データサイエンス100本ノック(構造化データ加工編)をBigQueryでやりたいに応える
概要
- 今回,BigQueryでデータサイエンス100本ノック(構造化データ加工編)を作りました.
- 同じ手順で,誰もが利用できると思います.
- Dockerで作ったJupyterLab環境で動きます.
- Dockerに関するファイルの説明は行いません.
以下にコード等を置いてありますので,興味がある方はご覧ください.
何か不具合あれば,issueでご連絡ください.
前提
手順
概要
- プロジェクトを作成する
- サービスアカウント/サービスアカウントキーを作成して,ローカルに保管する
- Docker上でBigQueryを動かしてみる
1. プロジェクトを作成する
まず,Google Cloud Platform上でプロジェクトを作成します.
-
ビューの上部にあるプロジェクト セレクタ(<プロジェクト名>▼の箇所)をクリックする
-
プロジェクト セレクタのダイアログ ボックスが表示されるので,右上の新しいプロジェクトをクリックする

-
プロジェクト名入力して,作成をクリックする(ここでは
100knocks-testとしている)
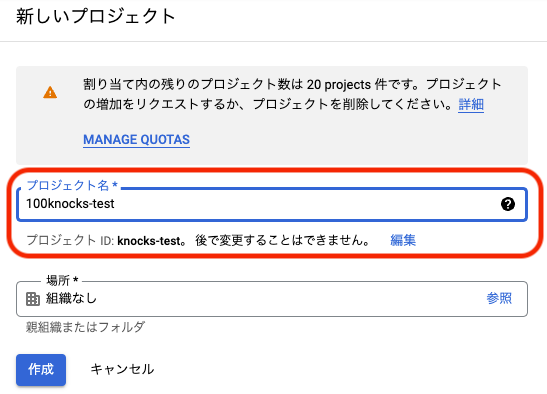
-
ビューの上部にあるプロジェクト セレクタ(<プロジェクト名>▼の箇所)をクリックして,先ほど作成したプロジェクトをクリックして移動する

-
リソースのUIから,BigQueryをクリックする
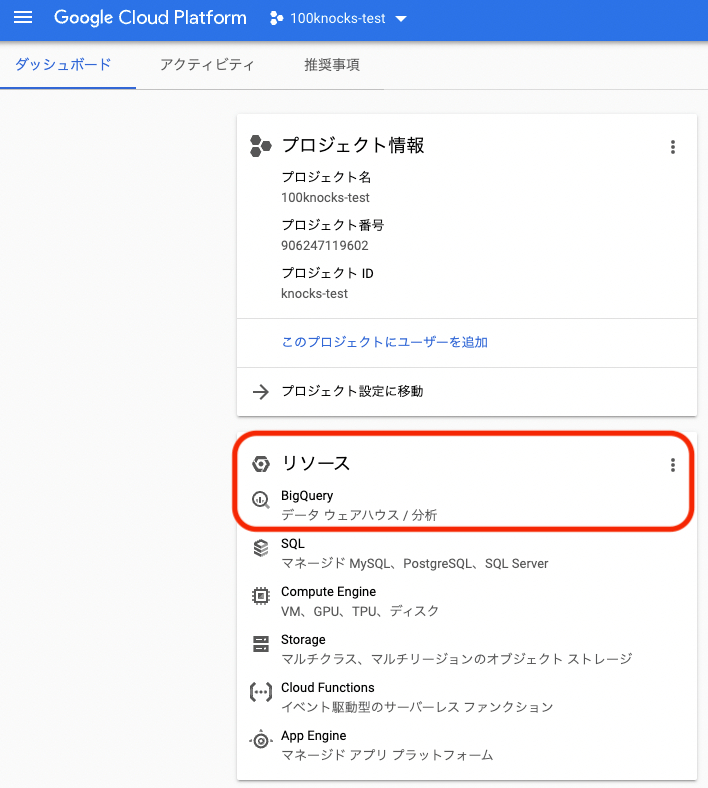
-
右上にでてくるアップグレードをクリックする
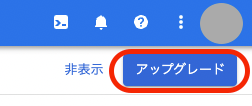
-
請求先のアカウントを選択し,アカウント設定をクリックする(個人だと請求先アカウントしかでない)

2. サービスアカウント/サービスアカウントキーを作成して,ローカルに保管する
続いて,サービスアカウント,およびサービスアカウントキーを作成し,ローカルに保管します.
-
ナビゲーションメニューをクリックし,IAMと管理を選択し,サービス アカウントをクリックする
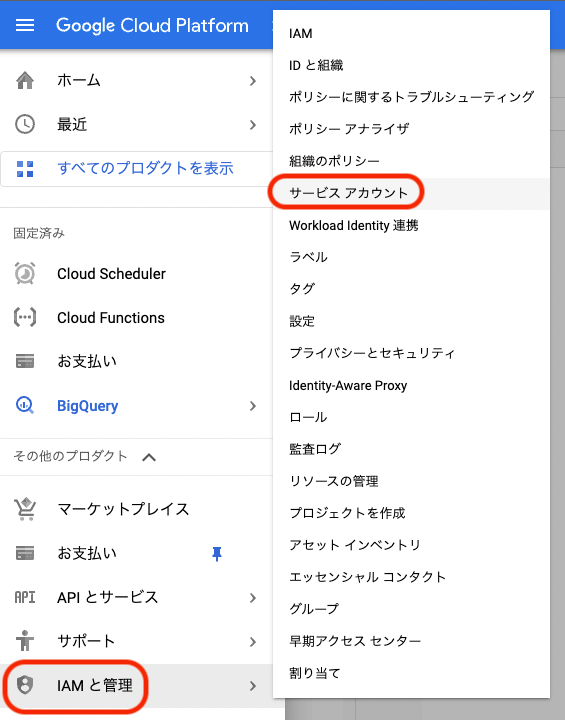
-
+サービス アカウントを作成をクリックする

-
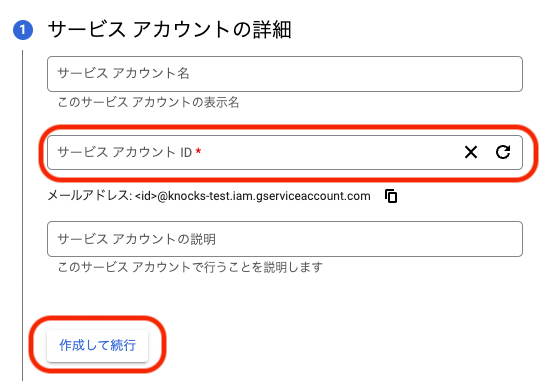
小文字開始の6~30の英数字でサービスアカウント IDを入力し,作成して実行をクリックする
-
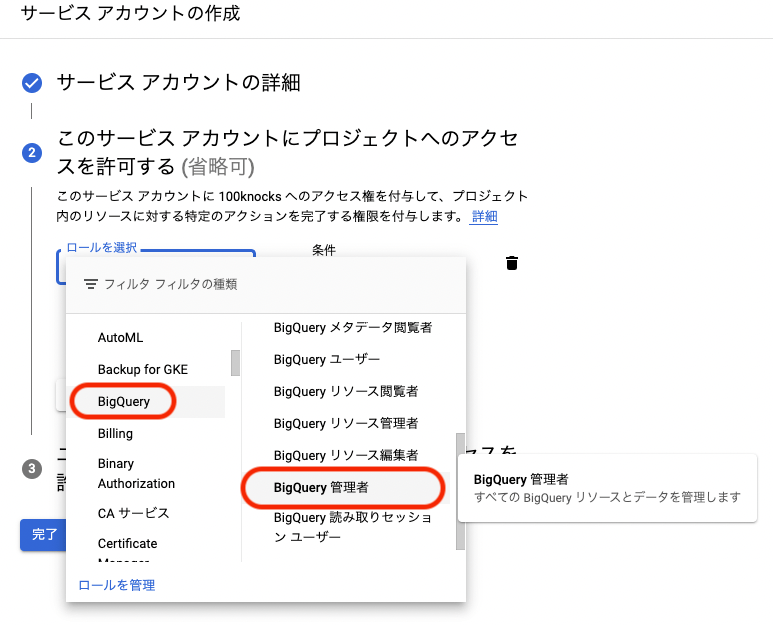
ロールを選択をクリックし,「BigQuery -> BigQuery管理者」を選択し,続行をクリックする
-
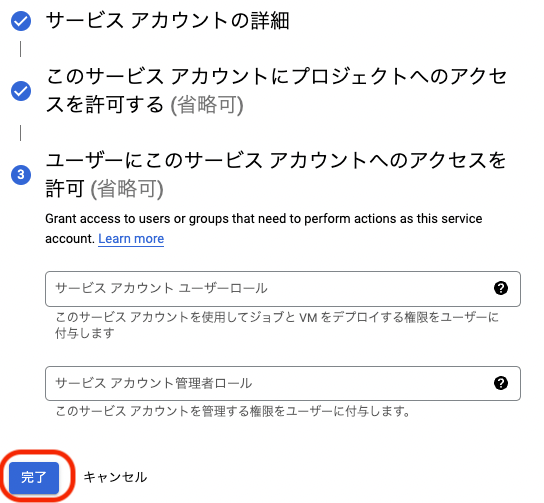
ユーザーにこのサービス アカウントへのアクセスを許可 (省略可)と出たら,完了をクリックする
-
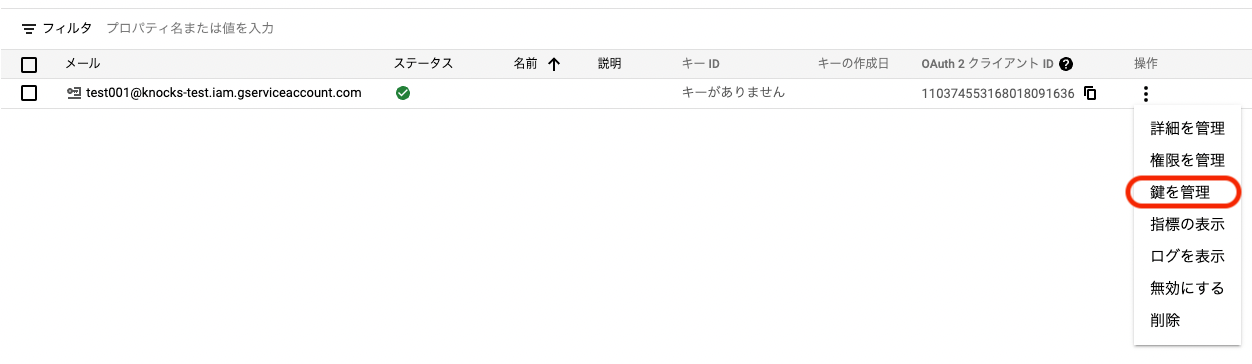
操作の下の「⋮」をクリックし,鍵を管理をクリックする
-
鍵を作成をクリックして,新しい鍵を作成をクリックする
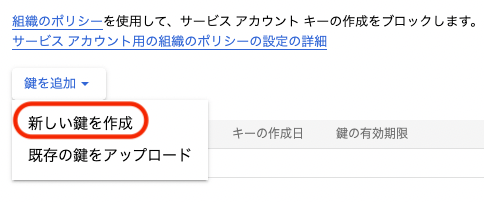
-
キーのタイプはそのまま「JSON」にしたまま,作成をクリックし,デスクトップにダウンロードしておく

-
mkdir /.gcpで隠しフォルダを作成し,mv ~/Desktop/<作成した鍵>.json ~/.gcp/で移動させる
3. Docker上でBigQueryを動かしてみる
いよいよ,BigQueryを動かしてみます.
-
$ git clone git@github.com:yuiki-iwayama/100knocks-preprocess-BigQuery.gitでリポジトリを任意のディレクトリにcloneしてくる -
$ cd 100knocks-preprocess-BigQueryでディレクトリを移動する -
.envファイルをエディターで開き,以下の項目を記載する-
GCP_KEY_PATH=は「~/.gcp/<作成した鍵>.json」を記載する -
GCP_IAM=は,サービスアカウントのメールを記載する
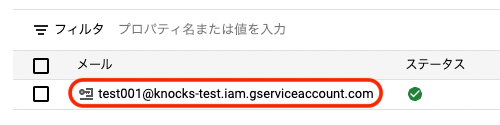
-
GCP_PROJECT_ID=は,「## 1. プロジェクトを作成する」で作ったプロジェクトのIDを記載する
※ナビゲーションメニュー->ホーム->プロジェクトIDで確認できる
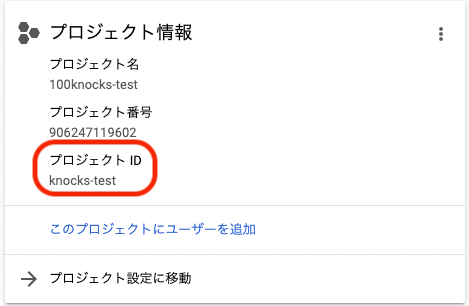
-
GCP_DATA=は,これから作りたいデータセット名を記載する
.env
GCP_KEY_PATH= GCP_IAM= GCP_PROJECT_ID= GCP_DATA= -
-
$ docker-compose up -d --buildでコンテナをbuildする(buildが終わっても,データを送っているため多少時間かかる) -
$ docker-compose logsでデータセットの作成が成功しているかを確認できる -
次にBigQuery上でもデータセットが作成されているかを確認できる
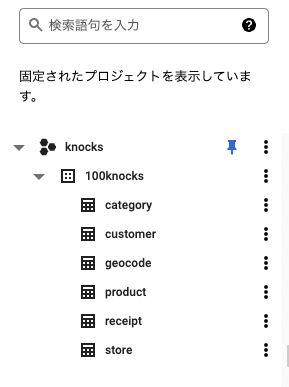
-
ブラウザで
localhost:8888にアクセスしてJupyterLabを立ち上げる -
BigQuery.ipynbを開き,1個めと2個めのセルを実行してうまくいけば,BigQueryで100本ノックを行える
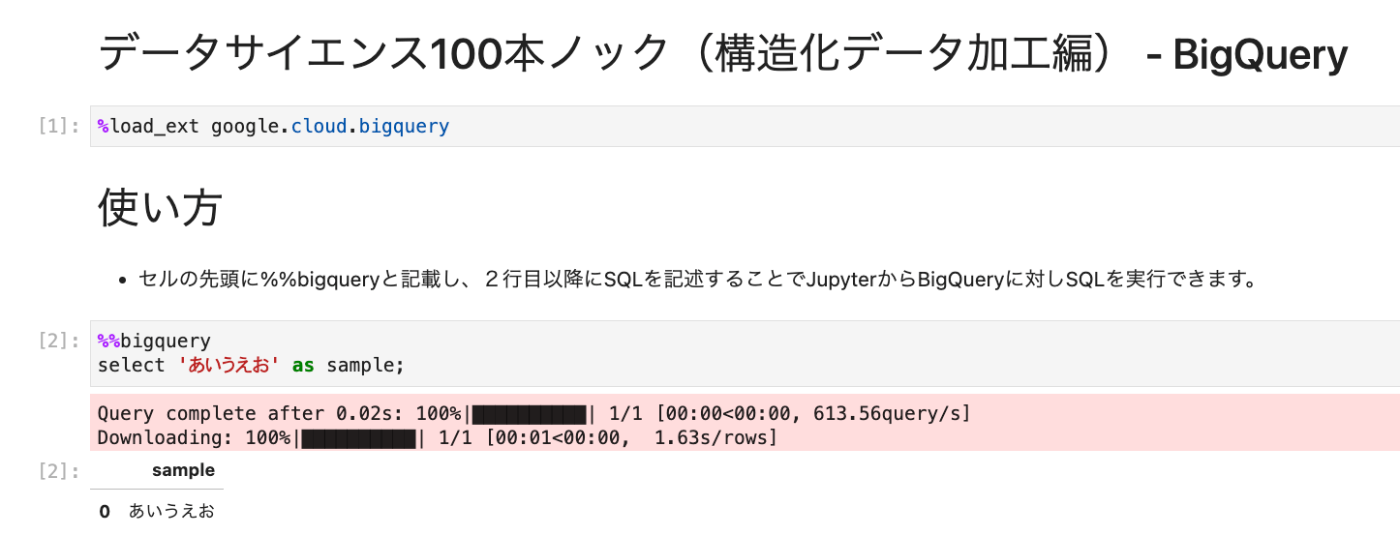
-
Python.ipynbも1個めのセルを実行すれば,BigQueryからデータがDataframeに格納されるので,同様に100本ノックを行える
参考
- The-Japan-DataScientist-Society/100knocks-preprocess
- Cloud SDK のインストール
- BigQueryにローカルのcsvファイルをインポート
- pandas-gbq との比較
-
おそらく無料の範囲内(クエリ:毎月 1 TB,ストレージ:毎月 10 GB)で大丈夫とは思いますが,料金についてはGoogle BigQuery の料金体系を解説を参考にしてください. ↩︎
-
ステップ 1: Google Cloud アカウントを作成するを参考にしてください. ↩︎
-
Docker入門して機械学習環境構築を参考にしてください. ↩︎
-
サンドボックスの状態のままだと,コンテナをbuildしてから60日後にテーブルが消えるかもしれないですが,検証していません.詳しくはクレジットカードは不要 : クエリを無料で試せる BigQuery サンドボックスをご確認ください. ↩︎
Discussion