LPFと勾配降下法に関する発見
概要
ノイズのある時系列データからノイズのない真の値を推測しようとするとき,ローパスフィルタ(LPF) はその選択肢の一つです.
センサなどで発生するノイズは高周波成分とみなせるため,LPF を用いることで取り除くことができます.
真の値を推測する別の方法としては,誤差関数を定義して,その誤差を最小化するようにパラメータを更新する方法が挙げられます.
この方法は,機械学習における最適化アルゴリズムとして知られている確率的勾配降下法(SGD) の基本的な考え方です.
この記事では,LPF と SGD の関係について考察し,LPF が SGD の特殊な場合として得られることを確認します.
また,SGD の改良アルゴリズムについても同様に LPF として解釈できるかを検証します.
背景:ローパスフィルタ(LPF)
ローパスフィルタ(Low Pass Filter; LPF)とは,時間によって変化する入力信号から,高周波成分を減衰させるフィルタのことです.
具体的な実装として移動平均法やガウシアンフィルタなどもありますが,ここでは一次遅れ系について詳しく見ていきます.
一次遅れ系とは,伝達関数
ここで,
入力の位相が遅れて出力される系の中で,伝達関数が
フィルタの特性を表す指標として,遮断周波数があります.
遮断周波数とは,フィルタ回路において入力信号のゲインが
Bode 線図では,遮断周波数はゲインが
一次遅れ系の遮断周波数
背景:確率的勾配降下法(SGD)
ある関数
勾配降下法は,そのような最適化問題を解くためのアルゴリズムの一つです.
具体的には,まず初期値
このように更新することで,
機械学習では,
確率的勾配降下法(Stochastic Gradient Descent; SGD)とは,入力データを 1 つずつ取り出してその都度勾配降下法を適用し,パラメータを更新するアルゴリズムです.
入力データをいちどに全て取り出して更新を適用するバッチ勾配降下法と比べて,SGD は計算コストが低く,局所解に陥りにくいという特徴があります.
発見:LPF と SGD の関係
ここで,入力との二乗誤差を損失関数としたときの SGD について考えます.
入力データを
時間変化する入力
さて,ここで
値の変化にかかる時間と対応した微小時間
なんと,伝達関数は
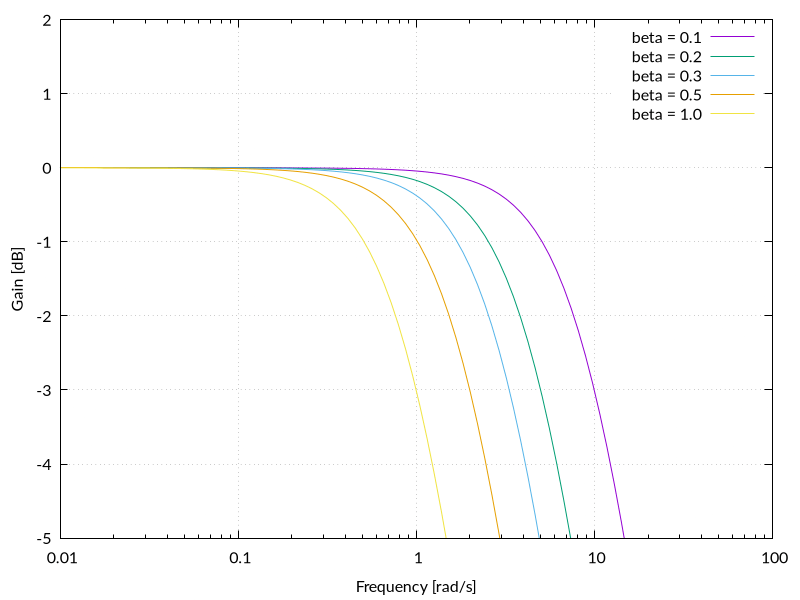
更なる実験
SGD には,様々な改良アルゴリズムが提案されています.
代表的なものとしては以下のようなものがあります:
- Momentum SGD
- Nestelov's Accelerated Gradient (NAG)
- AdaGrad
- RMSProp
- AdaDelta
- Adam
これらのアルゴリズムは,機械学習において,SGD よりも高速に学習できることが知られています.
ここでは,Momentum SGD について,同様に LPF として解釈できるかを検証します.
Momentum SGD
Momentum SGD は,SGD にいわゆる慣性項を加えたアルゴリズムです.
過去の勾配の情報を取り入れることで,高速に学習できることが知られています.
更新式は以下の通りです(
同様に,
まず,第 2 式から
ここで
続いて両式より
Momentum SGD の伝達関数は,二次遅れ系の LPF のものと一致することがわかりました!
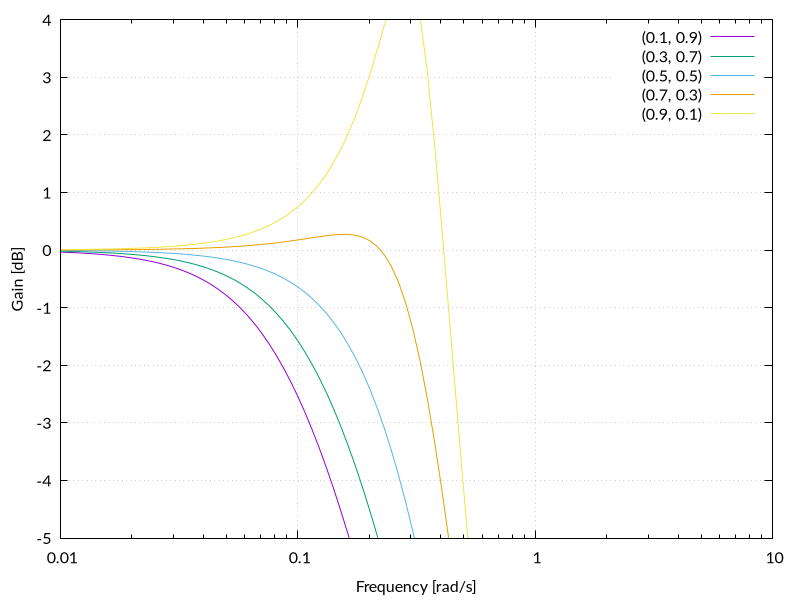
まとめ
目的関数を
また,Momentum SGD についても同様に LPF として解釈できることを確認しました.
他の最適化アルゴリズムの場合はどうなるか気になるところですが,それは今後の課題とします.
-
20 \log_{10} \frac{1}{\sqrt{2}} \approx -3.01\ \mathrm{dB} -3\ \mathrm{dB} -
未知数はふつう
x x y y -
今回はパラメータが 1 次元の場合を考えるが,一般にパラメータが多次元の場合は
\boldsymbol{\theta}_{n + 1} = \boldsymbol{\theta}_n - \eta \nabla f(\boldsymbol{\theta}_n) -
\beta \eta \Delta t \Delta t \eta -
\beta \alpha \Delta t
Discussion