自作Goコンパイラでマルチスレッドが動くようにするまで
自作Goコンパイラ babygo でマルチスレッドを動かすこと(=子スレッドの作成)に成功しました。
実は以前に挫折していた
1年半前に 一作目のGoコンパイラ minigo でもマルチスレッドに挑戦したことがあるんですが、そのときは子スレッド生成後すぐに Segmentation Faultが起きてしまい、解決方法わからずあきらめたのでした。(動かなかった syscall cloneの残骸 https://github.com/DQNEO/minigo/blob/5ab7420fbca2f65d81bc761d5cbe51a2b28953a8/internal/runtime/runtime.s#L41-L61 )
(当時は gdb でステップ実行すると他のスレッドも処理が進むということを知らなかったので、ただただ謎の挙動にしか見えなかった)
今回やったこと
今回は以下のように要素技術をしっかり押さえてから実装に望みました。
- アセンブラを自作してみて、マシン語や実行バイナリの仕組みに慣れる
- 公式Goのマルチスレッドの振る舞いを gdb でステップ実行して観察
- gdb でのマルチスレッドの扱いになれる
- 同時に公式runtimeのコードも読んで、自分できる範囲で細かいところまで挙動を把握
syscall cloneに再挑戦
さて syscall clone に1年半ぶりに挑戦です。
まずは引数なしで syscall cloneを呼んでみたらあっさりと動きました。
あれ?こんな簡単に動くのは変だと思ってよく見たら、flag指定なしの場合はどうやら親子でメモリを共有しないようです。(つまりマルチスレッドではなくマルチプロセス。fork()と同じ。)
気を取り直してこんな感じでflagsオプション全指定で clone(2)を呼んでみたところ、
cloneFlags = _CLONE_VM | /* share memory */
_CLONE_FS | /* share cwd, etc */
_CLONE_FILES | /* share fd table */
_CLONE_SIGHAND | /* share sig handler table */
_CLONE_SYSVSEM | /* share SysV semaphore undo lists (see issue #20763) */
_CLONE_THREAD /* revisit - okay for now */
clone(2)自体は成功するものの、親スレッドが動いてる最中に突然 Segmentation fault で落ちる。これはまさに1年半前に遭遇した現象です。
ただ今回は上記の公式Goのバイナリ観察の過程で gdbマルチスレッドの操作を習得していたので、親子スレッドを切り替えながら落ち着いて挙動を観察してみました。
わかったことは、
- 落ちているのは親スレッドの方。clone成功後、毎回違う箇所で落ちる。子スレッドが終了するタイミングの前後で親が落ちる
- 子スレッド側のコードを変更しながら動きを観察すると、clone(2)直後に子スレッドが別の関数を呼ぶと親が落ちる。呼ぶ関数が1階層だけだとなぜか落ちないけど、呼んだ先で別の関数を呼ぶと親が落ちる。
- 子スレッドでメモリ操作しているコードは特にない。ので、親のメモリを破壊したりはしてないはず。
coreファイルを吐かせてみる
"coredump"という単語をふと思い出しました。今まで聞いたことはあったものの使ったことはありませんでした。もしやこれを使う出番なのかも。
docker のデフォルトだとこれが offになっているっぽいのですが on にできるそうです。藁をもすがる思いでcoreダンプを吐かせてみました。
docker:babygo $ ulimit -c unlimited
docker:babygo $ /tmp/bbg/pre-test >/dev/null
Segmentation fault (core dumped)
お見事 core ファイルが生成されました。
docker:babygo $ ls -l core
-rw------- 1 root root 620388352 Sep 20 14:39 core
gdbでコアダンプを解析
いよいよ gdb で解析です
docker:babygo $ gdb /tmp/bbg/pre-test core
...
Reading symbols from /tmp/bbg/pre-test...
(No debugging symbols found in /tmp/bbg/pre-test)
[New LWP 1085]
Core was generated by `/tmp/bbg/pre-test'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x00007fffffffe680 in ?? ()
coreを読ませると Segmentation fault が起きた直後のプロセスの状態を再現してくれるんですね。これはすごい...!
さて backtraceを表示してみると、現在実行中のコードが変な場所になっています。
(gdb) backtrace
#0 0x00007fffffffe680 in ?? ()
#1 0x000000000041eb50 in runtime.clone ()
#2 0x000000000041c668 in runtime.main ()
Backtrace stopped: previous frame inner to this frame (corrupt stack?)
(gdb)
なにやら warningっぽいメッセージも出ている。
gdbのコード表示もこんな感じのわけのわからないコードを表示している。
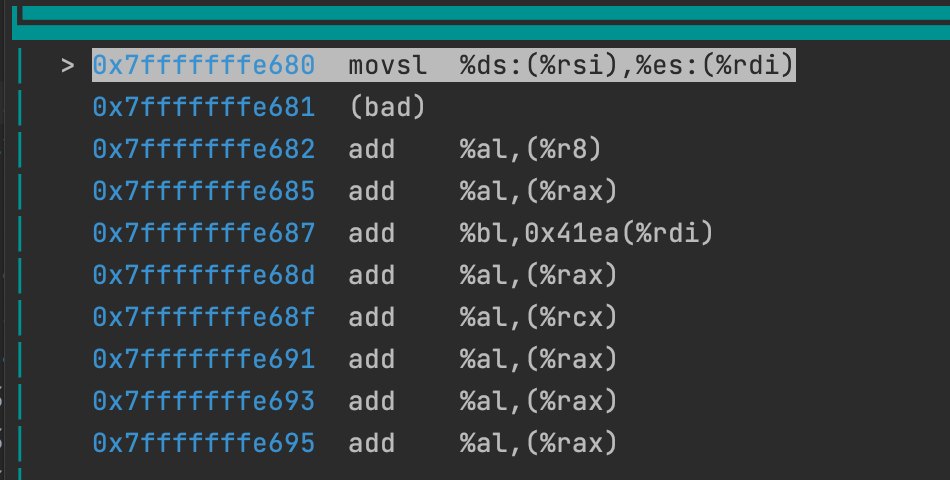
わけのわからないコード領域の中身にヒントが
以前の自分だったらもうここでお手上げだったところですが、今回はアセンブラを自作した後なので、これを見ると「これはコードじゃない場所に誤ってジャンプしてしまったっぽい」と察しがつくわけです。
add %al, みたいなのが延々と並んでるのは、たぶん何かのデータ領域のデータが無理やりディスアセンブリされてしまった結果だろうと察しがつきました。
そこでググってみるとこんな記事を発見。
こんなヒントが書かれていました。
(gdb) set $pc = *(void **)$rsp
(gdb) set $rsp = $rsp + 8
The other 1% of the time, the error will be due to overwriting the stack
要は SPレジスタの指すスタック領域のアドレスが、誤ってPCレジスタにセットされてしまった可能性を示唆するものでした。いやはやすごいヒントを出す人がいるものです。
さて今実行中のコード領域のメモリの中身を見てみると、
(gdb) x/1gx 0x7fffffffe680
0x7fffffffe680: 0x000000000041eaa5
たしかに本当のコード領域っぽいアドレスが見えます。
さらに rsp や他のレジスタを覗いてみると、
(gdb) i r rsp
rsp 0x7fffffffe648 0x7fffffffe648
のようになっており、0x7fff... はOSが提供するスタック領域であると見て間違いなさそうです。
ジャンプした先がスタック領域だった?
つまり「何らかの理由によりスタック領域にジャンプしてしまった」ということが確定です。
これは、子スレッドが親スレッドのスタックポインタ近辺のメモリを書き換えてしまったのが原因ではなかろうか?
子スレッドで普通に call 命令を発行するとこれは自然に起きてしまうのでは?という考えにいたり、もう一度いろいろググって見たら clone(2) の公式マニュアルの中に答えを見つけました。
child_stack 引き数は、子プロセスによって使用されるスタックの位置を指定する。 子プロセスと呼び出し元のプロセスはメモリを共有することがあるため、 子プロセスは呼び出し元のプロセスと同じスタックで実行することができない。 このため、呼び出し元のプロセスは子プロセスのスタックのためのメモリ空間を 用意して、この空間へのポインタを clone ()へ渡さなければならない。 (HP PA プロセッサ以外の) Linux が動作する全てのプロセッサでは、 スタックは下方 (アドレスが小さい方向) へと伸びる。このため、普通は child_stack は子プロセスのスタックのために用意したメモリ空間の一番大きい アドレスを指すようにする。
まさにこれ!変なプライドで英語のドキュメントばかりを読んでたので、英語力がないために完全に見落としていた。。。
もう一度 公式Goの runtimeを読んでみたら、たしかに runtime.clone の中で新スタックのアドレスを渡して子スレッドでSPを上書きしている処理がありました。
// int32 clone(int32 flags, void *stk, M *mp, G *gp, void (*fn)(void));
TEXT runtime·clone(SB),NOSPLIT,$0
MOVL flags+0(FP), DI
MOVQ stk+8(FP), SI // ← ココ!
MOVQ $0, DX
MOVQ $0, R10
MOVQ $0, R8
〜中略〜
MOVL $SYS_clone, AX
SYSCALL
// In parent, return.
CMPQ AX, $0
JEQ 3(PC)
MOVL AX, ret+40(FP)
RET
// In child, on new stack.
MOVQ SI, SP // ← ココ!
これを真似して
- 親スレッドであらかじめヒープ領域を確保
- clone(2) に上記領域のhigh側を指定
- 子スレッド誕生後、SPを上記アドレスで上書き
とやったところ、Segmentation faultが解決!!
これで並行処理(マルチスレッド)が見事に動き始めました。
最終的に動いたコード: https://github.com/DQNEO/babygo/commit/1cac6ee29db44f40b030ee4f19dcffee752314b7
まとめ
- clone(2) の CLONE_VMは、親子でスタックメモリも共有してしまうので、子がcallするとスタックトップが書き換えられて親がバグる
- clone(2)で CLONE_VM をセットするときはchild_stackを指定しないと死ぬ。(正直、このケースはOSが拒否してくれればいいのにと思った)
- 「スタック」というとき、SPレジスタとメモリ上のスタック領域という2つのハードウェアを明確に意識する必要がある
- 公式Goの runtimeのコードの細部にもちゃんと意味がある
- アセンブラを作った経験は大変役に立った
- 英語と日本語両方でググるとよい
Discussion