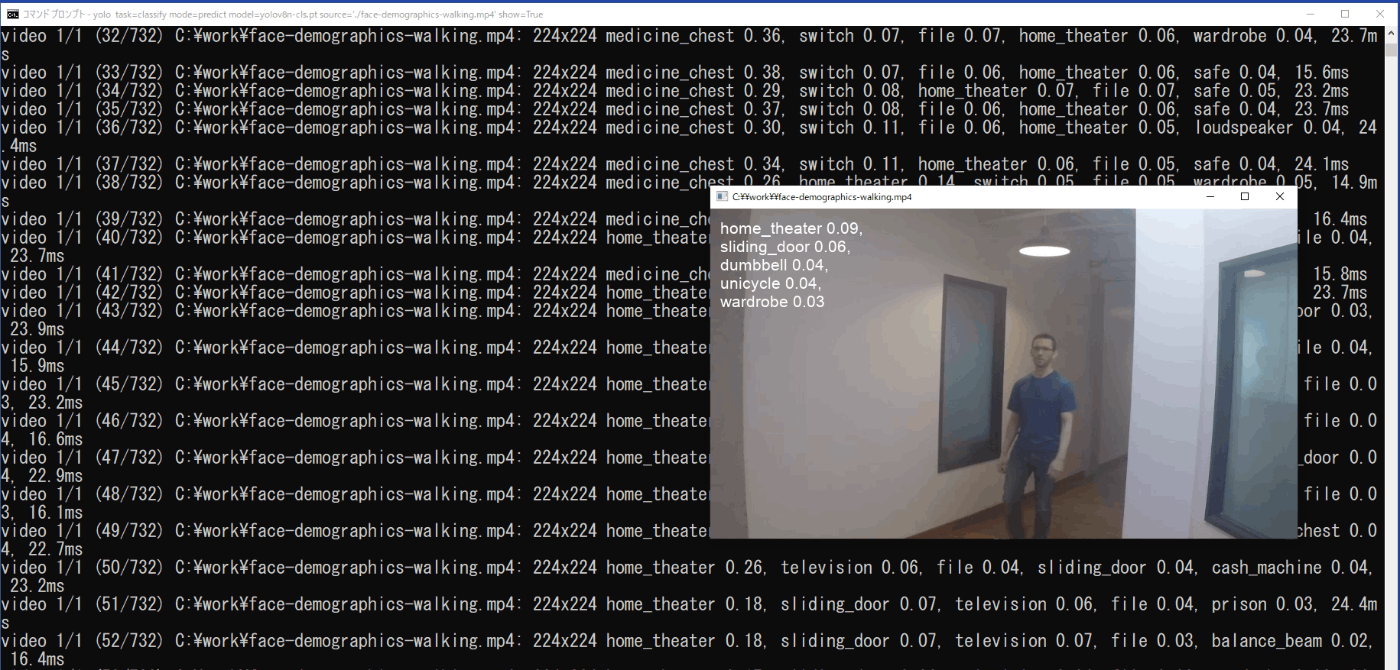
図3-9 実行時の動画表示
b. Pythonプログラムで実行
リスト 3-2のプログラムをファイル名「classify02.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python classify02.py
推論結果は、show=Trueを設定しているため、実行時に表示の動画で確認できます。また、save_txtとsave_confを設定しているため、\work\runs\classify\predict4\labelsフォルダに動画のフレームごとに、クラスとその信頼度の設定されたファイルが作成されます。しかし、ファイルが多く作成されるため、必要に応じてsave_txtとsave_confの設定をすると良いと思います。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-cls.pt')
# Predict with the model
source = "./face-demographics-walking.mp4"
results = model.predict(source, save=True, save_txt=True, save_conf=True, show=True)
リスト3-2 プログラムリスト (classify02.py)
(3) カメラ映像
付録 Aで示したように、YOLOv8をインストールすると、USBカメラを利用するための環境も設定されています。
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します。
yolo task=classify mode=predict model=yolov8n-cls.pt source=0 show=True
推論結果は、show=Trueにより、実行時の動画に表示されると供に、\work\runs\classify\predict5に動画「0.avi」として保存されます。また、bus.jpgを印刷したものをUSBカメラで映しているときの実行時の様子を図3-10に示します。
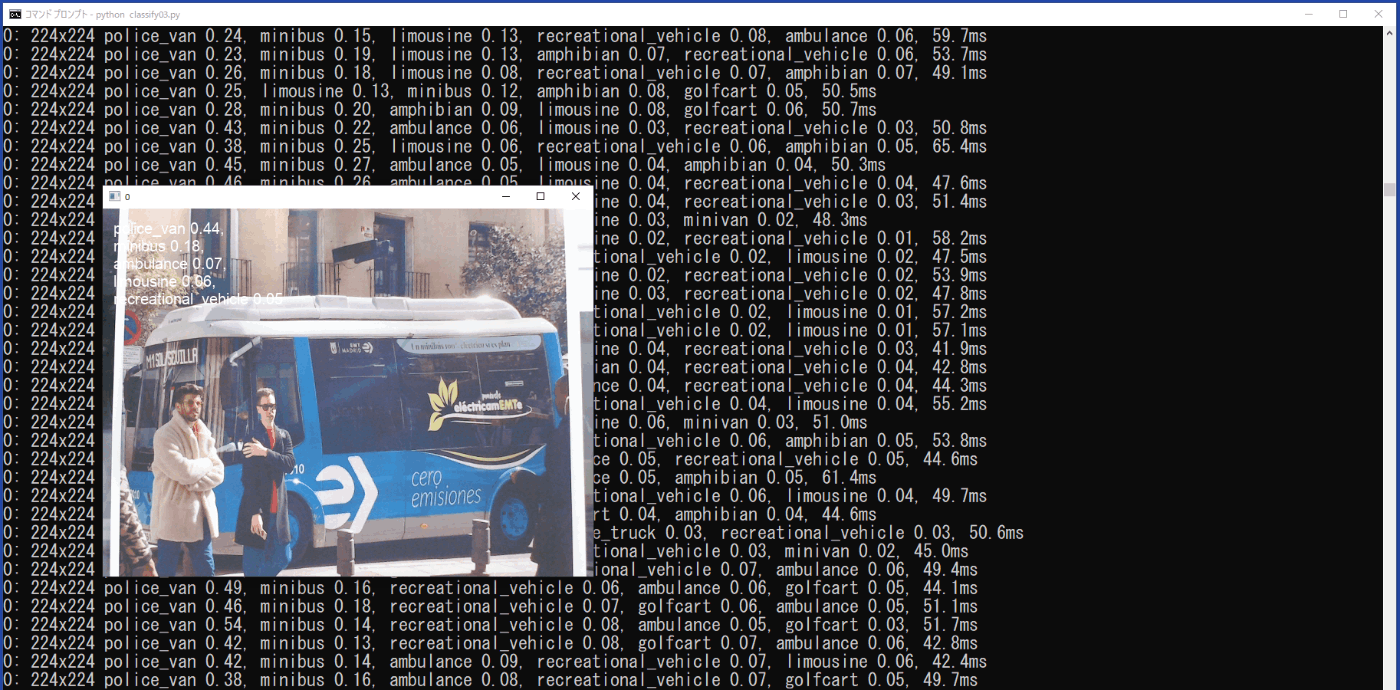
図3-10 USBカメラの動画の推論結果
b. Pythonプログラムで実行
リスト3-3のプログラムをファイル名「classify03.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python classify03.py
動画の場合と同様に、推論結果は、show=Trueにより、実行時の動画に表示されると供に、
\work\runs\classify\predict6に動画「0.avi」として保存されます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-cls.pt')
# Predict with the model
source = 0
results = model.predict(source, save=True, show=True)
リスト3-3 プログラムリスト (classify03.py)
3-3. 物体検出(Detection)、物体追跡(Track)
物体検出は、画像の中の対象物の位置を推定し、矩形枠でその場所が示されます。
(1) 静止画
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します(図3-11)。
yolo task=detect mode=predict model=yolov8n.pt source='./bus.jpg' show=True
推論の結果は、show=Trueにより画像に矩形枠とクラス、信頼度が表示されます(図3-12)が、一瞬のため、実際には、\work\runs\detect\predictフォルダに、保存される画像ファイルで結果を確認することになります。
図3-11 物体検出の実行(静止画)
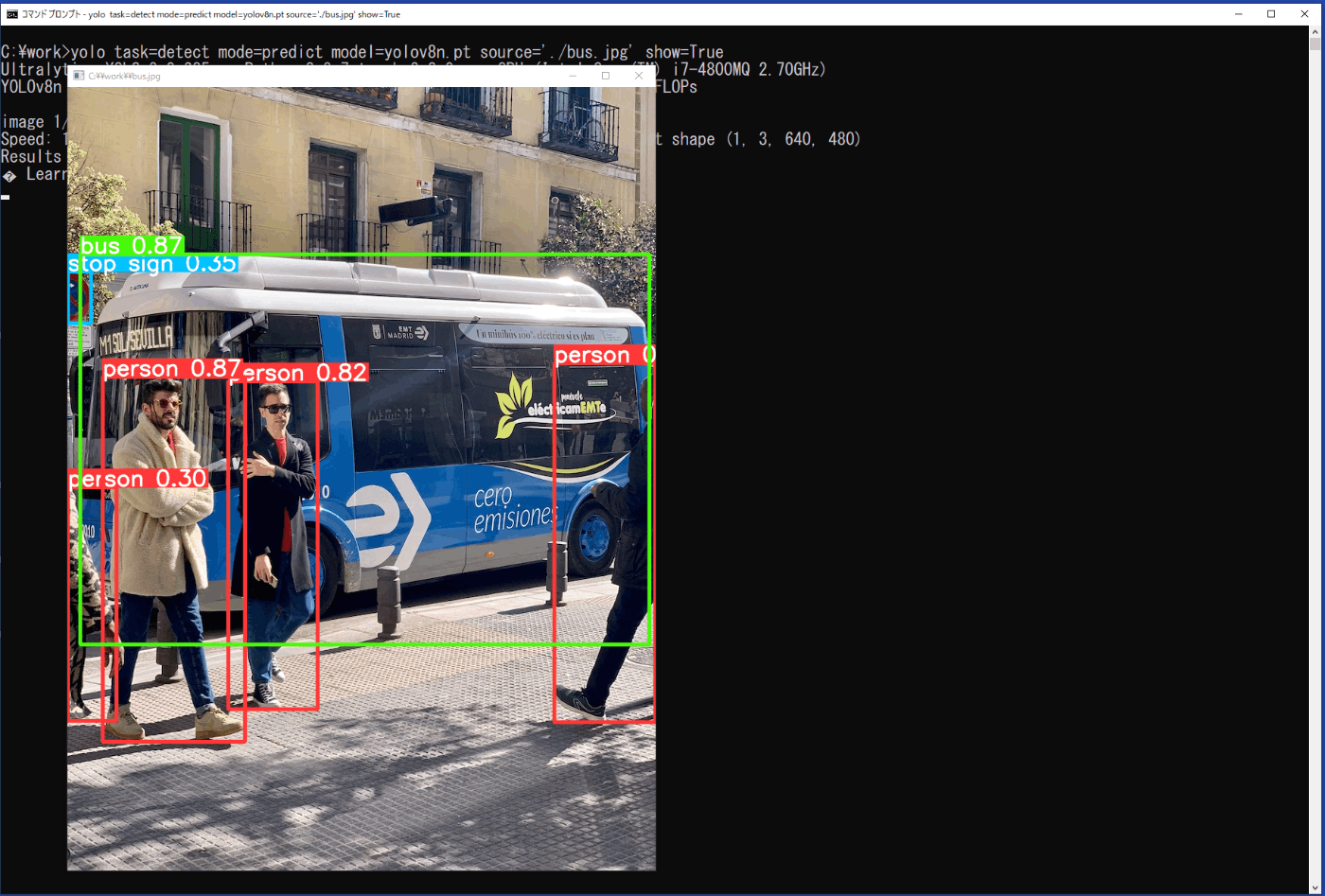
図3-12 物体検出の実行時の推論結果(静止画)
b. Pythonプログラムで実行
リスト3-4のプログラムをファイル名「detect01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python detect01.py
画像分類(Classification)の場合と同様に、\work\runs\detect\predict2\labelsフォルダに、bus.txtが出力されます(図3-13)。それぞれの行には、矩形枠ごとに、クラスの番号、矩形枠の中心のx,y座標と幅と高さ、信頼度が出力されています。
ここで、クラスの番号は、学習モデルとして80個が設定されていて、例えば、次のようになっています。
0: person
5: bus
11: stop sign
また、矩形枠の座標は画像の左上隅が(0,0)で、画像の幅と高さで正規化された値です。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt')
# Predict with the model
source = "./bus.jpg"
results = model.predict(source, save=True, save_txt=True, save_conf=True, show=True)
リスト3-4 プログラムリスト (detect01.py)

図3-13 bus.txtの内容
(2) 動画
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します。
yolo task=detect mode=predict model=yolov8n.pt source='./face-demographics-walking.mp4' show=True
推論結果は、実行したコマンドプロンプトにフレームごとにクラスと信頼度が示されると供に、show=Trueにより矩形枠とクラス、信頼度の表示された動画も表示されます(図3-14)。
また、この矩形枠とクラス、信頼度の表示された動画は、\work\runs\detect\predict3フォルダに保存されます。
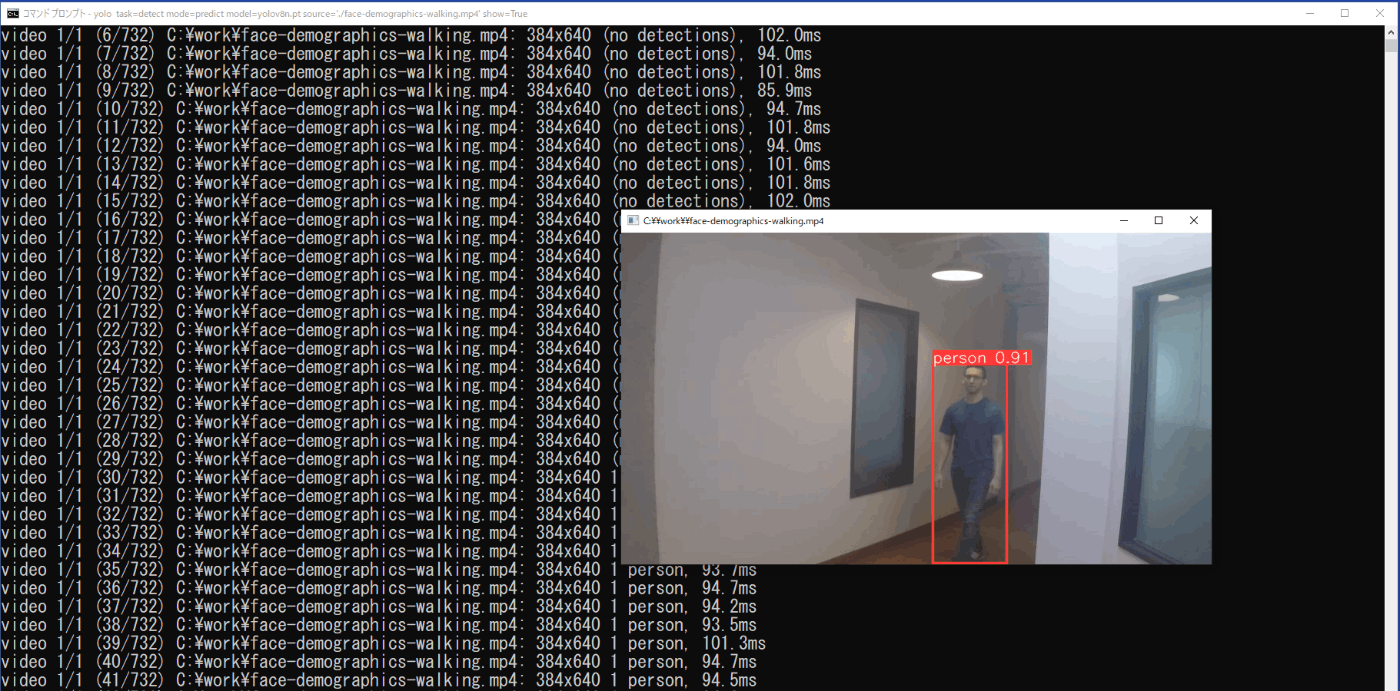
図3-14 物体検出の実行時の推論結果(動画)
b. Pythonプログラムで実行
リスト3-5のプログラムをファイル名「detect02.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python detect02.py
推論結果は、show=Trueを設定しているため、実行時に動画が表示されます。また、\work\runs\detect\predict4フォルダに矩形枠とクラス、信頼度の表示された動画が保存されます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt')
# Predict with the model
source = "./face-demographics-walking.mp4"
results = model.predict(source, save=True, show=True)
リスト3-5 プログラムリスト (detect02.py)
(3) カメラ映像
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します。
yolo task=detect mode=predict model=yolov8n.pt source=0 show=True
推論結果は、show=Trueにより、実行時の動画に矩形枠とクラス、信頼度が表示されると供に、\work\runs\detect\predict5に動画「0.avi」として保存されます。また、bus.jpgを印刷したものをUSBカメラで映しているときの実行時の様子を図3-15に示します。
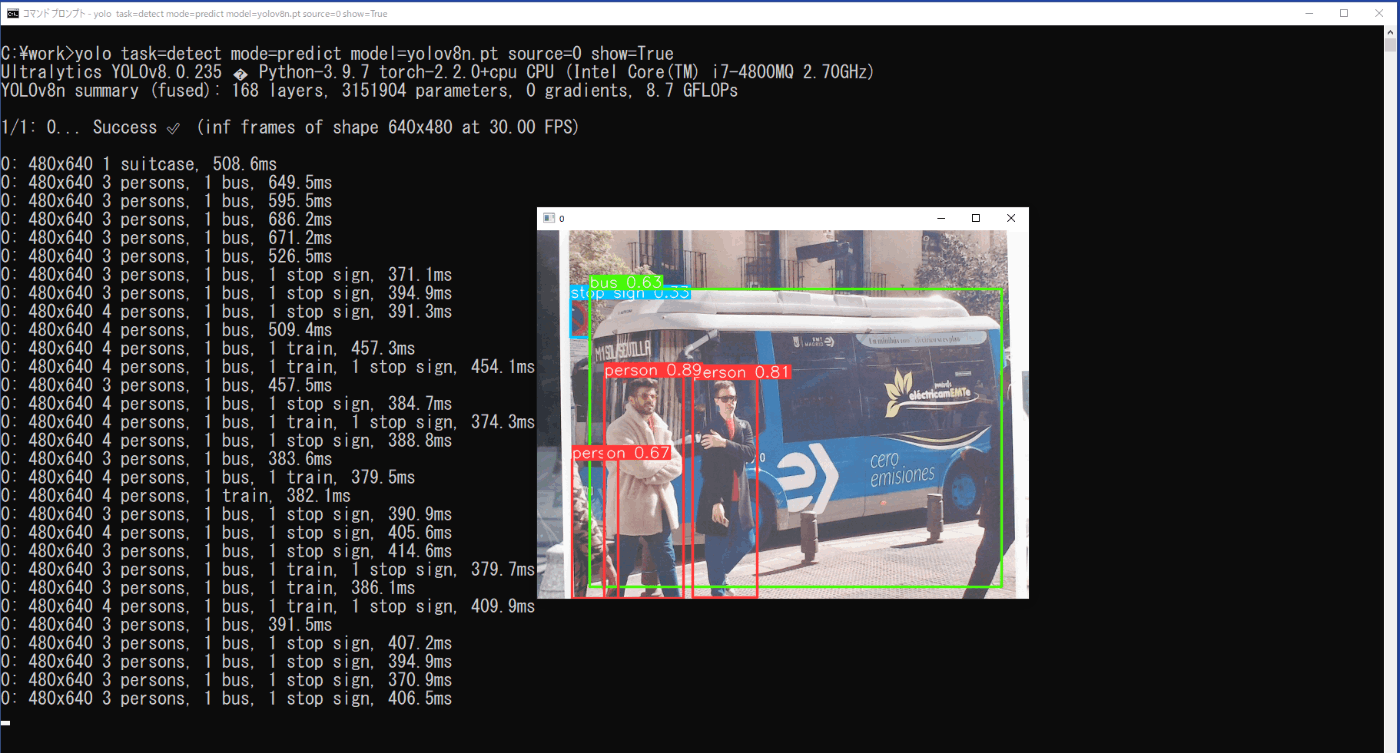
図3-15 USBカメラの動画の推論結果
b. Pythonプログラムで実行
リスト3-6のプログラムをファイル名「detect03.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python detect03.py
動画の場合と同様に、推論結果は、show=Trueにより、実行時の動画に矩形枠とクラス、信頼度が表示されると供に、\work\runs\detect\predict6に動画「0.avi」として保存されます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt')
# Predict with the model
source = 0
results = model.predict(source, save=True, show=True)
リスト3-6 プログラムリスト (detect03.py)
3-4. セグメンテーション(Segmentation)
セグメンテーションは、画像の中にある対象物の形も含めて、その場所が示されます。
(1) 静止画
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します(図3-16)。
yolo task=segment mode=predict model=yolov8n-seg.pt source='./bus.jpg' show=True
推論の結果は、show=Trueにより画像に矩形枠と対象の塗りつぶし、クラス、信頼度が表示されます(図3-17)が、一瞬のため、実際には、\work\runs\segment\predictフォルダに、保存される画像ファイルで結果を確認することになります。

図3-16 セグメンテーションの実行(静止画)
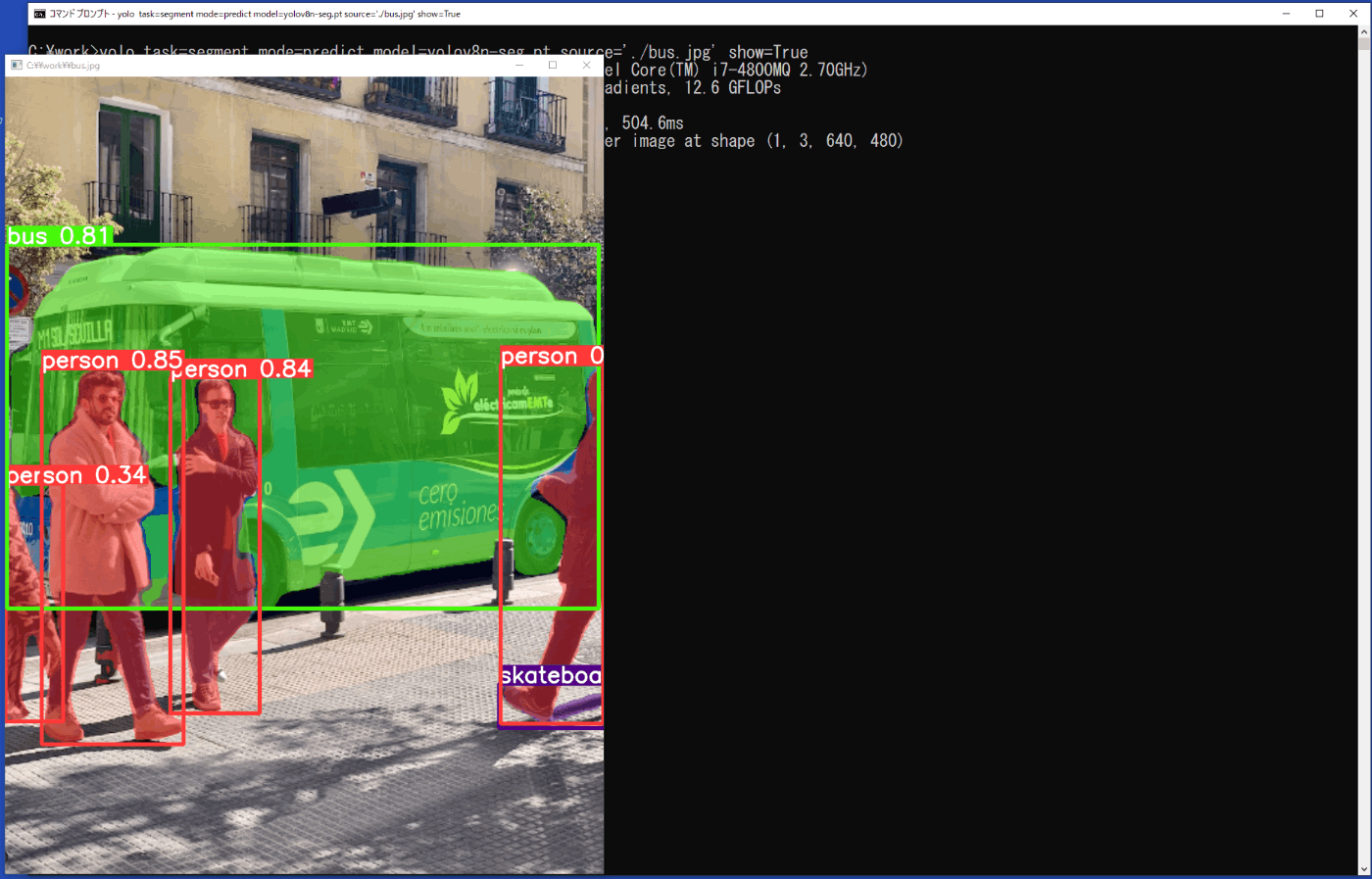
図3-17 セグメンテーションの実行時の推論結果(静止画)
b. Pythonプログラムで実行
リスト3-7のプログラムをファイル名「segment01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python segment01.py
画像分類(Classification)の場合と同様に、\work\runs\segment\predict2\labelsフォルダに、bus.txtが出力されます(図3-18)。それぞれの行には、矩形枠ごとに、クラスの番号、塗りつぶしの多角形の座標、信頼度が出力されています。矩形枠の座標もあると思いますが、判別ができません。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-seg.pt')
# Predict with the model
source = "./bus.jpg"
results = model.predict(source, save=True, save_txt=True, save_conf=True, show=True)
リスト3-7 プログラムリスト (segment01.py)

図3-18 bus.txtの内容
(2) 動画
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します。
yolo task=segment mode=predict model=yolov8n-seg.pt source='./face-demographics-walking.mp4' show=True
推論結果は、実行したコマンドプロンプトにフレームごとにクラスと信頼度が示されると供に、show=Trueにより矩形枠と対象の塗りつぶし、クラス、信頼度の表示された動画も表示されます(図3-19)。また、この矩形枠と対象の塗りつぶし、クラス、信頼度の表示された動画は、\work\runs\segment\predict3フォルダに保存されます。
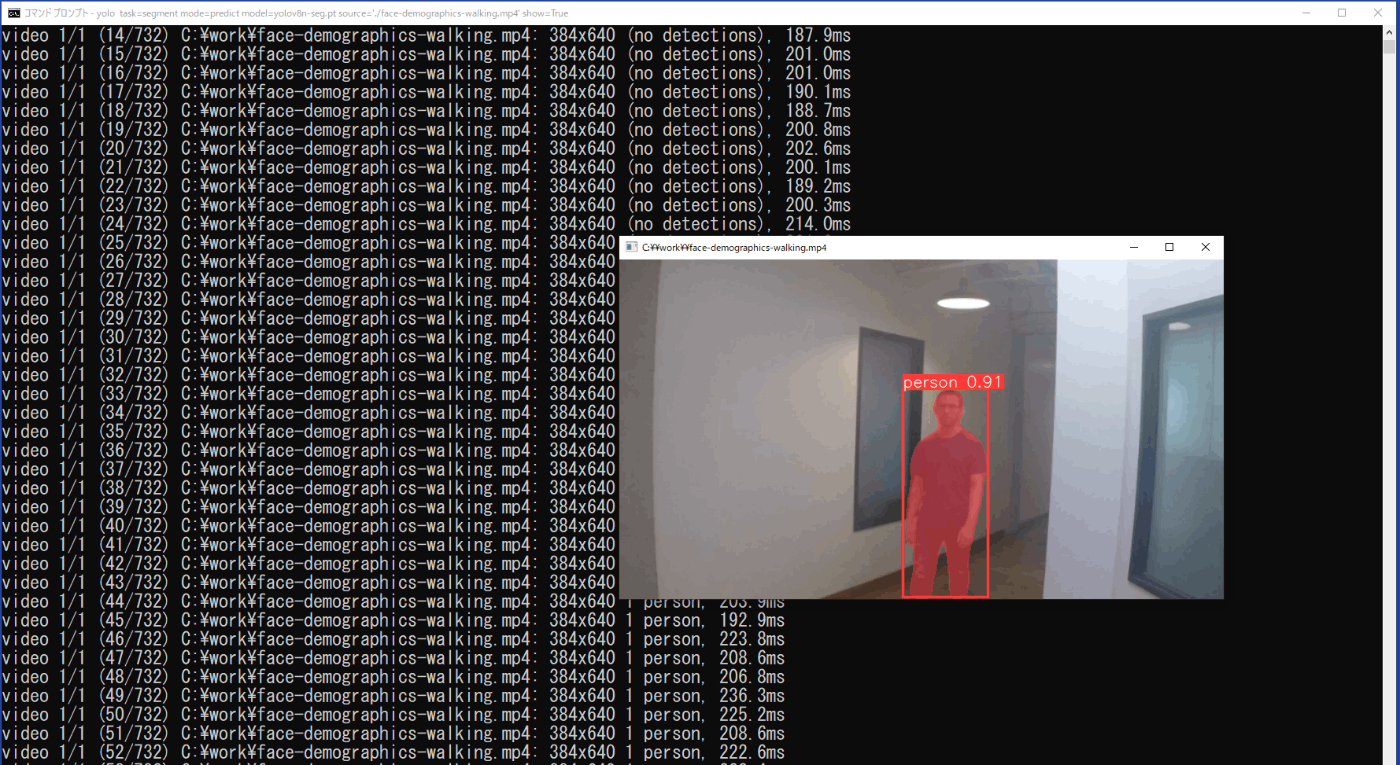
図3-19 セグメンテーションの実行時の推論結果(動画)
b. Pythonプログラムで実行
リスト3-8のプログラムをファイル名「segment02.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python segment02.py
推論結果は、show=Trueを設定しているため、実行時に動画が表示されます。また、\work\runs\segment\predict4フォルダに矩形枠と対象の塗りつぶし、クラス、信頼度の表示された動画が保存されます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-seg.pt')
# Predict with the model
source = "./face-demographics-walking.mp4"
results = model.predict(source, save=True, show=True)
リスト3-8 プログラムリスト (segment02.py)
(3) カメラ映像
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します。
yolo task=segment mode=predict model=yolov8n-seg.pt source=0 show=True
推論結果は、show=Trueにより、実行時の動画に矩形枠と対象の塗りつぶし、クラス、信頼度が表示される(図3-20)と供に、\work\runs\segment\predict5に動画「0.avi」として保存されます。
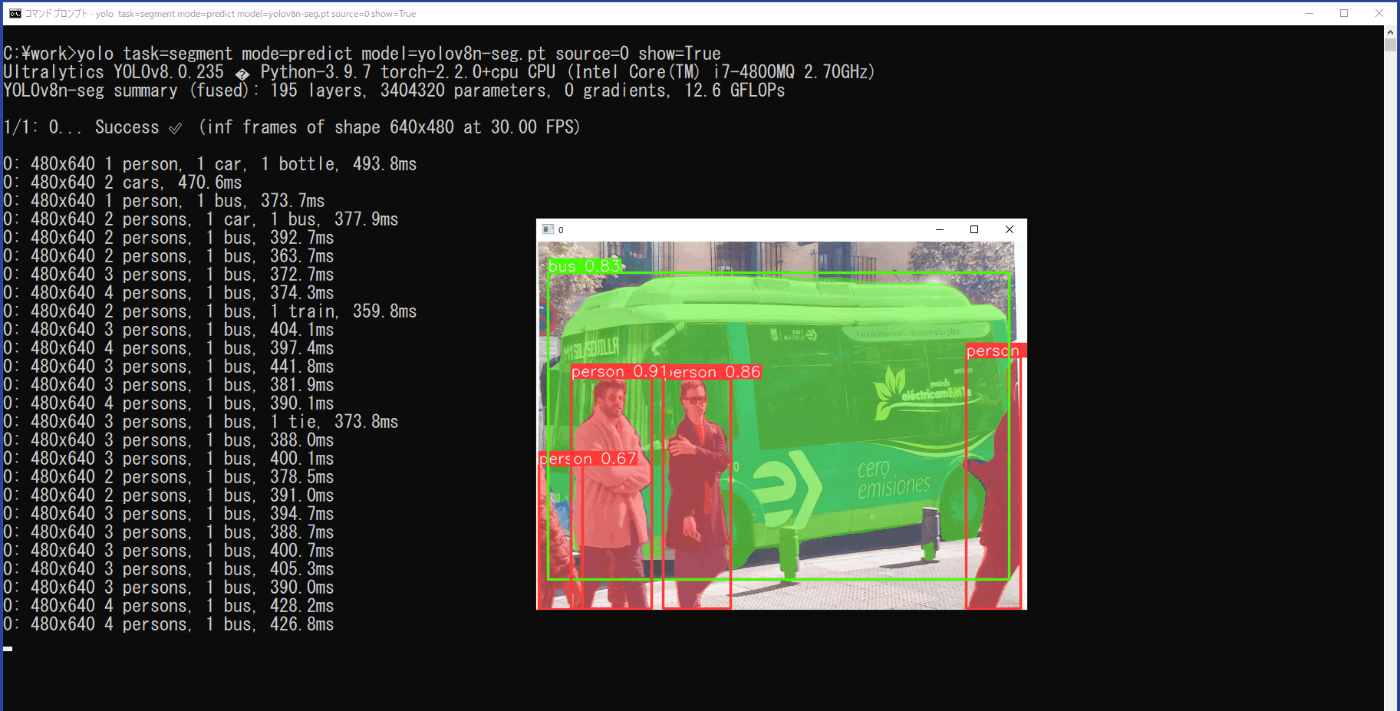
図3-20 USBカメラの動画の推論結果
b. Pythonプログラムで実行
リスト3-9のプログラムをファイル名「segment03.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python segment03.py
動画の場合と同様に、推論結果は、show=Trueにより、実行時の動画に矩形枠と対象の塗りつぶし、クラス、信頼度が表示されると供に、\work\runs\segment\predict6に動画「0.avi」として保存されます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-seg.pt')
# Predict with the model
source = 0
results = model.predict(source, save=True, show=True)
リスト3-9 プログラムリスト (segment03.py)
3-5. 姿勢推定(Pose)
姿勢推定は、目や鼻、肘や膝などの特徴点を推定して、それらの部分を線で結び骨格のように表示するものです。
(1) 静止画
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します(図2-21)。
yolo task=pose mode=predict model=yolov8n-pose.pt source='./bus.jpg' show=True
推論の結果は、show=Trueにより画像に矩形枠と特徴点を結んだ線、クラス、信頼度が表示されます(図2-22)が、一瞬のため、実際には、\work\runs\pose\predictフォルダに、保存される画像ファイルで結果を確認することになります。
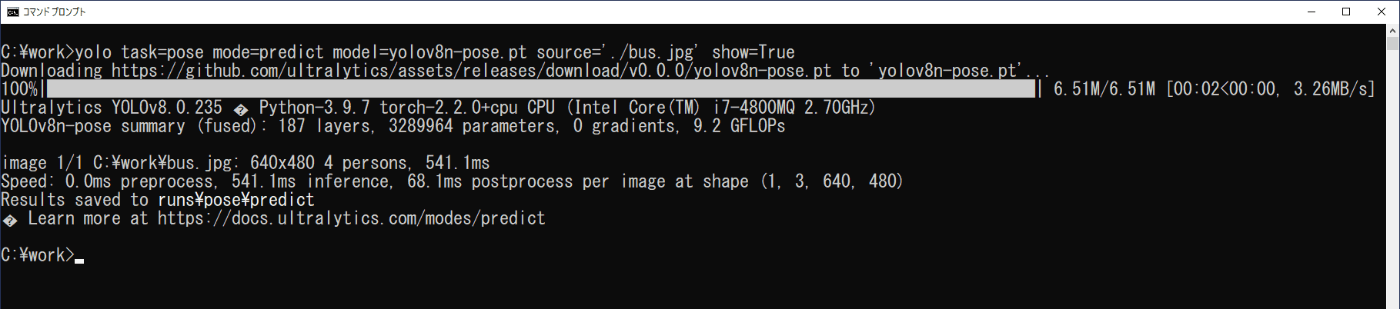
図3-21 姿勢推定の実行(静止画)
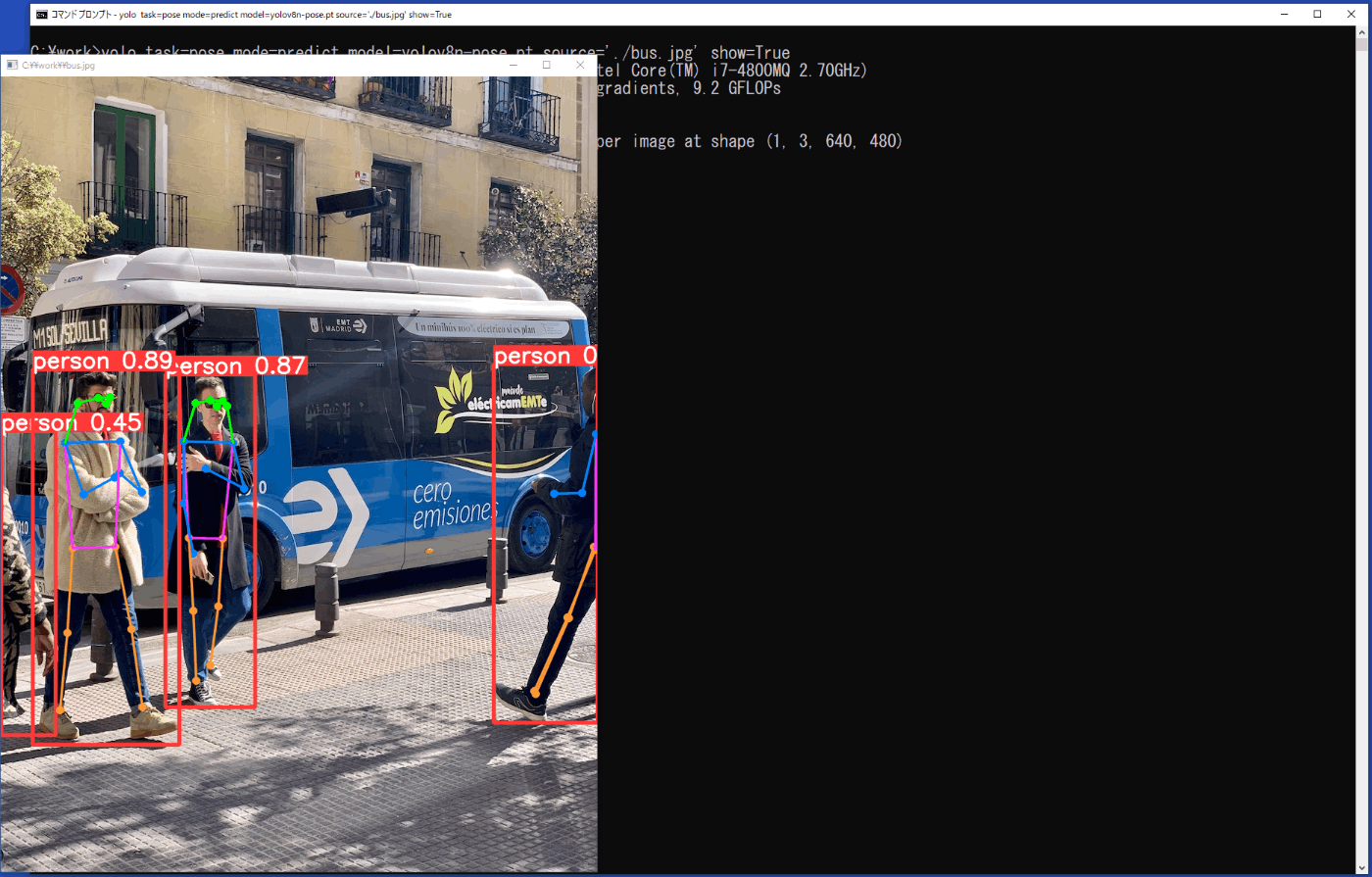
図3-22 姿勢推定の実行時の推論結果(静止画)
b. Pythonプログラムで実行
リスト3-10のプログラムをファイル名「pose01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python pose01.py
画像分類(Classification)の場合と同様に、\work\runs\pose\predict2\labelsフォルダに、bus.txtが出力されます(図3-23)。それぞれの行には、矩形枠ごとに、クラスの番号、特徴点の座標、信頼度が出力されています。矩形枠の座標もあると思いますが、判別ができません。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-pose.pt')
# Predict with the model
source = "./bus.jpg"
results = model.predict(source, save=True, save_txt=True, save_conf=True, show=True)
リスト3-10 プログラムリスト (pose01.py)

図3-23 bus.txtの内容
(2) 動画
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します。
yolo task=pose mode=predict model=yolov8n-pose.pt source='./face-demographics-walking.mp4' show=True
推論結果は、実行したコマンドプロンプトにフレームごとにクラスと信頼度が示されると供に、show=Trueにより矩形枠と特徴点を結んだ線、クラス、信頼度の表示された動画も表示されます(図3-24)。また、この矩形枠と特徴点を結んだ線、クラス、信頼度の表示された動画は、\work\runs\pose\predict3フォルダに保存されます。
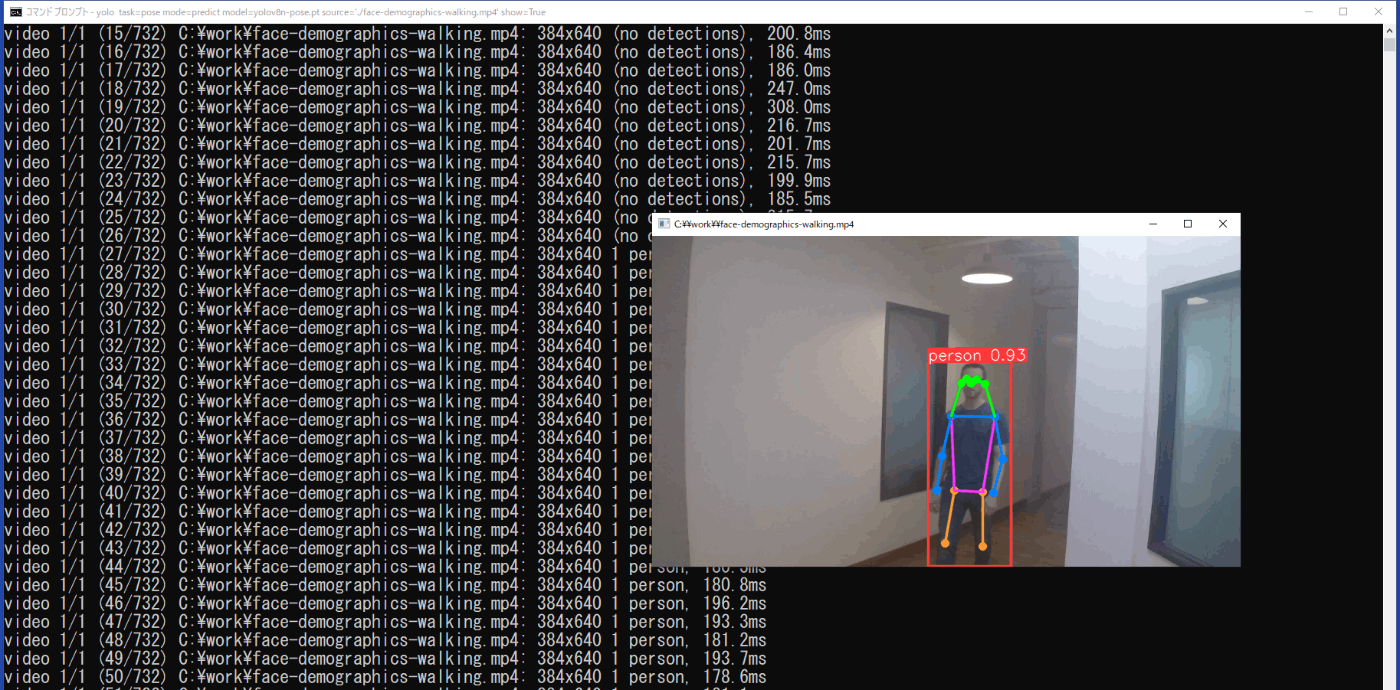
図3-24 姿勢推定の実行時の推論結果(動画)
b. Pythonプログラムで実行
リスト3-11のプログラムをファイル名「pose02.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python pose02.py
推論結果は、show=Trueを設定しているため、実行時に動画が表示されます。また、\work\runs\pose\predict4フォルダに矩形枠と特徴点を結んだ線、クラス、信頼度の表示された動画が保存されます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-pose.pt')
# Predict with the model
source = "./face-demographics-walking.mp4"
results = model.predict(source, save=True, show=True)
リスト3-11 プログラムリスト (pose02.py)
(3) カメラ映像
a. コマンドラインインターフェイスで実行
コマンドプロンプトを起動し、次のコマンドを実行します。
yolo task=pose mode=predict model=yolov8n-pose.pt source=0 show=True
推論結果は、show=Trueにより、実行時の動画に矩形枠と特徴点を結んだ線、クラス、信頼度が表示される(図3-25)と供に、\work\runs\pose\predict5に動画「0.avi」として保存されます。
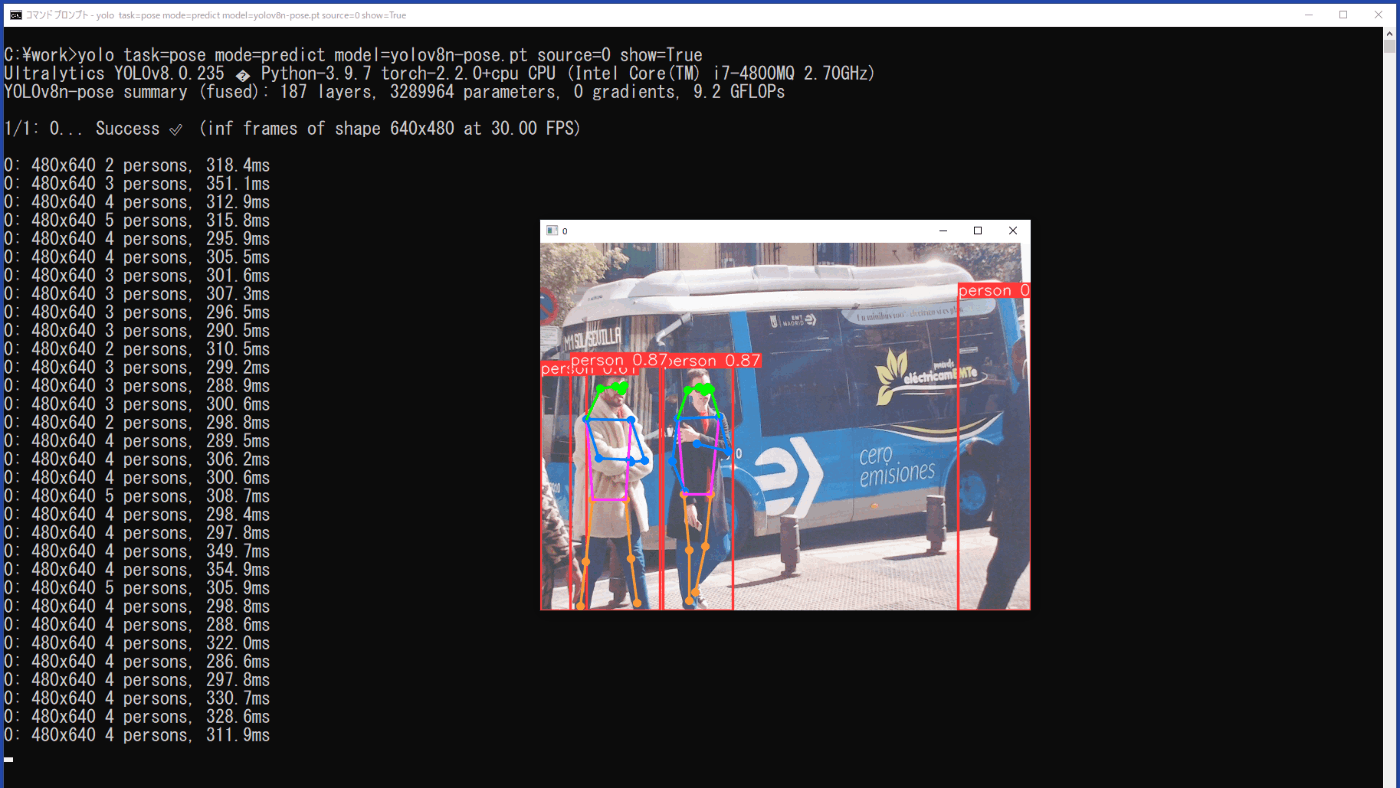
図3-25 USBカメラの動画の推論結果
b. Pythonプログラムで実行
リスト3-12のプログラムをファイル名「pose03.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します。
python pose03.py
動画の場合と同様に、推論結果は、show=Trueにより、実行時の動画に矩形枠と特徴点を結んだ線、クラス、信頼度が表示されると供に、\work\runs\pose\predict6に動画「0.avi」として保存されます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n-pose.pt')
# Predict with the model
source = 0
results = model.predict(source, save=True, show=True)
リスト3-12 プログラムリスト (pose03.py)
4.独自学習モデルによる物体認識
物体認識では、検出したい対象が学習済みモデルに含まれている場合は、そのモデルをそのまま利用することができますが、含まれていない場合は、新たなモデルを作成するために必要な画像を準備し、学習をさせる必要があります。ここでは、3種類の物体認識の方法に対して、学習の手順を示します。
4-1. 学習データ
画像は、付録Aを利用して取得したじゃんけんの480x480ピクセルのJPEG画像で、Rock(R)、Scissors(S)、Paper(P)のそれぞれ70個の画像を用います(図4-1)。
クラスはRock(R)、Scissors(S)、Paper(P)の3種類とし、70個の画像をそれぞれ、学習用(train)に50個、評価用(val)に10個、確認用(test)に10個を割り当るようにします。

図4-1 学習用の画像 (Rock、Scissors、Paper)
Windowsでは、ファイル名を変更するためにコマンドプロンプトを起動してrenやmoveコマンドを利用することができますが、ファイル名を一括して変更するときに、うまく行かないことがあります。ここでは、ファイル名がABC*.jpgで始まる任意のファイルをOK_ABC*.jpgのように、ファイル名を一括して変換するバッチファイルをリスト4-1に示します。「file_rename01.bat」のファイル名で保存したものを、変更するファイルのあるフォルダにコピーし、コマンドプロンプトからそのフォルダに移動して、file_rename01を実行します。
@echo off
for %%f in (ABC*.jpg) do call :change %%f <== どのファイルか
exit /b
:change
set fileName=%1
set fileName=%fileName:ABC=OK_ABC% <== どの文字を何に変えるか
ren %1 %fileName%
リスト4-1 ファイル名の変更 (file_rename01.bat)
4-2. 画像分類(Classification)
(1) 学習ファイルの設定
作業フォルダworkに、フォルダdatasetsを作成し、その中に画像分類用のフォルダhands_classificationを作成し、次の図4-2のフォルダ構成として、ファイルを配置します。ここで、矩形で囲まれたものはフォルダを表します。クラスはフォルダ名のRock、Scissors、Paperが割り当てられます。
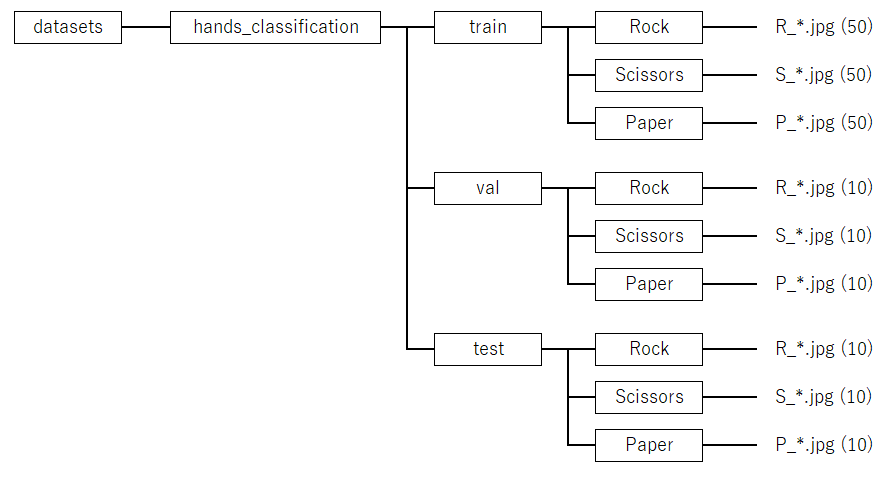
図4-2 学習ファイルの構成(画像分類)
(2) 学習の実行
リスト4-2のプログラムをファイル名「classify_train01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図4-3a,b)。
python classify_train01.py
model.train()の命令で用いられる引数については、次のサイトを参照して下さい。
https://docs.ultralytics.com/ja/modes/train/#train-settings
学習はepochsにより50回を設定し、imgszは画像のピクセルによるサイズを設定、fliplrはYOLOv8が左右対称の対象を画像の反転等により作り出して学習することを設定するものですが、ここでは反転の学習を行わない設定としています。また、リスト4-2の最後の命令model.val()はなくても、model.train()の命令でvalフォルダの画像を用いて評価するようです。
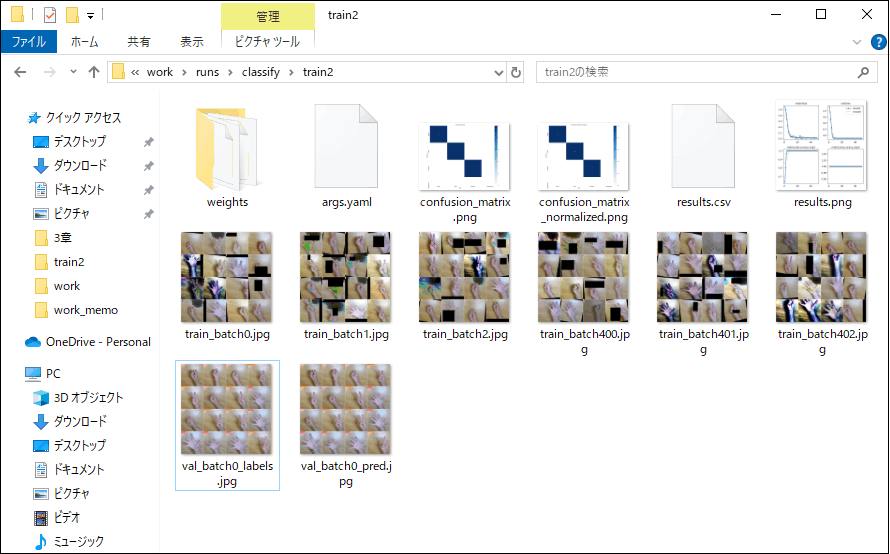
学習した結果は、作業フォルダ内の\work\runs\classifyに作成されたtrainフォルダに出力されます(図4-4a,b)。実行時の表示内容(図4-3b)から、model.train()の結果はtrain2に、model.val()の結果はtrain22にそれぞれ出力されたことが分かります。
また、confusion_matrix.pngファイルから、学習により、valフォルダの3種類の各10個の画像に対し、いずれも正しく推論されていることが分かります。学習したモデルは、weightsフォルダに、学習の繰り返しの最後のlast.ptと、最善のスコアのbest.ptが出力されます。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a pretrained YOLO model
model = YOLO('yolov8n-cls.pt')
# Train the model
dataset_path = "./datasets/hands_classification"
results = model.train(data=dataset_path, epochs=50, imgsz=480, fliplr=0.0)
# Evaluate the model's performance on the validation set
results = model.val()
リスト4-2 学習用プログラム (classify_train01.py)
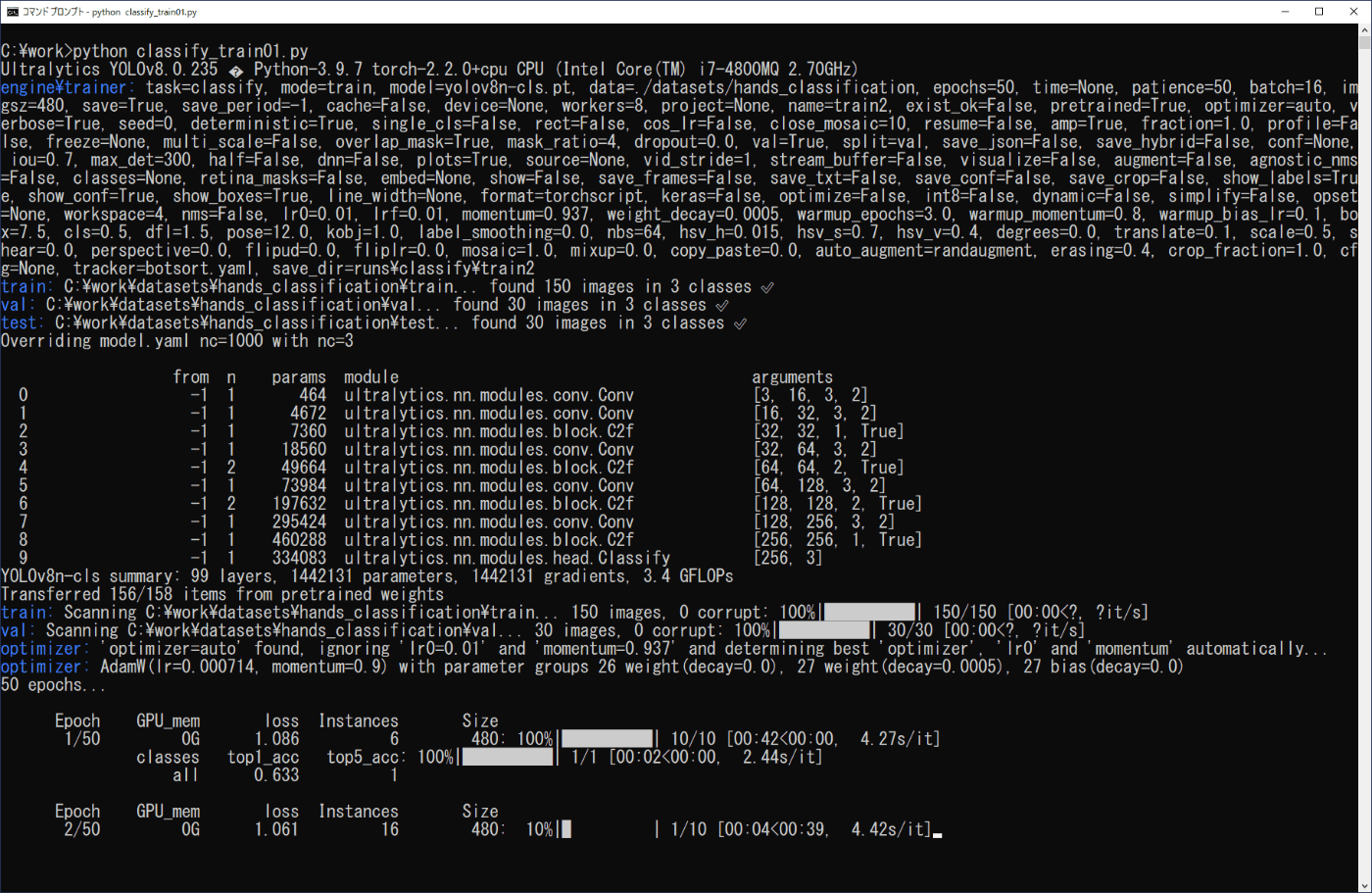
(a) 開始部分
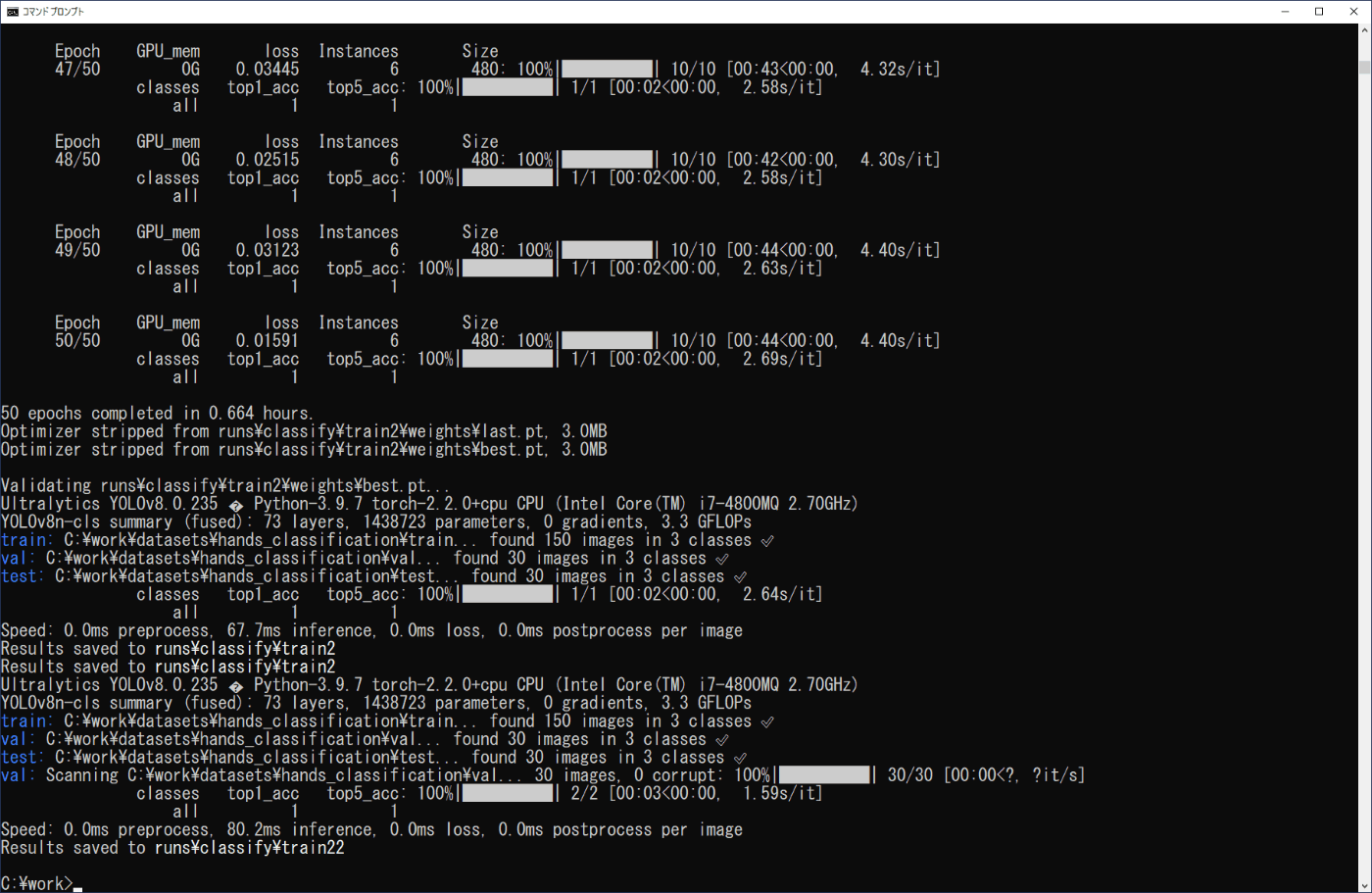
(b) 終了部分
図4-3 学習の実行(画像分類)
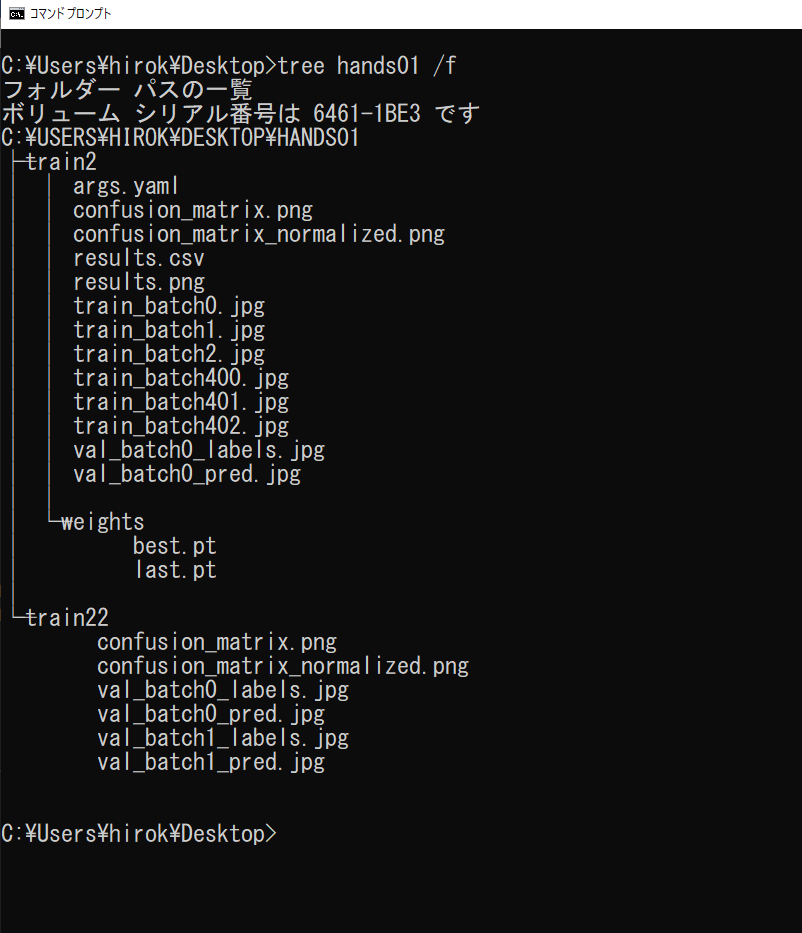
(a) 学習結果のフォルダ構成
(b) 学習結果のフォルダ
図4-4 学習結果(画像分類)
(3) 学習モデルを利用した画像分類
学習したモデルによる画像分類は、3章の学習済みモデルを利用した場合と同様に行うことができます。ここでは、3-2節の場合と同様にPythonプログラムで実行を行います。学習モデルはbest.ptを用い、確認する画像は、事前に準備したtestフォルダの画像(各10個)を、work\datasets\hands_classification_others\test_run01フォルダにまとめます。リスト4-3のプログラムをファイル名「classify_run01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図4-5)。
python classify_run01.py
\work\runs\classify\predictフォルダに出力された画像を確認すると、正しく推論されていることが分かります。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('./runs/classify/train2/weights/best.pt')
# Predict with the model
source = "./datasets/hands_classification_others/test_run01"
results = model.predict(source, save=True, save_txt=True, save_conf=True)
リスト4-3 プログラムリスト (classify_run01.py)
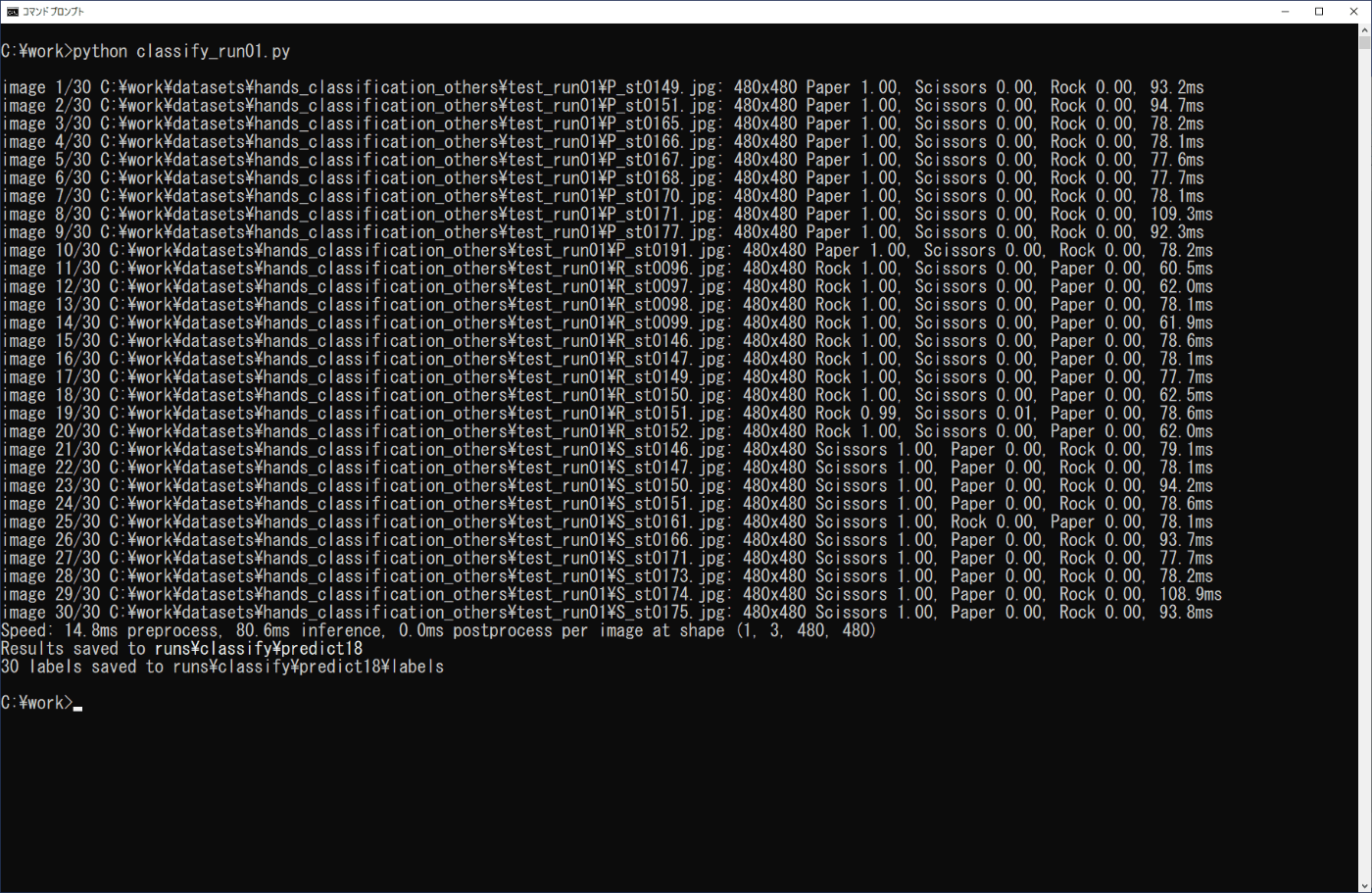
図4-5 学習モデルの実行(画像分類)
4-3. 物体検出(Detection)
(1) 学習ファイルの設定
\work\datasetsフォルダに物体検出用のフォルダhands_detectionを作成し、次の図4-6のフォルダ構成として、ファイルを配置します。ここで、train、val、testの各フォルダには3種類のファイルをまとめます。このとき、事前にファイル名の重複がないようにリスト 4-1のバッチファイル等を利用してファイル名を変更するなど注意が必要です。各ファイルがどのクラスに対応するかは、検出したい対象の位置を画像ごとにラベリングするアノテーションにより設定します。また、labelsのフォルダは、アノテーションによる結果を保存するためのもので、最初は空のフォルダです。dataset_detect.yamlは、学習をさせるときに必要な設定のファイルで、学習の前に作成します。
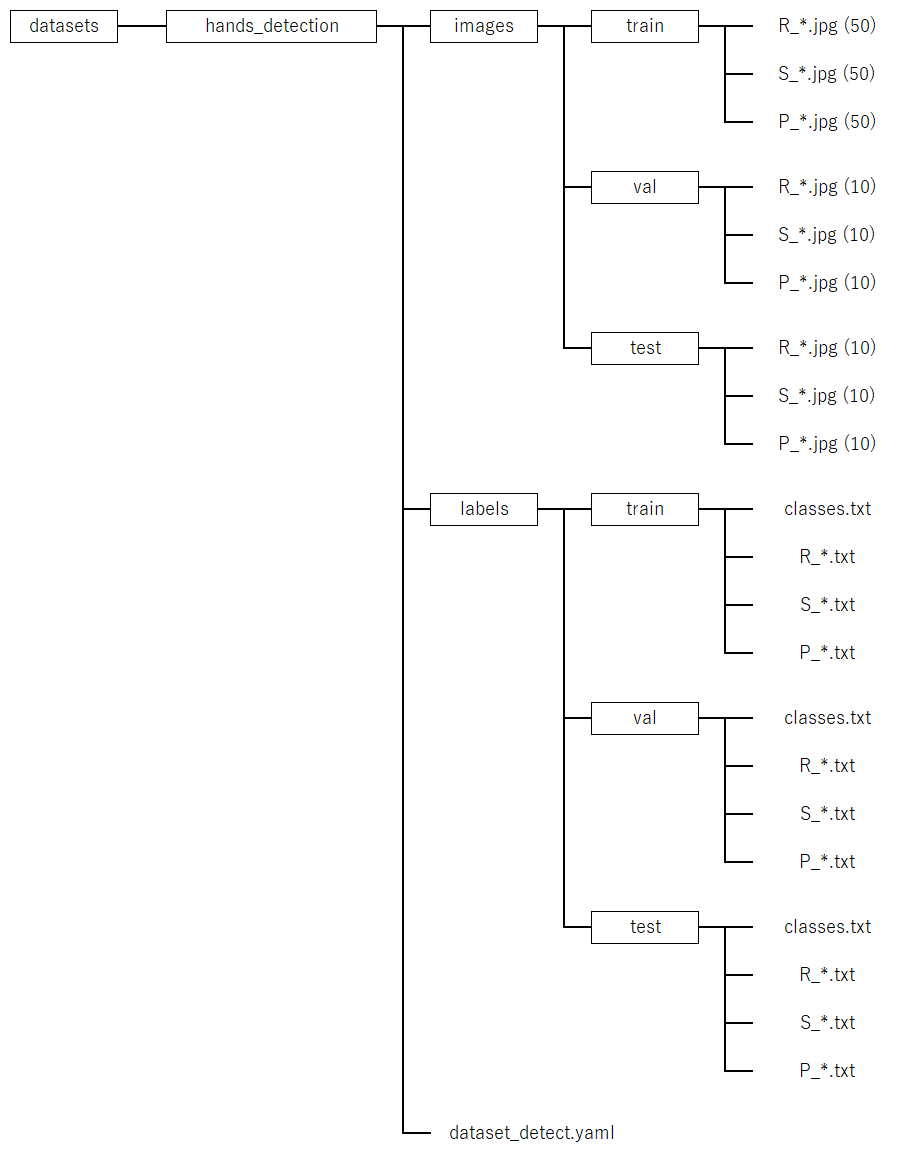
図4-6 学習ファイルの構成(物体検出)
(2) アノテーションプログラムのインストール
画像に対し、対象の位置とクラスを設定するアノテーションプログラムとして、ここでは、labelImgを用います。コマンドプロンプトから次のコマンドを実行してインストールします(図4-7)。
pip install labelImg==1.8.6
インストールの終了後、コマンドプロンプトからlabelImgを実行するとプログラムが起動します(図4-8)。終了は、右上隅の×の閉じるボタンをクリックするか、メニューから ファイル > Quit を選択します。
【参考】
Visual C++ 再頒布可能パッケージ「Microsoft Visual C++ 2015-2019 Redistributable」が見つからない等のエラーメッセージが現れたときは、以下のサイトを参照してパッケージをインストールする必要があります。
https://learn.microsoft.com/ja-jp/cpp/windows/latest-supported-vc-redist?view=msvc-170
または、以下のサイトから、ファイルをダウンロードしてインストールすることも可能です。
https://aka.ms/vs/17/release/vc_redist.x64.exe
図4-7 labelImgのインストール
図4-8 labelImgの起動
(3) アノテーションの実行
学習ファイルとして設定した\work\datasets\hands_detection\imagesフォルダのtrainフォルダのファイルのアノテーションを行います。valとtestフォルダについても同様に行います。
a. labelImgを起動します。
b. 左側の「Open Dir」を選択し、対象の画像のあるフォルダを設定します。
\work\datasets\hands_detection\images\train
c. 左側の「Change Save Dir」を選択し、アノテーションのデータを出力するフォルダを設定します。
\work\datasets\hands_detection\labels\train
d. 左側の「PascalVOC」または「CreateML」をクリックしてラベリングデータの保存形式を「YOLO」にします。
e. 右側の「File List」から画像を選択します。
f. 左側の「Create RectBox」を選択し、画像の対象部分をマウスでドラッグして矩形を設定します(図4-9a)。「w」キーを押すことでも選択できます。
g. 矩形の設定後、ラベルを設定する画面が表示され、クラス名を入力、または、すでに入力されたものがある場合は対応するものを選択し、「OK」を選択します(図4-9b)。そして、右側のラベルのリストに設定したクラス名にチェックマークが付き、対象部分に設定のクラス名が割り当てられたことが示されます。
h. 左側の「Save」を選択し、現在の画像のアノテーションのデータ(.txtファイル)を出力します。
i. 続いて、別の画像のアノテーションを行うときは、左側の「Next Image」または「Prev Image」を選択するか、右側の「File List」からファイルを選択します。そして、「Create RectBox」の手順から繰り返します。
j. 矩形枠の削除は、矩形枠を選択して「DEL」キーを選択します(図4-9c)。また、ラベルの変更は「CTRL+E」キーを押して行います。
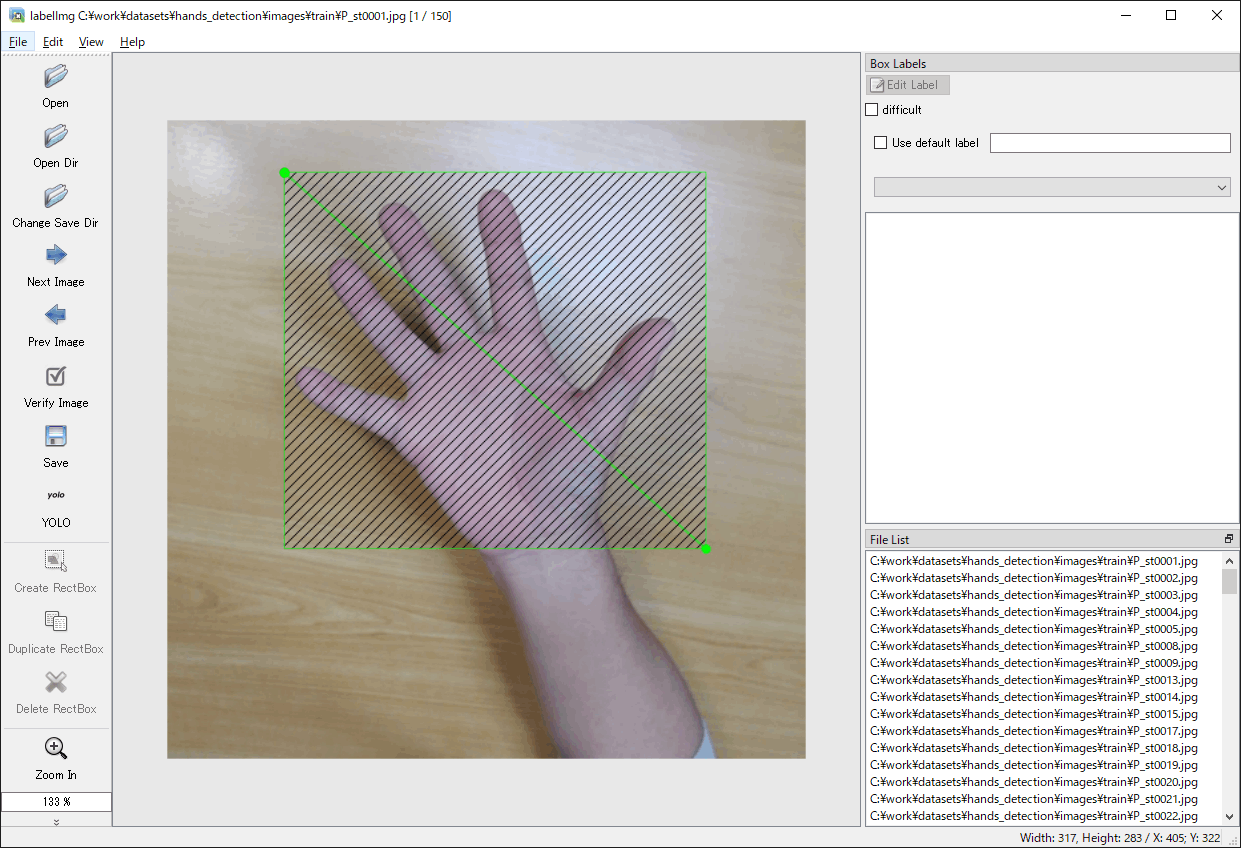
(a) 矩形領域の設定
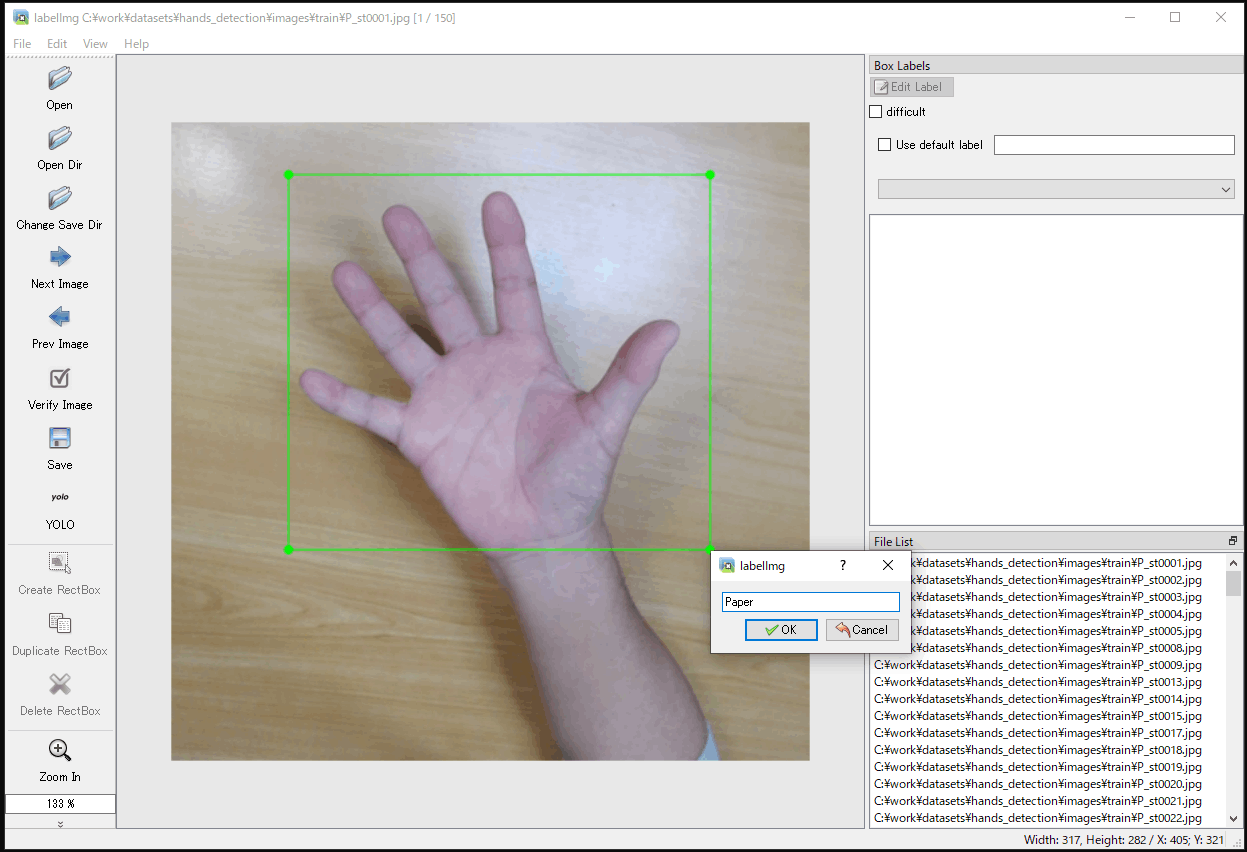
(b) ラベル名の設定
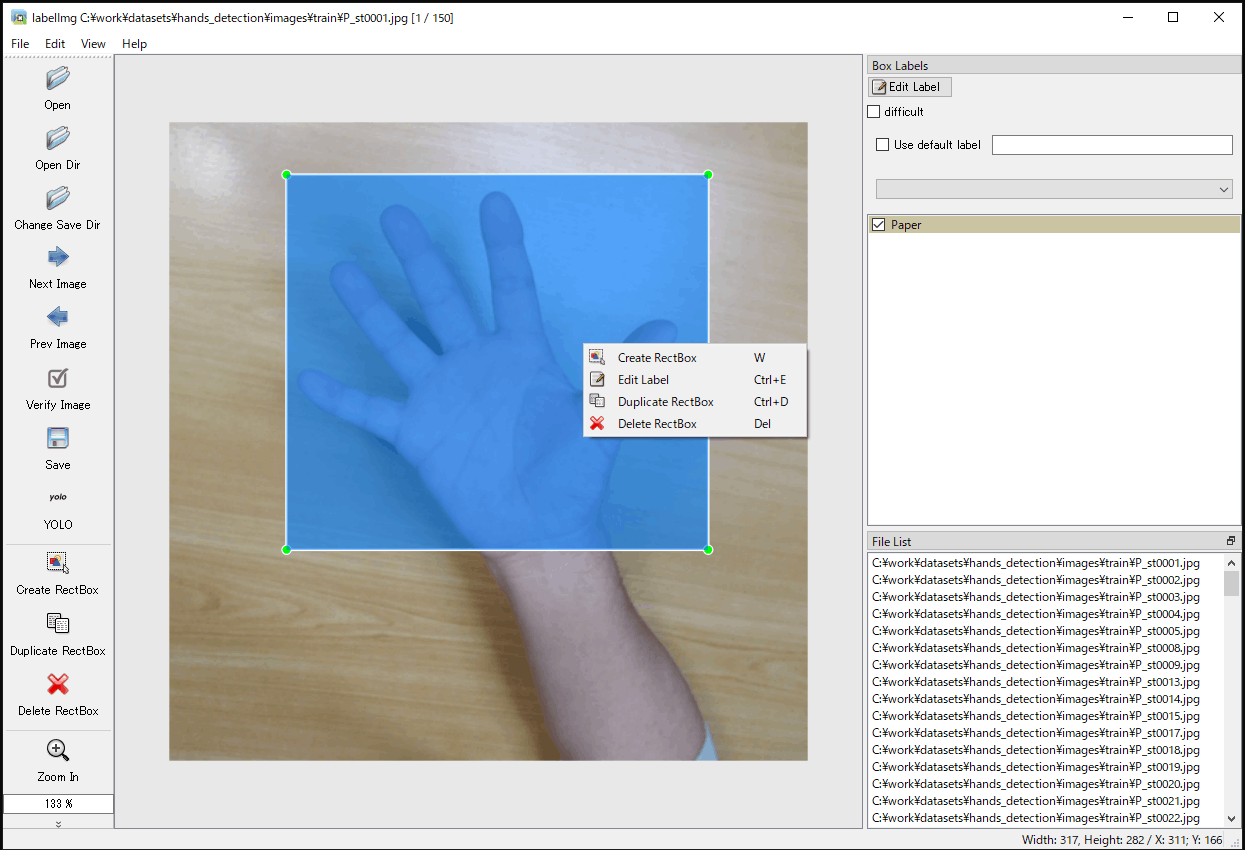
(c) 矩形領域の編集
図4-9 アノテーションの実行(labelImg)
(4) 学習の実行
学習を行うために画像データがどこにあるか、クラスの数とクラス名の情報を設定するリスト4-4の内容を\work\datasets\hands_detectionフォルダの「dataset_detect.yaml」ファイルにテキストエディタで入力し、保存します。また、クラス名は、アノテーションのデータを出力したフォルダにあるclasses.txtの内容に対応させます。学習の実行は、画像分類の場合と同様に行えます。リスト4-5のプログラムをファイル名「detect_train01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図4-10a,b)。
python detect_train01.py
学習した結果は、画像分類のときと同様に、作業フォルダ内の\work\runs\classifyに作成されたtrainフォルダに出力されます(図4-11)。
また、valフォルダの推論と学習したモデルのファイルについても、画像分類のときと同様です。confusion_matrix.pngファイルから、valフォルダの3種類の各10個の画像に対し、いずれも正しく推論され、weightsフォルダにlast.ptとbest.ptが出力されています。
# Path
# dataset roor folder
path: /work/datasets/hands_detection
# train, val images folder (relative to path)
train: images/train
val: images/val
# Classes
# number of classes
nc: 3
# class names
names: ['Paper', 'Rock', 'Scissors']
リスト4-4 yamlファイル (dataset_detect.yaml)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a pretrained YOLO model
model = YOLO('yolov8n.pt')
# Train the model
yaml_path = "./datasets/hands_detection/dataset_detect.yaml"
results = model.train(data=yaml_path, epochs=50, imgsz=480, fliplr=0.0)
リスト4-5 学習用プログラム (detect_train01.py)
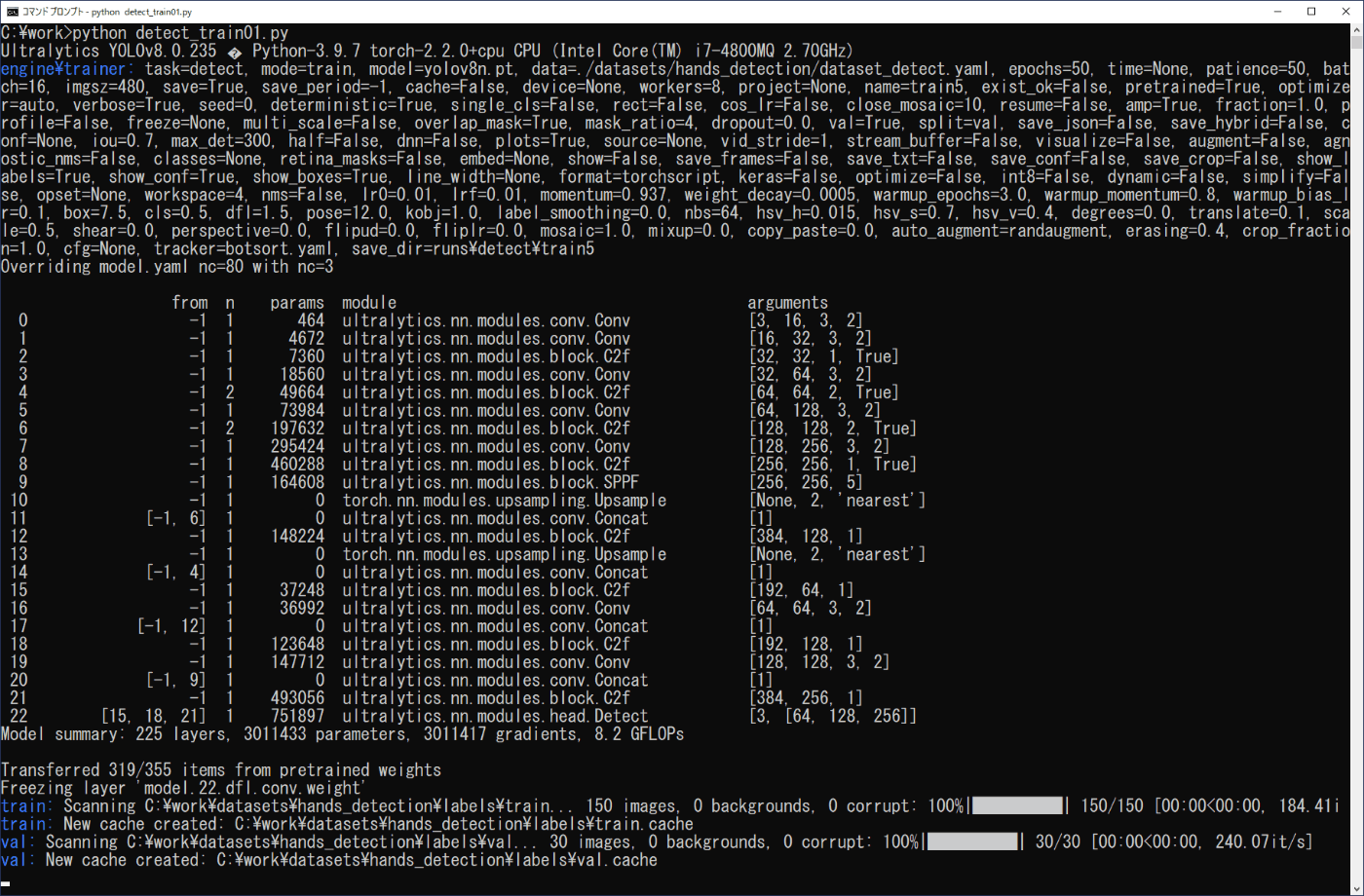
(a) 開始部分
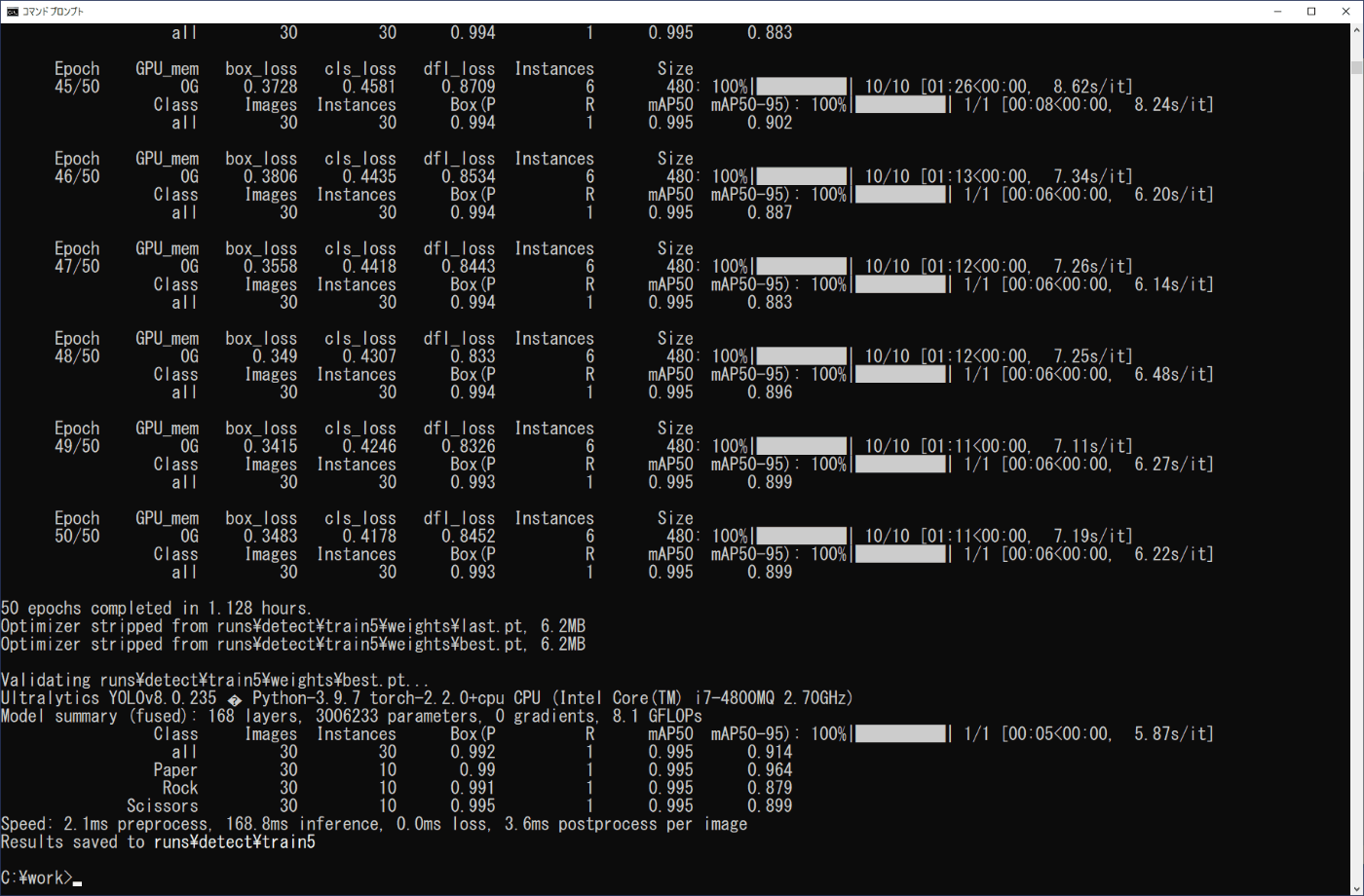
(b) 終了部分
図4-10 学習の実行(物体検出)
図4-11 学習結果(物体検出)
(5) 学習モデルを利用した物体検出
学習したモデルによる物体検出は、3章の学習済みモデルを利用した場合と同様に行うことができます。ここでは、3-3節の場合と同様にPythonプログラムで実行します。確認する画像は、事前に準備した\work\datasets\hands_detection\images\testフォルダの画像の各10個を用い、学習モデルはbest.ptを用います。リスト4-6のプログラムをファイル名「detect_run01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図4-12)。
python detect_run01.py
実行画面および\work\runs\detect\predict7\labelsのファイルから、R_st0151.txtの画像に対してRock(0.50)とScissors(0.67)の推論が行われています(結果の画像では重なっているためScissorsしか分かりません)が、それ以外は、正しく推論されていることが分かります。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('./runs/detect/train5/weights/best.pt')
# Predict with the model
source = "./datasets/hands_detection/images/test"
results = model.predict(source, save=True, save_txt=True, save_conf=True)
リスト4-6 プログラムリスト (detect_run01.py)
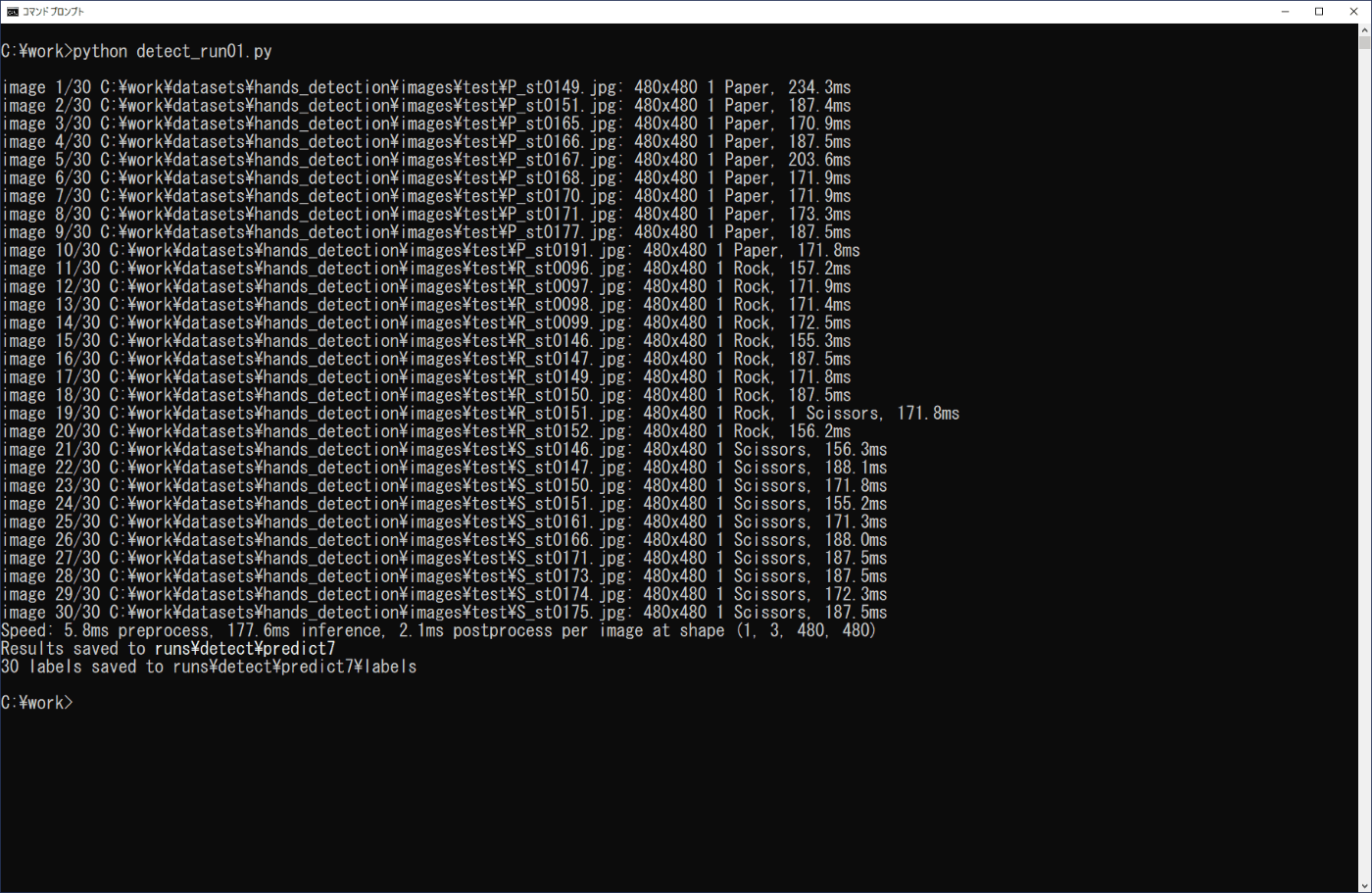
図4-12 学習モデルの実行(物体検出)
4-4. セグメンテーション(Segmentation)
(1) 学習ファイルの設定
\work\datasetsフォルダにセグメンテーション用のフォルダhands_segmentを作成し、seg_imagesフォルダに、Rock、Scissors、Paperの各70個のファイルをまとめます(図4-13)。また、アノテーション後に、ファイルをtrain、val、testに分けます。
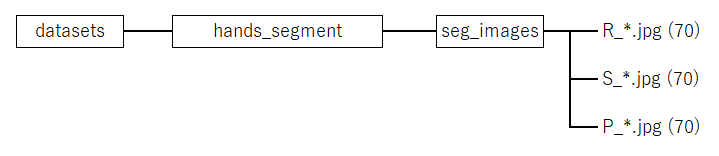
図4-13 学習ファイルの構成(セグメンテーション)
(2) アノテーションプログラムのインストール
画像の中にある対象物の形状とクラスを設定するアノテーションプログラムとしてlabelmeを用い、結果の形式の変換にlabelme2yoloを用います。コマンドプロンプトから次のコマンドを実行します(図4-14、図4-15)。
pip install labelme==5.2.1
pip install labelme2yolo==0.1.3
インストールの終了後、コマンドプロンプトからlabelmeを実行するとプログラムが起動します(図4-16)。終了は、右上隅の×の閉じるボタンをクリックするか、メニューから ファイル > Quit を選択します。
図4-14 labelmeのインストール
図4-15 labelme2yoloのインストール
図4-16 labelmeの起動
(3) アノテーションの実行
学習ファイルとして設定した\work\datasets\hands_segment\seg_imagesフォルダのファイルのアノテーションを行います。
a. コマンドプロンプトを起動して、カレントディレクトリを次のフォルダに変更し、labelmeを起動します。
\work\datasets\hands_segment\seg_images
b. 左側の「Open Dir」を選択し、対象の画像のあるフォルダを設定します。
\work\datasets\hands_segment\seg_images
c. メニューから「File > Change Output Dir」を選択し、アノテーションのデータを出力するフォルダを設定します。後で、labelme2yoloを利用しますので、対象の画像のあるフォルダを設定します。
\work\datasets\hands_segment\seg_images
d. メニューから「File > Save with Image Data」を選択し、チェックマークを外して、
アノテーション結果のファイルに画像データを含めないようにします。
e. 右側の「File List」から画像を選択します。
f. 左側の「Create Polygons」を選択し、画像の対象部分をマウスで頂点をクリックして多角形を設定します。終了は始点をクリックします。「Create Polygons」は「CTRL+N」キーを押すことでも選択できます。
g. 多角形の設定後、ラベルを設定する画面が表示され、クラス名を入力、または、すでに入力されたものがある場合は対応するものを選択し、「OK」を選択します(図4-17)。
そして、右側枠のラベルのリストに設定したクラス名にチェックマークが付き、対象部分に設定のクラス名が割り当てられたことが確認できます。
h. 左側の「Save」を選択し、現在の画像のアノテーションのデータ(.jsonファイル)を出力します。保存の画面が現れますので、確認して「OK」を選択します。
i. 続いて、別の画像のアノテーションを行うときは、左側の「Next Image」または「Prev Image」を選択するか、右側の「File List」からファイルを選択します。
そして、「Create Polygons」の手順から繰り返します。
j. 多角形の削除は、左側の「Delete Polygons」を選択して多角形を選択します。また、頂点の追加や多角形の変形は、左側の「Edit Polygons」を選択して行います。書きかけの多角形を取り消すときは「ESC」キーを押します。
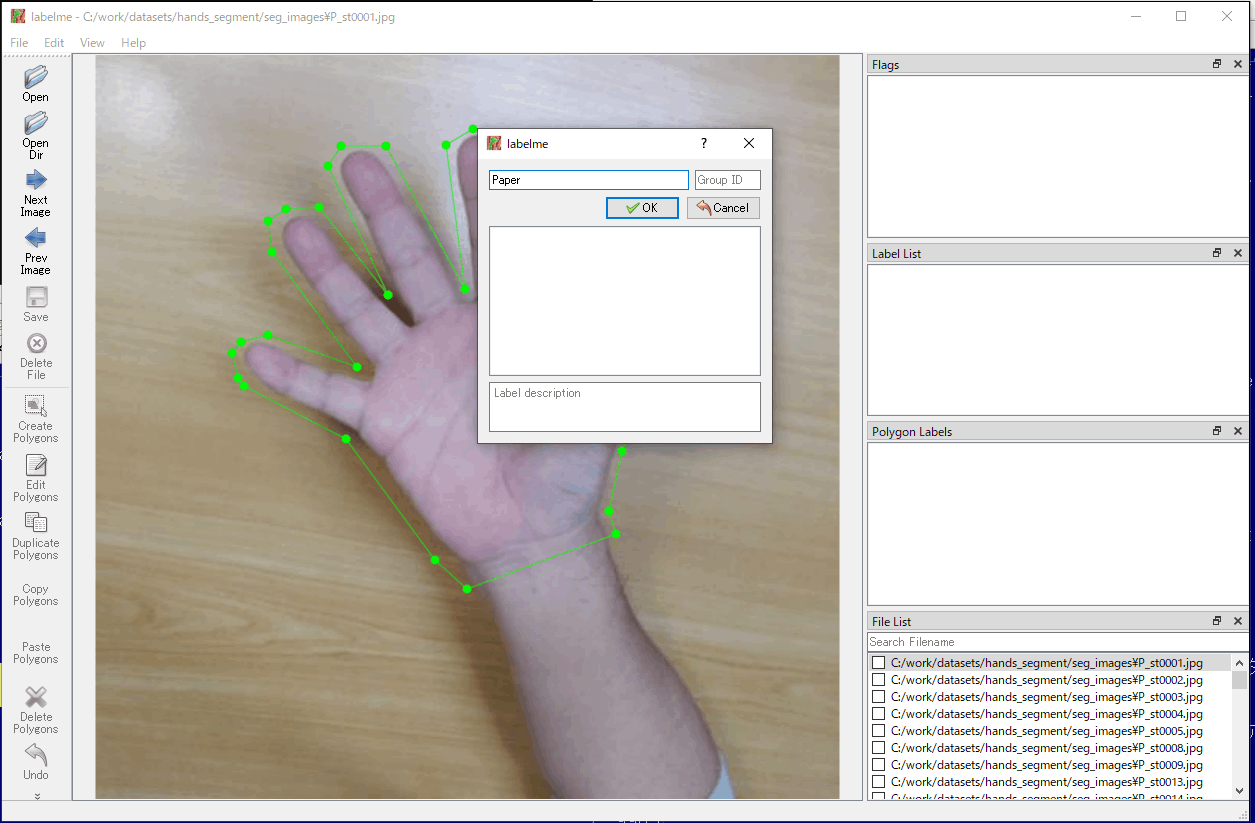
図4-17 アノテーションの実行(labelme)
(4) 学習用フォルダの構成
labelme2yoloプログラムを用いて、アノテーションを行ったファイルから、学習モデルを作成するために必要なフォルダを構成します。また、指定した割合でファイルをtrain、val、testのフォルダに配分します。
a. コマンドプロンプトを起動して、カレントディレクトリを変更して、labelme2yoloコマンドを実行します(図4-18)。
cd \work\datasets\hands_segment\seg_images
labelme2yolo --json_dir ./ --val_size 0.15 --test_size 0.15
val_sizeとtest_sizeにより、全体の70個の15%をvalとtestフォルダに配分しますが、3種類のものを正確に10個ずつには配分できないようです。
b. 結果は、カレントディレクトリのYOLODatasetフォルダに出力されます(図4-19)。
imagesフォルダに学習用のファイル(.png)が、labelsフォルダにアノテーション情報のファイル(.txt)が出力されます。labelsフォルダのファイルは、クラス名を表す番号と多角形の座標で、クラス名の番号は、dataset.yamlで設定のnamesの順番と対応します。
c. YOLODatasetフォルダを\work\datasets\hands_segmentフォルダにコピーします。
学習はこのコピーしたものを利用します。

図4-18 labelme2yoloの実行
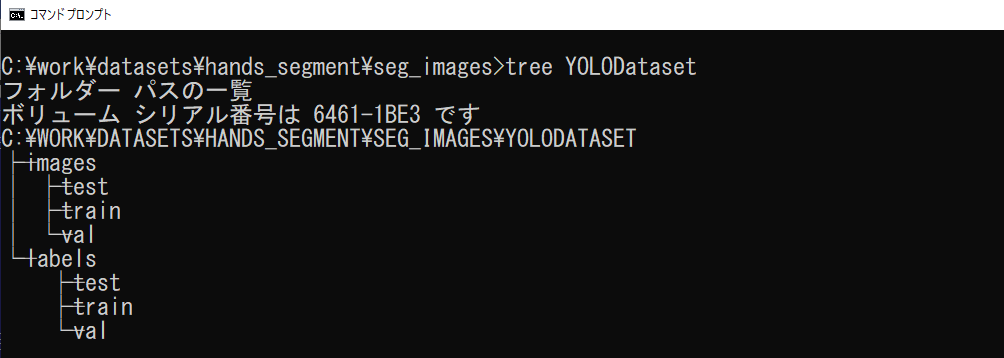
図4-19 YOLODtasetフォルダの構成
(5) 学習の実行
学習を行うためにコピーしたYOLODatasetフォルダのdataset.yamlの内容をリスト4-7の内容に修正します。また、学習の実行は、画像分類の場合と同様に行えます。リスト 4-8のプログラムをファイル名「segment_train01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図4-20)。
python segment_train01.py
学習した結果は、画像分類のときと同様に作業フォルダ内の\work\runs\segmentに作成されたtrainフォルダに出力されます(図4-21)。また、valフォルダの推論と学習したモデルのファイルについても、画像分類のときと同様に、confusion_matrix.pngファイルから、valフォルダのRockの9個とScissorsとPaperの各11個の画像に対し、いずれも正しく推論され、weightsフォルダにlast.ptとbest.ptが出力されています。
path: /work/datasets/hands_segment
train: ./YOLODataset/images/train/
val: ./YOLODataset/images/val/
test: ./YOLODataset/images/test/
nc: 3
names: ["Rock", "Scissors", "Paper"]
リスト4-7 yamlファイル (dataset.yaml)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a pretrained YOLO model
model = YOLO('yolov8n-seg.pt')
# Train the model
yaml_path = "./datasets/hands_segment/YOLODataset/dataset.yaml"
results = model.train(data=yaml_path, epochs=50, imgsz=480, fliplr=0.0)
リスト4-8 学習用プログラム segment_train01.py)
図4-20 学習の実行(セグメンテーション)
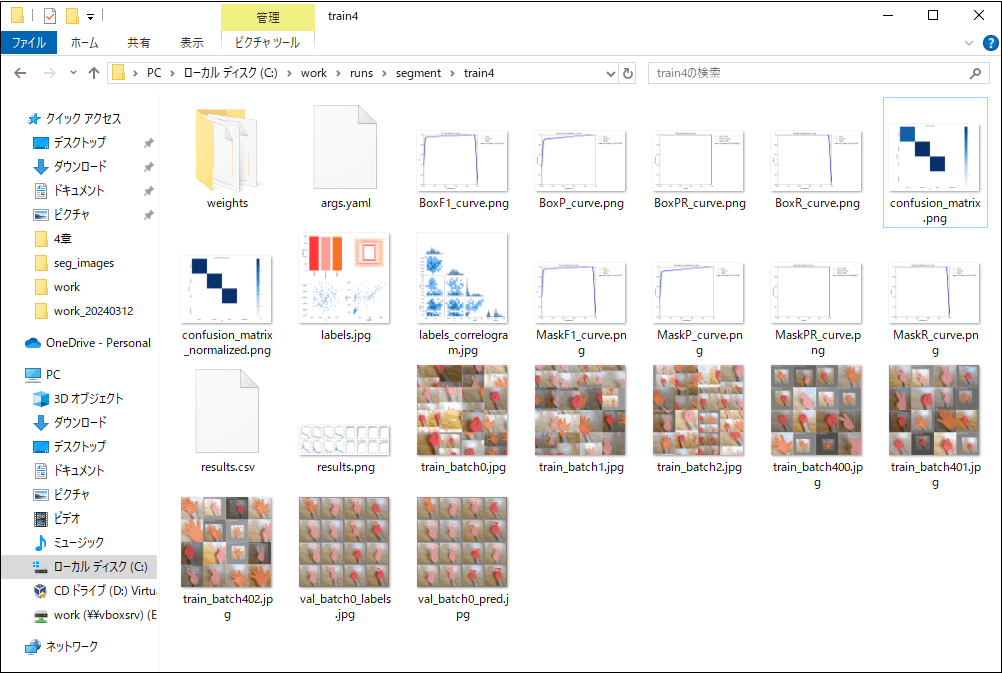
図4-21 学習結果(セグメンテーション)
(6) 学習モデルを利用した物体検出
学習したモデルによるセグメンテーションは、3章の学習済みモデルを利用した場合と同様に行うことができます。ここでは、3-4節の場合と同様にPythonプログラムで実行を行います。
確認する画像は、事前に準備した\work\datasets\hands_segment\YOLODataset\images\testフォルダの画像を用い、学習モデルはbest.ptを用います。
リスト4-9のプログラムをファイル名「segment_run01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図4-22)。
python segment_run01.py
実行画面と\work\runs\segment\predict7のファイルから、正しく推論されていることが分かります。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
# Load a model
model = YOLO('./runs/segment/train4/weights/best.pt')
# Predict with the model
source = "./datasets/hands_segment/YOLODataset/images/test"
results = model.predict(source, save=True, save_txt=True, save_conf=True)
リスト4-9 プログラムリスト (segment_run01.py)
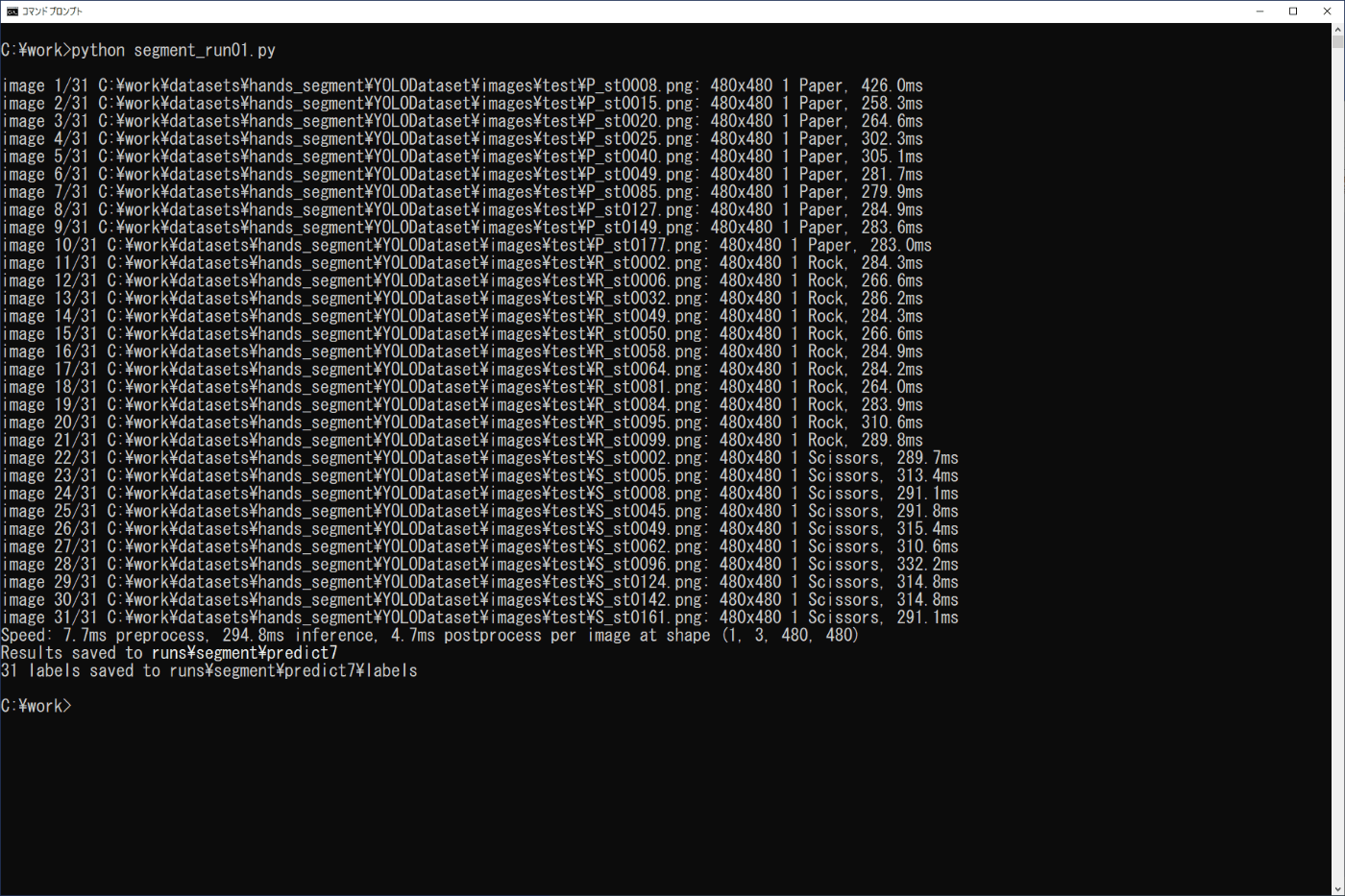
図4-22 学習モデルの実行(セグメンテーション)
5.プログラミング
YOLOv8の物体検出の機能を利用して、画像から検出された矩形領域の物体を取出すPythonのプログラムを紹介します。
5-1. 矩形枠の情報
3-3節で示した物体検出の実行プログラムを変更して、検出した物体の数、および各物体のクラス名、矩形の座標、信頼度を表示するプログラムをリスト 5-1に示します。
プログラムでmodel.predict()の命令を実行した検出の結果は、resultsに保存されます。resultsは配列で、画像ごとに要素番号が増えて行きますが、用いた画像が1個のときは、results[0]として参照できます。ここでは、結果をresultに代入し、resultの要素として検出した矩形枠の数や情報を参照します。但し、矩形枠の情報はPyTorch Tensorの配列のため、配列要素は.tolist()、数値は.item()を用いてアンパックする必要があります。
プログラムをファイル名「yolov8_box01.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図5-1)。
python yolov8_box01.py
プログラムの終了は、用いた画像ファイルの表示されている画面をカレントにした状態で、キーボードの「q」を押します。図5-1の左側の出力に、矩形枠の情報が出力されています。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
import cv2
# Load a model
model = YOLO('yolov8n.pt')
# Predict with the model
source = "./bus.jpg"
results = model.predict(source, save=True, save_txt=True, save_conf=True, show=True)
# Extract single item
result = results[0]
num = len(result.boxes)
print("Number of boxes : ", num)
# Detected objects
for box in result.boxes:
class_id = result.names[box.cls[0].item()]
cords = box.xyxy[0].tolist()
cords = [round(x) for x in cords]
conf = round(box.conf[0].item(), 4)
print("Object type : ", class_id)
print("coordinates : ", cords)
print("confidence : ", conf)
print()
while True:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
リスト5-1 プログラムリスト (yolov8_box01.py)
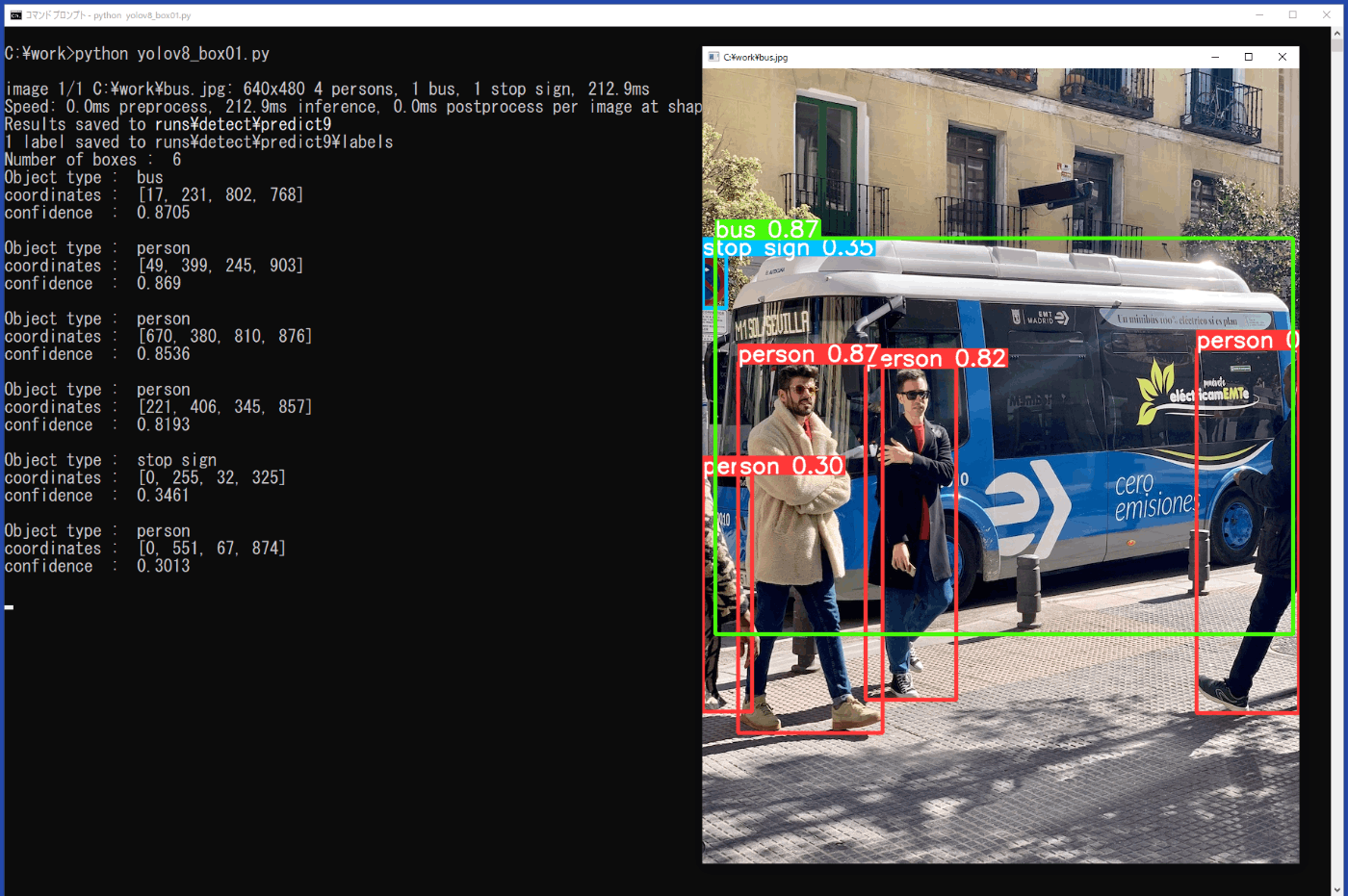
図5-1 矩形枠の情報表示(yolov8_box01.py)
5-2. 矩形枠の識別
前節5-1のプログラムを修正して、personを0.7以上の信頼度で検出した矩形枠のデータを表示するプログラムをリスト 5-2に示します。クラス名はclass_idで、信頼度はconfに設定された変数で参照できます。
プログラムをファイル名「yolov8_box02.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図5-2)。
python yolov8_box02.py
プログラムの終了は、用いた画像ファイルの表示されている画面をカレントにした状態で、キーボードの「q」を押します。図5-2の左側の出力上側には、bus.jpgで、personが4個、busが1個、Stop signが1個検出されていることが示されていますが、その下には、personで信頼度が0.7以上のもののみが3個出力されています。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
import cv2
# Load a model
model = YOLO('yolov8n.pt')
# Predict with the model
source = "./bus.jpg"
results = model.predict(source, save=True, save_txt=True, save_conf=True, show=True)
# Extract single item
result = results[0]
num = len(result.boxes)
# Detected objects
for box in result.boxes:
class_id = result.names[box.cls[0].item()]
if class_id == "person":
conf = round(box.conf[0].item(), 4)
if conf < 0.7:
continue;
cords = box.xyxy[0].tolist()
cords = [round(x) for x in cords]
conf = round(box.conf[0].item(), 4)
print("Object type : ", class_id)
print("coordinates : ", cords)
print("confidence : ", conf)
print()
while True:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
リスト5-2 プログラムリスト (yolov8_box02.py)
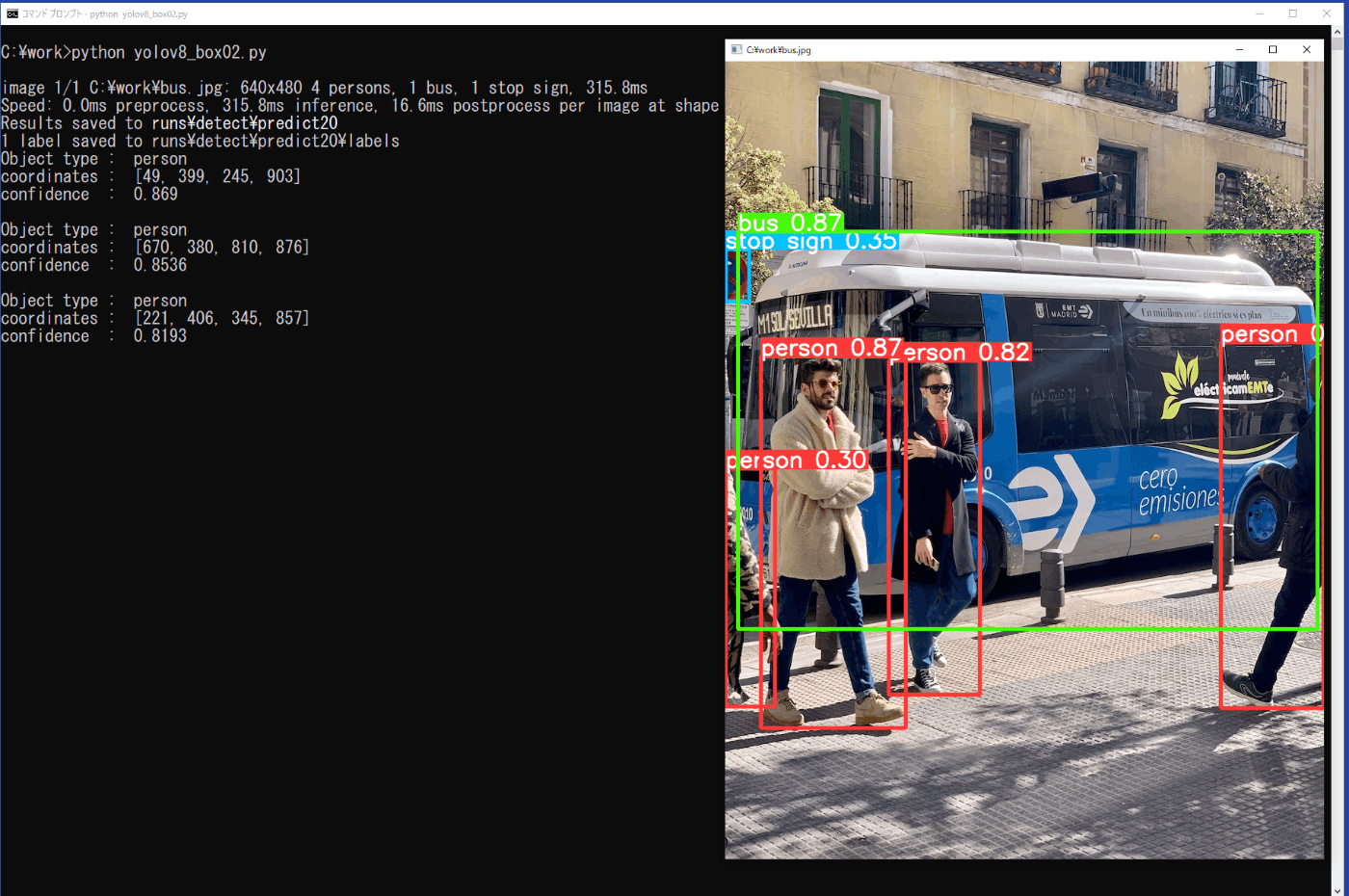
図5-2 矩形枠の選択(yolov8_box02.py)
5-3. 矩形枠の物体の取出し
前節5-2のプログラムを修正して、検出したpersonの信頼度が0.7以上の矩形領域の物体を取出して表示するプログラムをリスト5-3に示します。
矩形枠の情報は、xyxy[0]により参照することで、矩形枠の左上隅と右下隅のxy座標を取出すことができます。この座標から画像ファイルの指定した領域を取出すためには、付録A.3で示したリストA-2 画像の切取りのプログラムと同様に、画像データの設定された配列の一部を取出します。但し、配列の指定では、高さ(行)、幅(列)の順で領域を指定します。
プログラムをファイル名「yolov8_box03.py」でworkフォルダに保存し、コマンドプロンプトから次のコマンドを実行します(図5-3)。
python yolov8_box03.py
プログラムの終了は、用いた画像ファイルの表示されている画面をカレントにした状態で、キーボードの「q」を押します。取出した画像の画面が小さすぎて移動できないときは、画面の左上のメニューから「移動」を選択して、マウスでドラッグして下さい(図5-4)。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ultralytics import YOLO
import cv2
# Load a model
model = YOLO('yolov8n.pt')
# Predict with the model
source = "./bus.jpg"
results = model.predict(source, save=True, save_txt=True, save_conf=True, show=True)
# Image
im = cv2.imread(source)
# Extract single item
result = results[0]
num = len(result.boxes)
# Detected objects
no = 0
for box in result.boxes:
class_id = result.names[box.cls[0].item()]
if class_id == "person":
conf = round(box.conf[0].item(), 4)
if conf < 0.7:
continue;
cords = box.xyxy[0].tolist()
cords = [round(x) for x in cords]
no += 1
box_cut = im[cords[1]:cords[3], cords[0]:cords[2]]
cv2.imshow(('%s%d' % (class_id, no)), box_cut)
print("Object type : ", class_id)
print("coordinates : ", cords)
print()
while True:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
リスト5-3 プログラムリスト (yolov8_box03.py)
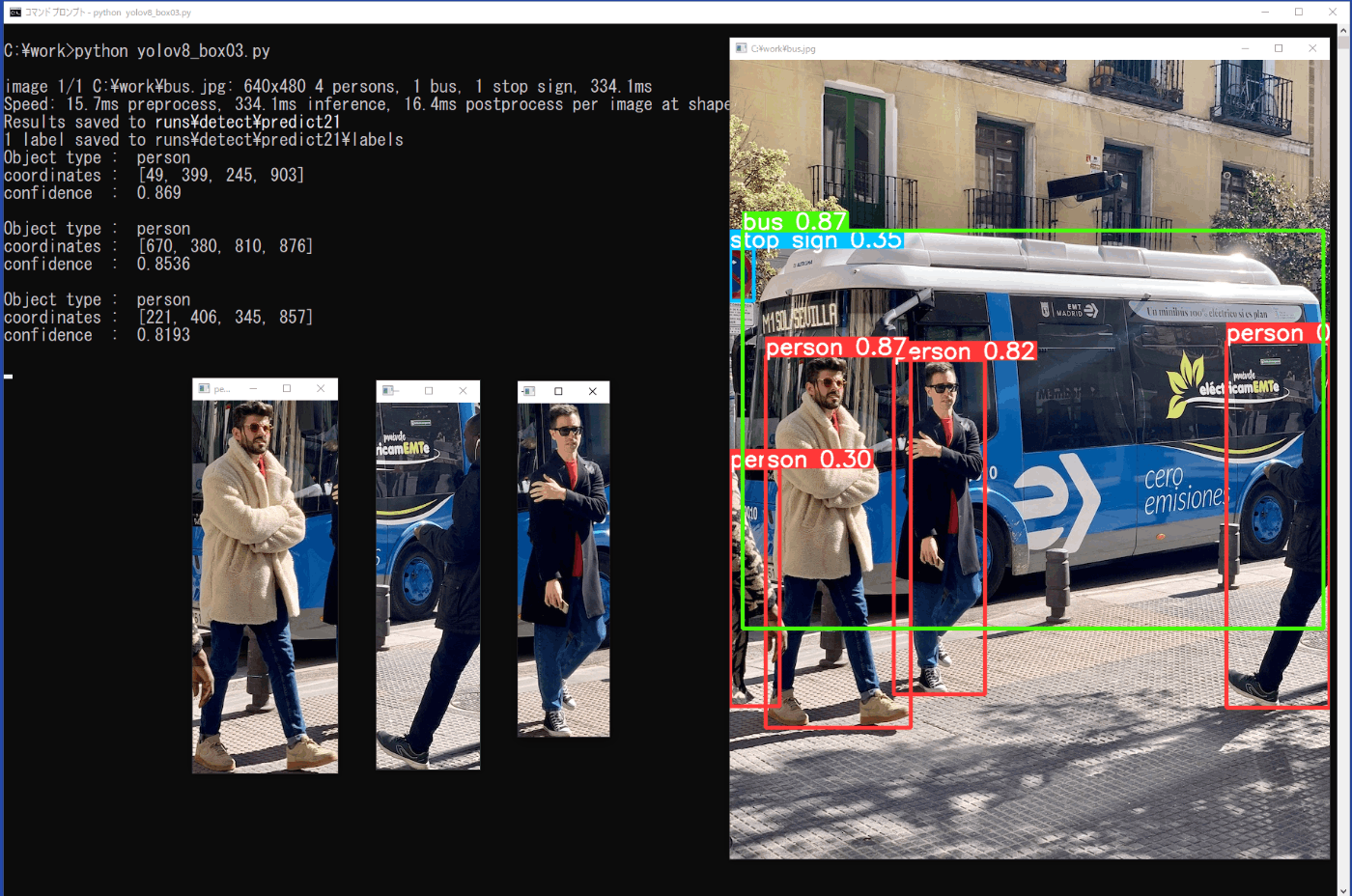
図5-3 矩形枠の取出し(yolov8_box03.py)
図5-4 画面の移動
6. まとめ
近年、画像判定が様々なところで利用されるようになって来ていますが、実際に画像判定を確認して見たいと思ったときに、プログラム環境を設定しプログラムをインストールして、確認するのに多くの時間が掛ったり、エラーが発生して先に進めなかったり、結局、確認したいことができずに諦めてしまうことも、少なくないと思います。
そのような中で、YOLOv8は、インストールが容易で、代表的な手法である画像分類(Classification)、物体検出(Detection)、セグメンテーション(Segmentation)、物体追跡(Track)、姿勢推定(Pose)を行うことができ、画像判定を確認したいと考えている方には、良いプログラムであると思います。また、画像や動画、USBカメラからの画像に対しても、容易に確認が可能です。
本手順書では、学習済みモデルを利用して各種の画像判定をコマンドやPythonプログラムから実行する手順、独自の学習モデルの作成方法と実行の手順、画像判定を利用したPythonプログラムの例について示しました。本手順書が、実際に物体認識を体験したい方、自前のデータで物体認識をさせたい方、さらに、物体認識を利用してプログラムを作成したい方等の参考になればと思います。
付録 A USBカメラによる静止画、動画の取得
A.1 実行環境
ここでは、画像判定を行うときに必要な静止画や動画をUSBカメラを用いて取得するPythonのプログラムを示します。プログラムの詳細については、参考資料に掲載のホームページ等をご覧頂ければと思います。
第2章のYOLOv8のインストールを行うと、PythonやOpenCVなど必要なソフトもインストールされますので、USBカメラを接続するだけで、Pythonによる画像の取得と保存が可能となります。但し、保存ファイルの形式により、表示用のソフトが必要となる場合もあります。ここでは、logicool社のStreamCamによりプログラムの動作確認を行いました。また、OpenCVでカメラの設定を行うときは、参考資料の[A-1]などが参考となります。
A.2 撮影と画像表示
はじめに、接続したUSBカメラによる撮影が正常に行えるか、確認します。リストA-1のプログラムA01_usb_camera01.pyを実行するとデフォルトの解像度で画像が表示されます。終了は、画像の表示されているフレームをアクティブにして、キーボードの q を押します。また、cv2.imshow('frame', frame) の命令の代わりに、その次の2行の先頭の#を削除して(コメントアウトを外して)、実行するとモノクロ画像の表示となります。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import cv2
cap = cv2.VideoCapture(0)
print("cap opened : ", cap.isOpened())
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print("Image size : ", width, " x ", height)
while True:
(ret, frame) = cap.read()
cv2.imshow('frame', frame)
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# cv2.imshow('frame', gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
リストA-1 動作確認 (A01_usb_camera01.py)
A.3 画像の取出しと表示
ここでは、画像の取出しを確認します。リストA-2のプログラムA02_usb_camera02.pyを実行すると撮影された848 x 480の画像から480 x 480の画像を取出して表示します。終了は、画像の表示されているフレームをアクティブにして、キーボードの q を押します。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import cv2
cap = cv2.VideoCapture(0)
print("cap opened : ", cap.isOpened())
# set region of interest
w_max = 848
h_max = 480
w_width = 480
h_height = 480
cap.set(cv2.CAP_PROP_FRAME_WIDTH, w_max)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, h_max)
w_cent = w_max / 2
w_half = w_width / 2
h_cent = h_max / 2
h_half = h_height / 2
w1 = int(w_cent - w_half)
w2 = int(w_cent + w_half)
h1 = int(h_cent - h_half)
h2 = int(h_cent + h_half)
while True:
(ret, frame) = cap.read()
cv2.imshow('frame', frame)
frame_cut = frame[h1:h2, w1:w2]
cv2.imshow('frame2', frame_cut)
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# cv2.imshow('frame', gray)
# gray_cut = gray[h1:h2, w1:w2]
# cv2.imshow('frame2', gray_cut)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
リストA-2 画像の切取り (A02_usb_camera02.py)
A.4 静止画の保存
ここで、切り取った480 x 480の画像を静止画として保存します。リストA-3のプログラムA03_usb_camera_Shot01.pyを実行し、画像の表示されているフレームがアクティブのときに、
キーボードのgを押すと、表示されている画像の保存
キーボードのqを押すと、プログラム終了
となります。静止画は、shotというフォルダが作られて、その中にst0001.jpgというファイル名から、gを押すたびに順番に番号が増えて保存されます。プログラムを実行するたびに、st0001から上書きされますので、必要に応じて、フォルダ名やファイル名を変更して下さい。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import cv2
def main():
cap = cv2.VideoCapture(0)
print("cap opened : ", cap.isOpened())
w_max = 848
h_max = 480
w_width = 480
h_height = 480
cap.set(cv2.CAP_PROP_FRAME_WIDTH, w_max)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, h_max)
w_cent = w_max / 2
w_half = w_width / 2
h_cent = h_max / 2
h_half = h_height / 2
w1 = int(w_cent - w_half)
w2 = int(w_cent + w_half)
h1 = int(h_cent - h_half)
h2 = int(h_cent + h_half)
import os
if os.path.exists("./shot") is False:
os.makedirs("./shot")
ptno = 0
while True:
(ret, frame) = cap.read()
frame_cut = frame[h1:h2, w1:w2]
cv2.imshow('Get Image (q to exit)', frame_cut)
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# gray_cut = gray[h1:h2, w1:w2]
# cv2.imshow('Get Image (q to exit)', gray_cut)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('g'):
ptno += 1
ptname = "./shot/st{:04d}.jpg".format(ptno)
cv2.imwrite(ptname, frame_cut)
cv2.imshow('Shot', frame_cut)
# cv2.imwrite(ptname, gray_cut)
# cv2.imshow('Shot', gray_cut)
print(ptname + " is saved.")
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
リストA-3 静止画の保存 (A03_usb_camera_Shot01.py)
A.5 動画の保存
ここでは、動画から480 x 480の範囲を切り取り、動画として保存します。
次のプログラムusb_camera_Movie01.pyを実行し、画像の表示されているフレームがアクティブのときに、
キーボードのgを押すと、録画開始
キーボードのhを押すと、録画終了
キーボードのqを押すと、プログラム終了
となります。動画からの切取りは、繰返し行え、1つの動画ファイルにまとめられます。そして、shotというフォルダにmv0001.mp4というファイル名で保存されます。プログラムを実行するたびに、mv0001.mv4が上書きされますので、必要に応じて、ファイル名を変更して下さい。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import cv2
def main():
cap = cv2.VideoCapture(0)
print("cap opened : ", cap.isOpened())
w_max = 848
h_max = 480
w_width = 480
h_height = 480
cap.set(cv2.CAP_PROP_FRAME_WIDTH, w_max)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, h_max)
w_cent = w_max / 2
w_half = w_width / 2
h_cent = h_max / 2
h_half = h_height / 2
w1 = int(w_cent - w_half)
w2 = int(w_cent + w_half)
h1 = int(h_cent - h_half)
h2 = int(h_cent + h_half)
import os
if os.path.exists("./shot") is False:
os.makedirs("./shot")
fmt = cv2.VideoWriter_fourcc('m','p','4','v')
fps = 20
size = (w_width, h_height)
writer = cv2.VideoWriter('./shot/mv0001.mp4', fmt, fps, size)
sw_mv = 0
while True:
(ret, frame) = cap.read()
frame_cut = frame[h1:h2, w1:w2]
cv2.imshow('Get Image (q to exit)', frame_cut)
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# gray_cut = gray[h1:h2, w1:w2]
# cv2.imshow('Get Image (q to exit)', gray_cut)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('g'):
sw_mv = 1
print("Start Recording")
elif key == ord('h'):
sw_mv = 0
print("Stop Recording")
if sw_mv == 1:
writer.write(frame_cut)
# writer.write(gray_cut)
writer.release()
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
リストA-4 動画の保存 (A04_usb_camera_Movie01.py)
参考資料
本資料の作成ではインターネットにある多くのサイトに掲載の情報を利用しました。以下に本文で参考にした主なWebサイトを示します。
[1] YOLOv8について
https://chem-fac.com/yolov8/
[2] YOLOv8の利用方法、学習、プログラム
https://www.freecodecamp.org/news/how-to-detect-objects-in-images-using-yolov8/
[3] YOLOv8、labelImgについて
https://farml1.com/yolov8/
[4] YOLOv8、labelImgについて
https://chem-fac.com/yolov8/
[5] YOLOv8、Labelmeについて
https://qiita.com/grapefruit1030/items/530bdb2ddeeedc32eb58
[6] Labelmeについて
https://qiita.com/yutakam/items/9b4c957273ab2fbfdf4d
付録A
[A-1] USBカメラの設定
https://www.klv.co.jp/corner/python-opencv-camera-setting.html
[A-2] 画像の切取り
https://non-it-engineer.com/pythonopencvで指定範囲のみに画像処理を行う方法/
[A-3] USBカメラによる動画の保存
https://watlab-blog.com/2019/09/26/webcamera-save/
以上
Discussion