自己紹介
こんにちは。現在ドリーム・アーツでインターンをしている中島光人(東京大学大学院・修士1年)です。2024年9月~11月にはインターンシップとしてマーケティング部門に所属していましたが、現在は「Shopらん(ショップラン)」のプロジェクトに参加しています。
今回は 「Shopらん」の検索アルゴリズムの刷新に関わらせていただいたので、その内容をまとめます。
検索等に関する事前知識はなくても基本的に理解できる内容になっているので、みなさん是非読んでみてください。
従来の検索システム:キーワード検索
新たな検索システムを説明する前に、これまで用いられていた検索システムがどのようなものであったかを説明します。
これまでの「Shopらん」では、いわゆるキーワード検索が用いられていました。
例えば「りんご」と検索したとき、キーワード検索ではどのような文書が検索にヒットするかというと、当然のことですが「りんご」という単語が含まれている文書が見つかります。
一方、「林檎」「リンゴ」のような単語が含まれている場合はどうでしょうか?
これらの場合は残念ながら見つかりません。
また、appleという単語が含まれているものについても、もちろん見つかりません。
普通キーワード検索と言ったとき、検索文字列についての形態素解析など分析などは行われるものの、apple-りんごのような言語間の翻訳を実施したり、読み仮名を用いて検索したりということは基本的にありません。

また、もう少し業務上で出てきそうな例を挙げてみます。
とある企業のAさんは、ある文書を上司に提出しなければなりませんが、うっかりその締切を忘れてしまいました。
そこでAさんは、どこかの文書にその締切が書いてあったはずだと思い、「締切」という単語で検索をしました。
しかし検索にはそれらしい文書はヒットせず、色々と単語を変えて検索をしていました。
試行錯誤の結果、「提出期限」という単語で検索をしたとき、「提出期限:〇年〇月〇日」と書かれた文書が見つかり、Aさんはことなきを得ました...

このように、ある単語で検索したときに探したい文書が見つからず、さまざまに単語を言い換えてみるということをするのは一種のあるあるだと思われます。
「締切」と言う単語と「提出期限」という単語は非常に意味の近いものですが、例のように、キーワード検索では「締切」と検索しても「提出期限」と書かれた文書を発見することはできません。
目的となる文書を発見するために人間がいちいち言い換えを考えるというのは面倒ですが、かといってキーワード検索のままでは解決することは困難です。
「締切」と「提出期限」が似ているということなどは、キーワード検索を行うエンジンからすれば知ることはできないのです。
(キーワード検索自体、それに用いられている技術が奥深いものではあるのですが、ここではその詳細は割愛します。本記事においては、検索文字列を適切な単位で分解し、表記揺れなどを解消した上で、その文字列を含む文書を探すというものであると考えて問題ありません。)
ベクトル検索
では先ほど述べたようなキーワード検索の欠点を解消する方法はあるのでしょうか?
ベクトル検索がその1つの答えになります。
先にざっくりとした説明をしておくと、ベクトル検索では①すべての単語をベクトルに変換し、②検索文字列のベクトルに近いベクトルを持つ文書を検索します。
急にそんなことを言われてもあまりイメージがつかないかもしれませんが、①②のそれぞれについて例を挙げて説明していきます。
(「すべての単語」というのは実際には世の中で良く用いられる単語に限られますが、その数は非常に多いです。)
単語をベクトルに変換
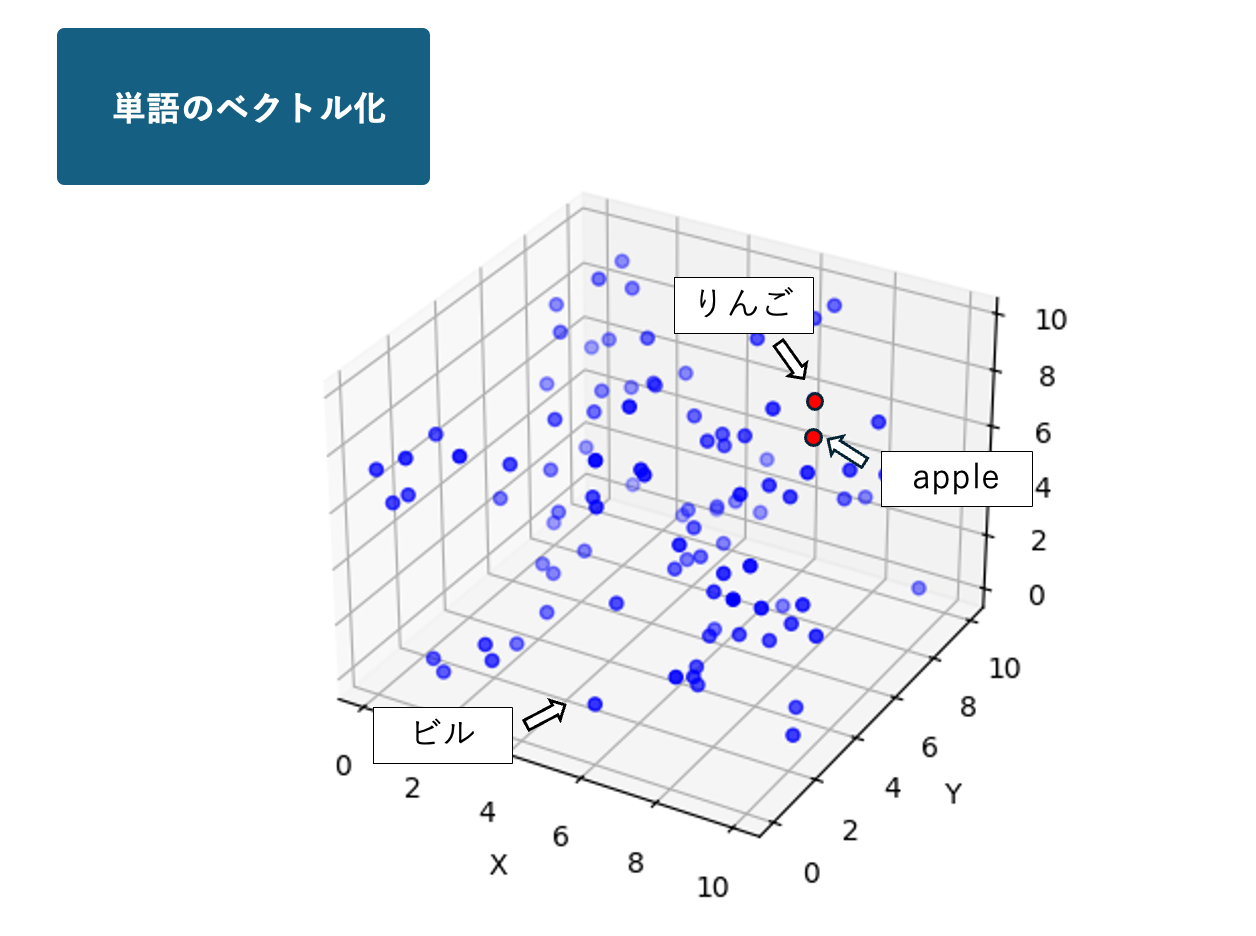
まず①についてです。
ベクトル検索を行うためには、すべての単語を「適切に」ベクトルに変換しておく必要があります。
「適切に」というのは、単語どうしの意味の近さというものが、それらを変換したベクトルどうしの類似度に反映されるように変換するということです。
単語をベクトルに変換する過程のイメージを説明してみます(あくまでもイメージに過ぎないことに注意してください)。
とても大きなボールを頭に思い浮かべてください。
これからそのボールの表面に、何らかの単語が書かれた付箋をたくさん貼り付けていくことを考えます。
このとき、意味の近いものどうしはなるべく近くに来るようにすることに注意します。
とりあえず適当に「りんご」と書かれた付箋をどこかに貼り付けてみましょう。
次に、「apple」と書かれた付箋を貼ります。
「りんご」と「apple」は言語の違いこそあれ意味は同じなので、先ほどの「りんご」の付箋の近くに貼っておきます。
次は「ビル」の付箋を貼ってみます。
「ビル」は「りんご」などとはかけ離れた意味をもつので、「りんご」や「apple」とはある程度離れた位置(ボールの反対側など)に貼ることになるでしょう。
次は「みかん」です。
「みかん」は「りんご」とは違いますが、果物という点では共通しているので、「ビル」よりは「りんご」に近い位置に貼ることにします。
このような作業を世の中で使われているすべての単語に対して繰り返し行うと、最終的にすべての単語の付箋がボールに貼り付けられます。
このときの各付箋の位置が、それに書かれた単語のベクトルを表します。
より正確には、各付箋の位置を、ボールの中心を原点とした3次元の座標で表したとき、その座標がその単語を表すベクトルになります。
例えば「りんご」の付箋の位置の座標が[1, 2, 3]であったとすると、「apple」の位置はそれに近い[1.1, 1.9, 3.1]のようなものになっているでしょう。
また「ビル」の位置は例えば[-3, -2, -1]のような全く異なるものになっていると考えられます。
上のような処理が実際にはコンピュータの中で何らかの技術を用いて自動で行われ(詳しく知りたい方はこちらのWikipediaの記事が良いとっかかりになるかもしれません)、各単語の適切なベクトルが得られます。上では3次元の座標をベクトルとして用いていますが、実際には数百次元のベクトルを用います。
このベクトルのことを単語の埋め込みと呼ぶことがあります。
単語の埋め込みは、単語の意味をコンピュータが解釈可能な形で数の並びに落とし込んだものということができます。
検索文字列のベクトルに近いベクトルを持つ文書の検索
さて、なぜこのようなことをしたのかというと、与えられた検索文字列に対して、それに近い単語を知るためです(②)。
例えば、「林檎」という単語と「apple」という単語が近いということを(それらをベクトルに変換した結果を用いて)知ることができます。
先ほどのAさんの例において考えます。
ベクトル検索においては、先に検索対象となる文書をベクトルに変換しておきます(そのやり方はいくつか考えられますが、文書内の各単語のベクトルを用いて行います)。
そして「締切」と検索した際、「締切」の埋め込みを取得し、それに近いようなベクトルになっている文書を検索します。
すると、「提出期限:〇年〇月〇日」と書かれた文書はある程度「締切」のベクトルに近いベクトルに変換されている(「提出期限」という「締切」に似た単語を含むため)ので、この文書がヒットすることになります。
チャンキング
文書をベクトルに変換する際、文書全体を1つのベクトルに変換することもできますが、もし文書が非常に長いと期待通りの結果にならないことがあります。
例えば「りんご」という文字列が1回しか現れないものの全体は非常に長いような文書を考えると、全体を変換したベクトルの中に「りんご」に関する情報はほとんど含まれないということが考えられます(ベクトルの次元を増やすことでこの影響を緩和できますが、それにも限界があります)。
これに対する対策として、チャンキングというものが考えられています。
チャンキングでは、単純に文書をいくつかの部分(チャンク)に切り分け、その分割したものそれぞれをベクトルに変換して保持します。
切り分け方としては、例えばある一定の長さで切ったり、段落の切れ目で切ったりと言ったものが考えられます。
このチャンキングにより、文書の持つ情報を薄めてしまうことなく文書全体をベクトルに変換できます。
ただし、分割してそれぞれをベクトル化しているので1つの文書に対するベクトルの数は増えていることに注意します。

ベクトル検索の欠点
これだけ聞くと、ベクトル検索はキーワード検索よりも柔軟で強力な検索システムであり、キーワード検索をベクトル検索に置き換えてしまえば良いのではないかと感じるかもしれません。
しかし実用上はベクトル検索だけでは上手く行きません。
特に、ベクトル検索は固有名詞に関する検索能力がキーワード検索に劣ってしまいます。
例えばインターン先企業の「ドリーム・アーツ」と検索したとき、ベクトル検索では「ドリーム・アーツ」を変換したベクトルに近いベクトルを持つ文書がヒットします。
すると、「ドリーム」に反応して「夢」という単語を持つ文書もヒットしてしまうことが考えられます。
「ドリーム・アーツ」と検索したとき、通常は企業名としての「ドリーム・アーツ」を含む文書を探したいはずなので、この挙動は不便です。
一方キーワード検索ではこのようなことは起こり得ないので、ベクトル検索の方が優れているとは一概には言えないということがわかります。
なぜベクトル検索?
ベクトル検索は、キーワード検索の欠点を改善するために用いることができるというのは先ほど述べた通りですが、実はベクトル検索の導入にはもっと深い意味があります。
その1つがRAGの構築です。
RAGとはRetrieval-Augmented Generation(検索拡張生成)の略称ですが、簡単にいうと「データベースと大規模言語モデル(LLM)を組み合わせた検索・応答システム」です。
「昨年度の〇〇の予算を教えて」などといったように、会話を行う形式で用いることができる新たな検索システムということができます。
LLMは入力した文章に対してまるで人間のような回答を返してくれますが、LLMを業務で用いるにあたっての大きな問題点の1つとして、そのままでは「嘘」をついてしまう可能性があるということが挙げられます。
特に、社内の機密情報などに関する質問をすると、それを知らないLLMはそれっぽい嘘の回答をすることになります。
そこで、データベースとの連携を行います。
具体的には、ユーザーが質問を入力すると、その質問に関連する情報をデータベースから検索・取得し、その結果を質問とともにLLMに与えることで最終的な回答を作成させます。
これにより、データベースに基づく正確な知識と、LLMの持つ対話能力を組み合わせた便利なシステム(=RAG)を構築できるというわけです。
そしてこのRAGにおけるデータベースとして現在よく用いられるのがベクトル検索です。
先ほども説明したように、ベクトル検索では単語や文章をベクトルに変換します。
RAGでは人間が文章を入力しそれに対しシステムが文章で回答するので、ベクトル検索の処理はRAGの仕組みと非常に相性が良いです。
将来的には、このようなRAGを「Shopらん」に導入したいという目標があります。
さらに、ベクトル検索の仕組みは例えばお知らせ生成のアシストAIの導入のためにも応用することができると考えられます。
このような目標の達成のため、ベクトル検索の導入は重要なステップになるということです。
ハイブリッド検索
ここまでの議論を表にまとめると以下のようになります。
| 利点 | 欠点 | |
|---|---|---|
| キーワード検索 | 固有名詞に強い | 似た意味でも異なる単語では検索できない |
| ベクトル検索 | 似た意味の異なる単語でも検索できる | 固有名詞に弱い |
キーワード検索とベクトル検索はそれぞれに強みと弱みがあることがわかります。
そこで、これらの良いとこどりをするために、ハイブリッド検索というものが考えられています。
ハイブリッド検索は、キーワード検索とベクトル検索の結果(それぞれのランキング)を何らかのやり方で融合させることで行います。
例えば、「林檎」でキーワード検索した結果、3つの文書a, b, cが見つかったとします(それぞれ検索結果上位1, 2, 3位ということです)。
一方ベクトル検索の結果d, a, bの文書が見つかったとします(同様にそれぞれ検索結果上位1, 2, 3,位)。
| キーワード検索の順位 | ベクトル検索の順位 | |
|---|---|---|
| 文書a | 1位 | 2位 |
| 文書b | 2位 | 3位 |
| 文書c | 3位 | なし |
| 文書d | なし | 1位 |
これらのランキングを組み合わせ、最終的なランキングを作ります。
ここでは例えばそれぞれの順位の逆数の和(順位がない場合は無視)を新たなランキングの指標(スコア)にしてみると、各文書のスコアは次のようになります。
| キーワード検索の順位 | ベクトル検索の順位 | ハイブリッド検索のスコア | |
|---|---|---|---|
| 文書a | 1位 | 2位 | 1.500 |
| 文書b | 2位 | 3位 | 0.833 |
| 文書c | 3位 | なし | 0.333 |
| 文書d | なし | 1位 | 1.000 |
このスコアから、ハイブリッド検索の順位は1位から順にa, d, b, cという結果になります。
| キーワード検索の順位 | ベクトル検索の順位 | ハイブリッド検索のスコア | ハイブリッド検索の順位 | |
|---|---|---|---|---|
| 文書a | 1位 | 2位 | 1.500 | 1位 |
| 文書b | 2位 | 3位 | 0.833 | 3位 |
| 文書c | 3位 | なし | 0.333 | 4位 |
| 文書d | なし | 1位 | 1.000 | 2位 |
このようなスコアの付け方はほんの一例ですが、このようにすることでキーワード検索とベクトル検索の結果の両方を考慮した検索結果を得ることができます。
スコアの付け方にも依存しますが、これによってキーワード検索とベクトル検索のそれぞれの利点を取り入れることができると期待されます。
「Shopらん」におけるハイブリッド検索の導入
これまでの「Shopらん」ではオープンソースの検索エンジンであるApache Luceneを用いてキーワード検索を実施していました。
現在、Luceneの拡張であるApache Solrの9系においてベクトル検索が導入されました。
「Shopらん」ではLuceneからSolrに移行し、このベクトル検索を利用してハイブリッド検索に対応しています。
まずキーワード検索のみの場合と同様に、各文書をインデクシング(詳しくは触れませんが、効率よく検索できるようにするための前処理を含めた文書の登録です)します。
一方その際にチャンキングを行い、各チャンク(子文書と呼称)のベクトルをそれぞれ別の文書に持たせてインデクシングします。
このときチャンキング前の元の文書(親文書と呼称)のidなども保持させておく必要があります。
そうして登録した文書群に対して検索を行います。
キーワード検索は、通常通りインデクシングした文書に対して検索を行います(この結果を後でランキング融合に用います)。
一方ベクトル検索では、検索文字列をベクトル化することでチャンクになっている文書に対して検索を行います。
このとき、同じ親文書に対応する子文書が複数検索にヒットする可能性があります。
これは順位計算のためには不都合なので、それらの中で最もスコアが高いもの(つまり最も検索文字列に似た文字列を含むもの)のみを取り出します。
そしてヒットした子文書(親文書に関する重複はなし)について、保持していた親文書のidをもとに親文書を取得します。
これらの結果から、ランク融合アルゴリズム(例えばReciprocal Rank Fusion(RRF))など)を用いることで、最終的な順位を得ることができます。
まとめと感想
本記事では、「Shopらん」にベクトル検索を導入するにあたって、その特徴や意義、実際の導入の方法について簡単に紹介しました。
自分が以前までエンジニアインターンに対して持っていたイメージは、事前に細かく分けられたタスクを消化していくという形で業務を体験するようなものでした。
しかし今回のインターンでは、検索システムの刷新にあたって、「どのようにベクトル検索を実現できるのか」「どのようなアルゴリズムが知られているのか」などといった基本的なことから自ら調査し、実装および実験を行うという、インターンとしてはある意味チャレンジングな内容に取り組みました。
その中で、ベクトル検索等の検索に関する知見を学ぶことができたのはもちろん、「Shopらん」という巨大なコードベースからなるソフトウェアの裏側に深く関わることができました。
社内エンジニアの方々からのサポートもあり、ドリーム・アーツのインターンを通じてエンジニアとして大きく成長できたことに感謝しています。
単に業務を体験するだけでなく、実際の業務に主体的に関わり、エンジニアとしての経験を積んでいきたい・様々な課題にチャレンジしたいと考えている方には、ぜひインターンへの応募をおすすめします。
昨今の生成AIはものすごい速さで進化しており、ある程度大規模なアプリケーションについては何らかの形で生成AIを取り入れることが当たり前になっていくのではないかと思います。
そのような中で、「Shopらん」に生成AIを用いたRAGを導入することは、ドリーム・アーツの掲げる「デジタルの民主化」を次のステージに押し上げるための第一歩になるのではないかと勝手ながら期待しています。
本記事は以上です。お読みいただきありがとうございました。

Discussion