要約
- BigQueryAPIからBigQueryStorageAPIに置き換えることで高速にデータ取得ができた
- 具体的には、約5.7億レコードのテーブルに対して
- BigQueryAPI: 2時間20分
- BigQueryStorageAPI: 3分
背景
- VertexAIのカスタムジョブ上でBigQueryAPI(Pythonライブラリ)を用いて、億単位のレコードを取得していた
- BigQueryAPIでのデータ取得がボトルネックとしてあり、カスタムジョブ全体の実行に時間がかかってしまっていた
- 高速化できないか調査したところ、大量のデータ取得に関しては、BigQueryStorageAPI一択とのこと
BigQueryStorageAPI
概要
The BigQuery Storage Read API provides fast access to BigQuery-managed storage by using an rpc-based protocol.
公式Doc
BigQueryAPIに対し高速化できている理由
When you use the Storage Read API, structured data is sent over the wire in a binary serialization format. This allows for additional parallelism among multiple consumers for a set of results.
上記の説明から、以下の2点がありそう
- 並列処理ができる
- セッション内で複数のストリームを使用して処理できる
- データ転送の効率が良い
- binary serialization formatへデータを変換する
実装
- インストール
$ pip install google-cloud-bigquery-storage
- pd.DataFrame形式で取得するように実装してみる
import pandas as pd
from google.cloud.bigquery_storage import BigQueryReadClient, types
class BigQueryStorage:
"""公式Doc: https://cloud.google.com/python/docs/reference/bigquerystorage/latest
大量のデータを高速で読み込むためのClass
"""
def __init__(self, project_id: str, dataset_id: str) -> None:
"""bigquery_storage.BigQueryReadClientの生成
Args:
project_id (str): GCPのプロジェクトID
dataset_id (str): GCPのデータセットID
"""
self.project_id = project_id
self.dataset_id = dataset_id
self.client = BigQueryReadClient()
def read(self, table_name: str, columns: list[str]) -> pd.DataFrame:
"""テーブル指定でselect
Args:
table_name (str): 取得したいテーブル名
columns (list[str]): 取得したいカラム名
Returns:
pd.DataFrame: selectしたテーブルデータ
"""
table = f"projects/{self.project_id}/datasets/{self.dataset_id}/tables/{table_name}"
requested_session = types.ReadSession()
requested_session.table = table
requested_session.data_format = types.DataFormat.ARROW
requested_session.read_options.selected_fields = columns
parent = f"projects/{self.project_id}"
session = self.client.create_read_session(
parent=parent,
read_session=requested_session,
max_stream_count=1,
)
# max_stream_count=1より、配列の0番目の要素を単に指定している
reader = self.client.read_rows(session.streams[0].name)
rows = reader.rows(session)
return rows.to_dataframe()
結果
-
約5.7億レコードのテーブルに対して、以下のように高速に取得できるようになった
- BigQueryAPI: 2時間20分
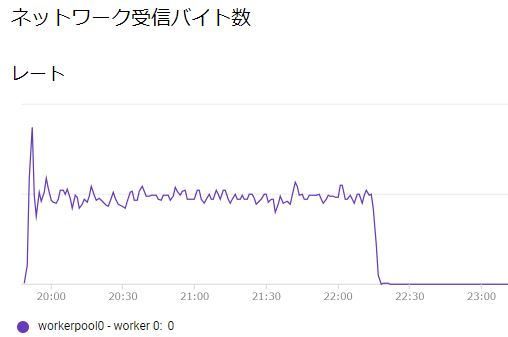
- BigQueryStorageAPI: 3分

ネットワーク受信バイト数の山ができている箇所がBigQueryとやり取りしていることを表している
備考
- TensorFlowでは、
tfio.bigquery.BigQueryClientがある- きれいなインタフェースとして提供されているので、ユースケースに合う場合はこちらがおすすめ
- 今回はReadのみの紹介となったが、Writeもある
おわりに
- 軽い実装で大幅にBigQueryからのデータ取得処理を高速化できた
- 実装に関して、
max_stream_countを増やせば、更に高速化できそう - BigQueryの内部挙動についてもざっくり知ることができ、勉強になった
参考
GitHubで編集を提案

Discussion