ネットワーク活用技術:ZABBIX APIより収集データを取得する
本記事はオープンソース総合監視ソフトウェア:ZABBIXの機能の一例を紹介します。前提として、今回はAWS EC2から立ち上げたサーバ(Amazon Linux 2)を土台に構築したZABBIXを使用します。ZABBIXやその構築方法については前記事を参照ください。
ZABBIX APIについて
ZABBIXで収集されるデータは、基本的にそのデータベース内に保管されます。例えば収集された過去のデータをみたい場合は、ZABBIXをWebブラウザで開き、当該のデータのグラフ画面から特定期間のトレンドを表示させるなどの方法があります。
このようにWebアクセスからいつでも遠方からでも情報を得ることは可能ですが、定期的にある期間の情報を収集したり、特定時間帯のcsvデータを毎日取得するなど、ルーチンな働きが必要な場合は、情報収集の自動化が求められたりします。
ここで、ZABBIXには外部のシステムとやり取りができる機能:APIが複数用意されており、このような自動化処理には有効なものになります。
- ZABBIX公式サイト:API一覧(ZABBIX5.0)
今回はHistoryという過去の指定期間のデータを収集できるAPIの検証を行ってみます。手法として、PythonプログラムによりZABBIXに収集されている任意期間のデータをcsv形式で取得する方法を紹介します。
ZABBIX収集データの表示方法(例:ZABBIXサーバメモリ使用率)
ZABBIX左メニューの「監視データ」→「ホスト」を選択すると、現在監視できるホスト一覧が表示されます。ZABBIXでは初期状態から、自身のサーバの状態を監視できます。
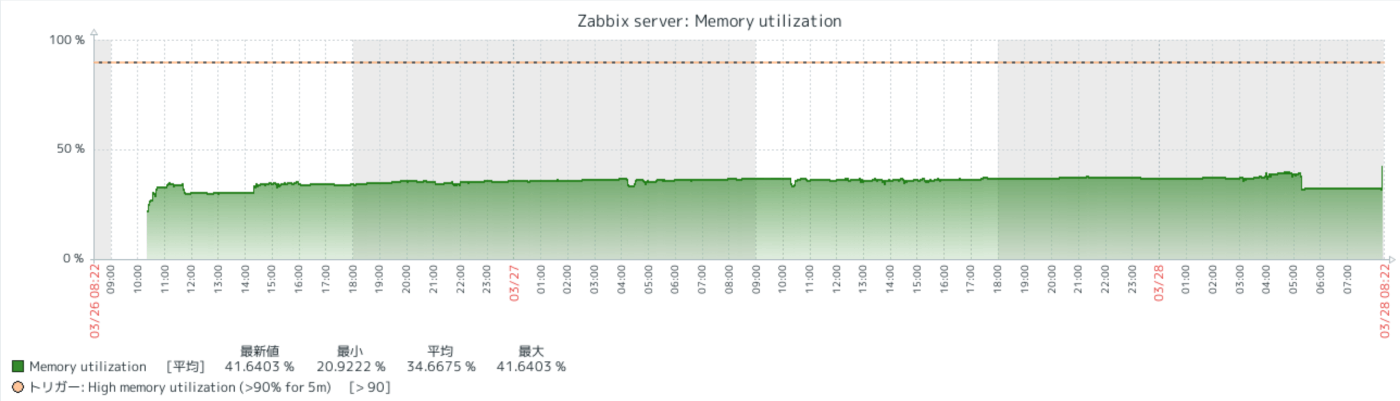
当画面から自身のサーバ:ここでは"Zabbix server”を選択し、「グラフ」を選択すると、監視できる項目のグラフが一覧で表示されます。
例えば、「Zabbix server : Memory utilization」ではサーバのメモリ使用率の変異が示されています。
Python環境の準備(Google Colaboratory)
今回は、このメモリ使用率を例に取り、Pythonを用いて特定期間の値をcsvで取得するプログラムの検証を行います。Python環境の構築はいくつかの手法がありますが、今回は手軽に検証できる手法としたいため、GoogleのPython環境:Google Colaboratoryの無償版を活用し、例として出力するcsvファイルは同Googleアカウントのドライブに保存することとします。
※既にお使いのPython環境があれば、本設定は不要です。
- お使いのGoogleアカウントがあれば、ログインした状態でGoogleドライブを開きます。
- マイドライブに移動し、任意の場所に新しいフォルダを作成します。
- 作成したフォルダに移動し、左上の「+新規」から「その他」→「アプリを追加」を選択し、表示されたウィンドウの検索欄に”Colaboratory”と入力します。
- 一番上に「Colaboratory」が表示されるので、選択して「インストール」を押下します。

- インストールが完了したら、再度Googleドライブのフォルダ画面左上の「+新規」から「その他」→「Colaboratory」を選択して、本アプリを開きます。
- 出力するcsvファイルが同Googleアカウントのドライブに保存できるように、Colaboratoryをドライブにマウントさせます。
画面上の「+コード」をクリックし、入力フォームを表示されたら、以下コマンドを入力し、フォーム左の再生ボタンをクリックします。
from google.colab import drive
drive.mount('/content/drive')$
- 「このノートブックにGoogleドライブのファイルへのアクセスを許可しますか?」と表示されるので、「Googleドライブに接続」を選択します。
すると、Googleアカウントの選択画面が表示されるので、使用しているアカウントを選択し、アクセスできる情報に全てチェックを入れて続行します。
先ほどのColaboratoryのフォーム下に”Mount at /content/drive”が表示されれば成功です。
PythonによるZABBIX収集データ取得プログラムの実行(ZABBIX API:History)
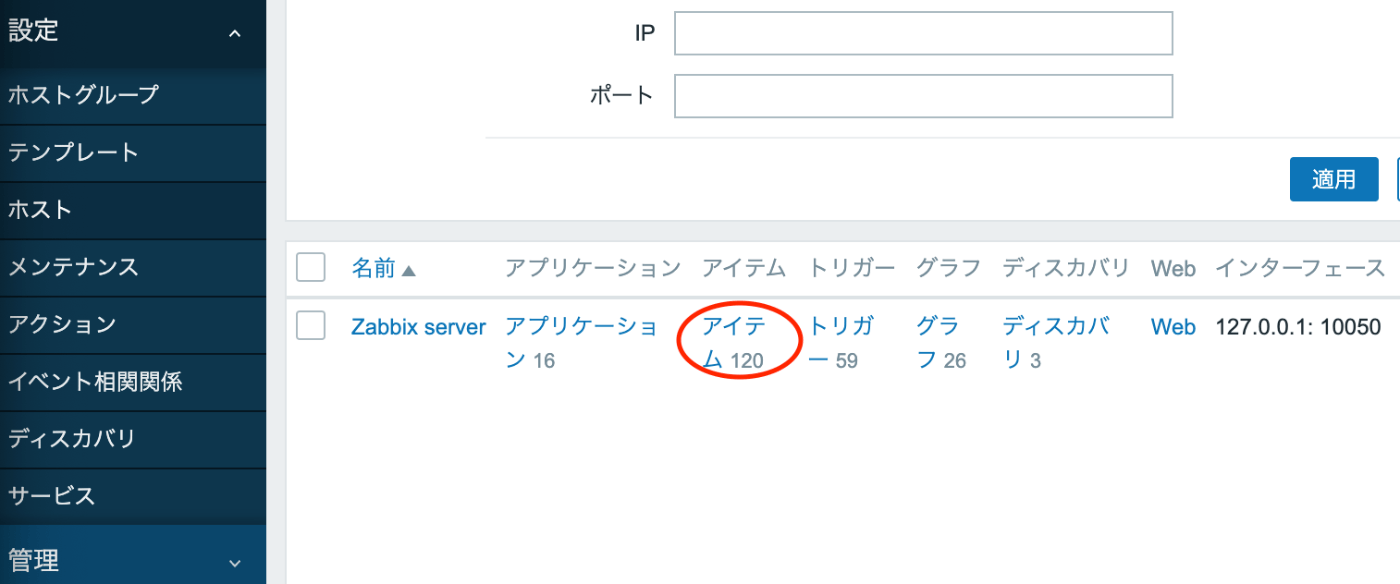
- ZABBIXの左メニューの「設定」→「ホスト」を選択し、Zabbixサーバの「アイテム」を選択します。
- 表示された画面上の「名前」欄に”memory”と入力し、「適用」を押下して画面下に表示される「Memory utilization」をクリックします。
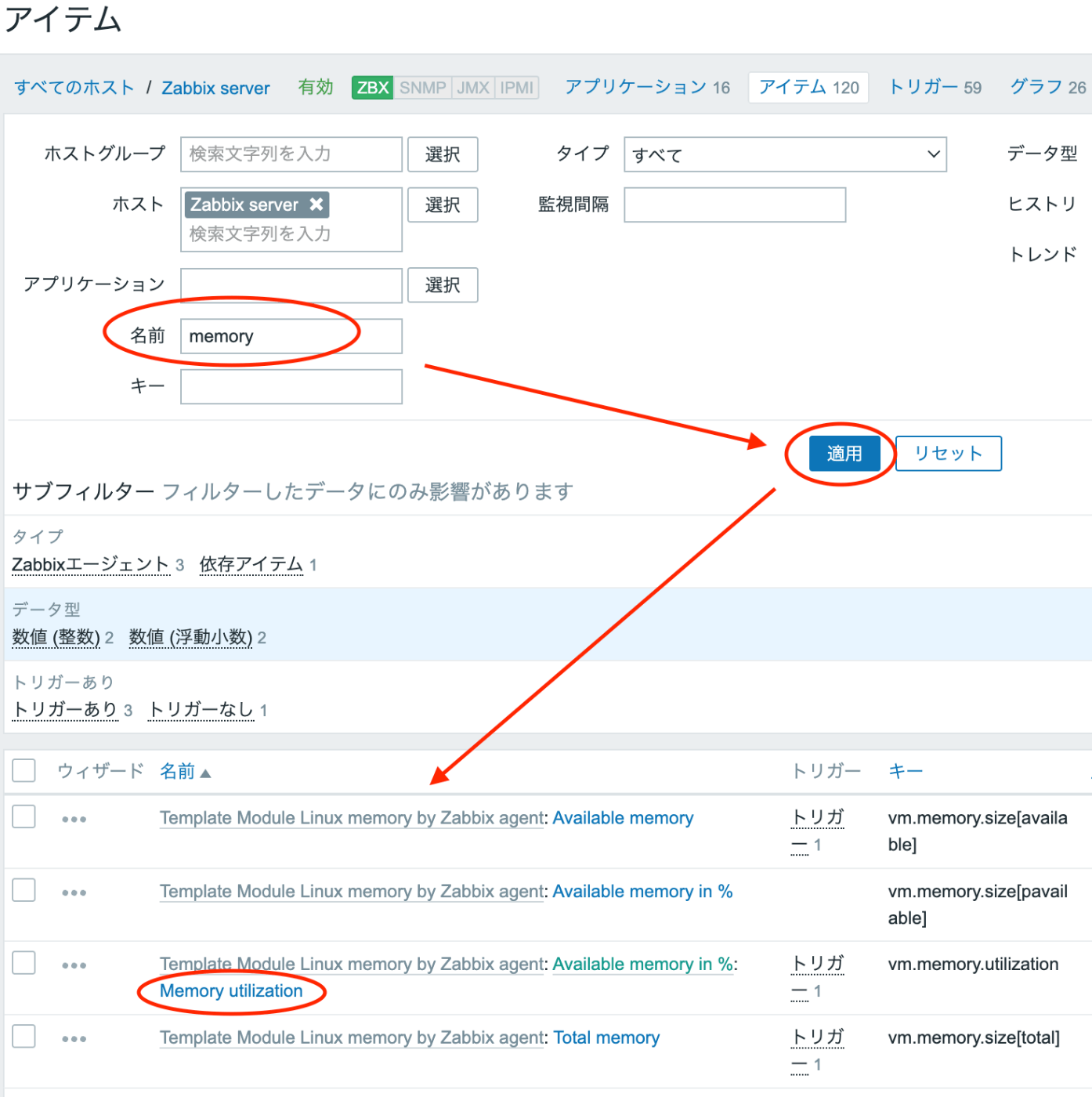
- 表示されたアイテム「Memory utilization」詳細画面のURLを確認し、最後の「itemid=xxxxx」の値(xxxxx)をメモします。

- 先ほどのGoogle Colaboratory画面に戻り、再度画面上の「+コード」をクリックします。
追加されたフォームに、以下のPythonコードを入力します。
ポイントとしては、次の3点です。
- 実際のZABBIXサーバのURL、userID、パスワードを反映。
- 取得したい期間(日時)を指定。
- 取得したいアイテム(収集データ)のID(itemID)を指定。
import requests
import csv
from datetime import datetime, timedelta, timezone
# ZABBIXのAPI情報 URL・userID・passwordは実際の設定に合わせてください
zabbix_server = 'http://xxx.xxx.xxx.xxx/zabbix/api_jsonrpc.php'
zabbix_user = 'Admin'
zabbix_password = 'zabbix'
# ZABBIX APIのエンドポイント
api_endpoint = zabbix_server
# ZABBIX APIへの認証
auth_payload = {
'jsonrpc': '2.0',
'method': 'user.login',
'params': {
'user': zabbix_user,
'password': zabbix_password,
},
'id': 1,
}
response = requests.post(api_endpoint, json=auth_payload)
auth_result = response.json()
if 'result' in auth_result:
auth_token = auth_result['result']
print('ZABBIX authentication successful. Token:', auth_token)
# 開始時刻と終了時刻の設定(例: 2024年3月26日 10:30〜10:45までの期間)
jst = timezone(timedelta(hours=9))
start_time = datetime(2024, 3, 26, 10, 30, 0, tzinfo=jst)
end_time = datetime(2024, 3, 26, 10, 45, 0, tzinfo=jst)
# ファイル名に使うための文字列を作成(例: 20240326_103000_20240326_104500.csv)
filename_datetime_format = "%Y%m%d_%H%M%S"
filename_start_time = start_time.strftime(filename_datetime_format)
filename_end_time = end_time.strftime(filename_datetime_format)
# 出力するファイルパスを指定
csv_file_path = f'/content/drive/MyDrive/ZABBIX API/CSV/{filename_start_time}-{filename_end_time}.csv'
# UNIXエポックへの変換
start_timestamp = int(start_time.timestamp())
end_timestamp = int(end_time.timestamp())
# ZABBIX APIに渡すための形式
start_time_zabbix_format = start_timestamp
end_time_zabbix_format = end_timestamp
# アイテムIDや期間など、取得するデータに合わせて変更してください
history_payload = {
'jsonrpc': '2.0',
'method': 'history.get',
'params': {
'output': 'extend',
'history': 0, # 0は数値データ
'itemids': '31272', # 取得するアイテムのID
'time_from': start_time_zabbix_format, # 開始時間
'time_till': end_time_zabbix_format, # 終了時間
'sortfield': 'clock',
'sortorder': 'ASC',
'limit': 1000, # 取得するデータの制限
},
'auth': auth_token,
'id': 2,
}
history_response = requests.post(api_endpoint, json=history_payload)
history_data = history_response.json()
if 'result' in history_data and len(history_data['result']) > 0:
data_to_write = history_data['result']
# 'clock'のUNIX時間を通常の日時表記に変換する関数
def convert_unix_to_datetime(unix_time):
# UTCから日本標準時に変換
jst = timezone(timedelta(hours=9))
return datetime.fromtimestamp(int(unix_time), tz=jst).strftime('%Y/%m/%d %H:%M:%S')
# 'clock'の値を変換
for row in data_to_write:
row['clock'] = convert_unix_to_datetime(row['clock'])
# CSVファイルにデータを書き込む
with open(csv_file_path, 'w', newline='') as csv_file:
# 列の順序を指定
fieldnames = ['itemid', 'clock', 'ns', 'value']
csv_writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
csv_writer.writeheader()
csv_writer.writerows(data_to_write)
print(f'Data successfully written to {csv_file_path}')
else:
print('No data retrieved or an error occurred.')
else:
print('ZABBIX authentication failed:', auth_result['error'])
このプログラムでは、Googleドライブの指定したパスに、指定日時期間をファイル名としたcsvファイルを保存させています。保存されたcsvファイルを見ると、1分毎にメモリの使用率を収集できていることがわかります。

まとめ
このように、ZABBIX APIを利用して外部のプログラムからZABBIXの収集データを取得することができます。今回の検証例はZABBIXサーバ自身の情報を取得することでしたが、ZABBIXではネットワークに接続された計測器などのデータを送受信し、データを格納することができるので、ZABBIXにあらゆるデータを集約すれば、IoTのようなシステムにとっても強力なツールとして活用することができます。
次回は、このようなデータの送受信に関する手法について、手軽なIoT機器を使用する事例を交えて紹介していきたいと思います。
Discussion