型システムのしくみのメモ
全般的なこと
- パーサーはライブラリを使うのでパーサーやトークンを知らない人はブラックボックス化している
- オブジェクトのフィールドの区切りを
,ではなく;で書いている。(foo: 1; bar: true)。これは本書で行うパーサーと記法を合わせるため。著者がTypeScriptについて詳しくないからという理由ではない。 - 再帰関数を用いる箇所の説明が甘い。たとえば
{foo: {foo1: {foo2: 1}}}のように深い階層まであるオブジェクト型にも対応するためには再帰関数を用いる必要がある。なので至ることろで再帰関数が使われるのだが、本書の具体例では{foo: 1, bar: true}程度のものしかあげていないので、再帰関数が用いられる理由が分かりづらい。よってコードを読む時難しく感じる人がいるだろう。再帰関数は難しい。再帰関数を読み解くコツは無限ループが終了する「ベースケース」を把握すること。本書だとTypeが"Boolean"や"Number"だと再帰関数が呼び出されず、無限ループが止まることが多い。
オブジェクト型の部分付け (p.80)
数学で習う部分集合とは違った。数学ではA={1,2,3}とB={1,3}という2つの集合があった場合、BはAの部分集合といえる。数学ではAがBの部分集合であるとき、Aの要素が全てBに含まれていることを指すからだ。
しかしTypeScriptでは{foo: number}と{foo: number, bar: boolean}の2つのオブジェクト型があった場合、型{foo: number, bar: boolean}は型{foo: number}の部分型とするといっている。つまり集合として、{foo: number}の方がより「大きい」集合だといっている。含むフィールドの数が「多い」型の方がより「小さい」型というのはどうも直感的に分かりづらい
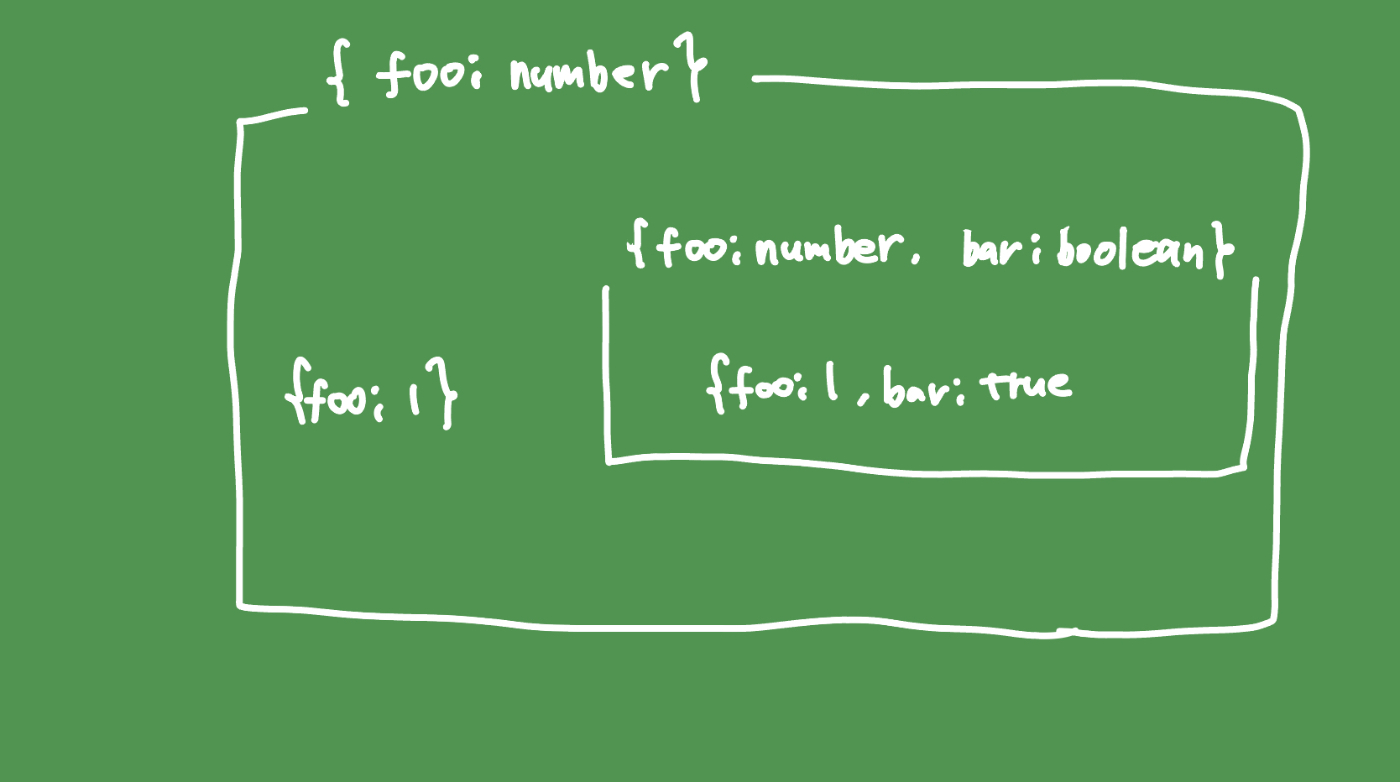
なので型Aが型Bの部分型であるというのを「AはBとしても使える」と考えてみるといいのかもしれない。型{foo: number, bar: boolean}は型{foo: number}の部分型というのは、{foo: number, bar: boolean}からfooだけををとってくれば型{foo: number}が作れる。つまり、。型{foo: number, bar: boolean}は型{foo: number}としても使える、といえる。
ここまで書いて思ったが
- ベン図を使っての理解は筋が悪い
- 部分型というのを使わない方がいい
1つ目に関して、図を書いて分かりやすくならなかったからわざわざ図で書いても仕方がない。2つ目に関して、部分型という概念が分かりづらい。だからAがBの部分型であるというのを、AはBの代わりに使ってもOKであることと言い換えることにする。言い換えると、AがBの部分型でないとき、AはBの代わりに使うのはNGだ。フィールド数の観点で言うと、フィールド数が多い型はフィールド数の少ない型の代わりに使える。このフィールド数というのは注意点があって、単に多ければいいというのではない。フィールド数が多いとは、使いたいフィールドを含み、かつ、余分なフィールドを含むという意味で使っている。つまり大は小を兼ねているというわけだ。
関数型(返り値)の部分型付け
関数の返り値に関して
- 型Aが型Bの部分型なら、型
()=>Aは型()=>Bの部分型としてよい - 型Aのフィールド数が型Bのフィールド数より多いなら、型
()=>Aは型()=>Bの代わりに使える - より広い型を許容
※部分型の定義がA,Bと()=>A,()=>Bを比べるときで違う。だから考える時は部分型というのを使わず、「代わりに使ってOK」と言い換えると分かりやすい。
type F = () => { foo: number };
const f = (x: F) => x().foo; // x.fooではなくx().fooとして、xを一度実行している。
const g = () => ({ foo: 1 }); // {foo:1}のままだとブロックとして解釈される。()で囲むとオブジェクトリテラルと認識される。
f(g); // 1
type F = () => { foo: number };
const f = (x: F) => x().foo;
const h = () => ({ foo: 1, bar: true })
f(h); // 1
関数型(引数)の部分型付け
- 型Aが型Bの部分型なら、型
(x: B) => Cは型(x: A)=>Cの部分型としてよい - より狭い型を許容
引数に余計なフィールドを入れると、使えないフィールドを使う関数がきたときに困る。
わからーん。でも、後者の(x: A)=>Cは具体的な関数で考えると分かりやすいかも。この記事のUserとAdminの例も分かりやすい。フィールドをより多く含むのがはっきりする。
返り値の場合も、引数の場合も、オブジェクト型であることを仮定している。別にbooleanでもnumberでもいいのだが、booleanの部分型はbooleanで、numberの型はnumberだからなんのひねりもないからスルーしている。
関数型(返り値)の部分型の判定
まずは関数型における部分型の判定するコードを抜粋する。
case "Func": {
if (ty1.tag !== "Func") return false;
if (ty1.params.length !== ty2.params.length) return false;
for (let i = 0; i < ty1.params.length; i++) {
if (!subtype(ty2.params[i].type, ty1.params[i].type)) return false;
}
if (!subtype(ty1.retType, ty2.retType)) return false;
return true;
}
返り値についての部分型の判定のコードは1行だ。
if (!subtype(ty1.retType, ty2.retType)) return false;
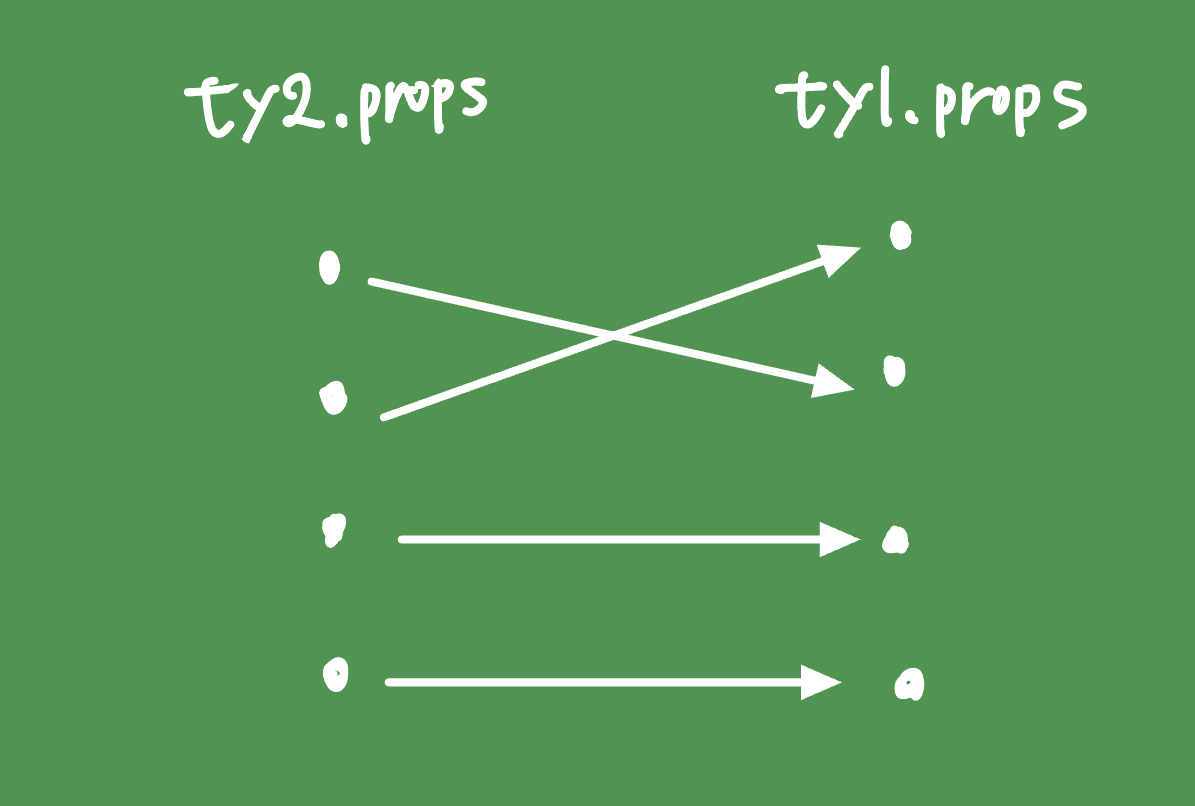
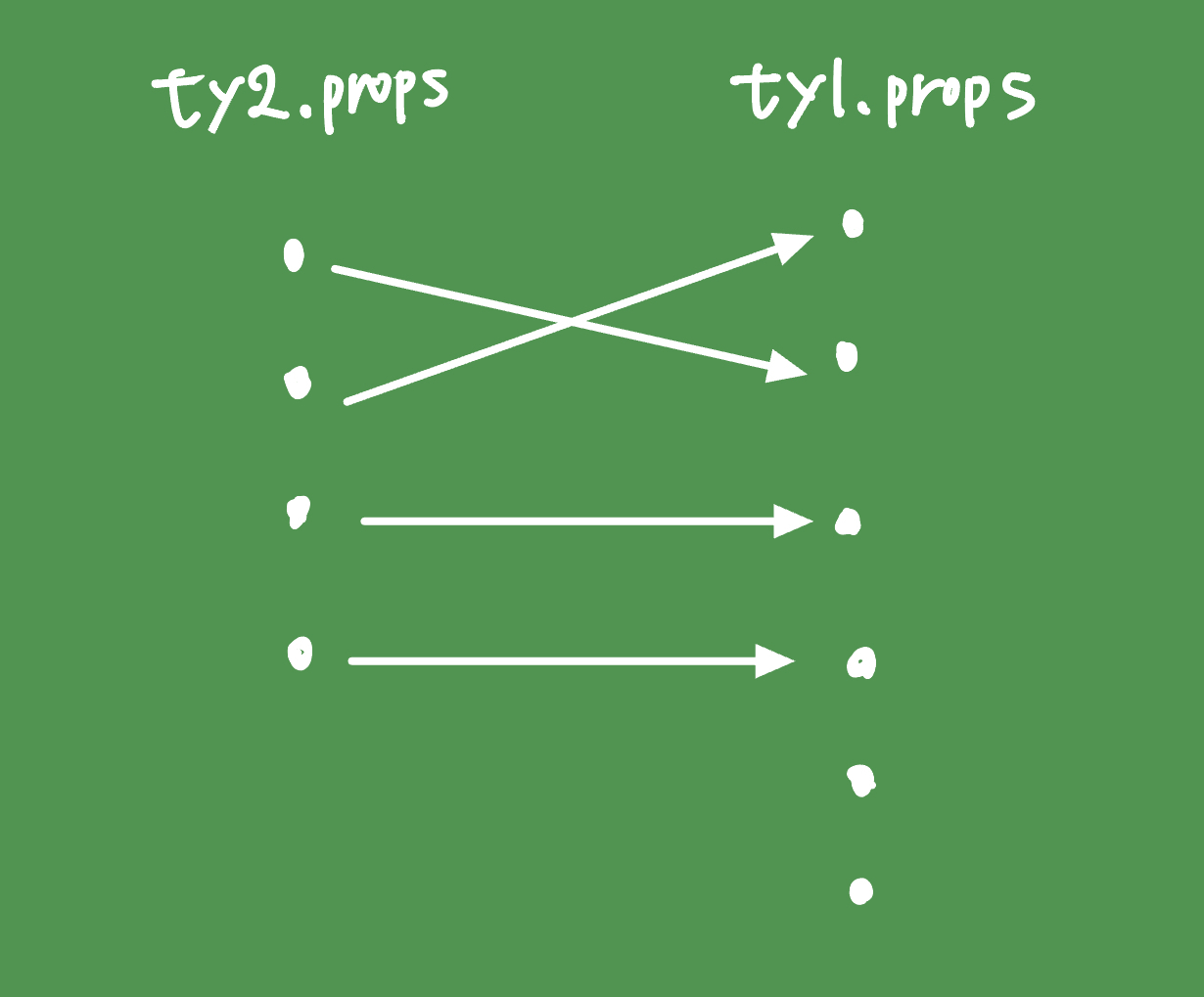
subtype()に渡す引数の順番はty1、ty2の順番になっている。引数の順番にはちゃんと意味があって、引数がオブジェクト型のときこの違いが明確になる。オブジェクトの判定では第二引数のフィールド(ty2.props)にあるものは、第一引数のフィールド(ty1.props)にあることをことを要請している。
つまり画像のような状況だとtrueとなる。順番はどうであれ、第二引数にあるものは全て第一引数にあればtrueということだ。
関数型(引数)の部分型の判定
関数型(引数)の部分型の判定のコードを抜粋する。ty1とty2の引数を一つずつ取り出し、subtype()に入れてチェックしている。ここで問題になるのもやはり引数がオブジェクト型の時だろう。ty2.params[i].typeのように、一度ループにかけているので分かりにくいが、関数の型が(x: boolean, y: { y1: boolean, y2: boolean}) => booleanのように、引数のうち1つにオブジェクト型がある場合をイメージすればいい。
引数の部分型の判定では第一引数にty2を、第二引数にty1を入れている。つまり、引数がオブジェクトだとするとty1.params[i]のフィールドty2.params[i]のフィールド数のときOKと判定される
for (let i = 0; i < ty1.params.length; i++) {
if (!subtype(ty2.params[i].type, ty1.params[i].type)) return false;
}
typeCheck 関数の実装
置き換え対象の型T、置き換えたい型変数Xの名前、型変数の代わりにおく再帰型自体μX.Tの3つが出てくる。それぞれをty、tyVarName、repTyという変数名で書かれる。
expandTypeの実用方法が後の方に説明されているから、前から読んでいて分かりにくい。おそらくパーサーの出力したものをexpandTypeの引数にしているのだろうけど、どんなふうに入れているのだろう。まあ関数なのだから定義の部分だけを読めばある程度は読み解けると信じて読むしかない。
1段しか展開しない?
再帰型μX.Tを(一段)展開する、という補助関数を書く。無限回展開するわけではない。なんで1段しか展開しないんだろうか。
型変数の読み替えを行う型の透過判定
- 型変数の読替を行いながら比較を行うこと。例えば、再帰型
μX. {foo: X}と再帰型μY. {foo: Y}は使われている型変数名が異なるが、明らかに同じ再帰型を表現している。
2.展開前の再帰型と展開後の再帰型を透過と判定すること。typeEq関数は、μX.{foo: X}と{foo: (μX. {foo: X})に対して真を返す必要がある。
1 のサンプルコード
実装のコードはあるけどこのコードを動かしたときのサンプルコードがないので自分で書いて動作確認する必要がある。AIに聞けばサンプルコードを作ってくれる。
const objType: Type = {
tag: "Object",
props: [
{ name: "id", type: { tag: "Number" } },
{ name: "value", type: { tag: "TypeVar", name: "X" } }
]
};
const expanded = expandType(objType, "X", { tag: "Boolean" });
まずはtagが"Object"なのでパラメーターをmapで1つずつ取り出し、expandTypeが再帰的に呼び出される。このときの引数はパラメーターのtypeは取り出して引数に渡し、tyVarNameとrepTyは再利用する。
case "Object": {
const props = ty.props.map(
({ name, type }) => ({ name, type: expandType(type, tyVarName, repTy) }),
);
return { tag: "Object", props }
}
まずは1つ目のフィールドの{ name: "id", type: { tag: "Number" } }がexpandTypeで展開される。tagはNumberなのでそのまま返される。よって1つ目のフィールドを展開した結果は何も変わらず{ name: "id", type: { tag: "Number" } }が返される。
次に2つ目のフィールドの{ name: "value", type: { tag: "TypeVar", name: "X" } }が展開される。tagがTypeVarなので、変数名が比較される。
case "TypeVar": {
return ty.name === tyVarName ? repTy : ty;
}
nameは"X"で、tyVarNameは"X"だ。このtyVarNameは初めの引数に入れたものだった。ty.nameとtyVarNameが一致するので、置き換えたい変数を発見したことになる。よってrepTyが返り値となるので、{ name: "value", type: { tag: "TypeVar", name: "X" } }のtypeフィールドは{ tag: "Boolean" }に置き換えらる。結果、返り値が{ name: "value", type: { tag: "Boolean" } }になる。
フィールドは2つだけなので最終的な返り値は次のようになる。
{
tag: "Object",
props: [
{ name: "id", type: { tag: "Number" } },
{ name: "value", type: { tag: "Boolean" } }
]
}
Type型を返すので、ty.tagが"Object"なら{ tag: "Object"; props: PropertyType[] }を返す。
Discussion