[Cube] 体感!セマンティックレイヤー
概要
布教用に書いた、とりあえずセマンティックレイヤーを体感してみようという趣旨の記事です。
具体的には theLook eCommerce という BigQuery の Public Dataset に対して、Cube Core でセマンティックレイヤーを実装し、marimo というアプリケーションからデータ活用するところまでやります。ほぼ SQL を書かずにデータ活用できちゃう様子をご覧あれ。
書くこと
- BigQuery / Cube Core / marimo を使った、セマンティックレイヤーの簡単なデモ
書かないこと
- BigQuery / Cube Core / marimo の詳しい説明
- セマンティックレイヤーの概念的な説明(ほかに素敵な資料がたくさんあるので[1])
準備
インストールする必要があるやつ
- gcloud CLI
- uv
- docker / docker compose
その他準備
- GoogleCloud で BigQuery は使えるようにしておく
-
gcloud auth application-default loginで認証しておく
デモ
必要なコードは GitHub に置いてあるので、git clone しておくと手元で再現しやすいです。
git clone https://github.com/kitta65/zenn-semantic-layer
cd zenn-semantic-layer
Cube Core
起動
さっそく Cube から触っていきます。Cube はセマンティックレイヤーの実装に特化したツールですが、この記事で扱う Cube Core はその OSS 版です。ちなみにこの記事で Cube Core をとりあげた理由は、無料で使えて、必要な前提知識が少なく、布教用にちょうどよかったためです[2]。
docker image が公開されているので、さっそくそれを起動したいところですが、その前にいくつかの設定を .env に書き出しておきます。
前半は root 権限で実行しないためにユーザー関連の設定をしていて、後半は BigQuery の認証関連です。GoogleCloud でサービスアカウントを発行するのが面倒くさいので、gcloud auth application-default login で発行される認証情報で代用しています。
{
echo "UID=$(id -u)"
echo "GID=$(id -g)"
echo "CUBEJS_DB_BQ_PROJECT_ID=$(gcloud config get project)"
echo "CUBEJS_DB_BQ_CREDENTIALS=$(cat "${HOME}/.config/gcloud/application_default_credentials.json" | base64 | tr -d '\n')"
} >> .env
準備ができたら docker compose up で起動して、ブラウザで http://localhost:4000 を開きましょう。cube/models/cube 以下にすでにいくつか yml を置いているので、すぐにでも Playground で遊べる状態になっていると思います。
services:
# see https://cube.dev/docs/product/getting-started/core/create-a-project#scaffold-a-project
cube:
image: cubejs/cube:v1.3.54
ports:
- 4000:4000
- 15432:15432
user: "${UID}:${GID}"
environment:
- CUBEJS_DB_TYPE=bigquery
- CUBEJS_DEV_MODE=true
- CUBEJS_DB_BQ_PROJECT_ID=${CUBEJS_DB_BQ_PROJECT_ID}
- CUBEJS_DB_BQ_CREDENTIALS=${CUBEJS_DB_BQ_CREDENTIALS}
volumes:
- ./cube:/cube/conf

Data Modeling
上のスクショでは、架空の EC サイトの注文履歴について「この四半期における」「日ごとの」「ユニークユーザー数」を集計しています。なぜこのような集計ができるかというと、事前に cube/model/cubes 以下の yml ファイルで定義した dimension や measure に基づいて、裏側で以下のような SQL を書いてくれるからです。
SQL
SELECT
TIMESTAMP(DATETIME_TRUNC(
TIMESTAMP(DATETIME(`orders`.created_at, 'UTC')),
DAY
)) as `orders__created_at_day`,
count(distinct `orders`.user_id) as `orders__count_user`,
FROM bigquery-public-data.thelook_ecommerce.orders AS `orders`
WHERE (
`orders`.created_at >= TIMESTAMP(?) -- 2025-07-01T00:00:00.000000Z
AND `orders`.created_at <= TIMESTAMP(?) -- 2025-09-30T23:59:59.999999Z
)
GROUP BY 1
ORDER BY 1 DESC
LIMIT 10000
cubes:
- name: orders
sql_table: bigquery-public-data.thelook_ecommerce.orders
data_source: default
joins:
- name: users
sql: "{orders}.user_id = {users}.id"
relationship: many_to_one
dimensions:
- name: order_id
sql: "{CUBE}.order_id"
primary_key: true
type: string
- name: user_id
sql: "{CUBE}.user_id"
type: string
- name: created_at
sql: "{CUBE}.created_at"
type: time
measures:
- name: count
type: count
- name: count_user
type: count_distinct
sql: "{CUBE}.user_id"
# multi-stage calculations (prior date)
# see https://cube.dev/docs/product/data-modeling/concepts/multi-stage-calculations#prior-date
- name: count_prev_year
multi_stage: true
sql: "{count}"
type: number
time_shift:
- time_dimension: created_at
interval: 1 year
type: prior
- name: ratio_count_yoy
multi_stage: true
sql: "{count} / {count_prev_year}"
type: number
pre_aggregations:
# Pre-aggregation definitions go here.
# Learn more in the documentation: https://cube.dev/docs/caching/pre-aggregations/getting-started
yml についてざっくり説明すると、
-
sql_table:DWH 上のどのテーブルを利用するか指定します- この記事で利用するデータは全て theLook eCommerce という BigQuery の public dataset のテーブルで、架空の EC サイトのデータです
-
joins:他のテーブル(正確には cube)と join する場合の方法を指定します- ここでは cube/model/cubes/users.yml で定義した cube と join できるようにしています
- これによって geneder を切り口にした分析なども可能になります
-
dimensions:どのカラムを分析の切り口として使うか(SQL でいう group by や where 句に使うか)を指定します -
measures:どのような指標を集計するか(SQL でいうとsum(column_name)とか集約関数に相当)を指定します
正確な説明は公式ドキュメントの Data Modeling あたりを読んでください。
さて、Playground で遊ぶのに飽きたら次のステップに進みましょう。
marimo
セマンティックレイヤーを通して、他のアプリケーションからデータを活用してみましょう。今回は marimo という Python notebook から Cube にアクセスしてみます。
起動
グローバルに marimo をインストールしたくないので、uv 経由で仮想環境にインストールします。
uv sync
その後 uv run marimo edit demo.py を実行すると、ブラウザでこんな感じの notebook が開きます。

SQL API
アプリケーションから Cube を通してデータを取得する方法はいくつかありますが、そのうちの一つが SQL API です。Cube を PostgreSQL とみなして接続[3]し、SQL で dimension や measure を指定します。上のスクショに映り込んだ SQL がちょうどその部分です。
-- 注文履歴について、四半期ごとのユニークユーザー数
SELECT
DATE_TRUNC('quarter', orders.created_at) as quarter, -- dimension
MEASURE(orders.count_user) as count_user -- measure
FROM orders
GROUP BY 1
LIMIT 10000;
簡単に Cube からデータを取得できていますね!すばらしい!と言いたいところですが、アプリケーション側にこの SQL を書くのは気が進まない、というのが正直な気持ちです。理由はこんな感じ。
- Python (に限らずアプリケーションを実装している言語)を書いている途中で SQL を書きたくない(コンテキストスイッチ)
-
DATE_TRUNC('quarter', ...)のような SQL をささっと書ける自信がない(書き慣れている BigQuery の SQL と引数の順番が違うし...) - dimension を select 句に追加したら group by 句もいじる必要があったりと面倒
ほかの方法も試してみましょう。
GraphQL API
Cube は REST API / GraphQL API も備えています。
なるべくコード補完を効かせつつ型安全に Cube 連携を実装するなら、連携用のコードを生成してしまうのが良い気がしてきました。指定可能な dimension や measure は yml ファイルに書いてあるのだから、これを解析すればコード生成できる気もしますね。ただ、GraphQL API があるのだから introspection してしまう方が簡単そうです。今回はこの作戦でいきましょう。
GraphQL API を introspection して Python 用のコードを生成するために、ariadne-codegen を使ってみます。必要な設定は pyproject.toml に記載しておいたので、あとは uv run ariadne-codegen client を実行するだけです。
[tool.ariadne-codegen]
remote_schema_url = "http://localhost:4000/cubejs-api/graphql"
enable_custom_operations = true
uv run ariadne-codegen client
生成されたコードを利用すると、以下のように Cube を呼び出してデータを取得できます。GraphQL API が返すデータの構造が深いので、その辺はちょっとごにょごにょしています。
# 生成されたコードの import
from graphql_client import Client, OrderBy
from graphql_client.custom_fields import (
OrdersMembersFields,
OrdersWhereInput,
UsersMembersFields,
ResultFields,
TimeDimensionFields,
)
from graphql_client.input_types import OrdersOrderByInput, DateTimeFilter
from graphql_client.custom_queries import Query
client = Client(url="http://localhost:4000/cubejs-api/graphql")
# dataframe としてデータを取得するするヘルパー関数
async def pl_from_query(query, operation_name="temp_query"):
data = await client.query(query, operation_name=operation_name)
data = data["cube"]
data = map(
lambda x: flatten_dimensions(flatten_cubes(x)),
data,
)
return pl.from_dicts(data)
def flatten_cubes(cubes):
res = {}
for key, val in cubes.items():
for k, v in val.items():
res[f"{key}_{k}"] = v
return res
def flatten_dimensions(dims):
res = {}
for key, val in dims.items():
if isinstance(val, dict): # if time dimension
for k, v in val.items():
res[f"{key}_{k}"] = datetime.datetime.fromisoformat(v)
else:
res[key] = val
return res
# 実際のデータ取得はここから
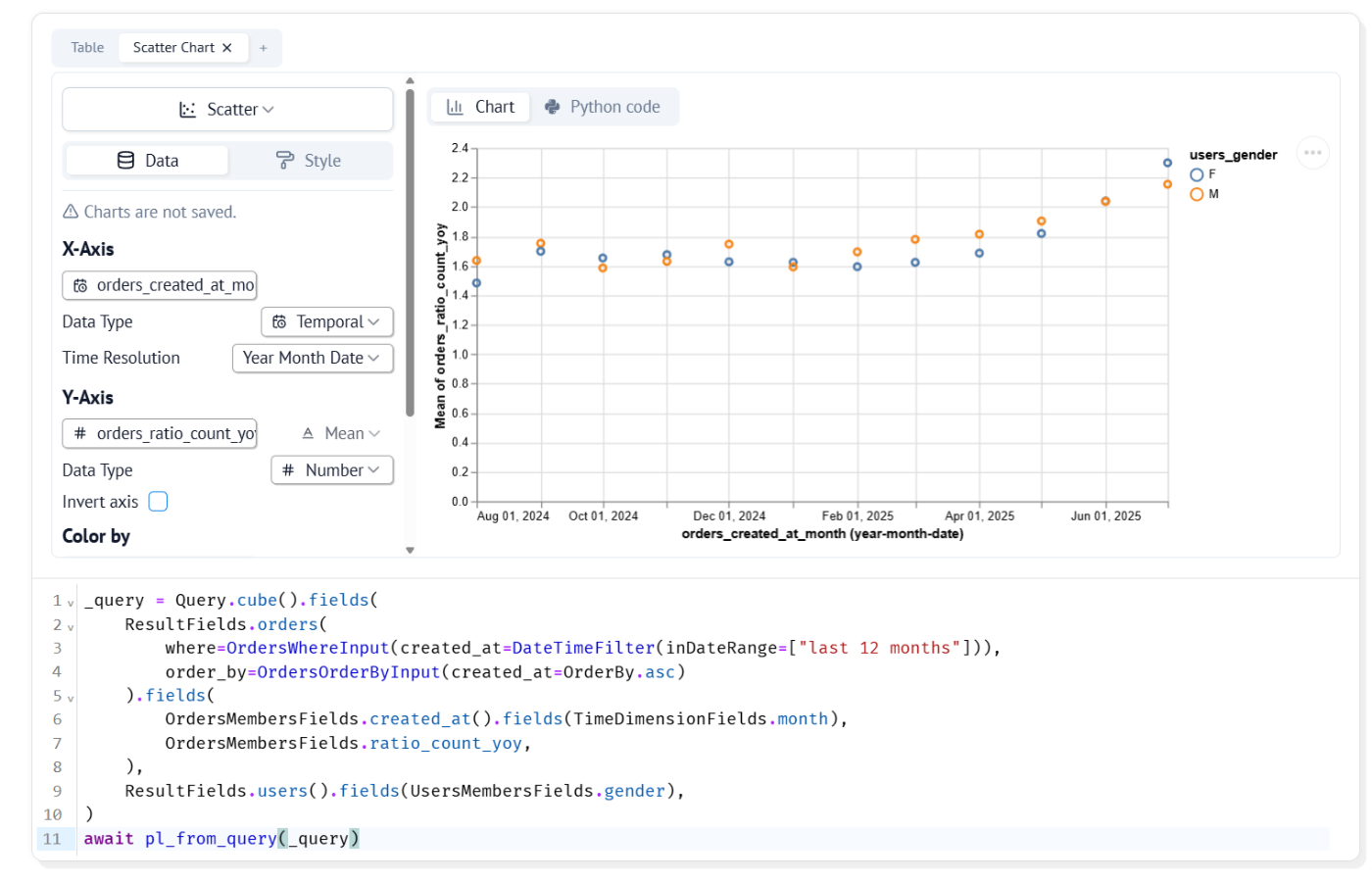
# 注文数の前年同月比を直近12ヶ月について男女それぞれ集計
_query = Query.cube().fields(
ResultFields.orders(
where=OrdersWhereInput(created_at=DateTimeFilter(inDateRange=["last 12 months"])),
order_by=OrdersOrderByInput(created_at=OrderBy.asc)
).fields(
OrdersMembersFields.created_at().fields(TimeDimensionFields.month),
OrdersMembersFields.ratio_count_yoy,
),
ResultFields.users().fields(UsersMembersFields.gender),
)
await pl_from_query(_query)
わりと複雑な集計を試しましたが、データの取得自体は簡潔に書けていますね。marimo 上でぽちぽち可視化まで行うとこんな感じです。参考程度に裏側で生成される SQL も貼っておきます(結構複雑...)。
sql
WITH
cte_0 AS (
SELECT
`users`.gender as `users__gender`,
`orders`.order_id as `orders__order_id`,
TIMESTAMP(DATETIME_TRUNC(
TIMESTAMP(DATETIME(`orders`.created_at, 'UTC')),
MONTH
)) as `orders__created_at_month`,
FROM
bigquery-public-data.thelook_ecommerce.orders AS `orders`
LEFT JOIN bigquery-public-data.thelook_ecommerce.users AS `users` ON
`orders`.user_id = `users`.id
WHERE (
`orders`.created_at >= TIMESTAMP(?)
AND `orders`.created_at <= TIMESTAMP(?)
)
GROUP BY 1, 2, 3
ORDER BY 3 ASC
),
cte_1 AS (
SELECT
`users__gender` as `users__gender`,
`orders__created_at_month` as `orders__created_at_month`,
count(`orders__order_id`) as `orders__count`,
FROM (
SELECT
q_0.`users__gender`,
q_0.`orders__order_id`,
q_0.`orders__created_at_month`,
FROM cte_0 as q_0
ORDER BY 3 ASC
) AS cte_1_join
GROUP BY 1, 2
ORDER BY 2 ASC
),
cte_2 AS (
SELECT
`users`.gender as `users__gender`,
`orders`.order_id as `orders__order_id`,
TIMESTAMP(DATETIME_TRUNC(
TIMESTAMP(DATETIME(
(
TIMESTAMP(DATETIME_ADD(
DATETIME(`orders`.created_at),
INTERVAL 1 YEAR
))
),
'UTC'
)),
MONTH
)) as `orders__created_at_month`,
FROM
bigquery-public-data.thelook_ecommerce.orders AS `orders`
LEFT JOIN bigquery-public-data.thelook_ecommerce.users AS `users` ON
`orders`.user_id = `users`.id
WHERE (
(TIMESTAMP(DATETIME_ADD(DATETIME(`orders`.created_at), INTERVAL 1 YEAR)))
>= TIMESTAMP(?)
AND (
TIMESTAMP(DATETIME_ADD(DATETIME(`orders`.created_at), INTERVAL 1 YEAR))
)
<= TIMESTAMP(?)
)
GROUP BY 1, 2, 3
ORDER BY 3 ASC
),
cte_3 AS (
SELECT
`users__gender` as `users__gender`,
`orders__created_at_month` as `orders__created_at_month`,
count(`orders__order_id`) as `orders__count`,
FROM (
SELECT
q_0.`users__gender`,
q_0.`orders__order_id`,
q_0.`orders__created_at_month`,
FROM cte_2 as q_0
ORDER BY 3 ASC
) AS cte_3_join
GROUP BY 1, 2
ORDER BY 2 ASC
),
cte_4 AS (
SELECT
`users__gender` as `users__gender`,
`orders__created_at_month` as `orders__created_at_month`,
`orders__count` as `orders__count_prev_year`,
FROM (
SELECT
q_0.`users__gender`,
q_0.`orders__created_at_month`,
`orders__count` as `orders__count`,
FROM cte_3 as q_0
ORDER BY 2 ASC
) AS cte_4_join
),
cte_5 AS (
SELECT
`users__gender` as `users__gender`,
`orders__created_at_month` as `orders__created_at_month`,
`orders__count` / `orders__count_prev_year` as `orders__ratio_count_yoy`,
FROM (
SELECT
q_0.`users__gender`,
q_0.`orders__created_at_month`,
`orders__count` as `orders__count`,
`orders__count_prev_year` as `orders__count_prev_year`,
FROM
cte_1 as q_0
INNER JOIN cte_4 as q_1 ON
(
q_0.`users__gender` = q_1.`users__gender`
OR (q_0.`users__gender` IS NULL AND q_1.`users__gender` IS NULL)
)
AND (
q_0.`orders__created_at_month` = q_1.`orders__created_at_month`
OR (
q_0.`orders__created_at_month` IS NULL
AND q_1.`orders__created_at_month` IS NULL
)
)
ORDER BY 2 ASC
) AS cte_5_join
)
SELECT
q_0.`users__gender`,
q_0.`orders__created_at_month`,
`orders__ratio_count_yoy` as `orders__ratio_count_yoy`,
FROM (SELECT * FROM cte_5) as q_0
ORDER BY 2 ASC
LIMIT 10000
ちなみにこのコードを書くとき、marimo 上でもまあまあコード補完は効きました(当初の目論見どおり)。

後書き
ざっくりセマンティックレイヤーを実装して、他のアプリケーションから SQL API や GraphQL API で呼び出すところまでやってみました。
ほぼ SQL を書かずにデータ活用ができて素晴らしい!という気持ちもある一方で、ちゃんと活用するには使いやすいテーブルを整備するのが大前提として必要だよな、などと思ったりしました。
この記事はセマンティックレイヤーを Cube で実装しましたが、もし業務で本格的に検討するタイミングがあったら、もう少しちゃんとツールは比較検討したいですね。連携方法[4]と、そのためのコードを自動生成できるか[5]が気になりポイント。
-
たとえば「セマンティックレイヤー入門」 ↩︎
-
Looker は高いし、dbt semantic layer は dbt cloud の無料プランから使えないし、lightdash は dbt から説明しないといけないし dbt semantic layer との住み分けが今後どうなるかわからないし... ↩︎
-
ちなみに marimo は、GUI で必要な情報を入力すると DB に接続するコードを生成してくれるので、それを利用しました。 ↩︎
-
といっても、どのツールも似たり寄ったりな印象はあります。Cube でいう SQL API のようなものは Looker だと Open SQL Interface があるし、dbt semantic layer だと JDBC API があります。GraphQL API は dbt semantic layer にもある。 ↩︎
-
実は Cube には JavaScript SDK があるので、もしアプリケーション側が JavaScript だったらコード生成をするまでもなかった説もあります。でも汎用的な SDK だと自分のセマンティックレイヤーの実装に合わせたコード補完など、かゆいところに手が届かない予感。 ↩︎
Discussion