Streamの視聴者をExcelにまとめよう、と思ったけどめんどくさいからAIにやらせてみた
Streamの視聴者をExcelにまとめよう、と思ったけどめんどくさいからAIにやらせてみた
注意
題名のStreamとはMicroSoft Streamを指しています。
あくまで備忘録のようなものなので環境によってはできない可能性があります。
動機
社内で技術発表会が行われたときに、SharepointのStreamで録画を保存しました。
運営サイドだった私は、録画視聴者名と録画視聴者人数を取らなくちゃいけません。
いざ、視聴者人数を確認すると、おおすぎっ!ってなって、どうにか手間かけずに集計するためAIを使おうとなりました。
準備
なんとな~く、PythonでExcelを操作しようかなと考えていたので、
まずはアウトプットのエクセルを作ります。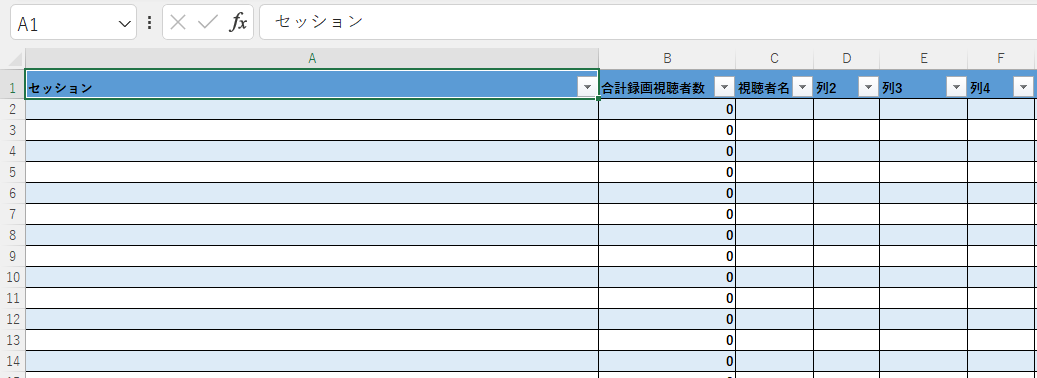
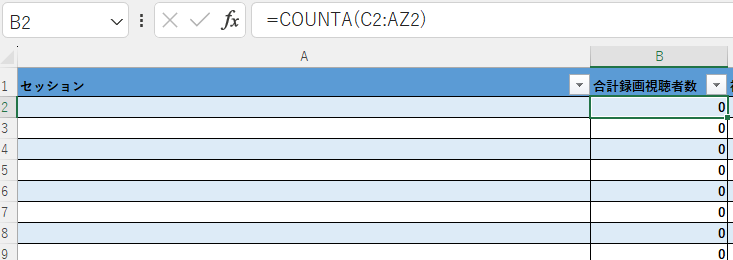
あとはB列に関数を作る。
次に、インプットの録画視聴者がまとめられているjsonファイルを取得します。
Streamを開きます。
F12から管理者ツールを開きます。
ネットワークタブを選択します。
streamに戻り、分析を選択します。
また、管理者ツールに戻り、名前から[alltime?$expand~~]で始まる項目を選択します。
レスポンスタブを選択します。

json形式で書いてあるので、マルっとコピぺします。
これを複数のStreamで行うので、ローカルで「json_folder」を作成してその中に保存していきます。
中身は(見せられないものの削除や修正を行っていますが)下記です。
{
"activities": [
{
"id": "00000",
"activityDateTime": "2025-03-05T05:24:34.399Z",
"access": {},
"actor": {
"user": {
"displayName": "Pikachu",
"email": "",
"id": "",
"userType": ""
}
},
"location": {
"address": {
"city": "",
"countryOrRegion": "",
"postalCode": "",
"state": "",
"street": ""
}
}
}
]
}
ふむふむ、activities配列内のactor.user.displayNameに名前が保存されているんですね。
実装
実装とは名ばかりの、ChatGPTにプロンプトを入力します。
「Pythonで、json_folder内のJSONファイルを読み込み、activities配列内のactor.user.displayNameを取得して、録画視聴者データ.xlsxの録画視聴者データシートに書き込むスクリプトを作成してください。各JSONファイルの名前をExcelのA列に書き込み、取得したdisplayNameをC列以降に横並びで記録してください。」
import os
import json
import openpyxl
# Excelファイルを読み込む
excel_file = '録画視聴者データ.xlsx'
wb = openpyxl.load_workbook(excel_file)
ws = wb['録画視聴者データ']
# json_folder内のJSONファイルのリストを取得
json_folder = 'json_folder'
json_files = [f for f in os.listdir(json_folder) if f.endswith('.json')]
# Excelの行カウンタを初期化
row_a = 2
# 各JSONファイルを処理
for json_file in json_files:
# ファイル名(拡張子込み)を取得
file_name_with_extension = json_file
# 拡張子込みのJSONファイル名を列Aに書き込む
ws[f'A{row_a}'] = file_name_with_extension
# 各JSONファイルの列カウンタを初期化
col_d = 3 # 列Cは3番目の列
# JSON内容を読み込む
with open(os.path.join(json_folder, json_file), 'r', encoding='utf-8') as f:
data = json.load(f)
# displayNameの値を抽出し、列Dから始まる現在の行に書き込む
for activity in data.get('activities', []):
display_name = activity.get('actor', {}).get('user', {}).get('displayName', '')
if display_name:
ws.cell(row=row_a, column=col_d, value=display_name)
col_d += 1
# 次のJSONファイルのために次の行に移動
row_a += 1
# 更新されたExcelファイルを保存
wb.save(excel_file)
print(f"データが正常に {excel_file} に書き込まれました。")
おお、なんかいい感じがする。
仮想環境を作ってopenpyxlをインストールを行って実行してみる。
結果・・・。
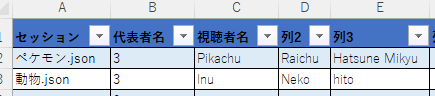
修正せずに動いてくれた!
ただ、細かいところですが、A列には拡張子は付かないでもらいたい。
追加で「A列には拡張子を着けないでください。」とプロンプトを入力した結果。(それくらい自分でやれとはおもいつつ)
import os
import json
import openpyxl
# Excelファイルを読み込む
excel_file = '録画視聴者データ.xlsx'
wb = openpyxl.load_workbook(excel_file)
ws = wb['録画視聴者データ']
# json_folder内のJSONファイルのリストを取得
json_folder = 'json_folder'
json_files = [f for f in os.listdir(json_folder) if f.endswith('.json')]
# Excelの行カウンタを初期化
row_a = 2
# 各JSONファイルを処理
for json_file in json_files:
# ファイル名から.json拡張子を取り除く
file_name_without_extension = '.'.join(json_file.split('.')[:-1])
# 拡張子を除いたJSONファイル名を列Aに書き込む
ws[f'A{row_a}'] = file_name_without_extension
# 各JSONファイルの列カウンタを初期化
col_d = 3 # 列Cは3番目の列
# JSON内容を読み込む
with open(os.path.join(json_folder, json_file), 'r', encoding='utf-8') as f:
data = json.load(f)
# displayNameの値を抽出し、列Dから始まる現在の行に書き込む
for activity in data.get('activities', []):
display_name = activity.get('actor', {}).get('user', {}).get('displayName', '')
if display_name:
ws.cell(row=row_a, column=col_d, value=display_name)
col_d += 1
# 次のJSONファイルのために次の行に移動
row_a += 1
# 更新されたExcelファイルを保存
wb.save(excel_file)
print(f"データが正常に {excel_file} に書き込まれました。")
結果・・・。

完璧です。
上の画像だと3名ですが、実際の人数はもっと多かったので非常に助かりました。
まとめ
AIはとても便利ですね。
今となってはですが、AI無しのコーディングが想像できません。
最近だと、コーディング技術より、プロンプトを作る技術のほうが大事なじゃないかと思ったり・・・。
ただ、AIの上で胡坐をかかず、日々精進していきたいです。
Discussion