はじめに
普段、分析業務はJupyterNotebook上で行っている。具体的には、クエリを書いてBigQueryに格納されているデータを集計・抽出し、Pythonで可視化を行う。
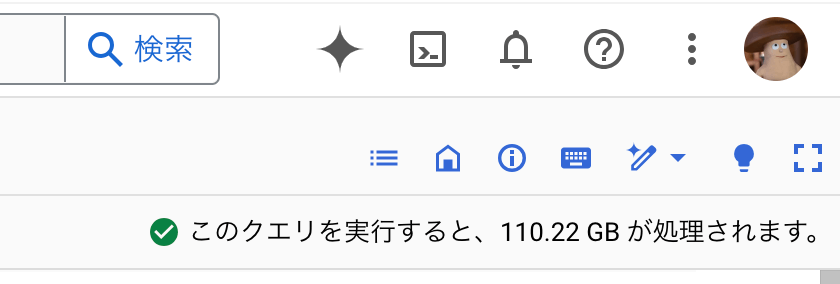
BigQueryのコンソール画面からクエリを実行する際には、以下のようにページの右上にスキャン量が表示される。これをJupyterNotebookでクエリを実行する際にも表示したい。
結論
分析環境はVertex AI Workbenchインスタンスで構築されたものを利用している。
クエリを実行する際、job_config でdru_runが実行されるようにしてあげることで、クエリ実行前にスキャン量を確認することが出来る。
import google.auth
from google.cloud import bigquery
credentials, project = google.auth.default(
scopes=[
"https://www.googleapis.com/auth/drive",
"https://www.googleapis.com/auth/bigquery",
]
)
client = bigquery.Client(credentials=credentials, project=project)
def execute(query):
global client
# check scan bytes
job_dry_runned = client.query(
query,
location='US',
job_config=bigquery.QueryJobConfig(dry_run=True)
)
scan_bytes = job_dry_runned.total_bytes_processed / (1024 ** 3)
print(f'scan bytes: {scan_bytes:.2f}GB')
# execute query
query_job = client.query(
query,
location='US',
job_config=bigquery.QueryJobConfig(dry_run=False)
)
return query_job.to_dataframe()
上記の実行関数は、例えば以下のように利用する。
df = execute('''
select
date_trunc(dt, month) as ym
, sum(unit_price * quantity) as sum_sales
from
order_log
where
dt between '2023-01-01' and '2023-12-31'
group by
1
order by
1
;
''')
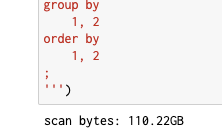
実行すると以下のような形でスキャン量が表示される。
スキャン量の上限を設定する
そもそもスキャン量を確認する目的は、誤って大量にスキャンして多額の実行料金が課金されるのを避けたい、というところが大きい。なのでスキャン量を確認するというよりは、特定のスキャン量を超えるクエリが実行されないようにしたい。
この場合、 job_config に maximum_bytes_billed を設定したconfigを渡してあげれば良い。
以下ではスキャン上限を100GBに設定している。
query_job = client.query(
query,
location='US',
job_config=bigquery.QueryJobConfig(
dry_run=False
, maximum_bytes_billed=(100*(1024**3))
)
)
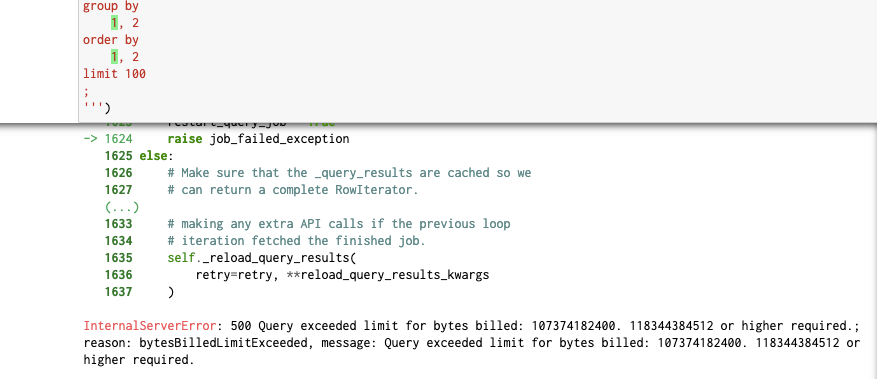
100GBを超えると以下のようにエラーが出て止まってくれる。
参考

Discussion