Dockerの公式リファレンスを読む
もっとDockerに詳しくなるために公式リファレンスを読む
目標は
- マルチステージビルドとBuild Kitの違いを理解する
- Dockerのビルド時間を少なくする
- Dockerの生成イメージを小さくする
Get Started
特に真新しいことは書いてなく、コンテナの利点を説明してる。
あと、Dockerはクライアント・サーバーアーキテクチャを使ってるよとの説明。
登場人物
- Docker デーモン
- Docker クライアント
- Docker デスクトップ
- Docker レジストリ
- Docker オブジェクツ
Docker デーモン
サーバーサイドに常駐。Docker API リクエストを受け付け後述するDocker オブジェクツ をkなりする。デーモンは他のデーモンとやり取りを行うこともある。
Docker クライアント
ユーザーがDocker とやりとりをするインターフェースを提供。docker run とかは Docker デーモンにリクエストを送ってる。1つ以上のデーモンとやり取りするよ。
Docker デスクトップ
Docker デーモンとDocker クライアントと Docker Compose と Docker Content Trust と Kubernetes と Credential Helper をバンドルしためっちゃ便利なやつだよ。君たちのPCで開発するときに使ってね。
Docker レジストリ
Docker イメージを保存するよ。Docker Hubが公式が提供するレジストリだよ。docker pull と docker push でイメージの出し入れができるよ。Docker Hub以外にも設定できるよ。
Docker オブジェクツ
イメージ、コンテナ、ネットワーク、ボリューム、プラグインとか。
イメージは、公式イメージをベースにDockerfile内でカスタマイズして使うよ。Dockerfileの行からレイヤーを作るよ。Dockerファイルを変更してリビルドした際は、変更以降のレイヤーのみを作り直すよ。これで、他の仮想化技術と比べて、イメージが軽量になるよ。
コンテナは、イメージの実体化だよ。扱いやすいよ。コンテナに1つ以上のネットワークやストレージをアタッチするよ。もしくはコンテナからイメージを作ることもできるよ。コンテナはよく分離できてるよ。コンテナを消すとデータもきえるよ。
DockerはGo言語で書かれているよ。Dockerはnamespaceという技術を大いに利用しているよ。
Get Docker
省略
Get Started
インストール方法書いてる。
コンテナとはなにか?
コンテナとは、簡潔にいうと、ホストマシンのすべてのプロセスから分離したサンドボックス。この分離はカーネルの名前空間(namespace)とcgroupsを利用している。これはLinuxで長らく提供されている機能。Dockerはこれらの機能をより使いやすくしてる。まとめると、コンテナとは
- 実行可能なイメージの実体。DockerAPIやCLIを使って、作成、停止、移動、削除ができる。
- ローカルマシンでも、仮想化環境でも、クラウドでも走らせることができる。
- ポータブル(どのOS上でも実行可能)。
- コンテナはそれぞれ分離されており、それぞれのソフトウェアやバイナリや設定を実行できる
コンテナをGo言語を使ってスクラッチで作ってみるセッション。面白そう。
コンテナイメージとはなにか?
コンテナを走らせるとき、分離されたファイルシステムを利用する。これらのカスタムファイルシステムはコンテナイメージによって提供される。イメージはコンテナのファイルシステムを内包しているので、アプリケーションを実行するのに必要なすべてのものを持たなければいけない。例えば、設定やスクリプトやバイナリとか。イメージは環境変数やデフォルトで実行されるのコマンドなどのコンテナに対する設定も持つ。
以降は docker コマンドの基本的な使い方が説明されていってる。
基本的にDocker デスクトップ上だとダッシュボードから操作するのが簡単。
PlayWithDocker というブラウザ上でDockerを実際に動かしてみる学習サイトもあるみたい。
コンテナボリュームとはなにか?
コンテナは削除するとデータも一緒に消えてしまう。ボリュームを使えば、特定のコンテナのファイルシステムとホストマシンをつなげることができる。コンテナのあるディレクトリがマウント(つなげること)されれば、そのディレクトリ内の変化はホストマシンにも同時に見られる。コンテナをリスタートしてもデータは消えたりしない。2種類のボリュームが存在する。named volumeとbind mounts。named volumeはDBとかデータを保持したいが、場所はどうでもいいときに使い、bind mountsは実際のアプリケーションコードなど、データを直接いじりたいときに使う。
| Named Volume | Bind Mounts | |
|---|---|---|
| ホストマシンの場所 | Dockerが選ぶ | あなたがコントロールする |
| マウント例 | my-volume:/usr/local/data | /path/to/data:/usr/local/data |
| Populates new volume with container contents | Yes | No |
| ボリュームドライバのサポート | Yes | No |
Populates new volume with container contents ってどういう意味?
マルチコンテナ
各コンテナは1つのことをするべきだよ。例えばアプリケーションコンテナとDBコンテナは分けるべき。理由は、
- DBよりもアプリケーションのほうがスケールする機会がおおい
- コンテナを別にすることで個別にバージョンコントロールが可能
- DBコンテナをローカルではコンテナで、クラウド上ではマネージドで提供されているものを使いたくなるかも。そうなったら、もしコンテナを一緒にすると無駄なリソースを消費してしまうよ。
- 複数のプロセスを走らせるにはプロセスマネージャーを使う必要がある(訳注: 必要はないが、管理上必須)。コンテナの起動と停止に複雑さをもたらす。
コンテナネットワークとはなにか?
コンテナはそれぞれ個別に動くので、同じマシンの他のコンテナが何やってるのかわからない。どうやって他のコンテナと通信したらよいだろう?ネットワーキングを使えば良い。単に以下のルールを覚えておいて。
docker compose
省略
注意だけ言及。
docker-compose downはボリュームは削除しない。ボリュームを含めて削除したいときはdocker-compose down --volumesを利用すること。
イメージ作成のベストプラクティス
docker scanをするとセキュリティスキャンができる。Dockerはsynkという脆弱性スキャンサービスとパートナーだよ。
docker image historyを使うと各レイヤーのサイズとか調べられるよ。--no-truncフラグをつけると、完全な出力を得られるよ。
レイヤーキャッシュのプラクティス。
イメージレイヤー
レイヤーキャッシュ
例えば以下のファイル
# syntax=docker/dockerfile:1
FROM node:12-alpine
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "src/index.js"]
これだと、COPY . .がyarn installより前に記述されているので、アプリケーションのコードが変更されるたびに、yarn installが走る設計になってしまってる。ライブラリに変更がなければyarn installさせたくないよね。どうしようか。yarn installをCOPY . .のあとに記述してしまえばいい。ただこれだとpackage.jsonの内容が書き換わってもyarn installされなくなるので、package.jsonは先にコピーしておく。
-
packaage.jsonを最初にコピーする。
# syntax=docker/dockerfile:1
FROM node:12-alpine
WORKDIR /app
COPY package.json yarn.lock ./
RUN yarn install --production
COPY . .
CMD ["node", "src/index.js"]
-
.dockerignoreファイルを作成し、node_modulesを追加する
2回めのCOPYフェーズでnode_modulesはコピーされてほしくない。でないと、せっかくyarn installしたものがCOPYフェーズで上書きされてしまうからだ。他のnodeに関するDockerのベストプラクティスはここにある。
以上でリファクタリング完了。
マルチステージビルド
最終成果物であるイメージにはビルド時のみに必要な依存ライブラリが含まれていることがあり、イメージサイズを肥大化させてしまう要因になる。これを削減するためにマルチステージビルドという機能が提供されている。
Cloud Native Landscape
これは圧巻。クラウド関連のプロジェクトまとめてる。
各言語のDocker化のチュートリアル
公式サイト関係ないけど、Node.jsのDocker化に関しては以下のUdemyがおすすめ
docker compose のAPI使って aws ecs にデプロイできることを初めて知った。
2020 年 11 月、Docker Compose for Amazon ECS の一般提供を開始しました。開発者はコンテナ化されたマイクロサービスベースのアプリケーションをワークステーションから取り出し、AWS クラウドに直接デプロイすることがさらに簡単になりました。以前紹介したこのブログにあるように、開発者は docker compose up コマンドを実行して既存の Docker Compose ファイルをそのまま Amazon ECS にデプロイできます。Docker Compose for Amazon ECS を活用することで、開発者はアプリケーションをローカルで開発する場合と Amazon ECS で実行する場合で一貫したフレームワークを持つことができます。
どうやらdocker-compose.yml を CloudFormationに変換してるっぽい?
本番に適応させるのは怖いけど、個人開発とかプロトタイプとかだったら便利そう。
Docker CI/CD ベストプラクティス
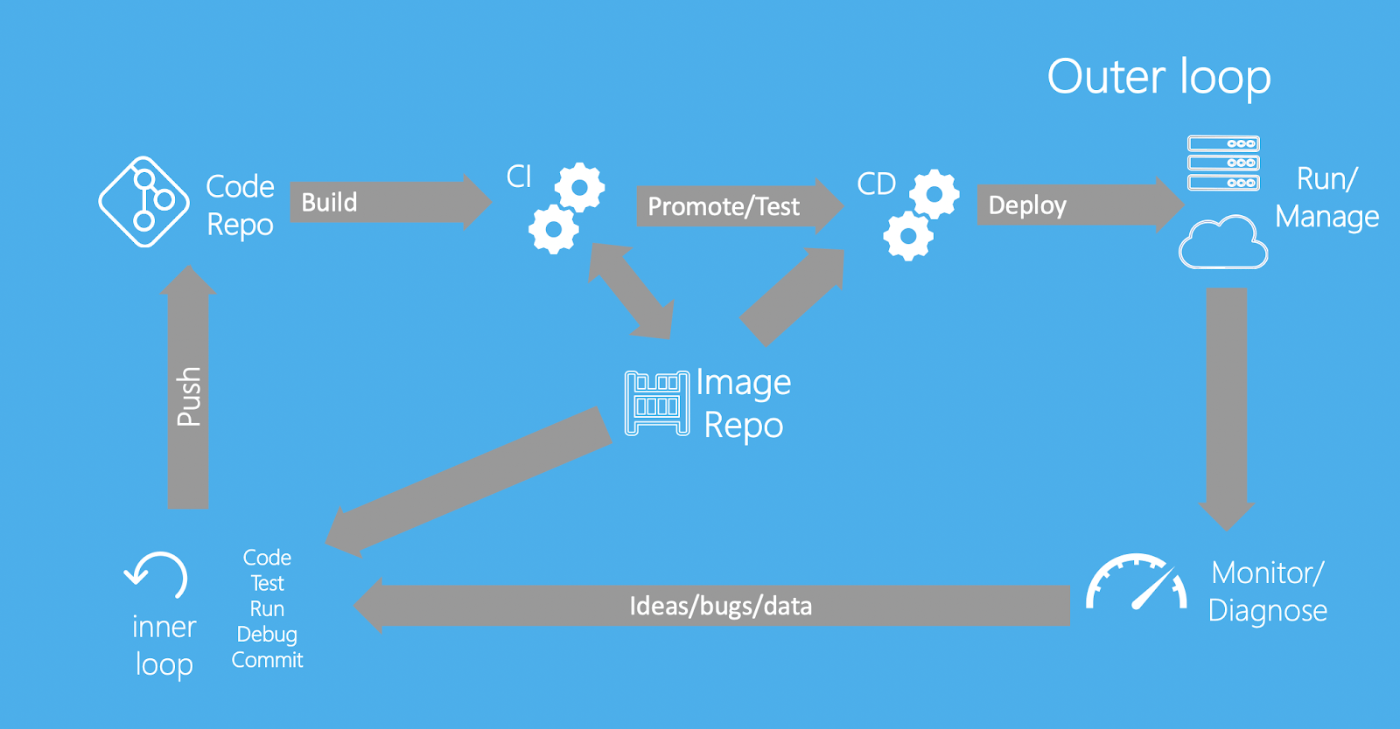
内部ループと外部ループ
内部ループ(ローカル環境でのコーディング、ビルド、実行、テスト)と外部ループ(git push, CI ビルド, CI テスト, デプロイ)を意識する。
CI/CDを最適化する前に、内部ループが外部ループ(つまりCI)にどう関わってくるのかを考えるのが大事。ほとんどのユーザーはCIでデバッグするのを好まず、ローカル環境でデバッグするほうが好ましい。ローカルでのデバッグ時には、マルチステージビルドのtargetを指定してdocker buildすることをお勧めする(訳注: 参考)。こうして、ローカルのマシンで、CI上で実行するのと同じユニットテストを実行できる。
CI/CDの最適化
- セキュリティ向上のため、CIサーバー上では、パスワードではなくアクセストークンを使用する。
- いつCIが走るのか決める。どのファイルが変化したらCIが走るとか。
- ビルド時間の削減のため、build cache を利用する。これはプラットフォームが提供していればbuildx(buildkits)を利用するか、もしくはプラットフォームが提供するキャッシュを利用すれば実現できる。GitHubActionsでのbuild cacheの利用例。
Docker開発ベストプラクティス
頑張ってイメージを小さくする
- Dockerfileには適切なベースイメージを選択する。JDKであれば、ベースを
ubuntuにしてopenjdkをインストールするよりも、openjdkイメージをベースにするほうが好ましい。 - マルチステージビルドを使って、ビルド時のみ必要な依存を最終イメージから除去しよう。
- もし共通点の多いイメージを複数使っているなら、それらをまとめた独自のベースイメージを作成しよう。Dockerは共通レイヤを一度ロードすればキャッシュできるので、ホストマシンのメモリを効率的に使用できるよ。
- 本番イメージを作成するときは、バージョンや目的(testなど)や安定性とか役立つ情報をタグ付けしよう。自動付与される
latestタグへの依存は避けよう。
アプリケーションデータをどこにどう永続化するか
- ストレージドライバを使用して、コンテナの書き込み可能なレイヤにアプリケーションデータを保存することは避けてね。I/Oの観点から効率が悪くなるよ。代わりに2種類のボリュームを使ってね。
- bind mountは、開発中に使ってね。本番環境では name volumeを使ってね。
- 本番環境では機密性の高いデータには
secretという機能を使ってね。機密性の低いデータにはconfigという機能を使ってね。
CI/CDをテストと開発に利用する
内容は上記のCI/CDベストプラクティスをみてね。特記すべきことといえば、開発、テスト、セキュリティチームなどに本番デプロイ前にイメージに対して署名をしてもらう機能もある。
開発環境と本番環境の違い
| 開発環境 | 本番環境 |
|---|---|
| コンテナ内のソースコードにアクセスするためにbind mountsを利用。 | コンテナのデータを保存するためにボリュームを利用 |
| Docker Desktopを利用。 | ホストプロセスからDockerプロセスを分離するためにDocker Engineを利用。 |
| 時間のズレを気にする必要はない。 | NTPクライアント(サーバーの時間あわせるやつ)をDockerのホスト上で実行。コンテナ内のすべてのプロセスの時間を合わせる必要がある。 |
訳注: 本番環境はクラウドを利用することが多いと思う。マネージド・サービスを利用すれば、この違いは意識しなくても良い。
Dockerfileベストプラクティス
省略。知らなかったことだけチョイス
docker buildコマンドは標準入力からのパイプが使用可能
echo -e 'FROM busybox\nRUN echo "hello world"' | docker build -
docker build -<<EOF
FROM busybox
RUN echo "hello world"
EOF
RUNコマンドのインストール系はアルファベティカルに並べると見やすい
RUN apt-get update && apt-get install -y \
bzr \
cvs \
git \
mercurial \
subversion \
&& rm -rf /var/lib/apt/lists/*
キャッシュのルール
イメージが同じかどうかのチェック
- ADDとCOPYはファイルごとのチェックサムの比較
- RUNは単に文字列の比較
BuildKit
あまり詳しく書かれてない。
有効にするには環境変数を設定するか、
$ DOCKER_BUILDKIT=1 docker build .
Dockerデーモンの設定を変更する。
{ "features": { "buildkit": true } }
普通にググったほうが詳しい記事出る
buildkit マルチステージビルドの並列実行とかビルドキャッシュのインポートとか便利そう。
セキュリティ機能は現状、環境変数で渡してるから使わなさそう。
buildxというプラグインを使えば、buildkitの強化された機能が使える。
Docker conの動画
Dockerfileにおける BuildKitのシンタックス