【Awesome】2025年 デジタル病理学のための深層学習手法まとめ
はじめに
空間オミクスやデジタル病理学の分野では、最新のベンチマーク、ワークフロー、基盤モデル、CLIP技術、さらにはオプショナルツールが次々と登場しています。
本記事は、筆者がこれまで見てきたデジタル病理画像解析に関するプロジェクトの中でもとくに競争力が高い、または画期的だと思った研究に絞ってまとめました。
各リンクから詳細な情報にアクセスできるので、ぜひ参考にしてください。
Benchmarks / Datasets
-
for foundation models
→ NeurIPS Spotlight 2024
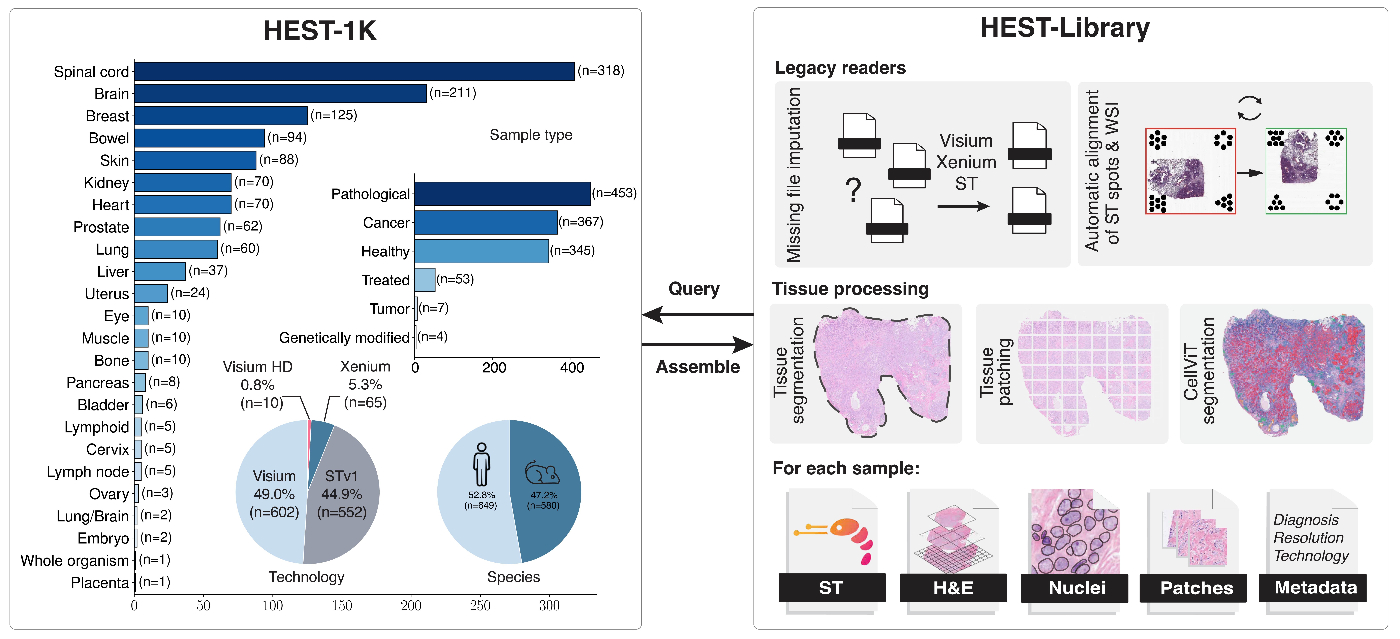
-
for non-foundation models
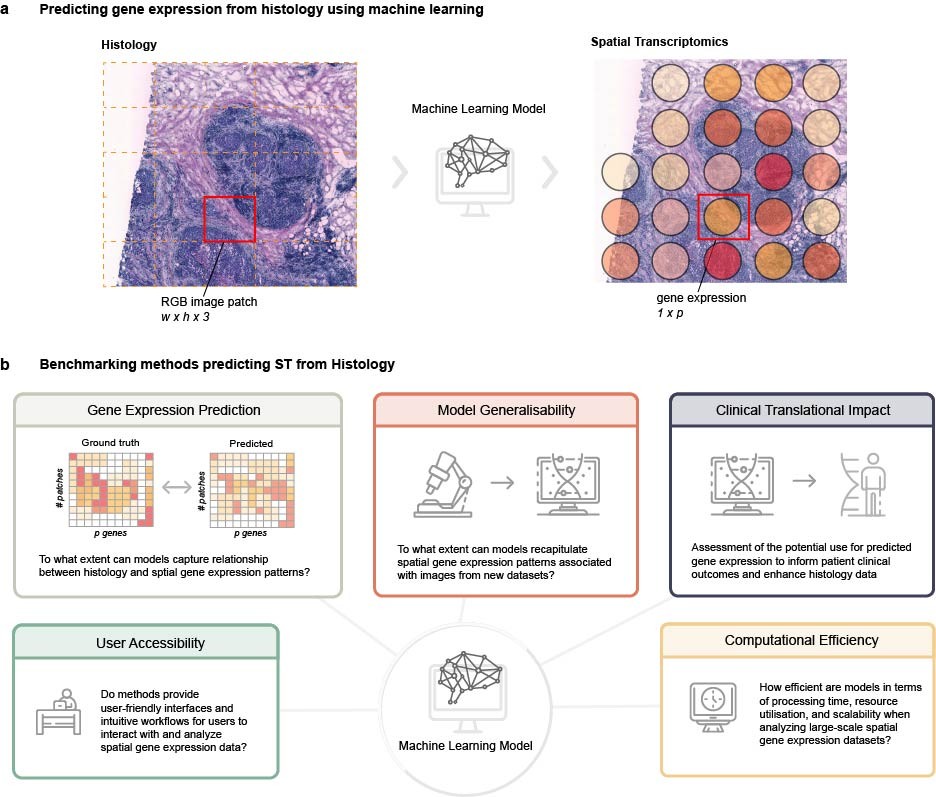
2D Workflow
-
Pre-processing & AbMIL
→ nature biomedical engineering 2021
3D Workflow
In 2D pathology, H&E image analysis is standard, while in 3D pathology, microCT is the main technique.
-
predict 3D ST from 3D pathology (not available)
paper → https://arxiv.org/abs/2502.17761
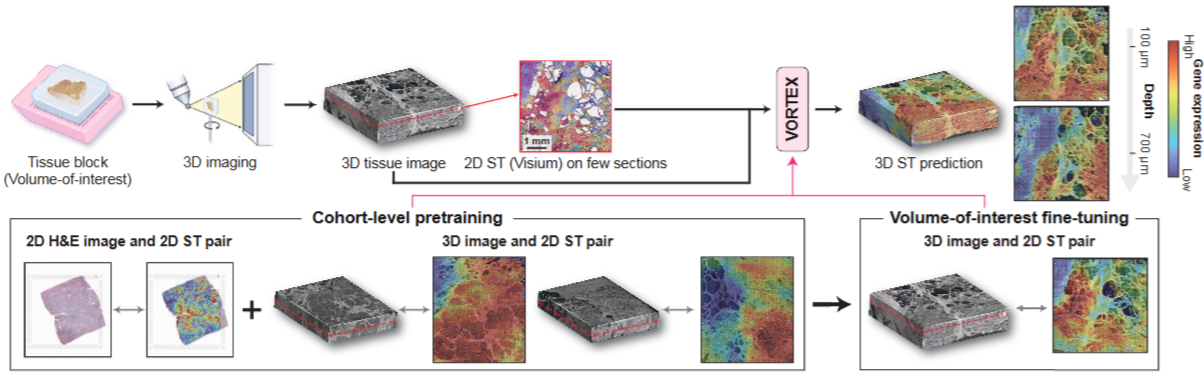
-
predict survival time from 3D pathology
→ Cell 2024

Foundation Models (Feature Extractors)
Patch-level
-
GigaPath
→ Nature 2024
-
UNI/Uni2-h
→ Nature Medicine 2024
Slide-level
-
GigaPath
→ Nature 2024
-
CHIEF
→ Nature 2024
Multimodal
- Vision + Language → Nature 2025
Omics
- Spatial Omics → bioRxiv 2025
CLIP
-
Vision and bulk RNA-seq
→ CVPR 2024
-
Vision and bulk RNA-seq
→ CVPR 2024
-
Vision and Spatial Omics
→ NeurIPS 2023
-
Vision and Spatial Omics (not available)
→ bioRxiv 2025
-
Vision and Text
→ Nature 2025
LoRA Fine-tuning for ViT
-
for ViT via Hugging Face Transformers library
-
for ViT via timm library
Optional Tools
-
Supervision
TESLA can impute gene expression at superpixels and fill in missing gene expression in tissue gaps.→ Cell Systems 2023
-
FF to FFPE
→ nature biomedical engineering 2022
-
Explainability for MIL
HIPPO systematically modifies tissue regions in whole slide images to create counterfactuals, enabling quantitative hypothesis testing, bias detection, and model evaluation beyond traditional performance metrics.→ arxiv 2024
-
DINOv2 (Self-Supervised Learning)
DINOv2 is a self-supervised learning method that trains vision transformers on large-scale datasets to produce robust visual features without supervision.→ arXiv 2023
-
Mask2Former (Cell and Tissue Segmentation)
Mask2Former provides single architecture for panoptic, instance and semantic segmentation.→ arXiv 2022
-
ViT-Adapter (Cell and Tissue Segmentation)
ViT-Adapter is a method that adapts vision transformers for dense prediction tasks, enhancing performance in segmentation tasks.→ ICLR 2023
-
LGSSL (Linear Probe & Few-Shot Evaluation)
LGSSL is a framework for evaluating self-supervised learning methods through linear probing and few-shot learning tasks.→ CVPR 2023
Discussion