AIは医師国家試験を解けるか?LLMベンチマーク「IgakuQA119」構築とFine-tuningによる性能評価【OSS】
はじめに
はじめまして、どくとりんと申します。医学部医学科の5年生で、現在は臨床実習の傍ら、研究室にて生命科学データ、特にオミクスデータに対する機械学習手法の開発に取り組んでいます。
最近、特に興味を持っているのが、大規模言語モデル(LLM)の医療分野への応用です。きっかけは、Preferred Networks(以下、PFN)大手町オフィスで今年3月28日に開催されたLLMオープンハウスへの参加でした。そこで語られていた経済ドメイン特化LLMの可能性や課題に触れ、医療ドメインにおいて自身の医学知識とこれまで培ってきた機械学習のスキルを活かせる領域だと強く感じました。
近年の研究では、主要な商用LLMが日本の医師国家試験において合格水準の知識と推論能力を持つことが示されています[1]。特に推論機能を持つモデルは高い正答率を記録し、人間と比較しても遜色ないレベルに達しつつあります。さらに、オープンソースのLLMにおいても、例えばPFNが開発した Llama3-Preferred-MedSwallow-70B は、医師国家試験でGPT-4を上回る性能を示し、オープンウェイトモデルとして初めて合格点を達成するなど、目覚ましい進展が見られます[2]。
しかし、これらの高性能LLMであっても、日本特有の医療制度や公衆衛生に関する問題、優先順位付けを要する臨床判断などには依然として課題が残されています[1:1]。また、医療ドメインにおけるLLMの性能を客観的に評価し、比較するための基準作り、特に日本語の医療文脈に特化した評価ベンチマークの整備はまだ発展途上です。英語圏では MedQA (USMLE), PubMedQA, MedMCQA, MMLU-Medical といった標準的なベンチマークが存在しますが[3]、日本語環境ではこれらの確立が遅れていました。
近年、有志によって IgakuQA[4] や JMMLU[5]、さらに JMED-LLM ([リポジトリ][6], [発表資料][7])、JMedBench ([データセット][8], [リポジトリ][9])、japanese-lm-med-harness[10] といった日本語評価基盤が登場し始めています。しかし、これらの既存ベンチマークにはいくつかの課題も指摘されています。例えば、一部のデータセットではライセンスが不明確であったり ([IgakuQA (jungokasai) に関する言及][7:1])、評価対象が主にテキストベースであり、画像を含む問題への対応が限定的である点が挙げられます。また、LLMの性能評価において重要なデータリーク (学習データに評価データが含まれてしまう問題) のリスクも無視できません。
そこで、これらの課題を克服し、より信頼性の高い評価基盤を提供することを目指し、LLMの知識がほぼない状態からでしたが、実際に手を動かして学ぶことを目的に、個人プロジェクトとして医師国家試験LLM評価ベンチマーク「IgakuQA119」を構築しました。このベンチマークは、[iKora128氏 (長嶋大地先生) ][11]が開発された[nmle-rtaリポジトリ][12]のクリーンなデータ作成プロセスにインスパイアされ、その成果(問題データ抽出部分など)を活用しつつ、評価パイプライン全体を独自に拡張したものです。
IgakuQA119は以下の点で独自性と強みを持っています。
- 最新試験データによるリーク防止: 評価対象として、2025年2月に実施された最新の第119回医師国家試験[13]を使用しています。これは、多くのLLMの知識カットオフ(通常2025年以前)よりも新しいデータであるため、学習データ汚染(データリーク)のリスクを大幅に低減し、LLMの真の推論能力を測定することに貢献します。
- クリーンなデータと再現性: [nmle-rta][12:1]のOCR処理などを基盤としつつ、データ準備から評価、分析までの一連のプロセスをOSS (GitHub: docto-rin/IgakuQA119) として公開しており、高い透明性と再現性を確保しています。
- (おそらく)日本語の医療ドメインでは初のマルチモーダル評価: 国試問題に含まれる画像問題(103問)も評価対象としており、テキスト処理能力だけでなく、Vision-Language Model (VLM) の性能も評価可能です。これは、テキストベースの評価が主流である既存の日本語医療ベンチマークにはない大きな特徴であり、マルチモーダルLLMの医療応用を見据えた評価を実現します。
このIgakuQA119ベンチマークを活用し、本プロジェクトでは32Bパラメータを持つ日本語LLM ([cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese][14]) に対して、自作の医師国家試験過去問データセット ([longisland3/NMLE][15] を元に加工) を用いた継続事前学習 (CPT) と教師ありFine-tuning (SFT) ([参考記事][16]) を行い、その効果を検証することに挑戦しました。Fine-tuningには、メモリ効率の良いQLoRAと高速化ライブラリUnsloth ([参考資料1][17], [参考記事2][18], [リポジトリ][19]) を活用しました。
本記事では、LLM初心者の医学部生が、約2週間という短期間で以下の内容に取り組んだプロセスと結果を、技術的な詳細を交えながら紹介します。
- IgakuQA119ベンチマークの設計と構築: 上記の強みを持つ評価フレームワーク。
- 医学知識注入のためのFine-tuningデータセット作成: Gemini 2.5 Proを活用した思考プロセス(CoT)付きデータセットの構築。
- Colab A100環境での32BモデルFine-tuning: Unsloth + QLoRAを用いたCPTとSFTの実践。
- Fine-tuning効果の検証: ベースモデルとFine-tuning後モデルの性能比較、誤答分析。
- 成果物の公開: Hugging FaceでのLoRA Adapter / GGUFモデル公開。
医療×AI分野やLLMのFine-tuningに興味のある方々、特にこれから医療ドメインでのLLM活用に取り組みたいと考えている方々の参考になれば幸いです。
IgakuQA119: 医師国家試験LLM評価ベンチマークの構築
背景と目的
LLMの医療応用には大きな期待が寄せられていますが、その性能を客観的に評価する基準作りが重要です。特に日本の医療文脈に合わせた評価が必要です。そこで、最新の第119回医師国家試験を題材に、日本語医療LLMの評価ベンチマーク「IgakuQA119」を開発しました。
主な目的は以下の通りです。
- 日本の医療ドメインにおけるLLM性能評価: 最新の国試問題で、知識・臨床推論能力を測る。
- 再現性と拡張性: OSS (GitHub: docto-rin/IgakuQA119) として公開し、誰でも評価・拡張可能にする。
- 多様なモデルへの対応: クラウドAPIからローカルLLM (Ollama経由) まで幅広くサポート。
- 自動化による効率化: 解答生成から採点、誤答分析の一部までを自動化。
- Fine-tuning効果の測定基盤: 自身が行うFine-tuningの効果を客観的に測定する。
このベンチマークは、[iKora128氏 (長嶋大地先生) ][11:1]が開発された[nmle-rtaリポジトリ][12:2]にインスパイアされており、特にデータセット構築の一部(PDFからのOCR処理など)は、同氏の許可を得てその成果(問題データ)を活用させていただいています。
長嶋先生による記事[1:2]は、メディックメディア社のINFORMAに掲載されており、本プロジェクトの基盤を考えるうえで非常に参考になりました。
システム概要
IgakuQA119は、データ準備から評価、分析までの一連のパイプラインをPythonで実装しています。リポジトリはこちらで公開しています。
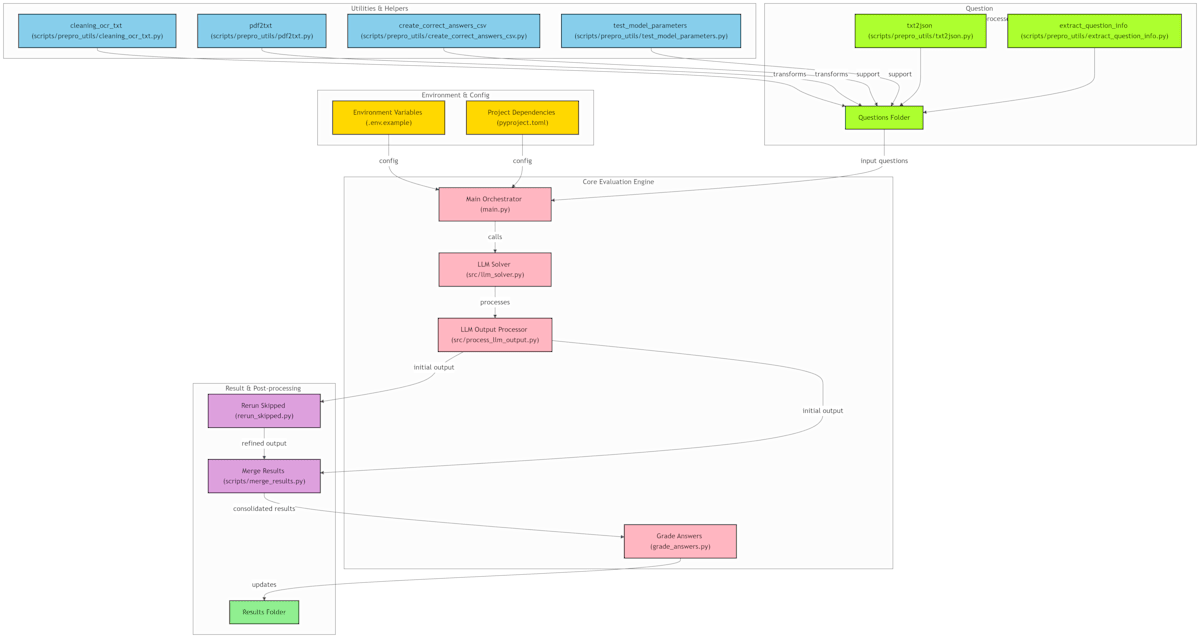
主なコンポーネントと私の貢献は以下の通りです。
1. データ準備 (scripts/prepro_utils 内のコード群)
医師国家試験の問題PDFをLLMが処理可能な形式に変換します。この部分は主に [nmle-rta][12:3] の作者によって実装されたコードです。
- PDF → テキスト抽出: Azure Document Intelligence を利用した高精度OCR。
- テキストクリーニング: OCR結果のノイズ除去、連問処理、英語問題対応。
-
JSON形式へ変換: 問題番号、問題文、選択肢、画像有無フラグを持つJSONデータを作成。
[ { "number": "119A1", "question": "問題文...", "choices": ["a. 選択肢A", "..."], "has_image": false }, // ... 他の問題 ... ] - 正解データ作成: 厚生労働省発表の正答に基づき、採点用のCSVファイルを作成。
2. LLMによる問題解答 (main.py, src/llm_solver.py)
評価したいLLMに問題を解かせるコア部分です。ここは元リポジトリの作者がベースを開発したものを、私が拡張しました。(ローカルLLM対応、プロンプト改良、出力のポストプロセス機能など)
-
マルチモデル対応: OpenAI API, Anthropic API, Gemini API, PLaMo API, DeepSeek API, Ollama ([20] 経由のローカルLLM) に対応。モデル指定の柔軟性を高めました (例:
ollama-llama3,huggingface.co/...)。 -
プロンプト設計: モデルに医師国家試験のエキスパートとしての役割と、厳密な出力形式(
answer,confidence,explanation,<think>タグによるCoT)を指示するプロンプトを設計・改善しました。 - 画像対応: マルチモーダルモデル向けに、問題番号に対応する画像をBase64エンコードしてプロンプトに含める機能(元作者による実装)。
-
出力処理 (
src/process_llm_output.py): LLMの応答をパースし、構造化データに変換。CoT抽出や、フォーマット不正時のポストプロセス機能を追加しました。
3. 自動採点 (grade_answers.py)
LLMの解答結果と正解データを比較し、自動採点します。このスクリプトは私が開発しました。
- 多様な解答形式への対応: 単数選択、複数選択(順序不問)、数値入力に対応。
- スコアリング: 正答率などを計算。
- 出力: モデルごとのサマリーテキストと誤答リストCSVを生成。
4. 結果集計 & リーダーボード更新 (grade_answers.py 内)
採点結果をもとに results/leaderboard.json と README.md 内のリーダーボードテーブルを自動更新する機能を実装しました。
| Rank | Entry | Overall Acc. | Overall Score (Rate) | No-Img Acc. | No-Img Score (Rate) |
|------|----------------------|--------------|----------------------|-------------|---------------------|
| 1 | Gemini-2.5-Pro | 97.25% | 485/500 (97.00%) | 97.64% | 372/383 (97.13%) |
| ... | ... | ... | ... | ... | ... |
| 4 | CA-DSR1-DQ32B-JP-SFT | 73.50% | 374/500 (74.80%) | 74.75% | 290/383 (75.72%) |
| ... | ... | ... | ... | ... | ... |
5. 誤答分析 (scripts/compare_wrong_answers.py)
モデル間の性能差を深く理解するため、誤答比較・分析スクリプトを開発しました。
- 比較: 2モデル間の誤答をパターン分類(両方誤答、片方のみ誤答)し、詳細レポート(CSV/Markdown)を出力。
- 自動考察: Gemini 2.5 Pro 等の高精度LLMに比較レポートを渡し、誤答傾向の違いや原因を考察させる機能を実装。これにより、分析の効率化と質の向上を目指しました。
6. 再現性と安定性の担保
評価の信頼性を高めるため、スキップされた問題の再実行 (rerun_skipped.py) と結果マージ (scripts/merge_results.py) の機能を追加しました。
これらのコンポーネントにより、医師国家試験を用いたLLM評価を体系的かつ効率的に行う基盤を構築しました。
次に、このベンチマークで評価するモデルの性能向上を目指し、Fine-tuningに取り組んだプロセスについて説明します。
医学知識注入のためのFine-tuningデータセット構築
LLMを特定のドメインに適応させる効果的な手法の一つがFine-tuningです。特に医療分野では、専門知識の正確性や臨床現場での思考プロセス(推論能力)が重要になります。そこで、ベースとなる日本語LLMに対し、医師国家試験の過去問データを用いて医学知識と言語能力、そして問題解決能力を注入することを試みました。
目的とアプローチ
Fine-tuningの目的は以下の2点です。
- 医学知識の強化: 医師国家試験で問われる広範な医学知識をモデルに学習させる。
- 思考プロセスの学習: 単に正解を当てるだけでなく、正解に至るまでの論理的な思考過程(Chain-of-Thought: CoT)と、その根拠を説明する能力を獲得させる。
この目的を達成するため、2つの異なるFine-tuningアプローチを採用しました。
- 継続事前学習 (Continued Pre-training: CPT): 大量のドメインテキスト(今回はCoTとExplanationを含むテキスト)を追加学習させることで、モデルの持つ言語モデルとしての基礎能力とドメイン知識全体を底上げする。
- 教師ありFine-tuning (Supervised Fine-tuning: SFT): 特定のタスク形式(今回の場合は「問題文 → CoT + 解答 + 説明」の生成)にモデルを適応させる。
データソースとCoT/Explanation生成
CoT/Explanation生成に関する注記
本研究における教師データ(思考プロセスおよび解説文)の生成には、Google社のGemini 2.5 Proを利用しました。Gemini APIの利用規約では、本サービスと競合するモデルの開発が制限されています。本プロジェクトは、特定の学術的課題(医師国家試験の解答精度向上)を探求する研究目的であり、小規模なファインチューニングを通じて得られた知見をコミュニティに共有するものです。Geminiのような汎用大規模モデルと競合する商用サービスを開発する意図は一切ありません。
- データソース: [longisland3/NMLE][15:1] データセットに含まれる、第110回から第117回までの医師国家試験過去問(3390問)を利用しました。このデータセットには問題文、選択肢、正解ラベルが含まれています。
-
CoT/Explanationの自動生成:
- 単に正解ラベルを学習させるだけでは、モデルの思考プロセスや説明能力は向上しにくいと考えました。そこで、思考過程 (CoT) と 解答根拠 (Explanation) を含む高品質な教師データを作成することにしました。
- 教師データの生成には、IgakuQA119ベンチマークで最高性能(得点率97.00%)を示した Gemini 2.5 Pro (gemini-2.5-pro-exp-03-25) を利用しました。各過去問の問題文・選択肢・正解ラベルを入力として与え、CoTとExplanationを生成させるプロンプトを設計しました。
- プロンプト例 (
JMLE-Gemini-2.5-Pro-CoT-Dataset Generatorより):def create_system_prompt(): return ( "あなたは医師国家試験の過去問を解くにあたり、" "医学を隅々まで理解している非常に優秀で論理的なアシスタントです。\n\n" # ... (ルール説明: <Thoughts>タグ、<o>タグでの出力形式指定) ... ) def create_user_prompt(example: dict) -> str: # ... (問題文、選択肢、正解ラベルを埋め込む) ... return ( "以下の問題文・選択肢・正解ラベルを踏まえ、" "最終解答に至るまでの詳細な思考過程と、最終解答を指定のタグで出力してください。\n\n" f"【問題番号】{example['id']}\n" f"【問題文】\n{example['question']}\n\n" # ... (選択肢表示) ... f"【正解(参考)】\n{example['answer']}\n\n" # ... (出力形式の指示と例) ... )
データ形式と品質向上
-
データ形式:
-
CPT用: 生成されたCoTとExplanationを結合した長いテキストデータとして扱いました。モデルがこれらのテキストのパターンや語彙、論理構造を学習することを期待しました。具体的には、以下のような形式のテキストを学習データとしました。(実際には
<think> 思考プロセス... </think> explanation: 医学的根拠...<|endoftext|><think>やexplanation:といった構造も学習データの一部として含めています) -
SFT用: より明確な指示応答形式にするため、ChatML形式を採用しました。
convert_to_chat_format関数で各問題をuser(問題提示) とassistant(CoT + 解答 + 説明) の対話ターンに変換し、SFTTrainerが扱えるようにしました。# convert_to_chat_format 関数で生成される形式の例 [ {"role": "user", "content": "以下の医師国家試験問題について...\n問題:...\n選択肢:...\n"}, {"role": "assistant", "content": "<think>\n思考プロセス...\n</think>\nanswer: a\nexplanation: 医学的根拠..."} ]
-
CPT用: 生成されたCoTとExplanationを結合した長いテキストデータとして扱いました。モデルがこれらのテキストのパターンや語彙、論理構造を学習することを期待しました。具体的には、以下のような形式のテキストを学習データとしました。
-
品質向上プロセス:
- Gemini 2.5 Proは非常に高性能ですが、それでも34件の問題で指示通りの形式で出力されなかったり、正解ラベルと矛盾したCoT/Explanationを生成したりするケースがありました (
unmatchedスプリット)。 - これらの不整合データを修正するため、ipywidgets を用いた簡易的な手動修正ツール (
JMLE-Gemini-2.5-Pro-CoT-Dataset-Correction.ipynb) をColab上で作成しました。これにより、問題ごとに元の正解とモデル生成の回答、CoT、Explanationを確認し、効率的に修正作業を行うことができました。 - 修正後のデータと元の
trainデータを結合し、最終的なFine-tuning用データセット (doctorin/JMLE-CoT-gemini-2.5-pro-dataset-combined) を作成しました。このデータセットには、データが元々train由来かunmatched由来かを示すsourceカラムも追加しています。
- Gemini 2.5 Proは非常に高性能ですが、それでも34件の問題で指示通りの形式で出力されなかったり、正解ラベルと矛盾したCoT/Explanationを生成したりするケースがありました (
このようにして作成した、CoTとExplanationを含む高品質な医師国家試験過去問データセットを用いて、次のステップであるFine-tuningに臨みました。
Colab A100で挑む32BモデルのFine-tuning (CPT & SFT)
32B(320億)パラメータクラスのLLMのFine-tuningは、通常、十分なGPUメモリを持つ環境が必要です。今回は、Google ColabのA100 (40GB VRAM) 環境を利用し、効率的なFine-tuningを実現するライブラリ Unsloth[19:1] と QLoRA を活用しました。
技術選定
- ベースモデル: Hugging Face Hubで公開されている日本語LLMの中から、比較的高性能で商用利用可能なライセンスを持つ [cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese][14:1] を選択しました。これはDeepSeekとQwenの知識を蒸留したモデルであり、日本語能力に期待が持てました。
- Unsloth: LoRA (Low-Rank Adaptation) を用いたFine-tuningを高速化・省メモリ化するライブラリです[19:2]。特にQLoRA (4bit量子化を用いたLoRA) と組み合わせることで、A100のような単一GPUでも大規模モデルのFine-tuningを現実的にします。手動での最適化コード記述の手間を大幅に削減できる点も魅力でした[18:1]。
- QLoRA: モデルの重みを4bitに量子化し、LoRAアダプタ部分のみを学習することで、メモリ使用量を大幅に削減する手法です[17:1]。性能の劣化を最小限に抑えつつ、大規模モデルのFine-tuningを可能にします。
CPT (継続事前学習)
CPTの目的は、モデルに医師国家試験ドメインのテキスト(思考プロセスや医学的説明を含む)を追加学習させ、言語モデルとしての基礎能力とドメイン知識を向上させることです[16:1]。
-
学習設定:
-
LoRA:
r=16,alpha=16,dropout=0.05。Target modulesは線形層 (q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj) に加え、埋め込み層 (embed_tokens,lm_head) も対象としました。これらのうち埋め込み層についてはSFTでは対象外にしました。 -
学習率:
5e-5(LoRAの標準的な値)。埋め込み層の学習率は5e-6と低めに設定。 -
バッチサイズ:
per_device=1,gradient_accumulation=8(Effective Batch Size = 8)。メモリ制約のため、勾配累積で実質的なバッチサイズを確保しました。 -
エポック数:
1。データセットサイズ(3390問 × 長いCoT/Explanation)を考慮し、1エポックとしました。 -
オプティマイザ:
adamw_8bit(省メモリ版AdamW)。 -
データコレータ:
DataCollatorForLanguageModeling(言語モデリングタスク用)。
-
LoRA:
-
学習コード:
JMLE-CPT.ipynb(Colabリンク)- Unslothの
FastLanguageModelを用いてモデルをロードし、get_peft_modelでLoRA設定を適用。 - データセットは、前述のCoT/Explanationを含むテキスト (
formatted_textカラム) を単純に連結する形で準備し、トークナイズ。 -
UnslothTrainerとUnslothTrainingArgumentsを用いて学習を実行。 -
# JMLE-CPT.ipynb より抜粋 from unsloth import FastLanguageModel, UnslothTrainer, UnslothTrainingArguments from transformers import DataCollatorForLanguageModeling # ... (model, tokenizer ロード & LoRA設定) ... # データセット準備 (CPT用テキスト生成 & トークナイズ) def create_cpt_text(example): # <think>...</think> explanation: ... EOS の形式 # (この部分は上記データセット準備のコードで実施済みの前提) # 実際のコードでは formatted_dataset['formatted_text'] を使う pass # tokenized_dataset = formatted_dataset.map(...) data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False) trainer = UnslothTrainer( model=model, tokenizer=tokenizer, train_dataset=processed_dataset["train"], eval_dataset=processed_dataset["test"], args=UnslothTrainingArguments( per_device_train_batch_size=1, gradient_accumulation_steps=8, num_train_epochs=1, # ... 他の引数 ... output_dir=output_dir, ), data_collator=data_collator, ) trainer.train()
- Unslothの
- リソース使用量: A100 (40GB) 環境で、ピーク時のVRAM使用量は約32.7GBでした。
SFT (教師ありFine-tuning)
SFTの目的は、特定のタスク形式、つまり「医師国家試験の問題文を入力として、CoT、解答、Explanationを所定の形式で出力する」能力をモデルに学習させることです。
-
学習設定:
- ベースモデル: CPTを実施した上記モデルではなく、オリジナルの [cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese][14:2] を再度ロードして使用しました。(CPT済みモデルにSFTを行うアプローチも考えられますが、今回はベースモデルからのSFTとCPTの効果を比較するため、それぞれ独立して実施しました。)
-
LoRA: CPTと同じ設定 (
r=16,alpha=16,dropout=0.05)。Target modulesは埋め込み層を除き、CPTと同様としました。 -
学習率:
2e-5。CPTよりやや低めに設定しました。 - バッチサイズ: CPTと同じ (Effective Batch Size = 8)。
-
エポック数:
1。 -
オプティマイザ:
adamw_8bit。 - データ形式: ChatML形式にフォーマットしたデータを使用。
-
Trainer:
trlライブラリのSFTTrainerを使用しました。これはInstruction Tuningや対話形式のデータセットでの学習に適しています。 -
データコレータ:
DataCollatorForSeq2Seqを使用しました。
-
学習コード:
JMLE-SFT.ipynb(Colabリンク)- データ準備段階で
convert_to_chat_formatとformatting_chat_funcを用いてChatML形式のtextカラムを作成。 -
SFTTrainerを初期化し、dataset_text_field="text"を指定して学習を実行。 -
# JMLE-SFT.ipynb より抜粋 from unsloth import FastLanguageModel from trl import SFTTrainer from transformers import TrainingArguments, DataCollatorForSeq2Seq # ... (model, tokenizer ロード & LoRA設定) ... # データセット準備 (ChatML形式への変換) # formatted_dataset = filtered_chat_dataset.map(formatting_chat_func, ...) # train_dataset_sft = split_dataset["train"] # eval_dataset_sft = split_dataset["test"] data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True) trainer = SFTTrainer( model=model, tokenizer=tokenizer, train_dataset=train_dataset_sft, eval_dataset=eval_dataset_sft, dataset_text_field="text", # ★ ChatML形式のテキストを指定 args=TrainingArguments( per_device_train_batch_size=1, gradient_accumulation_steps=8, num_train_epochs=1, learning_rate=2e-5, # ... 他の引数 ... output_dir=output_dir_sft, ), max_seq_length=max_seq_length, data_collator=data_collator, ) trainer.train()
- データ準備段階で
- リソース使用量: A100 (40GB) 環境で、ピーク時のVRAM使用量は約22.8GBでした。SFTの方がCPTよりも若干メモリ使用量が少ない傾向が見られました。
このように、Unsloth[19:3]とQLoRAを活用することで、Google ColabのA100環境でも32BパラメータモデルのCPTとSFTを比較的効率的に実行することができました。
次に、これらのFine-tuningが実際に医師国家試験LLMの性能をどの程度向上させたのか、詳細な評価結果と考察を述べます。
Fine-tuningは国試LLMの性能を向上させたか? 徹底比較と考察
Fine-tuningによってモデルの性能は向上したのでしょうか? 構築したIgakuQA119ベンチマークを用いて、ベースモデル、CPTモデル、SFTモデルの性能を定量的に比較し、さらに誤答分析を通じてその効果と限界を探りました。
評価方法
-
対象モデル:
- Base: [cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese][14:3] (Fine-tuning前のベースモデル)
- CPT: 上記ベースモデルに自作データセットでCPTを行ったモデル (LoRAアダプタを適用)
- SFT: 上記ベースモデルに自作データセットでSFTを行ったモデル (LoRAアダプタを適用)
- 比較対象: IgakuQA119リーダーボードに掲載されている他のモデル (Cogito-32B, Gemini, GPT-4oなど)
- 評価データ: 第119回医師国家試験 全400問 (画像問題含む)
-
評価指標:
- Overall Accuracy: 全400問に対する正答率
- Overall Score Rate: 配点を考慮した得点率 (参考値)
- No-Image Accuracy: 画像を含まない問題 (297問) の正答率 (テキストベースの能力評価)
- No-Image Score Rate: 画像を含まない問題の得点率 (参考値)
-
誤答分析:
scripts/compare_wrong_answers.pyを用いて、モデル間の誤答パターンを比較。Gemini 2.5 Proによる自動考察も参考にしつつ、詳細な分析を実施。
性能比較結果
IgakuQA119リーダーボードの結果(一部抜粋)を以下に示します。
| Rank | Entry | Overall Acc. | Overall Score (Rate) | No-Img Acc. | No-Img Score (Rate) | Fine-tuning Type |
|---|---|---|---|---|---|---|
| 1 | Gemini-2.5-Pro | 97.25% | 485/500 (97.00%) | 97.64% | 372/383 (97.13%) | - (Commercial) |
| 2 | Gemini-2.0-Flash | 88.00% | 436/500 (87.20%) | 88.55% | 333/383 (86.95%) | - (Commercial) |
| 3 | Cogito-32B-Think | 77.50% | 392/500 (78.40%) | 79.80% | 305/383 (79.63%) | - (Local/Think) |
| 4 | CA-DSR1-DQ32B-JP-SFT | 73.50% | 374/500 (74.80%) | 74.75% | 290/383 (75.72%) | SFT |
| 5 | CA-DSR1-DQ32B-JP (Base) | 70.50% | 364/500 (72.80%) | 71.38% | 280/383 (73.11%) | Base |
| 6 | CA-DSR1-DQ32B-JP-CPT | 69.50% | 356/500 (71.20%) | 71.72% | 277/383 (72.32%) | CPT |
| 7 | Cogito-32B-No-Think | 69.50% | 346/500 (69.20%) | 71.04% | 271/383 (70.76%) | - (Local/NoThink) |
| ... | ... | ... | ... | ... | ... |
主な結果:
- SFTの効果: SFTモデルは、ベースモデルと比較してOverall Accuracyで+3.0%、No-Image Accuracyで+3.37% と明確な性能向上を示しました。これは、SFTが医師国家試験解答という特定タスクへの適応に成功したことを示唆します。
- CPTの効果: 一方、CPTモデルは、ベースモデルと比較してOverall Accuracyで-1.0%、No-Image Accuracyで+0.34% と、性能向上は限定的、あるいはわずかに低下する結果となりました。今回のCPT設定(1エポック、特定のCoT/Explanation形式)では、必ずしも性能向上に繋がらなかった可能性があります。
- ローカルモデル内での比較: Fine-tuningしたSFTモデル (73.50%) は、推論モードをONにしたCogito-32B (77.50%) には及ばないものの、推論モードOFFのCogito-32B (69.50%) や他のいくつかのローカルモデルを上回る性能を示しました。
- 商用モデルとの差: 最先端の商用モデル(Gemini 2.5 Pro: 97.25%)との間には依然として大きな性能差があります。
誤答分析と考察
Fine-tuningの効果をより深く理解するため、compare_wrong_answers.py を用いて誤答を分析しました。以下は、Base vs SFTの比較分析レポート や CPT vs SFTの比較分析レポート (いずれもGemini 2.5 Proによる自動考察を含む) を参考に、私自身の考察を加えたものです。
SFTで改善が見られた点
- 臨床推論・治療選択の精度向上: ベースモデルが誤答した複雑な臨床問題や治療選択問題(例: 119A44 心不全治療、119A52 腎梗塞疑い、119B16 急性中耳炎、119D52 前立腺癌術前説明)において、SFTモデルが正答するケースが多く見られました。これは、CoTを含むデータで学習したことにより、問題解決に至る思考プロセスを模倣する能力が向上したためと考えられます。
- 国試特有のパターンへの適応: SFTにより、医師国家試験で問われやすい知識や出題形式への適合が進んだと考えられます。
SFTの課題・新たな誤答傾向
- 基本的な知識問題での誤答: 驚くべきことに、ベースモデルが正答していた比較的単純な知識問題(例: 119A4 好発部位、119B1 俗称、119F3 新生児の生理)でSFTモデルが誤答するケースが見られました。これは、SFTデータへの過学習や、Fine-tuning過程での破壊的忘却 (Catastrophic Forgetting) の可能性を示唆します。
- 複数選択問題での選択ミス: 複数選択が要求される問題で、正解の一部しか選択できなかったり、誤った組み合わせを選んだりするケースがSFTモデルに見られました(例: 119A12, 119D12, 119F35)。これは、指示理解能力や複数選択肢の評価能力に課題が残っていることを示します。
- 推論の硬直化?: 一部の問題では、ベースモデルよりも思考プロセスが単純化されたり、特定の情報に引きずられたりするような誤答も見られました。SFTにより柔軟性が失われた可能性も考えられます。
CPTの効果が限定的だった理由の考察
今回のCPTでは明確な性能向上が見られませんでした。考えられる理由としては、
- 学習エポック不足: 1エポックの学習では、広範な知識や能力を獲得するには不十分だった可能性があります。
- データ形式: CoTとExplanationを単純に連結したテキスト形式が、CPTには最適でなかった可能性があります。より多様な形式のテキストデータや、マスク言語モデルのようなタスクが有効かもしれません。
- 知識とタスクのトレードオフ: CPTによって広範な知識は注入されたかもしれませんが、それが特定のタスク(国試解答)の性能向上に直結せず、むしろ既存の能力と干渉してしまった可能性も考えられます。
CPTモデルにおける特異な誤答パターン:指示追従能力への影響
CPTモデルのスコアがBaseモデルを下回った点について、さらに詳細な誤答分析を行ったところ、興味深い、かつ重要なパターンが明らかになりました。IgakuQA119ベンチマークでは、解答形式として選択肢の記号(例: a, b)のみを期待しています。しかし、CPTモデル (doctorin/CA-DeepSeek-R1-D-Qwen-32B-Jp-cpt-0.3:Q4_K_M) では、記号で答えるべきところで選択肢の記述全文(例: e. 能力(エネルギー))を含めて解答してしまい、これが不正解と判定された問題が8問(配点合計12点分)も存在しました。
もし、この形式不一致による誤答を仮に正解として扱った場合、CPTモデルの合計スコア (356点) はBaseモデル (364点) を4点上回る計算になります (356 + 12 = 368点)。これは、単純なスコアだけでは見えないCPTの効果を示唆すると同時に、その副作用も浮き彫りにします。
CPTは、大量のドメインテキストを追加学習させることで、モデルの持つ知識や言語能力の底上げを目的とします。今回のCPTデータ(CoTとExplanationを含む自由形式テキスト)も、その意図で設計されました。しかし、この学習プロセスが、Baseモデルが元々持っていた(あるいは事前学習や初期のInstruction Tuningで獲得していた)厳密な指示に従う能力、特にシステムプロンプトで指定された出力形式を遵守する能力を弱めてしまった可能性が考えられます。つまり、知識増強というメリットの裏で、特定のタスク遂行に必要な指示追従性 (Instruction Following) が低下するというトレードオフが発生したのかもしれません。
特筆すべきは、このような「記号解答の失敗」パターンは、BaseモデルやSFTモデルではほとんど見られなかった点です。SFTは明確な指示応答形式(ChatML)で学習させたため、タスクへの適応と同時に指示追従性も維持・向上したと考えられます。このことから、単純な自由形式テキストによるCPTは、モデルの知識ベースを豊かにする一方で、特定の指示に対する忠実度を損なうリスクがあることが示唆されます。他のモデルではこの誤答パターンはそこまで見られず、今回のCPTモデルに特有の傾向でした。
この結果は、CPTを設計・実施する際には、注入したい知識の内容だけでなく、学習データ形式や学習方法がモデルの持つ他の能力(特にInstruction Following)にどのような影響を与えるかを慎重に評価する必要があることを教えてくれます。
CoTとExplanationの変化
Fine-tuning前後でExplanationの内容を比較すると、SFTモデルはベースモデルよりも構造化された、より詳細な医学的根拠を示す傾向が見られました。これは、教師データとして与えたCoT/Explanationのスタイルを学習した結果と考えられます。しかし、それが必ずしも正答に繋がっているわけではなく、誤った知識に基づいて詳細な(しかし間違った)説明を生成してしまうケースも見られました。
まとめとFine-tuningの示唆
- SFTは有効: 今回の実験では、SFTが医師国家試験解答タスクにおいて、ベースモデルの性能を明確に向上させることが示されました。特にCoTを含むデータでの学習は、臨床推論能力の向上に寄与する可能性があります。
- SFTの諸刃の剣: 一方で、SFTは過学習や知識忘却のリスクも伴います。基本的な知識の精度が低下したり、推論の柔軟性が失われたりする可能性があり、慎重なデータ設計と学習設定が必要です。
- CPTの難しさ: 単純なドメインテキストの追加学習(CPT)が、必ずしも特定タスクの性能向上に繋がるとは限りません。データ形式、学習量、タスクとの関連性、そして既存能力(特に指示追従性)への影響を考慮した設計が重要です。
- 計算問題への効果は限定的: Fine-tuning後も、計算問題における誤答は依然として多く見られました。これらの問題には、単なるテキスト学習とは異なるアプローチ(例: 計算モジュールの統合、専用データセットでの訓練)が必要かもしれません。
- CoT/Explanation学習の価値と課題: CoTやExplanationを学習させることで、モデルの思考プロセスや説明能力を向上させる可能性はありますが、その内容の質や正確性を担保することが新たな課題となります。
このFine-tuningの経験は、LLMの性能向上におけるデータと手法の重要性、そしてその難しさを実践的に学ぶ貴重な機会となりました。
成果物と公開モデル
今回のプロジェクトで開発したコード、学習済みモデルは、今後の医療LLM研究や開発に貢献できるよう、可能な限りオープンに公開しています。
1. IgakuQA119: 医師国家試験LLM評価ベンチマーク
- リポジトリ:
- 特徴: 第119回医師国家試験データ、多様なLLM対応評価パイプライン、自動採点・分析機能。
- GitHub (IgakuQA119 Analysis): Base vs SFT比較分析レポート(自動生成)
- GitHub (IgakuQA119 Analysis): CPT vs SFT比較分析レポート(自動生成)
2. Fine-tuning用コード・データセット生成コード
- リポジトリ:
-
内容:
- CoT/Explanation付きデータセット生成コード (
JMLE-Gemini-2.5-Pro-CoT-Dataset Generator関連) - 手動修正ツール (
JMLE-Gemini-2.5-Pro-CoT-Dataset-Correction.ipynb) - CPT学習コード (Google Colab: JMLE-CPT.ipynb)
- SFT学習コード (Google Colab: JMLE-SFT.ipynb)
- CoT/Explanation付きデータセット生成コード (
- Fine-tuning用元データ: [longisland3/NMLE][15:2] (CoT/Explanation生成前のデータ)
-
注意: 上記コードで生成・修正したCoT/Explanation付きデータセット (
doctorin/JMLE-CoT-gemini-2.5-pro-dataset-combined) はライセンスの都合上、現在非公開です。
3. Fine-tuning済みモデル
Fine-tuningによって学習されたモデルを、ローカル環境でCPU/GPUを用いて実行しやすいGGUF形式 (q4_k_m 量子化) および、元のLoRAアダプタ形式でHugging Face Hubに公開しています。
- CPT GGUF Model: doctorin/CA-DeepSeek-R1-D-Qwen-32B-Jp-CPT-GGUF
- SFT GGUF Model: doctorin/CA-DeepSeek-R1-D-Qwen-32B-Jp-SFT-GGUF
- CPT LoRA Adapter: doctorin/CA-DeepSeek-R1-D-Qwen-32B-Jp-CPT-LoRA-Adapter
- SFT LoRA Adapter: doctorin/CA-DeepSeek-R1-D-Qwen-32B-Jp-SFT-LoRA-Adapter
利用方法例 (GGUFモデル / Ollama)
- Ollama[20:1]をインストール
- モデルをダウンロード&実行 (例: SFTモデル):(タグ
ollama run docto-rin/CA-DeepSeek-R1-D-Qwen-32B-Jp-SFT-GGUF:q4_k_mq4_k_mは利用可能なファイルに合わせて指定してください) - IgakuQA119を動かす:
main.pyの--models引数にHugging Face HubのモデルIDを指定します。uv run main.py questions/119A_json.json --models huggingface.co/doctorin/CA-DeepSeek-R1-D-Qwen-32B-Jp-SFT-GGUF:q4_k_m --exp 119A_sft_gguf
これらの成果物が、他の研究者や開発者による医療LLMの評価や改善、新たな応用の探求に少しでも役立つことを期待しています。
まとめと今後の展望
本記事では、医学部生である私がLLMの知識ゼロから出発し、医師国家試験LLM評価ベンチマーク「IgakuQA119」を構築し、32B日本語LLMのFine-tuning (CPT/SFT) を行い、その効果を検証・公開するまでのプロセスを紹介しました。
本プロジェクトの成果と学び
- 実践的なベンチマーク構築: 最新の医師国家試験データに基づき、多様なLLMを評価できる再現性・拡張性の高いパイプラインを構築・公開しました。
- Fine-tuningの実践と評価: Colab A100環境とUnsloth[19:4]/QLoRA[17:2]を活用し、32BモデルのCPTとSFTを実施。特にSFTによる性能向上を確認する一方で、CPTの効果の限定性や指示追従性への影響、SFTの課題(過学習、知識忘却)も目の当たりにしました。
- データセット構築の重要性: 高品質なCoT/Explanation付きデータセットの作成(Gemini活用と手動修正)がFine-tuningの質に影響を与えることを実感しました。
- 短期間でのキャッチアップ: 約2週間という限られた期間で、LLMの基礎からFine-tuning、評価、公開までの一連のサイクルを自律的に経験し、多くの技術的知見を得ることができました。
このプロジェクトを通じて、机上の空論ではなく、実際に手を動かし、試行錯誤することでしか得られない深い学びがありました。特にFine-tuningの効果分析では、定量的な評価だけでなく、誤答の詳細な分析を通してモデルの挙動を理解することの重要性を痛感しました。
今後の展望
今回のプロジェクトは、医療LLM評価と改善に向けた第一歩です。今後は、以下のような方向でさらに発展させていきたいと考えています。
- IgakuQA119の拡張:
- データセットの質向上:
-
学習手法の改良:
- CPTの効果的な方法の探求: 今回の結果を踏まえ、データ形式、学習タスク、エポック数などを最適化し、CPTが持つポテンシャルを引き出す方法を探ります[16:2]。
- Instruction Tuningの多様化(Zero-shot, Few-shot性能の向上)。
- RLHFやDPOなど、より高度なFine-tuning手法の導入検討: 人間のフィードバックや嗜好を直接学習に取り入れる DPO (Direct Preference Optimization)[23][24] や、関連する手法 (IPO, cDPO, RSO) の導入を検討します。
- モデルマージ技術の活用検討: 複数のモデル(例えば、異なるFine-tuningを施したモデルや、特定の能力に特化したモデル)の重みを組み合わせることで、より高性能なモデルを効率的に構築するモデルマージ[25] の適用可能性を探ります。
- Fine-tuning効率化技術の継続的な活用・改善: Unsloth[18:2][19:5] やQLoRAなどの技術動向を注視し、より効率的な学習パイプラインを追求します。
-
信頼性と解釈可能性の向上:
- RAG (Retrieval-Augmented Generation) との連携: 外部知識データベースを参照することで、知識の正確性向上と出典提示を実現するRAG[26] の導入を検討します。
- MCP (Model Context Protocol) を活用した外部ツール連携によるアプリケーション推進。
- モデルの判断根拠をより分かりやすく提示する手法の開発。
最後に
「医学×情報学」という私のバックグラウンドは、医療AI開発においてユニークな視点を提供できると信じています。臨床現場のニーズやデータの特性を理解しつつ、最新のAI技術を適用していくことで、真に医療現場で役立つソリューションを生み出せる可能性があります。
このIgakuQA119プロジェクトは、その第一歩であり、私自身の学習プロセスそのものでした。LLMやFine-tuningは奥が深く、まだまだ学ぶべきことは多いですが、この経験を糧に、今後も医療AIの分野、特に信頼性が高く、臨床応用可能なLLMの研究開発に貢献していきたいと考えています。
この記事が、医療分野でのLLM活用やFine-tuningに興味を持つ方々への一助となれば幸いです。
-
INFORMA: 各AIモデルによる第119回医師国家試験の解答精度の評価 ↩︎ ↩︎ ↩︎
-
PFN Tech Blog: 医療・ヘルスケア領域における大規模言語モデルの構築に向けて ↩︎
-
Zenn (hellorusk): 医療ドメイン特化LLMの性能はどうやって評価する? ↩︎
-
GitHub: jungokasai/IgakuQA ↩︎
-
GitHub: nlp-waseda/JMMLU ↩︎
-
GitHub: sociocom/JMED-LLM ↩︎
-
Speaker Deck (fta98): JMED-LLM: 日本語言語モデルのための医療評価データセットの公開 ↩︎ ↩︎
-
Hugging Face Datasets: Coldog2333/JMedBench ↩︎
-
GitHub: nii-nlp/med-eval ↩︎ ↩︎
-
X (Twitter): iKora128 (長嶋大地先生) アカウント ↩︎ ↩︎
-
GitHub: iKora128/nmle-rta (National Medical Licensing Examination - RTA) ↩︎ ↩︎ ↩︎ ↩︎
-
厚生労働省: 第119回医師国家試験の合格発表について ↩︎
-
Hugging Face: cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese ↩︎ ↩︎ ↩︎ ↩︎
-
Hugging Face Datasets: longisland3/NMLE ↩︎ ↩︎ ↩︎
-
Qiita (ikedachin): unslothを用いて大規模言語モデルを継続事前学習 ↩︎ ↩︎ ↩︎
-
Docswell (KanHatakeyama): 数値で整理する大規模言語モデル(LLM) のメモ ↩︎ ↩︎ ↩︎
-
Zenn (sunwood_ai_labs): Unslothを使った高速なLlama 3.2ファインチューニング入門 (📒ノートブック付) ↩︎ ↩︎ ↩︎
-
Ollama: https://ollama.com/ ↩︎ ↩︎
-
Hugging Face Datasets: FreedomIntelligence/medical-o1-reasoning-SFT ↩︎
-
Hugging Face Datasets: FreedomIntelligence/Medical-R1-Distill-Data ↩︎
-
Qiita (kunishou): LLM における強化学習と Direct Preference Optimization による安全性能への影響評価 ↩︎
-
Qiita (shibu_phys): LLMファインチューニング・アライメント手法の解説 ↩︎
-
Nature Machine Intelligence: Evolutionary optimization of model merging recipes ↩︎
-
PFN Tech Blog: より正確ながん情報の提供を目指して:RAGと大規模言語モデルの研究 ↩︎
Discussion