WebアプリSEO対策基本ガイド

導入
本記事の目的
本記事では、個人開発者がWebアプリ開発おいて直面するであろう具体的なSEOの課題と、その解決方法を段階的に解説します。
以下の内容をカバーします:
- 基礎知識: JavaScriptレンダリング、メタデータ、インデックスの仕組み
- 技術実装: SSR、SSG、ハイブリッドアプローチの具体的な実装方法
- 構造化データ: JSON-LD、Schema.orgの実装パターン
- 計測と最適化: Google Search Console、Analytics、継続的改善プロセス
全て自分の経験則故にすぐに実践可能であると思いますが、誰でも導入可能な内容を目指しています。
なぜWebアプリでSEOが重要なのか
WebサイトとWebアプリケーションには、検索エンジンからの見え方に大きな違いがあります。
静的HTMLサイト: 検索ボットはページのコンテンツを即座に理解できる
Webアプリケーション: JavaScriptで動的に内容が変わるため、ボットがコンテンツを正しく認識するために多くの工夫が必要がある
Webアプリが検索流入を獲得できない場合、以下のような問題が起こります
- 見込み客への認知が限定される
- 検索からのトラフィックがほぼゼロに近くなる
- ブランド構築が難しくなる
- マーケティング予算が広告に集中する
第1章 Webアプリ開発におけるSEO基礎知識
1.1 Webアプリとトラディショナルサイトの違い
Webアプリケーションの特徴は、ユーザーのアクションに応じてコンテンツが動的に変化することです。
典型的なWebアプリの特性:
- ユーザーがボタンをクリック → JavaScriptが実行 → ページ内容が更新
- ページ遷移なしにコンテンツが書き換わる
- リアルタイムデータの反映(ダッシュボード、チャットなど)
- ユーザー入力に基づいた動的なUIレンダリング
このアーキテクチャはユーザー体験の向上に大きく貢献しますが、一方で検索エンジンボット(クローラー)にとっては認識が難しくなります。
検索ボットの見え方
【従来のサイト】
HTTP Request → HTML Response (コンテンツ完全) → インデックス
【Webアプリ】
HTTP Request → 初期HTML (スケルトンのみ)
↓
JavaScriptの解析・実行 (時間遅延)
↓
動的DOMの生成 → インデックス (または、失敗)
重要な課題:
- 検索ボットがWebアプリにアクセスしたとき、初期状態のHTMLのみを見ることがある
- JavaScriptの実行後に表示されるコンテンツは、従来の方法では検索インデックスに含まれないリスクがある
この部分が、Webアプリ特有のSEO課題となる
実際の影響例
シングルページアプリケーション(SPA)で構築されたブログサービスの場合:
// 初期HTML(クローラーが最初に見るもの)
<html>
<head><title>ブログ</title></head>
<body>
<div id="app"></div>
<script src="app.js"></script>
</body>
</html>
// JavaScript実行後(ユーザーが見るもの)
<html>
<head><title>最新ブログ記事タイトル</title></head>
<body>
<h1>最新ブログ記事タイトル</h1>
<article>記事内容...</article>
</body>
</html>
初期HTMLには記事タイトルや内容がないため、クローラーがJavaScriptを実行しなければ、この記事は検索インデックスに登録されません。
クローラーに対して動的なサイトを認識させることができると検索の上位に表示される可能性がある等の恩恵があります。この部分をSEO対策と呼びます。
(厳密にすると、色んな要因の基、検索上位に表示されるため一概にSEO対策をしたからといって必ず検索上位に表示されるわけではありません。本記事ではそこを無視してSEO対策に着目して記していきます)
1.2 メタデータとメタタグの役割
具体的なSEO対策について話していきます。最初はメタデータについてです。メタタグ<title>をWebアプリ内部に配置することでクローラーに対して情報を提示していきます。
<title> タグと meta description は、検索結果ページに表示される重要な情報です。
検索結果での表示例:
【タイトル】
Webアプリ開発のためのSEO対策完全ガイド | TechBlog
【説明(Description)】
JavaScriptレンダリング、SSR、構造化データなど、Webアプリ特有のSEO対策を
詳しく解説。実装例やチェックリスト付き。
これらのメタデータは、ユーザーがあなたのWebアプリページをクリックするかどうかを判断する大きな要因となります。
下記が主なメタタグの種類と役割です重要度が他界中に上から並んでいます。特に title/meta description/meta robots については必ず設定しておいた方が良いものになります。

Webアプリでは、ページ遷移後にこれらのメタデータが動的に変更される必要があります。実装方法は多様にありますが一例として以下に実装パターンを掲示します。
実装パターン:
// React例:ページ変更時にメタデータを更新
import { useEffect } from 'react';
function BlogPost({ postId }) {
useEffect(() => {
// API呼び出しで記事データを取得
const post = fetchPost(postId);
// メタタグを動的に更新
document.title = post.title;
document.querySelector('meta[name="description"]')
.setAttribute('content', post.excerpt);
document.querySelector('meta[property="og:title"]')
.setAttribute('content', post.title);
document.querySelector('meta[property="og:image"]')
.setAttribute('content', post.imageUrl);
}, [postId]);
return <article>{post.content}</article>;
}
Meta Descriptionの最適化:
また、一例としてMeta Descriptionの最適化について記載していきます。
- ページの内容を簡潔に要約(120-160文字)
- ユーザーがクリックしたくなるような表現
- キーワードの過度な詰め込みを避ける
- 実際のページ内容と一致
<!-- ❌ 悪い例 -->
<meta name="description" content="このページについてです">
<!-- ✅ 良い例 -->
<meta name="description" content="Webアプリ特有のSEO課題を解決するための実装ガイド。SSR、SSG、構造化データなど、段階的な対策を解説。">
CTR向上への効果:
適切なメタデータを設定することで、検索ユーザーへの訴求力が高まり、結果としてクリック率(CTR)の向上につながります。
CTR(クリック率)とは、検索結果に表示されたあなたのサイトが、どれだけクリックされたかを示す割合のことです。
1.3 キャノニカルURL(Canonical URL)
複数のURLが同じコンテンツを提供する場合、検索エンジンは重複コンテンツとして扱う可能性があります。 そのため重複を回避する処理を加えておく必要があります。
重複が発生するシナリオ:
- https://example.com/article/123
- https://example.com/article/123?utm_source=twitter
- https://example.com/article/123?sort=newest
- http://example.com/article/123 (HTTPS vs HTTP)
- https://www.example.com/article/123 (www の有無)
- https://example.com/article/123#comments (アンカーリンク)
これらのURLは同じコンテンツですが、検索エンジンからは異なるページと見なされます。
Canonicalタグの役割
<link rel="canonical" href="https://example.com/article/123">
このタグを使用して、どのURLが正規版であるかを指定します。
Webアプリでは、パラメータ付きURLや複数のアクセス経路が存在することが多いため、canonicalタグの正確な設定が特に重要です。
実装例:Canonical設定
// pages/blog/[id].js
import Head from 'next/head';
export default function BlogPost({ post }) {
const canonicalUrl = `https://example.com/blog/${post.id}`;
return (
<>
<Head>
<link rel="canonical" href={canonicalUrl} />
<title>{post.title}</title>
</Head>
<article>{post.content}</article>
</>
);
}
以上が、比較的実装しやすく効果が高いSEO対策になります。次章からより技術的なアプローチについて話していきます。
第2章 SEO実装の技術的アプローチ
最初にサーバーサイドの技術について簡単に触れます。既に知識がある方は 2.4まで読み飛ばしていただいても大丈夫です。
2.1 サーバーサイドレンダリング(SSR)
サーバーサイドレンダリング(SSR)は、サーバー上でJavaScriptを実行し、HTML形式で完成したコンテンツをクライアントに送信する方法です。
【クライアントサイドレンダリング(CSR)】
- ブラウザが初期HTML受け取り
- JavaScriptをダウンロード・実行
- DOMが生成される
- ユーザーがコンテンツを見る
【サーバーサイドレンダリング(SSR)】
- サーバーがJavaScript実行
- 完成したHTMLを返す
- ブラウザが受け取ったHTMLを表示
- ユーザーがすぐにコンテンツを見る
SSRのメリット
- SEO性能: クローラーが受け取るのは、すでにレンダリング済みのHTMLなため、JavaScriptの実行を待つ必要がない
- 初期表示速度: First Contentful Paint(FCP)が改善される
SSRのデメリット
- サーバーリソース消費: クライアントサイドより多くのサーバーリソースが必要
- 応答時間の増加: サーバーでレンダリングするため、API呼び出しの遅延がユーザーに直結
- 開発難度の上昇: データフェッチング、エラーハンドリングが複雑になる
2.2 静的生成(SSG / プリレンダリング)
静的サイト生成(SSG / プリレンダリング)は、ビルド時にHTMLを事前に生成する方法です。
【Build時】
- すべてのページを列挙
- サーバーでJavaScript実行
- 完成したHTMLファイルを生成
- ファイルをCDNにデプロイ
【ユーザーアクセス時】
- CDNから静的HTMLを配信
- ユーザーがすぐにコンテンツを見る
SSGが最適な場合
- ✅ ブログ記事、ドキュメント(更新頻度: 日単位以下)
- ✅ 商品カタログ(更新頻度: 日単位以下)
- ✅ ランディングページ
- ✅ 規模が大きくなく、ページ数が限定的
- ✅ リアルタイム性が不要
SSGが向かない場合
- ❌ ユーザー固有のデータ(ダッシュボード、マイページ)
- ❌ リアルタイムデータ(ライブストリーム、チャット)
- ❌ ページ数が非常に多い(1000+ページ)
- ❌ 更新頻度が高い(秒単位、分単位)
SSGのメリット
- 最高のパフォーマンス: CDNから配信するため、応答時間が最小
- サーバーリソース不要: ホスティングコストが低い
- SEO最適: すべてのコンテンツが静的HTMLで提供される
- スケーラビリティ: CDNの分散ネットワークで無限スケール可能
SSGのデメリット
- ビルド時間: ページ数が多いとビルドに時間がかかる
- リアルタイム性がない: 更新から反映までに時間差
- 動的コンテンツに対応不可: ユーザー固有のデータは別途対応
SSG実装例:
// pages/blog/[slug].js
// ビルド時にどのパスを静的生成するか指定
export async function getStaticPaths() {
const posts = await fetch('https://api.example.com/posts').then(r => r.json());
return {
paths: posts.map(post => ({
params: { slug: post.slug }
})),
fallback: 'blocking' // 新規投稿は初回アクセス時に生成
};
}
// ページのプロップを取得
export async function getStaticProps({ params }) {
const post = await fetch(`https://api.example.com/posts/${params.slug}`)
.then(r => r.json());
return {
props: { post },
revalidate: 3600 // 1時間ごとに再生成(ISR)
};
}
export default function BlogPost({ post }) {
return (
<>
<Head>
<title>{post.title}</title>
<meta name="description" content={post.excerpt} />
</Head>
<article>
<h1>{post.title}</h1>
<p>{post.content}</p>
</article>
</>
);
}
2.3 ハイブリッドアプローチ(SSR and SSG)
すべてのページをSSRやSSGにする必要はありません。ページの性質によって最適なレンダリング方式を選択することが実用的です。
【推奨構成】
SEO重要度 ★★★
- SSG または SSR
- ブログ記事
- ランディングページ
- 商品詳細ページ
SEO重要度 ★★
- SSR
- リスト表示ページ(複数フィルター)
- 動的なメタデータが必要なページ
SEO重要度 ★
- CSR
- ダッシュボード
- マイページ
- 管理画面
ハイブリッド構成のメリット
- 重要なページのSEO性能を確保
- 開発効率とのバランスが取れる
Next.jsでのハイブリッド実装
// pages/articles/[id].js
// SSG: 記事詳細ページは静的生成
export async function getStaticPaths() {
const articles = await fetchAllArticles();
return {
paths: articles.map(a => ({ params: { id: a.id } })),
fallback: 'blocking'
};
}
export async function getStaticProps({ params }) {
const article = await fetchArticle(params.id);
return { props: { article }, revalidate: 86400 };
}
export default function ArticlePage({ article }) {
return <Article {...article} />;
}
// pages/search.js
// CSR: 検索結果ページはクライアント側で動的に生成
import { useState, useEffect } from 'react';
export default function SearchPage() {
const [results, setResults] = useState([]);
const [query, setQuery] = useState('');
useEffect(() => {
if (query) {
fetch(`/api/search?q=${query}`)
.then(r => r.json())
.then(setResults);
}
}, [query]);
return (
<>
<Head>
<title>検索: {query}</title>
<meta name="robots" content="noindex" /> {/* 検索結果ページはインデックスしない */}
</Head>
<SearchBox value={query} onChange={setQuery} />
<Results items={results} />
</>
);
}
2.4 robots.txt とSitemap
robots.txt はWebサイトのルートディレクトリに配置するテキストファイルで、検索エンジンのクローラーにどのページをクロール(訪問)してよいか、どのページを避けるべきかを指示します。
robots.txtでできること:
- 特定のディレクトリやファイルへのクロール制限
- クローラーの訪問頻度の指定
- Sitemap の場所を指定
- ページのインデックス登録制御(補助的な役割)
注意: robots.txt はインデックス登録を制御しません。ページをインデックスさせないようにするには、meta robots="noindex" タグを使用する必要があります。
robots.txt の基本構文
# すべてのボットに対する指示
User-agent: *
Disallow: /admin/
Disallow: /private/
Allow: /public/
# Googleボットに対する指示
User-agent: Googlebot
Crawl-delay: 2
Request-rate: 30/1m
# Sitemap の場所
Sitemap: https://example.com/sitemap.xml
一般的な設定例:
# SEO重要ページへのアクセスは許可
User-agent: *
Allow: /blog/
Allow: /products/
# 内部用ページへのアクセスを制限
Disallow: /admin/
Disallow: /api/
Disallow: /internal/
Disallow: /*.json$
Disallow: /*.pdf$
# Sitemap を指定
Sitemap: https://example.com/sitemap.xml
Sitemap: https://example.com/sitemap_products.xml
シングルページアプリケーション(SPA)での注意:
# ❌ SPA全体をDisallowするのは避ける
User-agent: *
Disallow: /
# ✅ 不要なパスのみ制限する
User-agent: *
Disallow: /api/
Disallow: /admin/
Allow: /
SPA ではルーティングがクライアント側で行われるため、/ 直下のパスのみ許可し、API エンドポイントなどの内部パスを制限するアプローチが有効です。
参考情報:
私の場合appフォルダ配下に配置することが多いです
(Next.jsのApp Routerでは、TypeScriptファイルを使ってrobots.tsから自動的にrobots.txtを生成します。)
2.7 Sitemap(サイトマップ)
Sitemap(XML サイトマップ)は、Webサイトのすべてのページ(またはクロールしてほしいページ)をリストアップしたXMLファイルです。
Sitemap でできること:
- クローラーがサイト構造を素早く理解
- すべてのページをインデックス候補として認識
- ページの更新頻度や優先度を指定
- モバイル版、動画、画像など、特別なコンテンツを指定
Sitemap の基本構造
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://example.com/</loc>
<lastmod>2024-01-20T10:00:00Z</lastmod>
<changefreq>weekly</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>https://example.com/blog/article-1</loc>
<lastmod>2024-01-15T09:30:00Z</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
Next.js での Sitemap 生成例:
// pages/sitemap.xml.js
// 訪問時にSitemap を動的に生成
export async function getServerSideProps({ res }) {
const baseUrl = 'https://example.com';
// APIからページ一覧を取得
const pages = await fetch('https://api.example.com/pages')
.then(r => r.json());
const sitemap = `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>${baseUrl}</loc>
<priority>1.0</priority>
</url>
${pages.map(page => `
<url>
<loc>${baseUrl}/blog/${page.slug}</loc>
<lastmod>${page.updatedAt}</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
`).join('')}
</urlset>
`;
res.setHeader('Content-Type', 'text/xml');
res.write(sitemap);
res.end();
return {
props: {}
};
}
export default function Sitemap() {
return null;
}
大規模サイトでのSitemap 分割
ページ数が50,000を超える場合は、Sitemap を複数ファイルに分割し、Sitemap Index で管理します。
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://example.com/sitemap_blogs.xml</loc>
<lastmod>2024-01-20T10:00:00Z</lastmod>
</sitemap>
<sitemap>
<loc>https://example.com/sitemap_products.xml</loc>
<lastmod>2024-01-20T10:00:00Z</lastmod>
</sitemap>
<sitemap>
<loc>https://example.com/sitemap_pages.xml</loc>
<lastmod>2024-01-20T10:00:00Z</lastmod>
</sitemap>
</sitemapindex>
画像・動画を含む Sitemap
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:image="http://www.google.com/schemas/sitemap-image/1.1"
xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
<url>
<loc>https://example.com/products/item-1</loc>
<!-- 画像情報 -->
<image:image>
<image:loc>https://example.com/images/product1.jpg</image:loc>
<image:title>商品1の画像</image:title>
</image:image>
<!-- 動画情報 -->
<video:video>
<video:content_loc>https://example.com/videos/product1.mp4</video:content_loc>
<video:player_loc>https://example.com/player?v=product1</video:player_loc>
<video:thumbnail_loc>https://example.com/thumbnails/product1.jpg</video:thumbnail_loc>
<video:title>商品1の説明動画</video:title>
<video:description>商品1について詳しく説明します</video:description>
<video:duration>120</video:duration>
</video:video>
</url>
</urlset>
Sitemap の登録と管理
2.8 Google Search Console
Google Search Consoleは、Google検索におけるウェブサイトのパフォーマンスを監視、管理、改善するためのツールです。SEO対策を行う上で非常に重要な役割を果たします。
ここでの目標は
- 所有者証明をする
- sitemap.xml の存在をGoogle Search Consoleに知らせる
の2点です。
所有者証明
Google Search Consoleではまず最初にWebアプリの所有者であることを証明する必要あがります。ワークフローは以下です。
- Google Search Console にアクセス
↓ - プロパティタイプを選択
- URL プレフィックス
- ドメイン
↓
- 所有権を確認
- HTMLファイルをアップロード
- DNSレコードを追加
- HTMLタグを追加
- Google Analyticsで確認
- Google タグマネージャーで確認
↓
- 所有権が確認される
↓ - Sitemap を登録
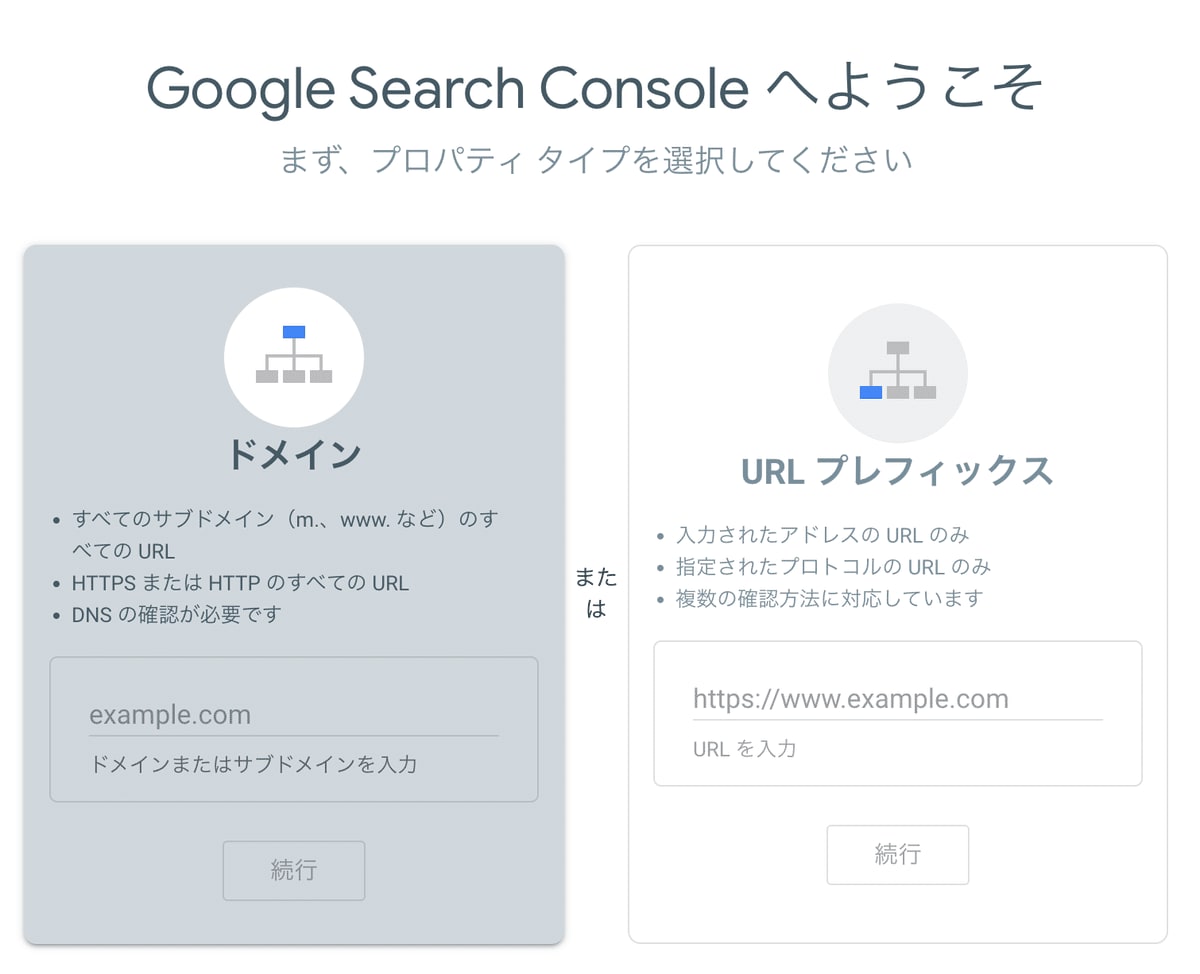
最初にドメイン名かURLを入力すると所有者確認方法が提示されます。
比較的簡単な方法が「HTMLファイルのアップロード」です。
これは、Google Search Consoleから秘密のHTMLファイルをダウンロードし自分のWebアプリにアップロードすることで所有者であることを証明する方式です。
- Google Search Console でHTMLファイルをダウンロード
└─ google○○○○○○○.html という名前 - ファイルをWebサイトのルートディレクトリに配置
└─ https://example.com/google○○○○○○○.html でアクセス可能 - Google Search Console で「確認」をクリック
- 確認完了後、ファイルは削除可能
確認完了後、Google Search Console では「所有権が確認済み」と表示されます。
Sitemapの登録
Sitemap の効果を最大化するには、Google Search Console に登録する必要があります。
登録手順:
- Google Search Console にアクセス
- 開発したWebアプリのドメイン or URLを入力
- プロパティを選択
- 左メニュー「Sitemap」を選択
- 「新しいサイトマップの追加」をクリック
- Sitemap のURL を入力(例:https://example.com/sitemap.xml)
- 「送信」をクリック
良い方法:
- ✅ Sitemap ファイルサイズは 52MB 以下に保つ
- ✅ 複数の Sitemap を作成する場合、Sitemap Index を使用
- ✅ 不要なページ(ログインページ、404ページ)は含めない
- ✅ ページ削除時は Sitemap から削除
- ✅ 更新頻度(changefreq)は実際の更新状況に合わせる
- ✅ 優先度(priority)は相対的な値なので、すべて 1.0 にしない
第3章 構造化データとサイテーション
3.1 構造化データの概要
構造化データとは、検索エンジンがページのコンテンツをより正確に理解するためのメタデータです。
【構造化データなし】
検索エンジンが解釈:「このページには"iPhone 15"という単語があります」
→ 具体的な情報(価格、在庫、レビュー)は理解できない
【構造化データあり】
検索エンジンが解釈:「このページは商品ページで、商品名は"iPhone 15"、
価格は$999、在庫あり、評価は4.5つ星です」
→ 詳細情報を正確に理解
構造化データを適切に実装することで、検索結果でリッチスニペット(拡張結果)として表示され、ユーザーのクリック率が向上します。
【通常の検索結果】
商品A | 説明文...
【リッチスニペット】
⭐⭐⭐⭐⭐ (4.5) 商品A
説明文...
💰 $99.99 [在庫あり]
リッチスニペット表示による効果:
まずリッチスニペットがどういうものかをが下の画像です。
検索結果に構造的に機能が表示されるのでユーザーからのクリック率が高くなります。
この他にもレビュー数を表示したり画像を表示したり等の例があります。
注意: 但し、リッチスニペットは「検索上位」であったり「Googleから品質が高いWebアプリ」であると認定を受けていることが条件になります。そのため開発初期は劣後しても良いと思います。
3.2 JSON-LD実装
JSON-LDはJSON形式で構造化データを記述し、HTMLの<script>タグ内に埋め込む方法です。
JSON-LDの利点:
- ✅ 最もシンプル(HTMLと分離)
- ✅ JavaScriptとの親和性が高い
- ✅ Webアプリ開発者に推奨
- ✅ 動的なデータ生成が容易
- ✅ GoogleやBingなど、主要検索エンジンが推奨
JSON-LDの基本構文
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Webアプリ開発のためのSEO対策完全ガイド",
"description": "JavaScriptレンダリング、SSRなどを詳しく解説...",
"image": "https://example.com/image.jpg",
"author": {
"@type": "Person",
"name": "Taro Yamada"
},
"datePublished": "2024-01-15",
"dateModified": "2024-01-20"
}
</script>
Webアプリでの動的JSON-LD生成
Webアプリでは、ページコンポーネントのレンダリング時に、動的にJSON-LDスクリプトを生成・注入することで、各ページに対応した構造化データを提供できます。
// components/JSONLDScript.js
export default function JSONLDScript({ data }) {
return (
<script
type="application/ld+json"
dangerouslySetInnerHTML={{ __html: JSON.stringify(data) }}
/>
);
}
// pages/products/[id].js
import JSONLDScript from '../../components/JSONLDScript';
export default function ProductPage({ product }) {
const productSchema = {
"@context": "https://schema.org",
"@type": "Product",
"name": product.name,
"description": product.description,
"image": product.imageUrl,
"brand": {
"@type": "Brand",
"name": product.brand
},
"offers": {
"@type": "Offer",
"url": `https://example.com/products/${product.id}`,
"priceCurrency": "JPY",
"price": product.price,
"availability": "https://schema.org/InStock"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": product.rating,
"reviewCount": product.reviewCount
}
};
return (
<>
<JSONLDScript data={productSchema} />
<h1>{product.name}</h1>
{/* 商品情報の表示 */}
</>
);
}
3.3 schema.orgスキーマの選択
schema.orgプロジェクトは、検索エンジンやその他のアプリケーションが相互に理解できるスキーマを定義しています。
| スキーマ | 用途 | リッチスニペット |
|---|---|---|
| Article | ブログ記事、ニュース | 記事のメタデータ、著者 |
| BlogPosting | ブログ投稿 | 日付、著者、イメージ |
| Product | 商品 | 価格、在庫、レビュー |
| Event | イベント | 日時、場所、チケット |
| Organization | 組織、企業 | ロゴ、連絡先 |
| Person | 人物 | 名前、職業 |
| Review | レビュー | 評価、テキスト |
| Recipe | レシピ | 材料、調理時間、評価 |
| LocalBusiness | 地元企業 | 営業時間、住所 |
| VideoObject | 動画 | サムネイル、期間 |
選択時のポイント
自分のコンテンツタイプに合わせて、適切なスキーマを選択し、必須フィールドと推奨フィールドを埋めることが重要です。
記事ページの例:
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"headline": "タイトル",
"description": "説明",
"image": ["https://example.com/image.jpg"],
"datePublished": "2024-01-15T10:00:00Z",
"dateModified": "2024-01-20T15:00:00Z",
"author": {
"@type": "Person",
"name": "著者名"
}
}
商品ページの例:
{
"@context": "https://schema.org",
"@type": "Product",
"name": "商品名",
"description": "商品説明",
"image": "https://example.com/product.jpg",
"brand": {
"@type": "Brand",
"name": "ブランド名"
},
"offers": {
"@type": "Offer",
"priceCurrency": "JPY",
"price": "99.99",
"availability": "https://schema.org/InStock"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.5",
"reviewCount": "100"
}
}
3.4 検証とテスト
実装した構造化データが正しいか検証することが重要です。
Google Rich Results Test での検証
- https://search.google.com/test/rich-results にアクセス
- ページURL またはHTML を入力
- 「テスト」をクリック
- エラーや警告を確認
よくあるエラー:
-
❌ エラー: 必須フィールド "image" が見つかりません
- 解決策: 画像URL を JSON-LD に追加
-
❌ エラー: "priceCurrency" が無効です
- 解決策: 通常3文字の通貨コード(例: JPY)を指定
-
❌ 警告: 推奨フィールド "datePublished" が見つかりません
- 解決策: 公開日を指定(リッチスニペット表示に影響)
検証結果例:
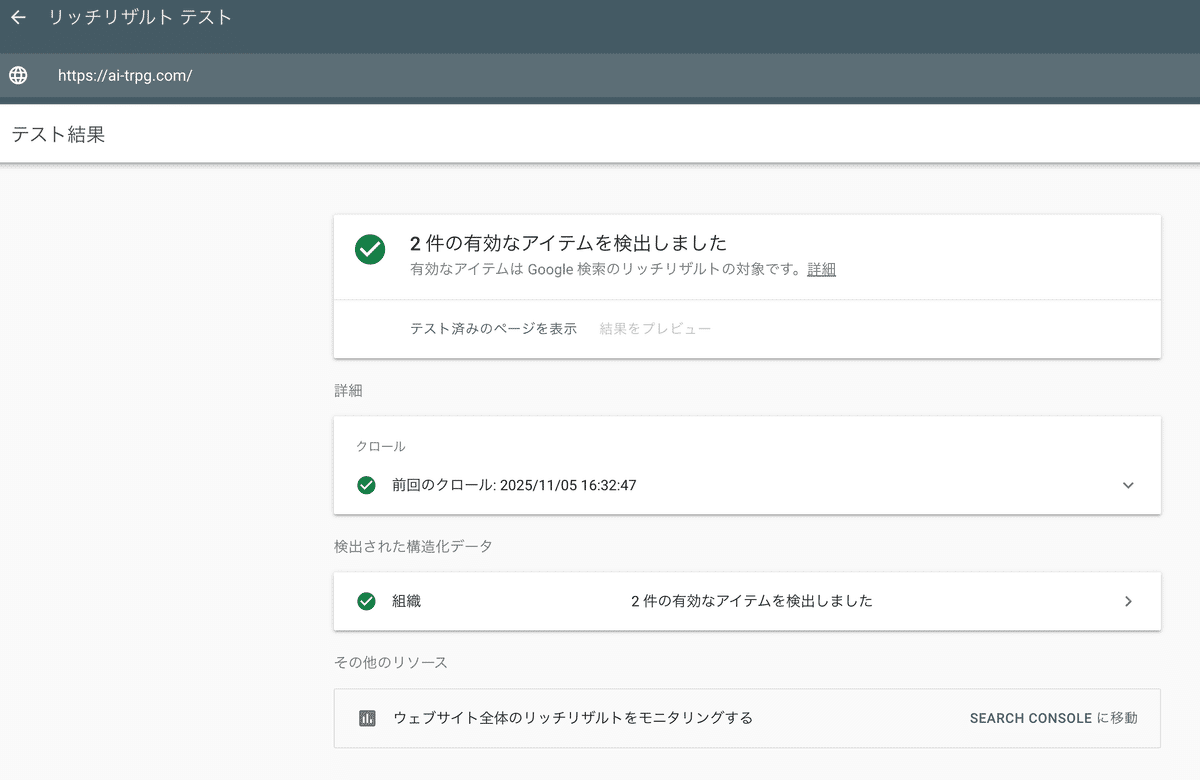
第4章 計測と継続的な最適化
4.1 Google Search Console の活用
できること:
- Googleがあなたのサイトをどのように認識しているか確認
- クロールエラーを検出
- インデックス登録状態を把握
- 検索パフォーマンス(表示回数、クリック数など)を分析
1. カバレッジレポート
- 有効: インデックスされたページ
- エラー: クロール・インデックスに失敗したページ
- 除外: noindex指定やパラメータ付きURLなど
Webアプリの場合、JavaScriptレンダリングエラーが報告されないか、定期的に確認することが重要です。
2. パフォーマンスレポート
- 表示回数(Impressions): 検索結果に表示された回数
- クリック数(Clicks): ユーザーがクリックした回数
- 平均掲載順位(Average Position): 平均的な検索順位
- クリック率(CTR): 表示回数に対するクリック数の割合
改善の指標:
- 掲載順位が11位以上 → テクニカルSEOの問題
- 掲載順位が5-10位だがCTR低い → タイトル・説明の改善
- CTR高いが順位低い → コンテンツ充実化が必要
3. 検査ツール
URL検査 → 特定のページの:
- インデックス登録状態
- JavaScriptレンダリング状況
- 採用されたメタデータ
- エラーの詳細
4.2 コアウェブバイタルと Page Speed
コアウェブバイタル(Core Web Vitals)
Googleはページ体験をランキング要因の一つとしており、以下3つの指標を重視しています:
1つ目: LCP(Largest Contentful Paint)
0秒 ────── 2.5秒 ────── 4.0秒
✅ 良好 ⚠️ 要改善 ❌ 不良
最大コンテンツ(画像、テキスト)が表示されるまでの時間
改善方法:
- 画像の最適化(WebP形式、遅延ロード)
- JavaScriptの分割・遅延ロード
- CSSの削減
- サーバーのレスポンス時間改善
2つ目: FID(First Input Delay)
0ms ────── 100ms ────── 300ms
✅ 良好 ⚠️ 要改善 ❌ 不良
ユーザーがクリック・入力してから反応するまでの時間
改善方法:
- JavaScriptの実行時間短縮
- Web Workersの活用
- 長いタスクの分割
3つ目: CLS(Cumulative Layout Shift)
0 ────── 0.1秒 ────── 0.25秒
✅ 良好 ⚠️ 要改善 ❌ 不良
予期しないレイアウト変化の度合い
改善方法:
- 画像・広告に明確な領域指定(width, height)
- フォント読み込み中の代替フォント指定
- 動的コンテンツ挿入時のスペース確保
まとめ
Webアプリの開発とSEO対策は、個人開発者にとって必要不可欠なものです。特に、初期ユーザーをより呼び込むために必要な工程になります。
Google Analyticsやその他ツールなどについても記載したかったのですがページの都合上省略しました。また別の機会に記事にしようと思います。
Discussion