

Paper
B-Learner: Quasi-Oracle Bounds on Heterogeneous Causal Effects Under
Hidden Confounding (記事のタイトルに入りきらなかった)
Introduction
Meta-Learner系の中では割と最近発表されたB-Learnerの論文について紹介します。
B-Learnerは、隠れた交絡因子のレベルを想定した上で、CATEの予測に加えてsharp boundを学習するものになります。(交絡因子のレベルはドメイン知識で補う必要があります。)
Background and setup
今回は、Neyman-Rubinのoutcomeフレームワークを用います。データ
この前提の元、CATE(Conditional Average Treatment Effect)は、outcomeの差で求めることができます。
また、交絡因子が存在しない場合は、CATEは潜在outcomeの期待値の差で導出できます。
しかし、観測された共変量
Properties of bound estimates
未観測の交絡を含むデータ
集合
Valid estimates
逆に、
Sharp estimates
bound estimates example
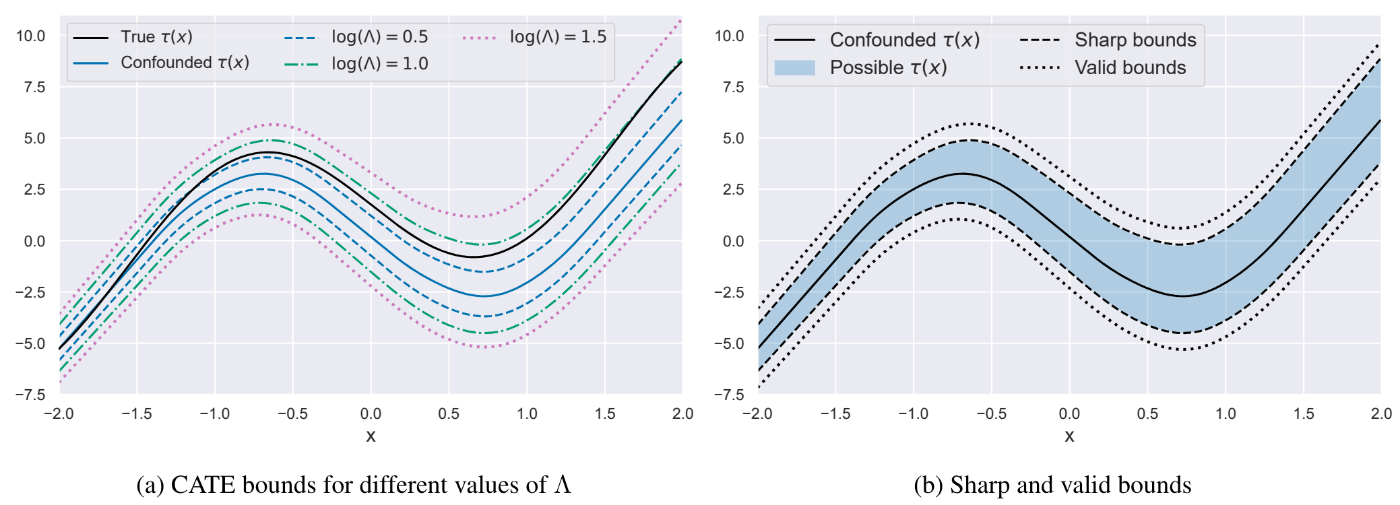
図1. 真のオッズ比
Identification and estimation of sharp bounds
観測データ分布
まずは、CVaR(Conditional Value at Risk)と未観測のoutcome境界に対応するような、擬似outcomeを導入します。
ここで、sharp bound
以上より、CATEのsharp boundの上限は
(ここまでが導入です。)
(本編)B-Learner: Pseudo-Outcome Regression for Doubly-Robust Sharp CATE Bounds
先ほどまででCATEのsharp boundを形式化してきました。ここからは、さらにsharp boundの精度を上げる工夫を施し、B-Learnerを提案する章になります。
Pseudo-outcome regression for quasi-oracle estimation
推定されたnuisanceを
Algorithm
B-Learnerは2段階の推定手法になっています。
第1段階では、k-foldのクロスフィッティングでnuisances(outcome、傾向スコア、CVaR)を推定し、擬似outcome推定量を構築します。第2段階では、推定された擬似outcomeを共変量

傾向スコア
また、outcome
Experiments
論文中ではシミュレーションデータ、IHDP、401(k) Eligibilityの3種で検証を行っていました。今回は401(k) Eligibilityの結果のみ記載します。
Impact of 401(k) Eligibility on Wealth Distribution
401(k) Eligibilityは、401(k)資格とその金融資産への影響に関するデータセットです。このデータセットは交絡がないことがわかっていますが、交絡があると仮定して
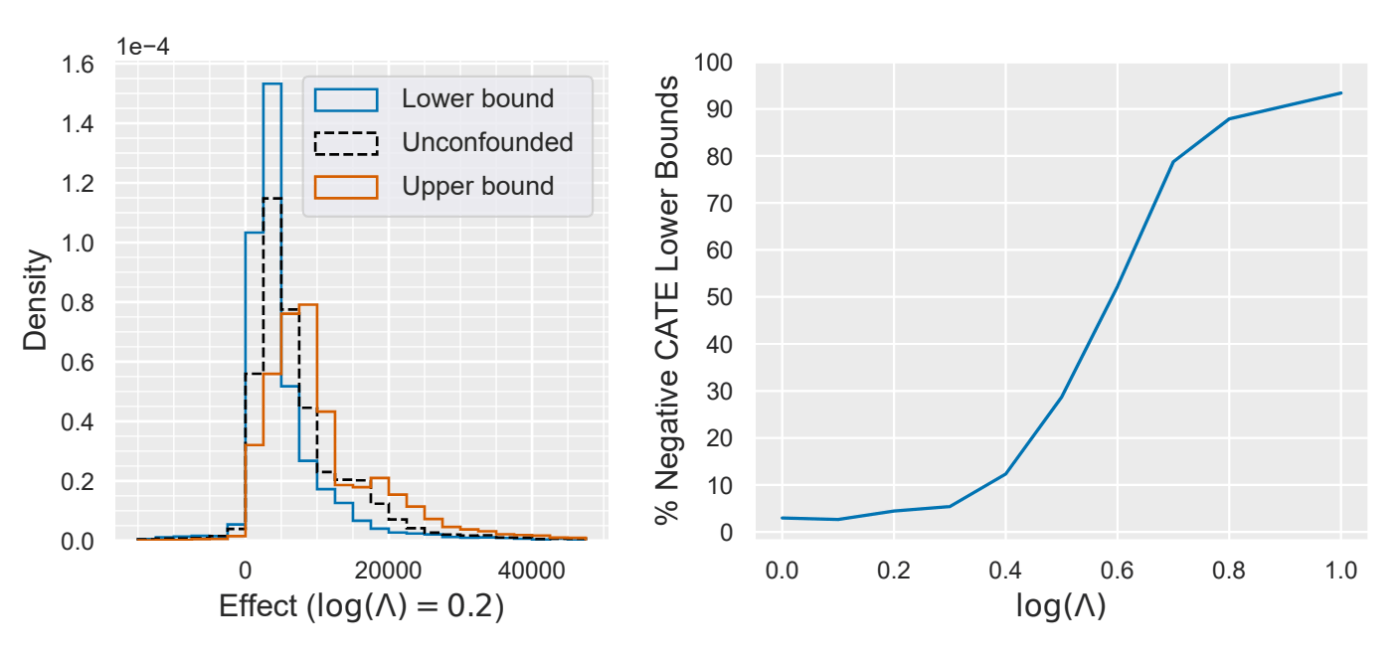
左図:
右図:
検証
B-Learnerは著者がgitにコードを提供してくれているので検証してみます。
今回は、論文中に評価が行われていたシミュレーションデータを用いて、lower upper boundが推定できていることを確かめようと思います。
シミュレーションのデータ生成過程は以下の形式です。(
git cloneでコードを引っ張ってきます。
!git clone https://github.com/CausalML/BLearner.git
cd BLearner
中には著者が準備してくれているgeneratorがあるので、それをそのまま使います。
from datasets import synthetic #データ生成器
generator = synthetic.Synthetic(num_examples=10000, gamma_star=1, mode='mu')
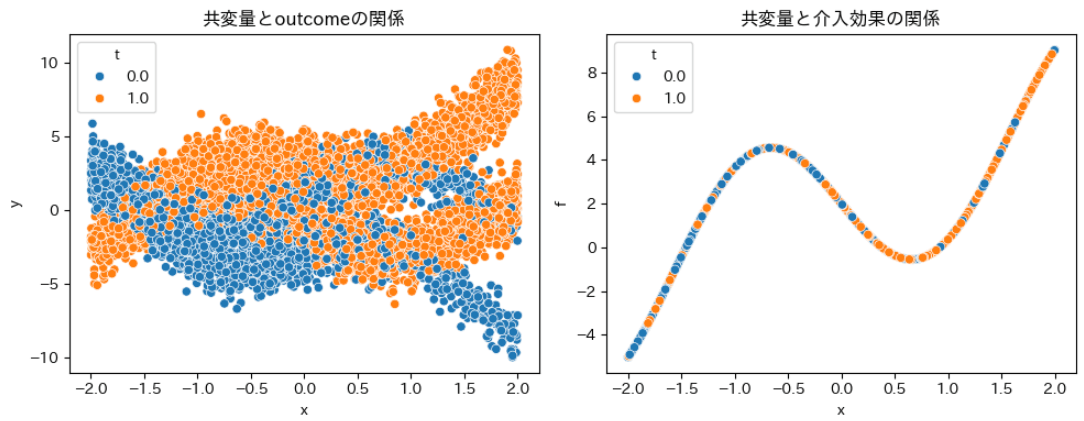
データを取り出してみるとこんな感じでした。共変量に対して介入効果が非線形に与えられているのが分かります。
print(f'ATE:{generator.tau_fn(generator.x).mean()}')
ATE:2.021308422088623
ATEも見ておきます。おおよそ2くらいの介入効果でした。
次にB-Learnerの推定器を作ります。まずは、各コンポーネントの回帰・分類モデルを定義しておきます
gamma = np.e # log(gamma) = 1 の場合
tau = gamma / (1+gamma)
#傾向スコアモデル
propensity_model = lightgbm.LGBMClassifier()
#outcomeモデル
mu_model = lightgbm.LGBMRegressor()
#四分位予測モデル
quantile_model_upper = RandomForestQuantileRegressor(q=tau)
quantile_model_lower = RandomForestQuantileRegressor(q=1-tau)
#CVaR上界モデル
cvar_model_upper = KernelSuperquantileRegressor(kernel=RFKernel(clone(mu_model, safe=False)),
tau=tau, tail="right")
#CVaR下界モデル
cvar_model_lower = KernelSuperquantileRegressor(kernel=RFKernel(clone(mu_model, safe=False)),
tau=1-tau, tail="left")
# CATE境界モデル
cate_bounds_model = lightgbm.LGBMRegressor()
これらを全て入れ込むとB-Leanerの推定器が作れます。
estimator = BLearner(propensity_model = propensity_model,
mu_model = mu_model,
quantile_plus_model = quantile_model_upper,
quantile_minus_model = quantile_model_lower,
cvar_plus_model = cvar_model_upper,
cvar_minus_model = cvar_model_lower,
cate_bounds_model = cate_bounds_model,
use_rho=True,
gamma=gamma)
引数が大量にあって、かなりややこしいですが、、、一応論文で説明されたモデルがすべて入っていることが分かります。
print(f'estimated ATE:{estimator.mu1(X) - estimator.mu0(X)}')
estimated ATE:2.0081604922300373
実際に推定してみるとATEが2程度になり、ちゃんと推定できていることがわかります。
print(f'estimated lower:{effects[0].mean()}')
estimated lower:-0.46066781397843126
print(f'estimated upper:{effects[1].mean()}')
estimated upper:4.610615861659414
上下限も見てみました。率直な感想は思ったより広かったです、、、がこんなもんなのかもしれません。
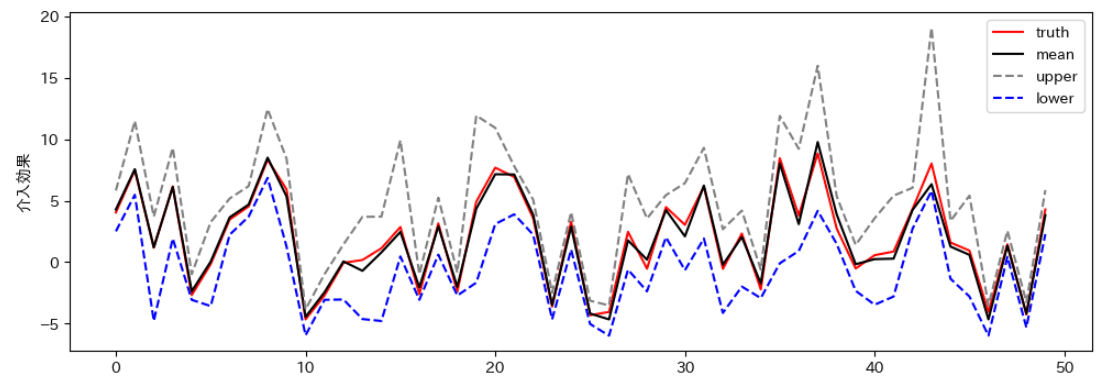
ITEの上下限もプロットしてみました。ほぼすべての点で、きれいに上下限を表せていました。
次に感度パラメータを変更してみます。
gamma = np.e ** 3
print(f'estimated ATE:{estimator.mu1(X) - estimator.mu0(X)}')
estimated ATE:2.01403225907998
print(f'estimated lower:{effects[0].mean()}')
estimated lower:-5.598983732440596
print(f'estimated upper:{effects[1].mean()}')
estimated upper:10.217975521577744
ATEは変わらず、上下限がかなり広がったことが分かります。未観測の交絡因子の大きさがどの程度あるかをシミュレーションする分には楽しめそうですね!
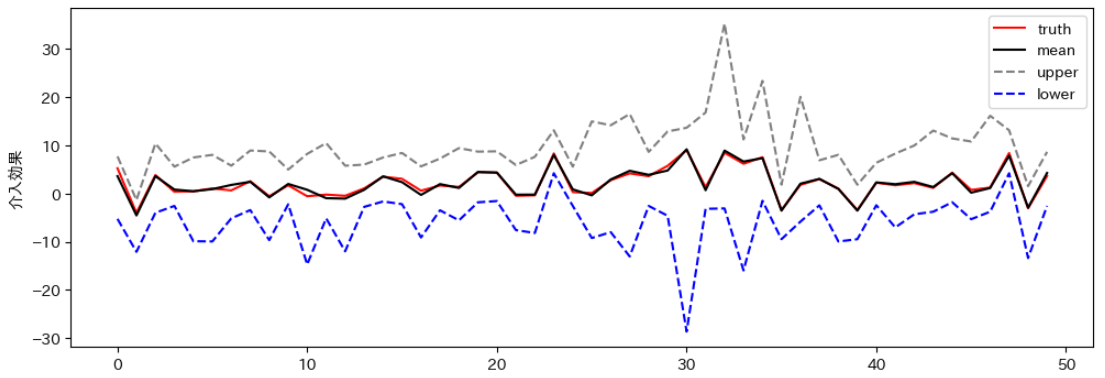
ITEのプロットも見てみると、こちらも先ほどよりも幅が広がってることがわかります。
まとめ
今回はMeta-Learner系の中では割と最近発表されたB-Learnerの論文について紹介しました。これまでのMeta-Learnerの機能を持ち合わせつつ、感度パラメータによって未観測の交絡因子の影響を可視化できるようになりました。しかし、感度パラメータの取り扱いはかなり難しい(事業的なお気持ちも入る)ので、どのくらいの影響までを許容するのかを相手方とうまくすり合わせる必要があります。この推定器でシミュレーションした結果は、そのコミュニケーションツールの一つになるかもしれないとも思いました。

Discussion